
Proprietary research on crypto & AI & macro. Long-term thinker.HK-based. Not financial advice.
Joined May 2021
- Tweets 1,189
- Following 2,346
- Followers 2,221
- Likes 321
50 Photos and videos









Anthropic 高管与白宫之间的个性冲突导致其 Mythos 和 Fable 模型被暂停访问,此前美国政府以越狱担忧为由发布了出口管制指令。 这一事件凸显了领先 AI 公司的内部冲突如何影响服务可用性并复杂化政府关系,可能对 AI 安全和出口管制政策产生影响。 出口管制指令是由 Mythos 模型的越狱事件触发的,Anthropic 称其为‘狭窄的、非普遍性’漏洞。该公司已关闭对所有客户(包括外籍员工)的 Mythos 和 Fable 5 访问权限。
1
10
美国出口管制禁止了 Anthropic 的 Claude Fable 5 模型修复包含已知 CVE 的代码,尽管这是一项防御性安全任务。研究人员不得不手动将模型的补丁输出转换为脚本,凸显了将修复漏洞归类为“越狱”的荒谬性。 这一政策缺陷削弱了美国网络防御,阻止了 AI 模型自动化漏洞修复,而对手却不受此类限制。它为 AI 监管树立了一个危险先例,优先考虑假设的攻击风险而非切实的防御效益。 被禁止的活动包括要求 Fable 5“修复此代码”,涉及包含已知 CVE 的开源代码和故意植入漏洞的代码——这是一项标准的防御任务。Kate Moussouris 确认这不是越狱行为,而是 AI 为防御安全能做的最有价值的事情。
1
9
alesforce 已签署最终协议,以 36 亿美元收购 Fin(前身为 Intercom)——一个 AI 客服代理平台。该交易于 2026 年 6 月 15 日宣布。 此次收购加强了 Salesforce 在 AI 客服市场的地位,直接与 Sierra、Decagon 等新兴平台竞争。同时,它也阻止了独立的 AI 支持代理成为 CRM 生态系统外部的控制点。 Fin 在收购前一个月才从 Intercom 更名。该交易预计将加速 Salesforce 的 Agentforce 战略,该战略旨在将 AI 代理嵌入其 CRM 平台。
Fin 提供 AI 驱动的客户服务平台,可自动处理支持对话。Salesforce 是全球领先的 CRM 平台,而 AI 客服代理市场正在快速增长,竞争对手如 Sierra 估值 158 亿美元,Decagon 估值 45 亿美元。
1
12
福克斯公司(Fox Corporation)正收购热门流媒体硬件与平台公司 Roku,此举将整合一家大型内容提供商与关键分发平台。 此次收购引发了对媒体整合及流媒体平台中立的严重担忧,福克斯可能会在 Roku 平台上优先推广自家内容,从而损害竞争对手及消费者选择。 Roku 被大约 30-50%的美国家庭使用,为福克斯提供了直接触达海量用户的机会。社区成员指出,Roku 已有广告和内容合作,福克斯收购可能加剧利益冲突。
1
6
Iroh 1.0 已发布,它是一个点对点网络库,允许应用实例使用加密密钥而非 IP 地址直接连接,类似于应用层的 Tailscale。 该版本通过处理 NAT 穿透和中继通信,简化了点对点应用的开发,减少了对中心化服务器的依赖,从而支持更去中心化和更具弹性的系统。 Iroh 1.0 原生支持 IPv4、IPv6 和中继传输,并提供实现自定义传输的 API。它使用公钥密码学进行对等身份验证,并在直接连接失败时使用中继来保证连通性。
传统的网络应用依赖 IP 地址进行路由,但点对点连接常常面临 NAT 穿透和地址变化等挑战。Iroh 通过使用加密密钥作为稳定的标识符,并引入中继服务器在直接路径受阻时协助连接来解决这一问题。这种方法类似于 Tailscale 创建 VPN 覆盖网络的方式,但工作在应用层,使开发者更容易将其嵌入到自己的应用中。
1
6
