
Joined September 2021
- Tweets 877
- Following 300
- Followers 3,017
- Likes 188
319 Photos and videos













Pinned Tweet

4 Oct 2025
Ludzie często dziwią się dlaczego jako AI Engineer jestem sceptyczny odnośnie wykorzystania AI.
Odpowiedź jest prosta, mój entuzjazm odnośnie AI jest dokładnie taki sam jak 5 lat temu. To ludzie zaczęli być zbyt optymistyczni.
Od zawsze twierdziłem że AI ma konkretne zastosowania - dobrze uporządkowane, konkretne, powtarzalne procesy z wystarczającą ilością danych historycznych, gdzie jesteśmy w stanie zaakceptować kompromis pomiędzy precyzją a czułością systemu.
Różnica jest taka że kiedyś panowało podejście „AI nie jest w stanie rozpoznać rasy psa na zdjęciu to zbyt skomplikowane”
A teraz jest „Po co komu lekarze, wpisałem moje symptomy do ChatGPT i już mnie zdiagnozował”
Kiedyś trzeba było ten entuzjazm wzbudzać, teraz trzeba go ostudzać ale ja dalej ciągnę do tego samego punktu, tylko teraz trzeba ciągnąć w drugą stronę.

23
25
368
41,639
Aleksander Obuchowski retweeted

Jun 13
Fable feels like a polish freelancer. Shows up, speaks in its own dialect, writes the best code you've ever seen, and then disappears
48
146
2,517
175,661
Aleksander Obuchowski retweeted

Jun 13
To jest właśnie przykład dlaczego trzeba tworzyć niezależne AI.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
52
26
390
21,920
Chciałem wrzucić post zachęcający do wzięcia udziału, ale widzę, że prawie mamy sold out, więc chyba nie trzeba 🙂 Ale! Zostały jeszcze ostatnie miejsca!
W najbliższy wtorek na Health AI & Cybersec Summit opowiem o tym, jak zbudowaliśmy najlepszy polski detektor danych wrażliwych, który mieści się w pamięci przeglądarki.
Zapraszam, będzie to solidana dawka wiedzy a nie tylko prezentacja marketingowa, zamierzam opowiedzieć dokładnie o treningu modelu i odpowiem na wszystkie pytania 🙂
2
7
622
Okej, Fable 5 jest super ale limty kończą się zdecydowanie za szybko
4
20
1,517
Zeszły tydzień był szalony dla otwartych modeli AI
25 🤯 premier modeli open-weight 👇
🧠 LLM-y
-> NVIDIA Nemotron 3 Ultra: hybryda Mamba-MoE 550B, tylko 55B aktywnych, kontekst 1M, 89.1 na MMLU. Wariant NVFP4 obiecuje ~5x przepustowości na chipach Blackwell. Pierwsza otwarta hybryda Mamba-Transformer w skali 550B
-> Google Gemma 4 12B: w pełni otwarty, gęsty model any-to-any (tekst/obraz/audio/wideo), kontekst 256k, bez enkodera, 140 języków, AIME 2026 na poziomie 77.5. Wypuszczony z falą 23 checkpointów QAT (mobilne ONNX MLX). Najłatwiejszy do wdrożenia model tygodnia.
→ Liquid AI LFM2.5-8B-A1B: MoE na edge, raptem 1.5B aktywnych, kontekst 128k, MATH500 88.8, gotowy pod MLX. Najlepsza opcja on-device w tym tygodniu.
→ JetBrains Mellum2-12B-A2.5B-Thinking: ich pierwszy otwarty MoE, koduje prawie jak Qwen3-14B przy 2.5B aktywnych. Apache 2.0.
🎨 Generowanie obrazów )
→ Ideogram 4: ich PIERWSZE otwarte wagi w historii. Diffusion Transformer (DiT) typu flow-matching, 9.3B, trenowany od zera. #2 ogółem za GPT Image 2 i najlepszy model open-weight na Design Arena LMArena. Najlepszy otwarty model do obrazów z dużą ilością tekstu,
🔊 Audio i mowa (przełomowy tydzień dla otwartego TTS wypuściły 4 laby)
→ Higgs Boson Audio v3 4B: 102 języki, 21 emocji, śpiew/szept/krzyk, TTFA poniżej sekundy.
→ rednote dots.tts: jedyny w pełni ciągły (bez kodeka) otwarty pipeline TTS, Apache 2.0.
→ Google Magenta RealTime 2: generowanie muzyki w czasie rzeczywistym, latencja <200ms, tekst audio MIDI. multimodalart przeportował to do PyTorcha w kilka godzin, z działającymi demami na ZeroGPU.
→ NVIDIA Nemotron-3.5 ASR: streamingowe 600M, 17x więcej równoległych strumieni niż Parakeet RNNT 1.1B.
👁️ Wizja i VLM-y
→ StepFun Step-3.7-Flash: rzadki MoE VLM 198B, ~11B aktywnych, SWE-Bench PRO 56.3. Apache 2.0.
→ PaddleOCR-VL-1.6: SOTA w parsowaniu dokumentów przy 1B parametrów, Apache 2.0.
→ Baidu NAVA: wspólne generowanie audio-wideo 6.3B, najlepsza w klasie synchronizacja A/V, Apache 2.0.
🎬 Wideo, 3D i modele świata
→ NVIDIA Cosmos3-Super: omnimodalny model świata 64B, łączy trajektorie akcji z generowaniem wideo audio, pod Physical AI.
→ JD JoyAI-Echo: tekst-do-wideo do 5 minut, wieloujęciowe, na LTX-2.3.
→ ByteDance Bernini-R VAST TripoSplat (z jednego obrazu do gaussian splattingu 3D, MIT).
5
1
25
2,583
Aleksander Obuchowski retweeted

