
The latest news from the top 100 companies in AI. Over 300,000 devs read our newsletter.
Joined February 2010
- Tweets 891
- Following 331
- Followers 15,458
- Likes 2,716
291 Photos and videos












SIA is interesting because it treats agents as editable systems.
Not just prompts.
Tools, parsers, verifiers, harness code, and weights all become update targets.
The paper reports:
> 70.1% on LawBench
> - 1,017 µs CUDA kernel
> 0.289 mse_norm on denoising
Public repo makes you pick "--focus harness" or "--focus weights".
The paper’s automatic switch is the missing piece.
Real lesson: a self-improving agent is only as good as its verifier.
2
1
1
128
AlphaSignal AI retweeted

Introducing Adaline 2.0 - The Agent Self-Improvement Layer
Adaline turns Traces into Behaviors,
Behaviors surface Issues,
Issues become auto-generated Evals Data,
Adaline then generates new agent candidates and tests them.
You review the winners and ship!
107
5,678
617
448,063
The biggest bottleneck for computer-use agents just got automated away.
Reinforcement learning broke open math and coding.
But for agents clicking around real software, progress stalled.
The bottleneck was generating training data at scale.
CUA-Gym is a pipeline that solves this.
It synthesizes verifiable tasks for computer-use agents end to end.
The setup uses three coordinated coding agents:
> Generator writes environment setup scripts
> Discriminator drafts the reward function blind
> Orchestrator iterates until both align
The team also built mock versions of 94 popular apps.
These include Slack, Notion, Salesforce, and Gmail clones.
Rewards read state directly, skipping flaky screenshot judges.
The resulting dataset holds 32,112 verified tuples across 110 environments.
A trained model hits 72.6% on OSWorld-Verified, matching Claude Sonnet 4.6.
A smaller 3B version matches its 17B base with 10x fewer parameters.
The full system, dataset, and models are open source.
4
5
11
1,453
Repo: github.com/xlang-ai/CUA-Gym
Check out alphasignal.ai/newsletter to get a daily summary of the latest
breakthrough news, models, papers and repos. Read by 300,000 devs.
2
507
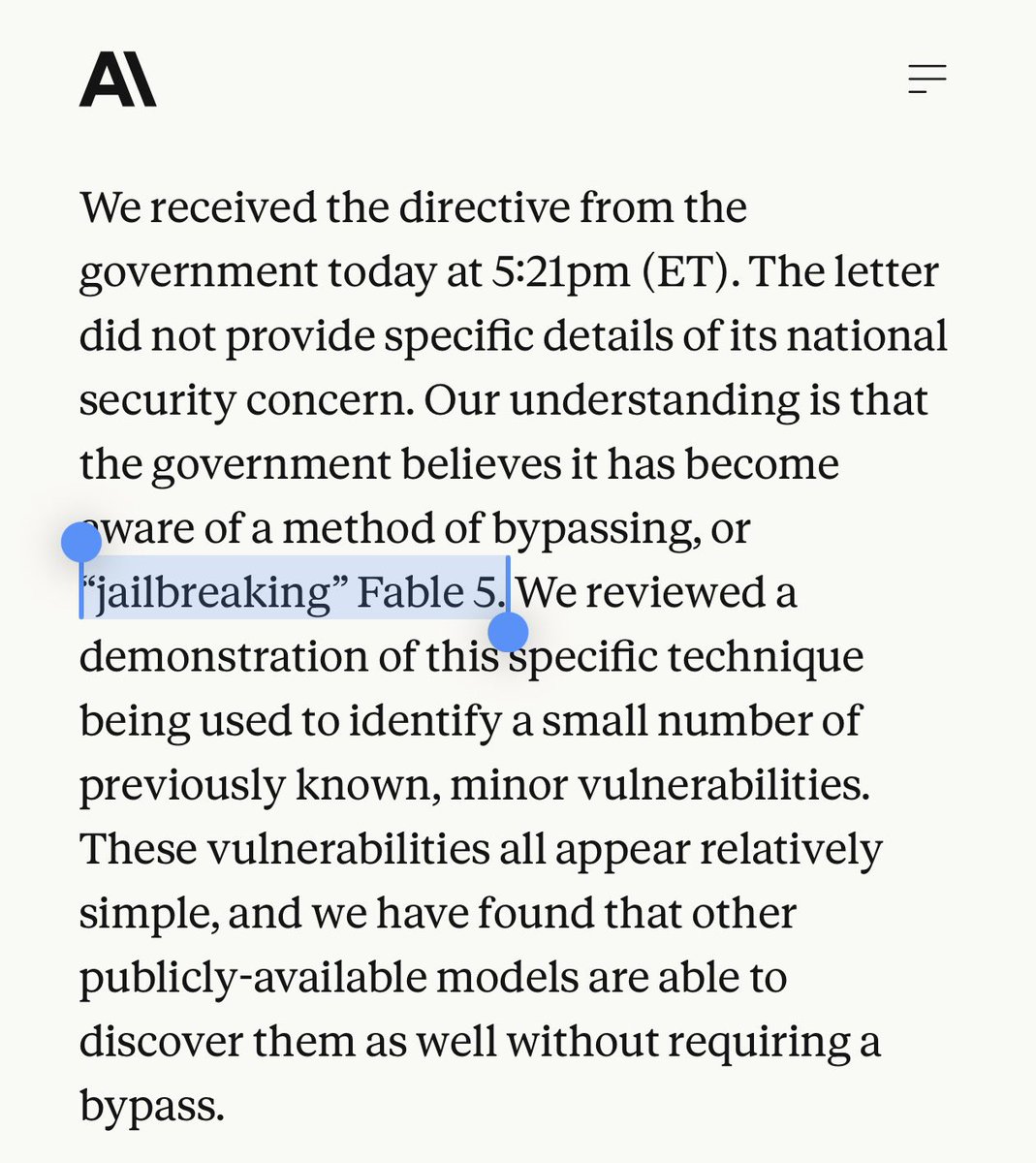
“Fable 5 prompt leak / jailbreak” was so serious that it got banned? or the model was so powerful for a prompt leak?
Well, they said “it’s a non-universal jailbreak..”