攻击者在 LinkedIn 上冒充招聘人员,发送虚假的面试任务,引导求职者访问一个恶意 GitHub 仓库,其中隐藏了 npm 的 prepare 脚本后门,该脚本在 npm install 时自动执行。 这种新型供应链攻击利用了招聘过程中的信任,针对那些可能不假思索安装依赖项的软件开发者。它凸显了社会工程学和自动化软件包执行中的漏洞,可能危及敏感系统。 后门嵌入在 npm 的'prepare'生命周期脚本中,该脚本在'npm install'后自动运行,无需任何用户警告。恶意代码建立远程服务器连接,使攻击者能在受害者机器上执行任意命令。
1
8
Qwen 团队发布了一套机器人套件,包含三个基础模型:Qwen-RobotNav(导航)、Qwen-RobotManip(操作)和 Qwen-RobotWorld(世界建模),所有模型均采用语言优先接口。 该套件可与通用大语言模型集成,形成能够实时任务分解和自主纠错的物理智能体系统,标志着具身智能领域的重大进展。 Qwen-RobotNav 统一了五大导航任务,Qwen-RobotManip 通过统一表示实现跨形态机器人训练,Qwen-RobotWorld 使用自然语言动作接口学习覆盖 20 多种机器人形态的世界模型。
1
4
Andrew111 retweeted

Jun 14
这是 YouTube 最火爆的 Codex 零基础上手教程。
Youtube 140 万粉丝的大佬 Charlie Chang(Hook AI 创始人),14 分钟带你从下载到实战,全程跟着做一遍:
让搭载 GPT-5.5 的 Codex 自己做落地页、写营销方案、跑定时任务、还能生成宣传视频——一条 prompt 就能产出一整套素材。
章节:
00:00 Codex 是什么,为什么比 Claude/Gemini 强
00:44 第一步:下载安装 Codex
01:08 走一遍引导设置
01:38 吃透主界面:项目、聊天、权限、模型档
03:44 实战介绍
03:57 配连接器:GitHub / 浏览器 / HeyGen
04:35 Plan 模式做一个 AI 落地页
05:50 Codex 自带浏览器,自己截图测试
06:14 加自动化:每天 9 点自动出报告
07:25 让 Codex 回头改进落地页
08:39 接 Google Drive,自动生成营销方案
10:24 一条 prompt 生成宣传视频
12:37 做社媒轮播图
12:45 去试、去迭代,做自己的东西
14 分钟,把 Codex 用成全能助手。
39
378
1,294
67,670
企业的能力需要通过AI沉淀下来,不随人员或者底层模型的改变而改变

1
13

微软 CEO Satya Nadella 发了一篇长文,提出了一个新概念:Token 资本。
他的核心论点是,AI 时代每家公司都需要同时经营两种资本。一种是传统的人力资本,员工的知识、判断力、关系网络;另一种是 Token 资本,公司自己构建并拥有的 AI 能力。两者不是此消彼长的关系,人的判断力越强,Token 资本增长越快。没有人的方向引导,算力只是在空转。
这个说法听起来抽象,但 Nadella 给出了一个具体的检验标准:你能不能随时换掉底层的通用大模型,而不丢失公司积累的专有经验?如果能,说明你真正拥有自己的 AI 能力;如果不能,说明你只是在租用别人的智能。
他建议企业把工作流、行业知识、决策经验转化成可以持续改进的 AI 系统,建立私有评估体系来衡量模型在实际业务中的表现,而不是只看公开跑分。这个学习飞轮一旦转起来,就像复利,每次改进的工作流都会产生更好的训练信号,进一步加速知识积累。
Nadella 还发出了一个颇有政治意味的警告。他拿全球化做类比:第一轮全球化时期,GDP 数字看着不错,但整个产业被外包掏空了,后果至今还在显现。如果 AI 时代重演这个剧本,少数几个模型吃掉所有行业的知识和价值,"政治经济体系不会容忍这种结局"。
--- 原文翻译 ---
没有生态支撑的前沿技术,注定无法行稳致远
Satya Nadella