3 czerwca KE opublikowała „Europejską Strategię Open Source”. W skrócie: Europa doszła do wniosku, że cyfrowo jest dziś prawie całkowicie zależna od technologii i dostawców spoza Europy. Plan zakłada m.in. uczciwsze traktowanie rozwiązań open source w zamówieniach publicznych (np. aby urzędy w ogóle rozważały alternatywy w przetargach, zamiast automatycznie sięgać po licencje na „domyślny” pakiet biurowy), większe wsparcie dla projektów OSS oraz rozwój europejskich alternatyw w obszarach takich jak chmura czy AI.

The EU Open Source Strategy was adopted today as a part of the Tech Sovereignty Package.
It promotes open, interoperable, and resilient digital ecosystems that reduce reliance on non-EU providers and move from the proprietary lock-in to open standards. 👉 link.europa.eu/cVWcBr

ALT EU flag in the background with the text: EU Open Source Strategy - Tech Sovereignty Package
1
7
626
Anoniminer-Flash - nasz nowy model do wykrywania danych osobowych - 4x szybszy, bardziej dokładny.
Jesteś ciekaw, jak to zrobiliśmy?
Rzucę trochę inside info:
- Model bazowy: Roberta 8k od PKO Bank Polski wypada podobnie do bazowej Roberty, a ma dużo dłuższy kontekst, więc czemu nie. Dużo lepsze wyniki niż baza od OpenAI privacy filter
- kilka sztuczek zaczerpniętych z Privacy Filter np. Viterbi Decoding z dynamicznymi wagami.
-Próbowaliśmy użyć Bielika 1.5B podobnie jak Privacy Filter robił z GPT OSS i patch na bidirectional attention ale wyniki były gorsze
-Przede wszystkim dane (i dlatego o reszcie piszę tak otwarcie bo to najcięższe do zreplikowania 😉) Mamy już 30tys danych treningowych w tym z realnych teksów z danymi osobowymi i nasze własne przepisy na tworzenie danych. Mocno pomogły tez beta testy i feedback od testerów i klientow za co serdecznie dziękuję 🙏
4
4
26
2,150
Więcej info o modelu: medalion.tech/models/anonimi…
5
334
Akuart niedługo planje wymieniać laptopa
Myślałem o M5 ale...musze przyznać że to brzmi bardzo interesująco pod kątem odpalania lokalnych llmów
- do 128GB unified ramu (oczywiście przy obecnych cenach tanio nie będzie)
- 600GB/s bandwidth
- performance na poziomie 5070
Oczywiście liczę na natywne wsparcie linuxa

