
The first investor for technical founders. Early backers of Datadog, Chainguard, dbt Labs, Temporal, Modal, Hightouch, Luma, Scribe, and more.
Joined October 2012
- Tweets 3,471
- Following 263
- Followers 7,532
- Likes 3,654
142 Photos and videos







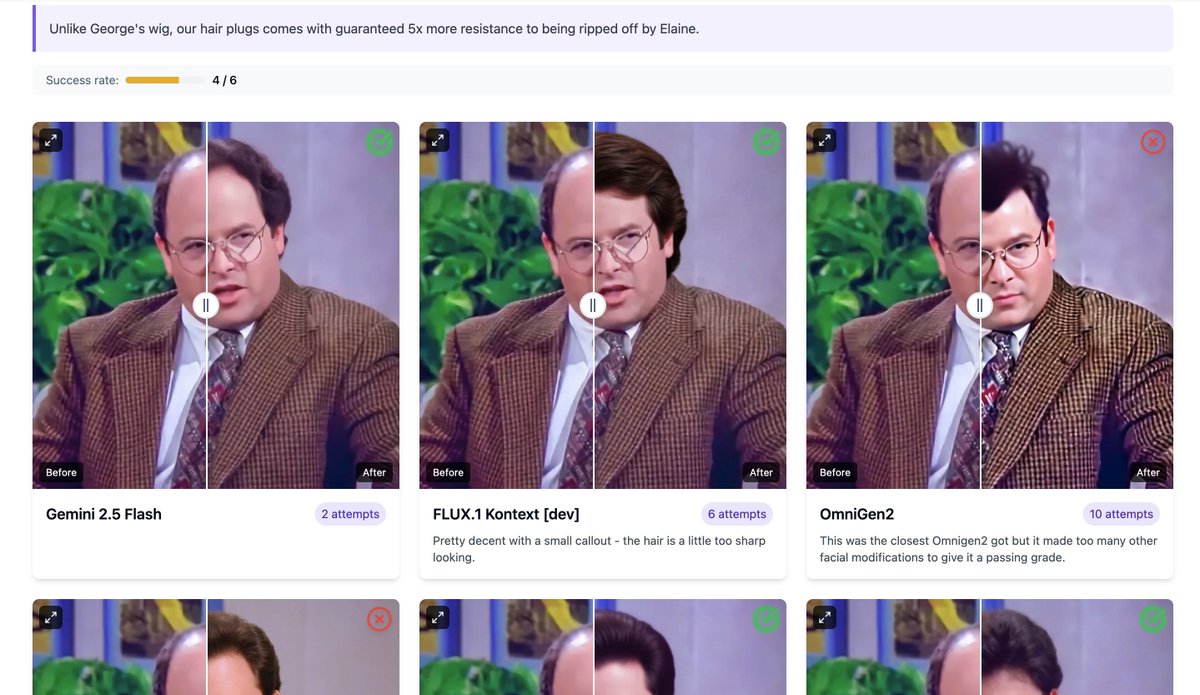




Jun 12
DeepMind used self-play with RL to build AlphaGo in 2016. The model played against older versions of itself, creating an automatic curriculum of increasingly difficult tasks.
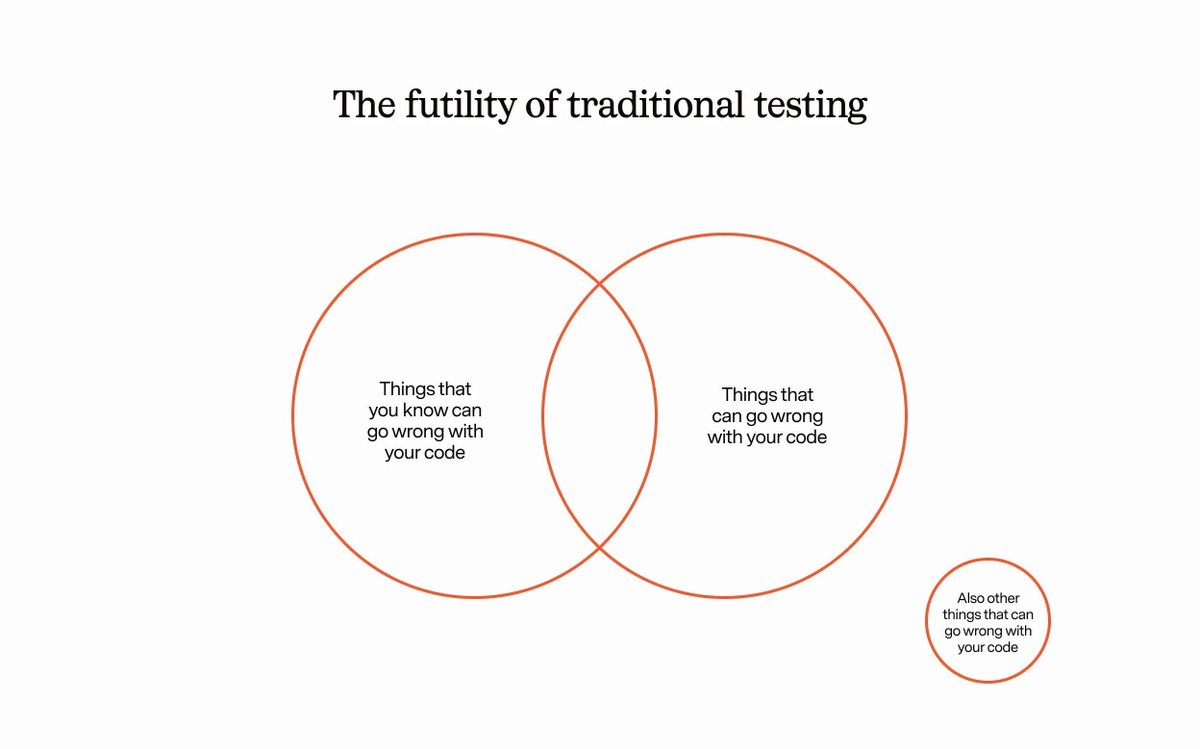
Why haven’t we done this with language models yet?
amplifypartners.com/blog-pos…
5
266
Amplify Partners retweeted

"How do I write a good launch blog post for developers?"
> State your controversial opinion
> Motivate the problem
> Show traction and social proof
> Write for yourself

5
3
51
3,933
Amplify Partners retweeted

Jun 11
12
82
597
1,066,536
Jun 10
Congrats to Sajid and Conor on Niteshift going GA today. If you're doing complex, long running work with coding agents you should give it a try (first class support for Fable, too)
Jun 10

We're launching @niteshiftdev – the full-stack cloud for coding agents
Verification is the new bottleneck.
Software teams can now define their dev environment and verification tools once. Then run any frontier agent in the cloud: Claude Code, Codex, or OpenCode
5
863
Amplify Partners retweeted

Jun 10
Rohan should have titled this “A trip down memory lane”- but he can be forgiven.
Lots of folks conflating continual learning with RL optimization; the latter may be necessary but likely insufficient.
Here he reviews the different veins of historical and current research that can together enable continually learning and capable agents.
Jun 9

Memory Augmented Neural Networks aren’t new, but their modern counterparts open new axes for scaling agents. I wrote a post on how architectures like Memory Networks and Neural Turing Machines pave the way for making retrieval and continual learning intrinsic to the model itself
The silent revolution has already begun. In January, DeepSeek released Engram, a sparse memory module that looks up knowledge within the forward pass. It split where memory is stored from where reasoning happens, analogous to how MoE made transformers capable of conditional computation. Sequential compute is no longer wasted storing facts.