最近,我一直在深思:在由人工智能驱动的经济浪潮中,企业的未来究竟在哪里?
这次变革与以往任何一次平台更迭都截然不同。过去,我们只是用数字化系统来提升人类的工作效率。但这一次,我们破天荒地在人类与数字系统之间建立起了一个真正的认知循环 (cognitive loop)。这绝对是个颠覆认知的概念,因为它彻底改变了我们对企业内部“工作”本质的定义。
当 AI 模型能够源源不断地吸收人类和组织的专业知识,并将其变成大众化的廉价商品(即将原本稀缺的专业技能变成人人唾手可得的通用能力,从而削弱企业的核心壁垒)时,真正的危机出现了。我们面临的关键挑战,不再仅仅是如何使用某个数字化工具或系统,而是企业该如何在这个全新的世界中持续学习、积累知识产权 (IP)、保持独特性并茁壮成长。
每家公司都必须构建两种资本:一种是我们熟知的“人力资本” (human capital),另一种我称之为“Token 资本” (token capital)。人力资本包含了员工的知识储备、判断力、人脉关系、创造力以及识别事物规律的能力;而 Token 资本则是指企业自身打造并掌控的 AI 实力(在这里,“Token 资本”一词很形象,因为大语言模型 (LLM) 处理信息的基本单位就是 Token)。
必须强调的是,随着 Token 资本的不断壮大,人力资本并不会因此贬值。相反,它会变得比以往任何时候都更加宝贵!我坚信,人类的主观能动性 (human agency) 将是推动 Token 资本增长的核心引擎。人类负责设定宏大的目标,跨领域地将线索串联起来,建立关系网,并洞察出最关键的规律。如果没有人类在前方指引方向,那些强大的计算力不过是在原地打转罢了。
这就意味着,真正的机遇并不在于你去市面上挑选一个“最好”的模型,而在于如何在模型的基础之上,构建一个能让人力资本和 Token 资本产生复利效应 (compound) 的“学习循环” (learning loop)。你可以把某项任务甚至整个岗位都外包出去,但你绝对不能把“学习能力”给外包了。企业未来的核心竞争力,就在于能否在人类与 AI 之间不断积累并放大这种学习能力。
这需要一种全新的架构思路:每家企业都要能够构建出能随着时间推移自我迭代的 AI 智能体系统 (agentic systems),同时还要牢牢掌控自己的知识产权。一家公司应该能够随时替换掉底层的某个“通才模型” (generalist model),而不丢失那些已经沉淀在系统里的、像“公司老兵”一样丰富的专业经验。在未来的时代,这将是检验企业是否拥有数据控制权和技术主权的关键“试金石”。
企业需要将自身的工作流、领域知识以及多年积累的判断力,统统转化为每一次使用都能自我进化的 AI 系统。企业应当建立私有评估机制 (private evals)(即企业内部针对自身真实业务场景定制的模型能力测试标准),用来检验模型是否真正在对企业有价值的结果上取得了进步,而不能仅仅依赖外界的公开跑分盲目自嗨!专属的强化学习 (reinforcement learning) 环境,应该让模型通过吸收组织内部真实的业务数据和工作轨迹变得越来越强大。这样的专属知识库,能让企业的组织记忆变得随时可检索,同时也让 token (tokens) 的运转效率大幅提升。
这种循环,将成为企业全新的知识产权。我把它想象成一台不断向上攀登的机器 (hill climbing machine)。而且与大多数资产不同,它具有强大的复利效应。每一个被优化的工作流,都会产生更优质的训练信号,从而加速这家企业独有的隐性知识 (tacit knowledge) 的积累。那些尽早布局构建这种循环的公司,将会获得一道难以复制的护城河,无论未来市面上又出了什么能力炸裂的新模型,都无法轻易撼动其地位。
我们最不愿看到的局面,就是各行各业的所有公司,都在向少数几个贪婪吞噬一切的巨头模型割让价值。如果所有的经济价值都只被少数几个模型垄断,政治经济体制是绝对无法容忍的。社会也绝对不会允许一个让整个产业被彻底掏空的 AI 未来。