NVIDIA, ARM tabanlı yeni işlemcisi RTX Spark'ı duyurdu.
- İşlemcide RTX 5070'e denk bir GPU bulunuyor.
- Modern oyunlarda 1440P'de 100 FPS'te çalışıyor.
- Laptop, Windows olmasına rağmen prizden çektiğinizde performans düşmüyor.
- Batarya ömrü uzun.
- Sadece laptoplar için değil masaüstü bilgisayarlarını da hedefliyor.
- Sahnede 007 First Light ve Forza Horizon 6 ile gösterildi.
- Yapay zeka işlem gücü de yüksek.
- 2026 Sonbahar'ında çıkacak.
39
2
81
49,287
The way you should prompt Claude changed a lot with Opus 4.8.
It follows instructions more literally, writes less, reaches for tools less, and spawns fewer subagents — all by default.
which means half your old prompt scaffolding is now just noise.
especially effort, works much differently now
made a quick guide 👇

8
1,063
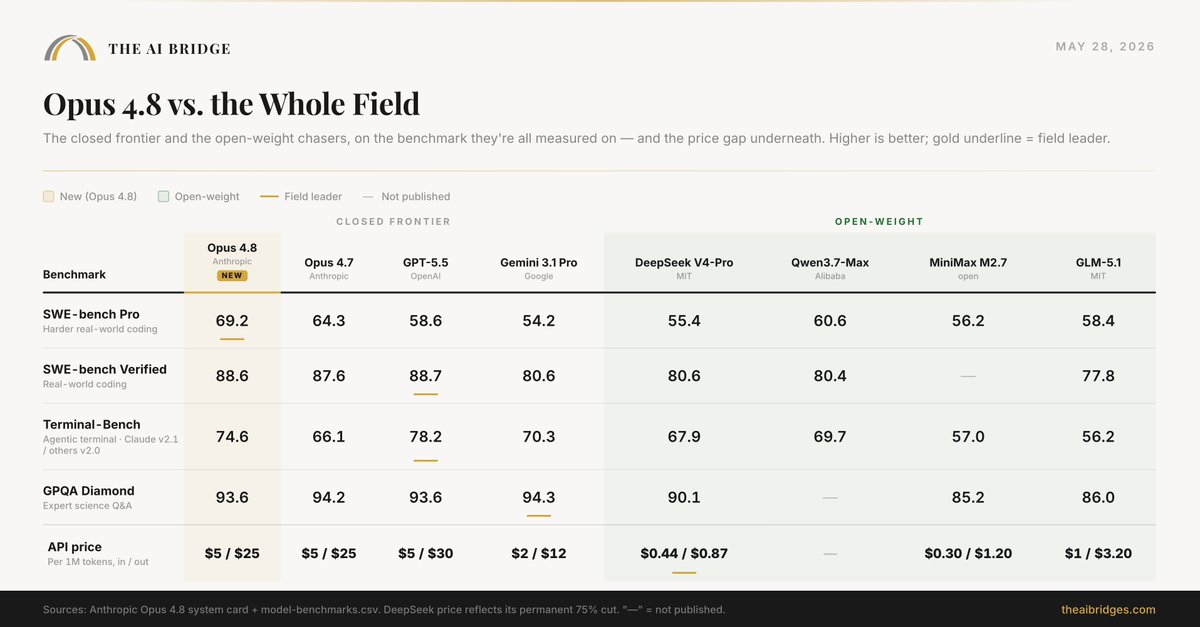
Claude Opus 4.8 TL;DR:
Nie „mądrzejszy", tylko „uczciwszy"
→ Najważniejsze: jest lepszy w wychwytywaniu własnych błędów 4x lepiej niż Opus 4.7
→ Wyniki na benchmarkahc trochę lepsze, do niektórych zdań nadal jest lepszy GPT 5.5
→ Ta sama cena $5/$25 co 4.7. Tryb fast 2,5× szybszy i 3× tańszy
→ Claude Code dostaje dynamiczne workflow: setki subagentów naraz, sprawdzających nawzajem swoją robotę np. ogarnia migracje całego repo
→ Model klasy Mythos ma wyjść w ciągu kilku tygodni
1
11
2,966