Retrieval has come a long way from single-vector RAG. We use multi-vector embeddings and post-train models to search over filesystems and vector databases, though latency is high and tool call tokens fill up context. Methods like context compaction e.g. Cartridges reduce this cost, but also shifts the burden to teaching a model when cartridges should be used or updated. Still lots to be done here!
On a complementary axis, there’s a rich lineage where retrieval is trained into the model mid-layer. Memory didn't always live in context alone! @jaseweston et al.’s Memory Networks (2014) made memory an explicit addressable matrix the model queries mid-forward-pass. RETRO by @borgeaud_s et al. scaled it to transformers in 2021. @GuillaumeLample et al.’s Product Key Memory made sparse KV retrieval over a parameterized memory layer more efficient, and recently this was scaled up in Memory Layers by Berges et al. in 2024.
Beyond retrieval, as agent tasks stretch from weeks to months, we’ll increasingly want to write information to the model within an episode. Context engineering can store token-level working information in filesystems, but always-on test-time training enables continuous weights updates as in Learning to Discover at Test Time by @mertyuksekgonul.
Over long horizons, continual learning faces two main problems: how to distill the right signal to learn from and how to integrate information without catastrophic forgetting. Most existing work still uses unsupervised learning objectives, or shallow subsets of parameters, shifting the problem to choosing which LORA to swap in and out. There’s even more work to be done here!
On a second complementary axis, what if we could write relevant information to network parameters during a forward pass without catastrophic forgetting? Neural Turing Machines (Graves et al., 2014) made reads AND writes to external memory differentiable, Differentiable Neural Computers ensured only unused slots were updated, and @santoroAI et al. showed in 2016 you could meta-learn a generalizable write policy across many episodes. Imagine a model with an intrinsic scratchpad for planning over long horizons!
3
3
24
7,887
Amplify Partners retweeted