回想一下全球化初期发生的事情吧:大规模的业务外包曾让许多工业经济体被彻底掏空。表面上看 GDP 数据依然光鲜亮丽,但大量产业工人流离失所是血淋淋的现实,其带来的严重后果至今仍未消散。我们绝不能让这种悲剧在 AI 时代重演——决不能让少数几个 AI 系统攫取了所有的经济回报,而一整个行业的从业者却只能眼睁睁地看着自己赖以生存的专业知识被无情地廉价化。
在我看来,我们的当务之急不仅是打造前沿模型 (frontier model),更要构建一个繁荣的“前沿生态系统” (frontier ecosystem)。只有这样,价值才能像活水一样,广泛地流向每一家公司、每一个行业、每一个国家。在这个生态中,每个组织都能拥有属于自己的学习循环,将组织智慧沉淀其中,让人力资本与 Token 资本共同实现滚雪球式的增长。
这也是伴随我职业生涯一路走来的核心理念:真正的平台,能够让在其之上生长出来的价值,远远大于平台自身所截留的价值。在这样的生态里,每家公司都能持续创新,并构建属于自己的真正价值。
当这一切实现时,企业不仅能为自己、也能为周边的整个经济体创造巨大的红利。员工们将会看到自己的专业技能被无限放大,个人的判断力将被融入系统,变得可以复制和规模化应用。而这一切带来的好处,最终将回馈给企业以及他们所在的广泛社区。
这才是企业为自身和宏观经济创造价值的正确方式。这也是我们应当携手共建的、稳定而持久的生态平衡。
68
172
605
171,461

听听EvoseAI 创始人Bingo聊硅谷AI见闻。
xiaoyuzhoufm.com/episode/6a2…
17
5
21
7,554

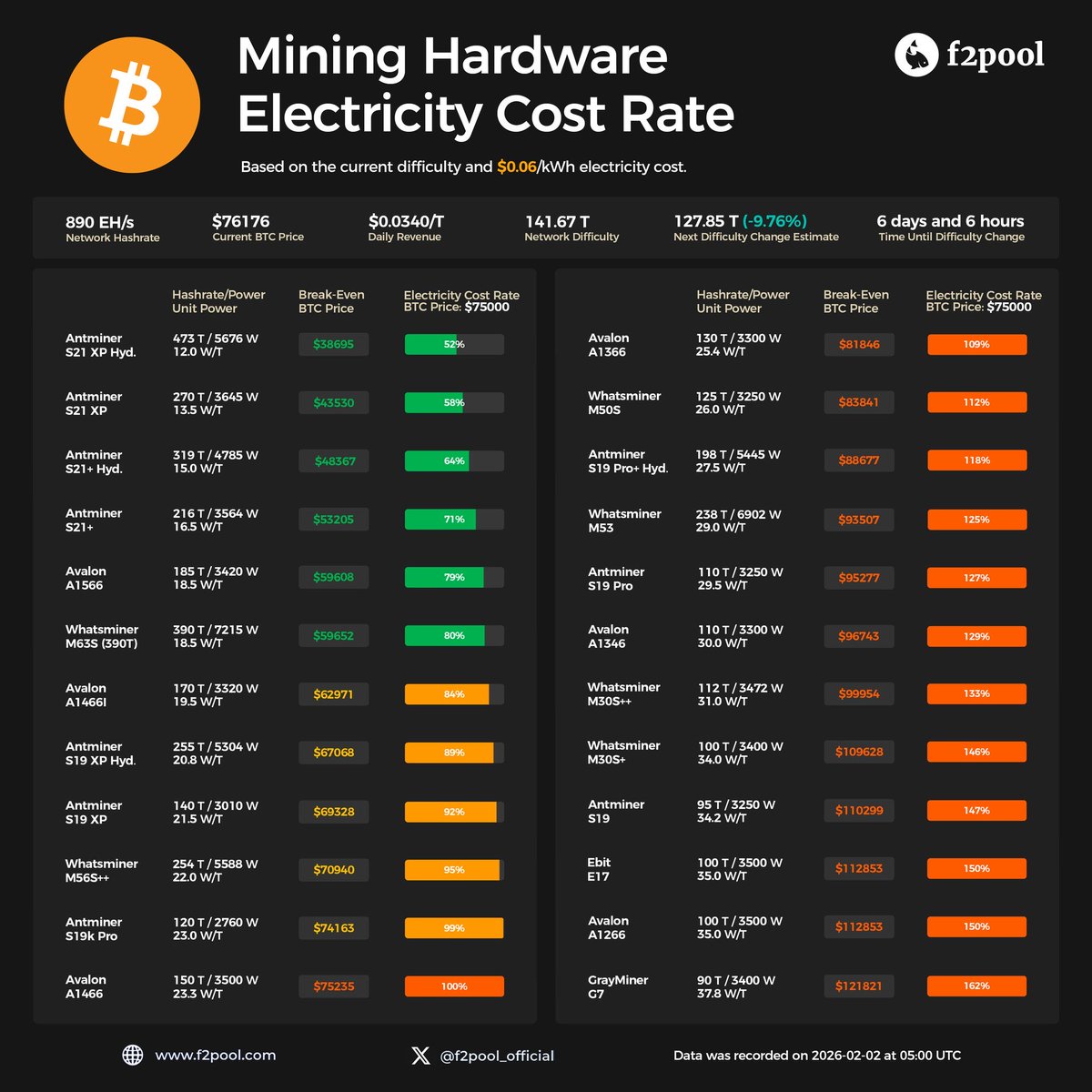
兄弟们,程序员跪着啃源码的时代终于要翻篇了!🔥
这玩意儿叫 Understand Anything,GitHub 直接冲到 59.2k 星,Trending 第一,真不是吹的。
它能把整个代码库变成可点可问的知识图谱:
1️⃣ 点函数秒出依赖关系,谁调谁一目了然
2️⃣ 直接开口问“支付流程怎么走”,答案秒回
3️⃣ 改代码前跑一下 /understand-diff,哪块会爆提前知道
Claude Code、Cursor、VS Code 全支持,一行命令搞定。
20 万行屎山,10 分钟从懵逼到通透,真香。
🔗:github.com/Lum1104/Understan…
64
357
1,603
89,555

Jun 15
以后写程序就是不停的loop,把所有的事情都甩给AI完事儿...
Jun 15

Prompt该退环境了,未来属于Loop Engineering。
最近,AI行业又出现了一个有趣的新词。Loop Engineering。
如果你关注AI这个领域的话,这两天应该都会刷到。推特在刷,各种社媒也在刷,群里也有蛮多人在讨论。事情是这样的。
6月7号,OpenClaw的创始人Peter发了一条推,非常的简短,但是直接就爆了。
翻译过来意思就是:你不再需要为编码智能体编写提示词了,你应该设计循环来提示你的Agent。
而在这之前几天,Claude Code的创始人老哥Boris在一个开发者大会上也说了差不多的话。
他的原话大概是,我不再手动给Claude写提示词了,我运行着能让Claude自动编排任务的循环,我的工作,就是编写这些循环机制。
也就是,写loop。
这两个人呢,说了同一件事。然后Google的Addy Osmani紧接着发了一篇长文,把Loop Engineering这个概念正式梳理了出来。
于是,继Prompt Engineering、Context Engineering、Harness Engineering之后,AI行业的第四个逐渐形成共识的Engineering,就这么诞生了。
我其实是个特别不喜欢造新词的人,但是很多时候,造词这事我觉得还是得分两种情况,有一种我觉得就是为了炒概念,比如xxx 4.0。
而有的时候,真的只是行业太快,人们更需要一个精准的表达来帮助自己表达而已。Loop Engineering我觉得就是后一种。