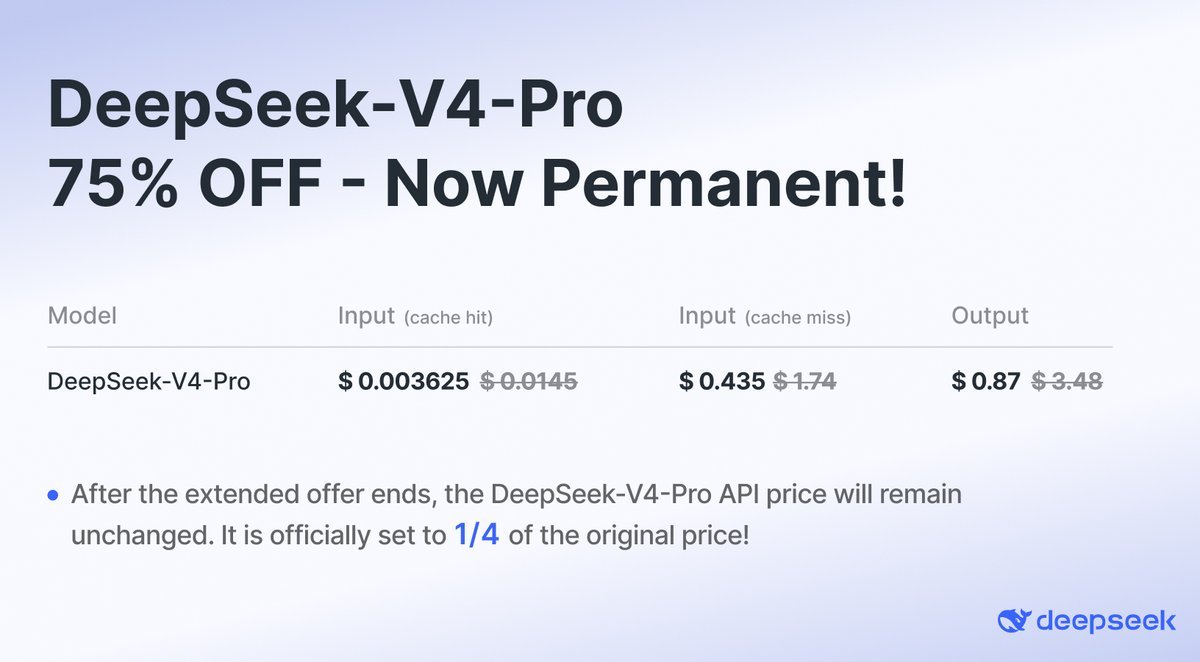
Deepseek V4 - może nie zrobił takiej rewolucji na V3 ale oferuje niesamowity stosunek ceny do jakości.
0.87$ za mln tokenów to niespotykana cena w dzisiejszych czasach gdzie modele kosztują po 60$
I to nie kwestia marketingu i dopłacania do modelu
ale przemyślanej architektury
- Compressed Sparse Attention (CSA)
- Heavily Compressed Attention (HCA)
- MegaMoE
4
2
16
2,347
Nice paper on sleep-like consolidation in hybrid SSM-attention LLMs.
When the context window fills, the model goes "offline": N recurrent passes over accumulated tokens, updating fast weights in SSM blocks via a learned local rule. KV cache is then evicted. Extra compute is paid at sleep time, not at inference.
Pure SSMs and standard transformers fail on cellular automata, multi-hop graph retrieval, and GSM-Infinite as reasoning depth grows. Sleep fixes it: gains scale with N.
2
291
Dlaczego znowu jesteśmy silni wobec słabych i słabi wobec silnych?
Dlaczego „przeraża” nas emerytura znanej aktorki milionerki a nie przerażają nas emerytury milionów Polek i Polaków którzy pracowali na etacie 40 lat?
May 26

Należy pilnie uruchomić też rządowy program token dla artystów sztuki generatywnej. Niepewni jutra są też prompt inżynierzy. Potrzebny jest też interwencyjny skup przez państwo vibe codowanych apek.