4
3
11
3,654
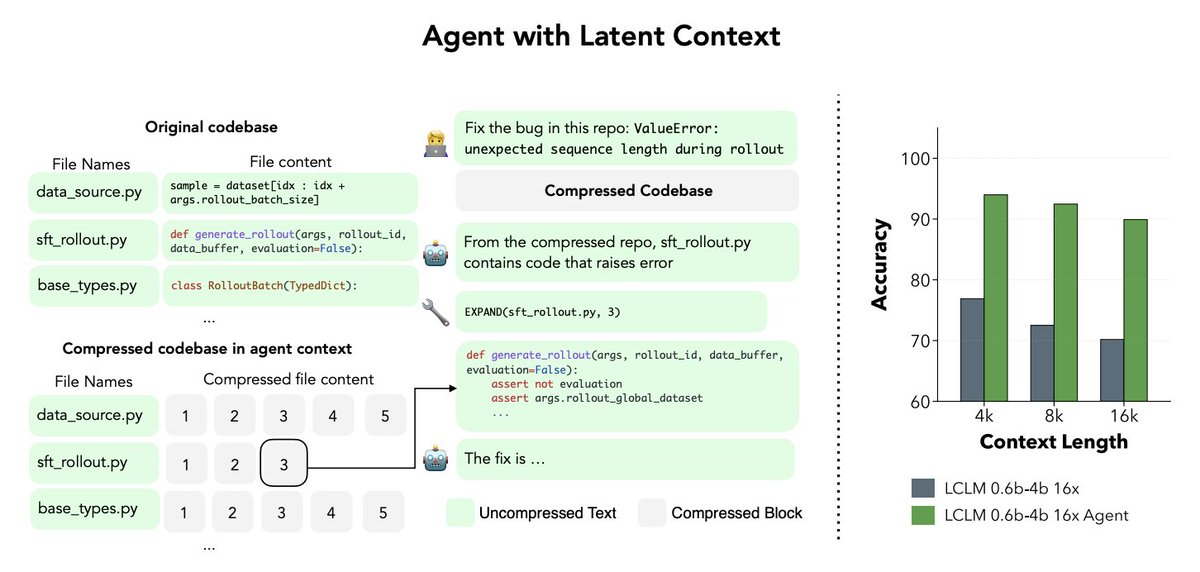
Researchers just made frozen AI models smarter without retraining them.
Large language models run each input through their layers exactly once.
Researchers asked a simple question.
Can you squeeze more reasoning out of a finished model without retraining it?
A new paper called "Training-Free Looped Transformers via Numerical ODE Integration" says yes.
The trick is treating each layer as one step in solving a math equation.
Looping a layer naively breaks things, since later layers expect a specific input.
So instead they replace one big step with several smaller damped ones.
This gives frozen models extra thinking time at inference.
What makes this practical:
> No fine-tuning required
> Works on existing checkpoints
> Strongest on hard knowledge tests
Gains reached 2.64 points on MMLU-Pro and 2.01 on GPQA.
It held positive across 87% of tested combinations.
If old weights hide this much capacity, what else are we leaving unused?
3
3
22
1,124
Paper: alphaxiv.org/abs/2605.23872
Check out alphasignal.ai/newsletter to get a daily summary of the latest
breakthrough news, models, papers and repos. Read by 300,000 devs.
403

Jun 13
You installed that AI skill without scanning it. So did 99% of developers.
26.1% of published skills contain vulnerabilities. 36% contain prompt injection vectors. A skill can be dangerous without a single line of malicious code.
NVIDIA open-sourced a scanner built specifically for this.
It's called SkillSpector.
4
2
9
1,271
Jun 12
Reminder before 22 Jun: Learn how to use Claude Fable 5 properly, save tokens, maximize efficiency, and build before it goes to API only.
4
3
999
Jun 12
1
2
1,057
Jun 12
We finally know why bigger models are smarter. It's not the data.
More training data was supposed to fix small models.
A new paper shows why it cannot.
Researchers proved some tasks need model scaling, not data scaling.
A small model fails them even with infinite data.
The cause is competition over neurons.
Frequent tasks grab capacity first and keep it.
Rare task updates get overwritten before the next example arrives.
The model learns, then forgets, in an endless loop.
Scaling breaks the loop in three steps:
1. Common tasks get fully learned
2. Their gradients fade to nothing
3. Rare features accumulate safely
The team pretrained OLMo models from 4M to 4B parameters.
They injected novel tasks at controlled frequencies during training.
Only the largest models learned the rare ones.
Interference between their gradients nearly disappeared.
How many tasks is your model silently skipping?
5
10
32
1,588
Jun 12
Paper: arxiv.org/abs/2605.29548
Check out alphasignal.ai/newsletter to get a daily summary of the latest
breakthrough news, models, papers and repos. Read by 300,000 devs.
2
336
Jun 12
1
657