Jun 9
Memory Augmented Neural Networks aren’t new, but their modern counterparts open new axes for scaling agents. I wrote a post on how architectures like Memory Networks and Neural Turing Machines pave the way for making retrieval and continual learning intrinsic to the model itself
The silent revolution has already begun. In January, DeepSeek released Engram, a sparse memory module that looks up knowledge within the forward pass. It split where memory is stored from where reasoning happens, analogous to how MoE made transformers capable of conditional computation. Sequential compute is no longer wasted storing facts.
Retrieval has come a long way from single-vector RAG. We use multi-vector embeddings and post-train models to search over filesystems and vector databases, though latency is high and tool call tokens fill up context. Methods like context compaction e.g. Cartridges reduce this cost, but also shifts the burden to teaching a model when cartridges should be used or updated. Still lots to be done here!
On a complementary axis, there’s a rich lineage where retrieval is trained into the model mid-layer. Memory didn't always live in context alone! @jaseweston et al.’s Memory Networks (2014) made memory an explicit addressable matrix the model queries mid-forward-pass. RETRO by @borgeaud_s et al. scaled it to transformers in 2021. @GuillaumeLample et al.’s Product Key Memory made sparse KV retrieval over a parameterized memory layer more efficient, and recently this was scaled up in Memory Layers by Berges et al. in 2024.
Beyond retrieval, as agent tasks stretch from weeks to months, we’ll increasingly want to write information to the model within an episode. Context engineering can store token-level working information in filesystems, but always-on test-time training enables continuous weights updates as in Learning to Discover at Test Time by @mertyuksekgonul.
Over long horizons, continual learning faces two main problems: how to distill the right signal to learn from and how to integrate information without catastrophic forgetting. Most existing work still uses unsupervised learning objectives, or shallow subsets of parameters, shifting the problem to choosing which LORA to swap in and out. There’s even more work to be done here!
On a second complementary axis, what if we could write relevant information to network parameters during a forward pass without catastrophic forgetting? Neural Turing Machines (Graves et al., 2014) made reads AND writes to external memory differentiable, Differentiable Neural Computers ensured only unused slots were updated, and @santoroAI et al. showed in 2016 you could meta-learn a generalizable write policy across many episodes. Imagine a model with an intrinsic scratchpad for planning over long horizons!
6
9
35
10,881
Sandboxes started as a weekend prototype at Modal. Now they're handling 100,000 concurrent environments for RL workloads, with customers targeting 1 million. How do you orchestrate that many isolated containers? amplifypartners.com/blog-pos…
1
11
800
Most major LLMs today generate tokens one at a time, which is among the least efficient methods possible. Diffusion models generate everything at once instead, and Mercury 2 hits 1,009 tokens/sec — 10x faster than Haiku 4.5. How we got here is quite wild: amplifypartners.com/blog-pos…
2
4
314
Amplify Partners retweeted

Accelerating momentum at Runway: just in the past 6 weeks, we saw 50% growth in token consumption, 140% growth in power users, and an inflection point in enterprise NDR to 300% as Runway becomes more embedded in daily workflows
This is the way
16
8
97
7,277
Congrats to @evanyou and the entire @voidzerodev team on joining Cloudflare today 🙂
Jun 4