3
1
32
1,056
Co gotuje Elon?
Wygląda na to, że xAI szykuje wyraźną zmianę kierunku i chce mocniej wejść na rynek narzędzi dla programistów.
xAI zakończył główną fazę treningu modelu Grok V9 (1,5T parametrów), a jego premiera planowana
jest na połowę czerwca.
Najciekawszym elementem jest integracja z danymi z Cursora - czyli edytora kodu z AI.
Tradycyjnie modele uczą się na statycznym kodzie (np. z otwartych repozytoriów), czyli widzą tylko gotowy efekt końcowy.
Dane z Cursora dają xAI wgląd w sam proces pisania programów. Model analizuje realne interakcje: to, jak programiści poprawiają błędy w locie, jak radzą sobie ze skomplikowaną architekturą i jak wyglądają logi z ich wieloetapowych zadań.
Dzięki temu Grok uczy się działać bardziej jak autonomiczny inżynier oprogramowania i rozwiązywać realne problemy, a nie tylko generować od zera strony internetowe.
Elon widzi, gdzie są prawdziwe pieniądze w AI.
O ile chatboty dla masowego odbiorcy budują zasięgi, o tyle realne przychody płyną ze specjalistycznych
Narzędzia dla profesjonalistów.
Najlepszym punktem odniesienia jest tu Anthropic, gdzie sam Claude Code ma osiągnąć w 2026 aż 2,5 mld dolarów rocznego powtarzalnego przychodu.

Grok foundation model V9-Medium (1.5T) has finished training. Evals look good. A lot of Cursor data was added in supplementary training and there is more to come.
Fine-tuning is underway and reinforcement learning begins in a few days. 2 to 3 weeks to public release.
This will be a major improvement over the 0.5T v8-small that currently serves all Grok production traffic, especially for difficult coding tasks.
5
1
29
7,978
To oficjalne: 🇨🇳 Chiny dogoniły albo nawet przegoniły 🇺🇸USA, jeśli chodzi o sztuczną inteligencję!!
Qwen 3.7-Max nie tylko dorównuje Gemini i Claude pod względem inteligencji, ale jest przy tym 3–4 razy tańszy!
Może też działać autonomicznie przez 35 h❗
Poniżej pełna analiza 👇
W najnowszym rankingu Artificial Analysis Intelligence Index Qwen 3.7-Max zdobył 57 punktów, tyle samo co najlepszy Gemini Pro i Claude Opus. Wyżej jest tylko GPT 5.5 z wydłużonym trybem myśelnia

24
17
161
15,047
Tym, co naprawdę wyróżnia Qwen 3.7-Max, jest jego cena.
Qwen 3.7: 7,50 USD za milion tokenów
Claude Opus 4.7: 30 USD za milion tokenów
Gemini 3.5 Flash: ok. 10,50 USD za milion tokenów
GPT-5.4: 17,50 USD za milion tokenów
Mamy do czynienia więc nie tylko z wysoką inteligencją modelu ale też bardzo konkurencyjną ceną
1
1
10
1,300
Czy to więc koniec Claude Code, Codexa i Antigravity?
Oczywiście, że nie.
Po pierwsze, benchmarki to jedno, ale prawdziwa weryfikacja przyjdzie po tygodniach używania modelu.
Po drugie, nie mamy gwarancji, czy Anthropic i OpenAI nie zaprezentują zaraz czegoś jeszcze lepszego.
Anthropic ma w końcu w zanadrzu Mythosa
Dla mnie najważniejsze jest co innego, to że Qwen nie jest już drugą ligą "tańszych ale gorszych chińskich modeli" tylko wkroczył do pierwszej ligi i raczej tam zostanie.
2
8
1,088