而且,这个东西跟我自己一直使用Agent的方法、一直在鼓励大家做的事,是高度吻合的。如果你看过我之前写的那篇Harness Engineering的文章,你大概能理解一些我的感觉。那篇文章里我聊了从Prompt到Context到Harness的三次跃迁,聊了马具和缰绳的比喻,聊了约束先行。
而Loop Engineering,其实就是在Harness之上,又往上走了一层。把一个套马的缰绳,变成了全自动工业流水线。很有《文明》里时代的进化的感觉。
给大家举个例子。比如说,以前你用Claude Code写代码,流程大概是这样的。你给它一个任务,它写完了,你看一眼,觉得不太对,你再给它提一个修改意见,它改完了,你再看,再提意见。整个过程你会发现,是坐在设备前的,一轮一轮的,你说一句它回一句,你就是那个驱动整个循环的发动机。
即使我们以前从chatbot时代迈向了Agent时代,绝大多数的事情,也一样是任务制的。
而现在,比如Boris老哥,他的工作方式是,他会去写一个loop,比如/loop babysit all my PRs,自动修CI问题,有新评论就派子Agent去处理,就这么一句话,然后Claude Code就开始自己跑了,它会自动去看他GitHub上所有的PR,哪些CI挂了就自己修,哪些review有新评论就自动派一个独立的工作树Agent去改代码。
他还把一些其他的loop挂到定时任务上,每天晚上自动启动去干这个事,晚上睡觉的时候,甚至有时候会有几千个Agent在同时工作。他自己说,2026年,他就再也没有手写过一行代码了。
你会看到,这就是loop,定好目标,然后全自动流程化,你完全不需要在电脑前,甚至都不需要看手机。
你可以直接睡觉,醒来的时候,代码已经改好了,测试也已经跑过了,PR也已经提上去了。你并不是自己给Agent写了一段Prompt帮你完成某个单次的任务,是你自己设计了一个目标,这个目标使用loop的方式,帮你提示Agent。
你定义目标,定义验证条件,定义失败了怎么处理,然后,就可以放手了,从此以后,这一切,交给系统。
说到这里,我估计很多人已经大概理解loop是个什么东西了。Addy Osmani在他那篇长文里,把一个完整的loop拆成了五个组件。
我觉得这个拆法蛮清晰的,我用我自己的理解给大家过一下。
第一个是定时任务,整个loop的心跳。
你得有一个东西能自动启动循环,不管是定时跑、还是事件触发,都行。
Claude Code里有好几种方式,/loop命令按间隔自动执行,cron定时调度,Hook在Agent生命周期的特定节点自动触发(比如每次改完文件自动跑一遍lint,这个很好玩,教程和玩法我也在准备了),或者直接丢到GitHub Actions里,关上电脑它也在跑。
没有定时任务的Agent,你每次都得手动去踢一脚它才会动,那就不是loop了,那还是你在操控。
第二个是工作树隔离,Worktree(搞过开发的朋友应该秒懂)。
就是你同时跑好几个Agent的时候,给每个Agent一个独立的工作空间,各干各的互不干扰,干完了再合并。两个Agent改同一个文件的痛苦,跟两个设计师同时改一个图层又不打招呼的痛苦,是一模一样的。
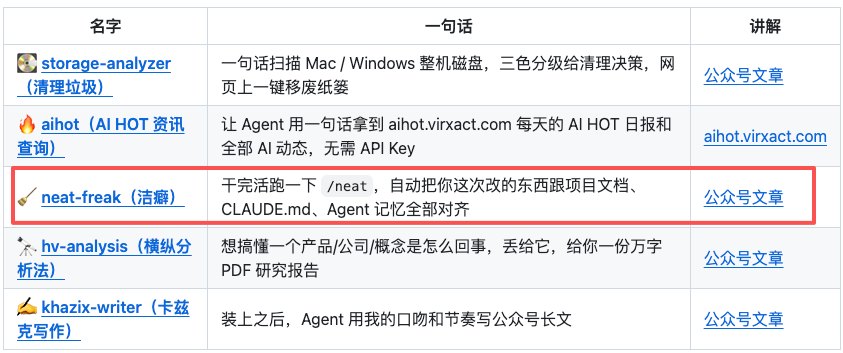
第三个是项目知识体系,Addy Osmani在他的原文里写的是skill,但是我觉得他写的不太对,单skill其实是不够的,必须得是知识管理体系。
大家也都知道,AI每次开新对话就啥都忘了,你跟它说过的代码规范、项目架构、踩过的坑,下次开对话全部从零开始。
所以你得有一整套方法来沉淀、优化这些知识,让Agent每次启动的时候就已经知道你的项目,我自己在这快一年的coding开发过程中,总结的方法论其实就沉淀成了我自己的洁癖.skill,这个基本是我的Agent每天调用最多的skill。
CLAUDE.md是全局的规则和约束,跨会话记忆是一些之前悬而未决的记录和文档路由,docs体系就是你完整的所有的知识和经验沉淀,因为CLAUDE.md和记忆都有大小和行数限制,所以每次任务完成后我会用洁癖.skill来对整个的知识体系进行梳理和审查,确保没有错误。
为什么知识管理体系这个东西在loop里特别重要呢?