BIG DAY! @voidzerodev is joining @cloudflare 🚀
before anything else: @vite_js is very much remaining open source, and will always remain that way, with robust ongoing investment
we're also going to keep making cloudflare the best place for building applications!
thrilled to have @evanyou and team join us to help us on that mission.
blog.cloudflare.com/voidzero…
6
571
Amplify Partners retweeted

Jun 2
Where you start your VC career can make or break it. Most people choose wrong. My thoughts after nearly twenty years of hiring and promoting junior VCs.
5
5
50
26,806
A year ago, LLMs hadn’t drastically transformed software engineering. A lot has changed! Engineers are now delegating much (most?) of code authorship to agents, and the SDLC is being redesigned from scratch. Here are the emergent patterns: amplifypartners.com/blog-pos…
6
700
Amplify Partners retweeted

Jun 2
I have been waiting for when Sydney Sweeney finally makes it into a VC blog post 🤣.
Great post, as expected!
2
1
4
1,151
Amplify Partners retweeted
Jun 2
I hate pitch meetings. So I take at most 2-3/week. The rest of my time is spent meeting researchers and engineers. Anywhere else this would be sacrilege (coverage goals?!) but it’s the only thing that works for me. Find a place that works for you.
Jun 2

Where you start your VC career can make or break it. Most people choose wrong. My thoughts after nearly twenty years of hiring and promoting junior VCs.
8
3
62
9,958
Amplify Partners retweeted
Jun 2
2
3
25
1,831
Consider the 4th wall of this account broken.
Jun 2
Where you start your VC career can make or break it. Most people choose wrong. My thoughts after nearly twenty years of hiring and promoting junior VCs.
3
436
Werewolves welcome.
Jun 2

Join me and @lennypruss from @AmplifyPartners at our next AI Infra After Dark in SF during @aiDotEngineer's World's Fair!
1
5
475
Amplify Partners retweeted

AI Infra After Dark is on during @aiDotEngineer's World Fair in SF 💥
We're super excited to host this event with our friends at @AmplifyPartners.
RSVP here: luma.com/vermilion-zoog
cc @ashl3ysm1th @lennypruss

2
2
530
Amplify Partners retweeted

Jun 2
Free Radicals is back! Today’s guest is @ElliotHershberg, partner at @AmplifyPartners and author of the popular blog Century of Biology.
We talk about GLP-1s as a breakthrough moment for biotech, why drug development is starting to behave like software, and how falling discovery costs could finally free biotech startups from selling themselves to pharma.
Other topics include Elliot’s "massive markets, medium prices" thesis, the rise of consumer and "n-of-one" medicine, and Sid Sijbrandij @sytses going founder mode on his own cancer.
Thank you to @SynBioBeta for hosting us at their conference, where we recorded this episode, and several others we’ll be releasing soon!
Follow me, @FreeRadicalsBio & @EricDai_BioE for weekly episodes with leaders in biotech and longevity.
0:00 Intro
2:12 What era of biotech are we in?
3:58 GLP-1s: the once-in-a-generation breakthrough
7:04 Inside Lilly's trillion-dollar valuation
9:09 The Gillette Era of GLP1s
9:54 The Bryan Johnson Era of Biotech: Biohacking goes mainstream
12:55 The $1T question on Consumer Biotech
14:33 Patent cliffs, fast followers, and building for "me-last" therapies
18:20 Disintermediating pharma: HIMS, Loyal, and the standalone biotech
19:41 Why do biotechs sell to pharma in the first place?
23:03 Longevity: a science problem or an ecosystem-alignment problem?
27:14 Why GLP-1s came from pharma
29:52 Why Elliot is Bullish on Standalone Biotechs
33:03 Is Drug Development Becoming more like Software? Not if upside is capped at <$10B
41:30 The geroscience hypothesis and longevity as massive markets, medium prices
45:36 Treating age related diseases or aging as an indication
47:55 How do you value curing aging?
4
8
5,677
Amplify Partners retweeted

Hey everyone — big day for us at Skiplabs: Skipper Beta is live 🚀
Skipper is a closed-loop coding agent. Instead of constantly going back and forth with the AI, you give it a spec and it iterates internally until it produces a working software service.
We believe this is where AI-assisted coding is heading, and we’re excited to finally share what we’ve been working on behind the scenes.
Start building with Skipper: skipperai.dev
3
8
25
20,840