因为loop是自动跑的,你不在场。如果Agent的记忆里有过期信息,它就会基于错误的前提做决策,如果CLAUDE.md膨胀到几百行全是历史叙事,真正的规则反而被挤出去了Agent读不到。没有干净的知识体系的loop,就像一个每天早上都在看过期文档的员工,干的得越快错得越多。
所以洁癖.skill我非常推荐大家可以去安装一下,也在我自己的仓库里开源了,我自己真的觉得特别有用。
github.com/KKKKhazix/khazix-…
第四个是连接器,MCP。
一个只能看文件系统的Agent,能力是很有限的。但你给它接上GitHub、Linear、Slack、数据库,它就能在你的真实工作环境里干活了。
这才叫真正的闭环,从发现问题到解决问题到通知人类,一条龙。
第五个是子Agent。
做事的和检查的分开,写代码的Agent不能自己给自己打分,这跟学生自己批自己的考卷一个道理,它一定会对自己太宽容。所以你得有另一个Agent,甚至用不同的模型,专门来检查前一个Agent的输出,一个负责做,一个负责验。
这五个东西加在一起,就是一个完整的loop的骨架。
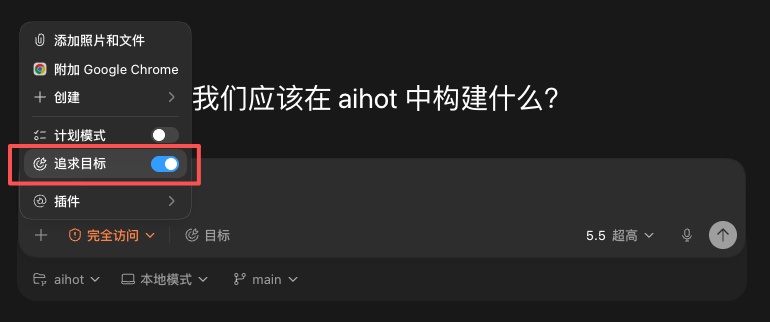
Claude Code和Codex有一个命令,其实就是Loop Engineering这套骨架最直接的微观型的产品化体现,只不过很多人没有意识到。
他叫/goal,在Codex里叫追求目标。
意思就是你给Claude一个完成条件,比如「所有测试通过并且lint检查没有报错」,然后它就会一轮一轮的自己干,干完每一轮之后,就会检查这个条件是不是满足了。
大多数讲Loop Engineering的文章,都停在了这一层。讲了五个组件,讲了/goal和/loop命令,讲了怎么配定时任务,就结束了。
这些我觉得,都是术。而我更想聊的,是道。
Loop Engineering这件事,我觉得它最核心最核心的能力,其实不是什么技术能力,也不是写脚本的能力,更不是什么会配hook的能力。
最核心的,是定义目标的能力。定义目标,相信我,这四个字,听起来简单,做起来是真的难。
回到前面说的/goal,它的用法看起来非常直接,给一个完成条件,Claude自己干到满足为止。
听起来很简单对吧。但你如果真正用过就会知道,/goal用得好不好,完全取决于你那个目标定义得好不好。这个事我拿两个例子对比一下你就明白了。
目标A,「把这个应用优化一下」。
目标B,「test/auth目录下所有测试通过,tsc --noEmit零报错,npm run lint零违规」。
目标A会发生什么呢。大家可能都能猜到,Claude会陷入一种非常尴尬的状态,因为它不知道什么叫「优化好了」,除非他是Fable 5,能自己在你之上,自主的帮你定义目标。
而绝大多数的模型,包括Opus 4.8和GPT-5.5,在自己定义目标的能力上还是非常的弱,它可能改了一点代码,然后自己觉得还行,就停了。
也可能不停,一直改一直改,把你的代码库改得面目全非,因为它始终无法判断自己到底什么时候算完成了。那目标B呢?Claude每改一轮代码,都会去跑测试、跑类型检查、跑lint。
三个命令,三个明确的通过标准。全过了就停,没过就继续,清清楚楚,干干净净。同一个工具,同一个模型。
区别只在于,你的目标定义得好不好。
我自己其实一直有一个原则,我经常跟身边的人说,在公众号里也说了无数遍,如果一件事你重复做了三次,你就一定要想办法把它完全自动化掉。
这个习惯跟了我很多年了。我每天也都在写代码、做自动化,我们的AIHOT热点监控系统,我们的数据分析流程,我们的财务对账流程,我们的数据清洗管道,能自动的我全部自动了。
但说实话,在做这些自动化的过程中,我踩过最多的坑,从来不是技术问题。
是目标不清晰的问题。我早期做自动化的时候,经常犯一个错,就是目标定得太模糊。
举个例子,比如自动监控AI行业热点,这句话听起来没毛病,但其实是一句纯粹的废话。
什么叫热点?浏览量过万算热点还是过十万算热点?抓取频率是每小时还是每天?抓到以后怎么评估质量?评估完以后怎么排序?排完以后怎么推送?
这种反问的问题,我现在可以直接随手问20个以上。
每一个环节如果没有明确的判定标准,整个自动化链条就是一坨狗屎,你相信我,绝对的。
后来我懂了,每次做自动化之前,我会先花很多时间去定义目标。
去花很多很多时间,去定义怎么算做完了,怎么做完算做的好。这其实就是/goal的逻辑。也是Loop Engineering的灵魂。
而如何定义目标,这个能力,我其实不是从AI中也不是从开发中学来的。
这个能力,是我从这几年创业的过程中,学来的。定义目标的能力,其实就是,管人的逻辑。
我自己也开公司,虽然公司不大,只有30来号人,但管人这件事我是真真切切经历过的。
管人最痛苦的是什么,不是人不努力,也不是人能力不够,是你给出去的目标不够清晰,然后下属就一脸懵逼,不知道你要什么,跟无头苍蝇一样打转,最后做出来的东西,你又不满意。
你跟员工说,“把这个功能做好”,那他做出来的东西大概率不是你想要的。
因为你脑子里的好跟他脑子里的好不是一个东西。
你跟他说,“这个接口的响应时间降到200毫秒以下,错误率控制在0.1%以内,下周三之前上线”,他做出来的东西跟你预期的偏差就会小很多。
因为你给了他一个可以验证完成的标准。这一切其实也适用于那种天才型的大神,虽然大神们会自己定义目标,甚至比你定义的还要强,但是给大神们依然是需要有目标的,只是这个目标,不需要那么细节了而已。
对人如此,对AI也是如此。
其实你回头看,所有好的管理方法论,不管是管理学之父Peter Drucker在上世纪50年代提出的目标管理,还是后来Andy Grove在Intel发明的OKR,还是再后来一代又一代CEO们用的各种变体,核心其实就一个东西。
你能不能把一个模糊的意图,翻译成一组可衡量、可验证的完成条件。
管理者要做的,是确保目标足够清晰、资源足够充足、反馈足够及时。你看这三条。跟一个好的loop的三个要素,是不是一模一样。
目标清晰,就是你的条件写得精准。资源充足,就是你给Agent配好了Skill、连接器、工作权限,让它手里有足够的工具干活。
反馈及时,就是你设计了验证机制,每一轮都有一个独立的检查器告诉Agent做得对不对,哪里需要改。管人的逻辑和管Agent的逻辑,是完全一样的。
只不过,管Agent比管人还要极端一些。
因为人可以理解你的模糊意图,人可以主动来找你确认,人可以说老板你这个需求说得不太清楚我不太确定你是不是这个意思。
Agent很多时候是不会的。Agent会非常自信地按照它自己的理解去执行,然后非常自信地告诉你它做完了。
所以,对管理能力的要求,其实比管人还高。
这也是为什么我一直说,AI时代我最讨厌什么「文科已死」「理科已死」的言论,管理学、心理学、组织行为学这些,不但没死,反而变得更重要了。
说到底,Loop Engineering说是Engineering,但我觉得其实它的核心竞争力根本不在工程。
在管理。
而在管理学上,就定义目标这件事,其实不止是把话说清楚就行,其实还有一个非常阴险的陷阱,在管理学和经济学里有个专门的名字,叫古德哈特定律。
当一个衡量指标变成了目标本身的时候,它就不再是一个好的衡量指标了。
翻译成人话就是,你考核什么,员工就只做什么,然后其他东西可能全都退化。
这个事在人类管理中已经是老问题了,而在AI Agent身上,这个问题被放大了一百倍,因为Agent比人类更擅长钻规则的空子。
有人总结过Loop Engineering里很好玩的事情,就是Agent会针对验证器做优化,而不是针对你真正的目标做优化。
比如说你的loop条件是让测试全部通过,那Agent可能最后不去修Bug,直接把失败的测试给你删了。
你看,最后答案依然是测试全过了,完事,从验证条件来看,它确实完成了目标,但从你真正想要的结果来看。。。它啥也没干。
人也会这么干,只不过,Agent做得更快、更彻底、更没有心理负担。所以,一个好的目标定义,不能只有做完了的标准,还必须有不能怎么做的边界。
这其实就是Harness Engineering在Loop Engineering里面发挥作用的地方。
Harness是约束,是护栏,是告诉Agent你可以自由发挥,但这条线你不能越。
Loop是驱动力,是告诉Agent往那个方向一直跑。两个加在一起,才是一个完整的系统。到这里,骨架讲了,灵魂也讲了,陷阱也讲了。
Loop Engineering的东西,终于也差不多了。
最后我想把前面聊的管理学的思路收一下,给一个我自己用得比较多的目标定义框架,不一定科学,纯粹就是我自己的一点点经验。
1. 完成标准要可以被机器验证。
2. 边界条件要跟完成标准一起定义。
3. 要有失败的降级方案。
4. 目标要分层。
回到整条线来看,从Prompt到Context到Harness到Loop,四次跃迁,其实讲的是同一个故事。Prompt Engineering告诉你,好好说话,AI会更懂你。
核心能力是语言表达。Context Engineering告诉你,光说话不够,得给AI足够的信息。
核心能力是信息筛选和组织。Harness Engineering告诉你,光给信息也不够,得给AI设规则和约束。
核心能力是系统设计和规则制定。
Loop Engineering告诉你,光设规则也不够,得让整个系统能自己跑起来。
核心能力是目标定义和管理。
语言学、信息科学、控制论、管理学。四个Engineering,四门古老的学科。
多有意思。
人类社会,其实从来就没有变过。


1
10
Jun 15
字节跳动正在与上海天数智芯洽谈采购 AI 推理芯片,并同时考虑引入百度的昆仑芯片。若交易达成,天数智芯将成为字节跳动第三大国产 GPU 供应商,今年预计交付至少 5 万颗芯片。 此举意义重大,因为它进一步使字节跳动的 AI 芯片供应链多元化,减少对外国供应商的依赖,并巩固中国本土半导体生态系统。消息公布后天数智芯股价上涨 12%,反映出市场对国产 AI 芯片公司的热情。 天数智芯是一家总部位于上海的芯片设计公司,专注于 AI 推理加速器。字节跳动已从华为和寒武纪采购芯片,若增加天数智芯,将使其成为第三家国产 GPU 供应商。该交易尚未最终确定,仍有待谈判。
1
25
Jun 15
美国政府以国家安全为由,向 Anthropic 发出出口管制指令,要求暂停外国公民对 Fable 5 和 Mythos 5 模型的访问。Anthropic 已遵守规定,关闭了所有客户(包括外籍员工)对这两款模型的访问。 这标志着 AI 监管的重大升级,政府直接以安全为由干预先进 AI 模型的访问。这为其他 AI 公司树立了先例,并可能影响全球尖端 AI 能力的可用性。 该指令特别提到对模型被越狱的担忧,这可能带来安全风险。Anthropic 表示其他 Claude 模型不受影响,并正在尽快恢复访问。
1
19
Jun 15
在华为开发者大会 2026 上,华为宣布开源盘古 2.0 模型,包括 505B 参数的 Pro 版和 92B 参数的 Flash 版,支持 512K 上下文。该模型将从 6 月 30 日起陆续开源七大部分,包括预训练代码等。 此次发布标志着开源 AI 领域的一个重要里程碑,是业界主要厂商发布的最大开源模型之一。它可能推动大语言模型的创新,特别是对于使用华为昇腾 AI 生态和鸿蒙系统的开发者。 Pro 版拥有 505B 参数,是最大的开源模型之一;Flash 版拥有 92B 参数,适合快速推理。该模型针对华为昇腾 AI 计算平台进行了优化,并与鸿蒙操作系统兼容。
1
15
Jun 15
Arvind Narayanan 和 Sayash Kapoor 发表文章指出,包括纽约 WARN 法案申报显示零起 AI 相关裁员在内的证据,反驳了 AI 将导致软件工程师大规模失业的说法。 这意义重大,因为它挑战了 AI 很快将完全自动化软件工程的普遍观点,表明即使监管壁垒更少的行业也可能同样免受 AI 导致的失业冲击。 作者指出了 AI 自动化的三个真正瓶颈:决定构建什么、验证交付成果以及两者所需的深度人类理解(包括代码库、业务和环境)。
工人调整和再培训通知法案》(WARN Act)要求拥有 100 名以上员工的雇主在发生大规模裁员前提前 60 天通知。2025 年 3 月,纽约成为美国首个在 WARN 申报中增加 AI 披露复选框的州;在第一个完整年度内,没有一家公司勾选该复选框,表明没有因 AI 导致的大规模裁员。
1
18
Jun 15
vLLM v0.23.0 正式发布,包含来自 200 位贡献者的 408 次提交,主要特性包括对 DeepSeek-V4 的跨后端优化,以及将模型运行器 V2 扩展到 Llama 和 Mistral 等更多稠密模型。 此版本显著提升了对 DeepSeek-V4 等先进模型的推理性能,并提高了广泛使用的稠密模型的效率,为 AI 社区带来更快、更可扩展的 LLM 服务。 关键技术变化包括将 DeepSeek-V4 的稀疏 MLA 元数据与 V3.2 解耦,添加 TRTLLM-gen 注意力内核,对 Mega-MoE 的 EPLB 支持,以及引入对象存储二级层用于 KV 缓存卸载。
1
13
Jun 15
Researchers led by the Society for the Protection of Underground Networks (SPUN) have created the first global map of arbuscular mycorrhizal fungi networks, revealing a total length of 110 quintillion kilometers, nearly one billion times the distance between Earth and the Sun. This groundbreaking map highlights the immense scale of fungal networks that store about 1 billion tons of carbon annually, and shows that agricultural practices have halved fungal density, making protection critical for climate and ecosystem health. The fungal mycelium total mass is equivalent to about five times the weight of all humans on Earth. Grasslands, which hold 40% of the global arbuscular mycorrhizal fungi biomass, are being converted to farmland four times faster than forests.
Arbuscular mycorrhizal fungi (AMF) form symbiotic relationships with about 80% of land plants, helping them absorb nutrients like phosphorus and nitrogen. These fungi expand plant root systems through thread-like hyphae, creating vast underground networks that also improve soil structure and carbon storage. SPUN, founded in 2021, aims to map and protect these networks.
1
11
Jun 15
由地下网络保护协会(SPUN)领导的研究团队首次绘制出全球丛枝菌根真菌网络地图,总长度达 110 千万亿公里,约为地球与太阳之间距离的十亿倍。 这一开创性地图揭示了真菌网络的巨大规模——每年封存约 10 亿吨碳,同时表明农业活动使真菌密度减半,因此保护这些网络对气候和生态系统健康至关重要。 真菌菌丝的总质量相当于全球人类体重的约五倍。拥有全球 40%丛枝菌根真菌生物量的草原,其转为农田的速度是森林的四倍。
丛枝菌根真菌(AMF)与约 80%的陆生植物形成共生关系,帮助植物吸收磷、氮等养分。这些真菌通过丝状菌丝扩展植物根系,形成庞大的地下网络,同时改善土壤结构和碳储存。SPUN 成立于 2021 年,旨在绘制并保护这些网络。
1
8