
PM²; capital markets and tech/media/entrepreneurship; leave your mark: annotote.launchrock.com #DYODD #NIA
Joined February 2015
- Tweets 50,269
- Following 622
- Followers 3,436
- Likes 62,899
7,531 Photos and videos










Pinned Tweet

16 Mar 2020
Naisbitt once said “We're drowning in information but starved for knowledge.”
58% now suffer fm info overload -- so Annotote’s knowledge network gives highlights of everything u need to read and lets u annotate anything u want to save or share.
Do it >>> annotote.launchrock.com
2
5
30
…but alas (nbcnews.com/tech/tech-news/d…):
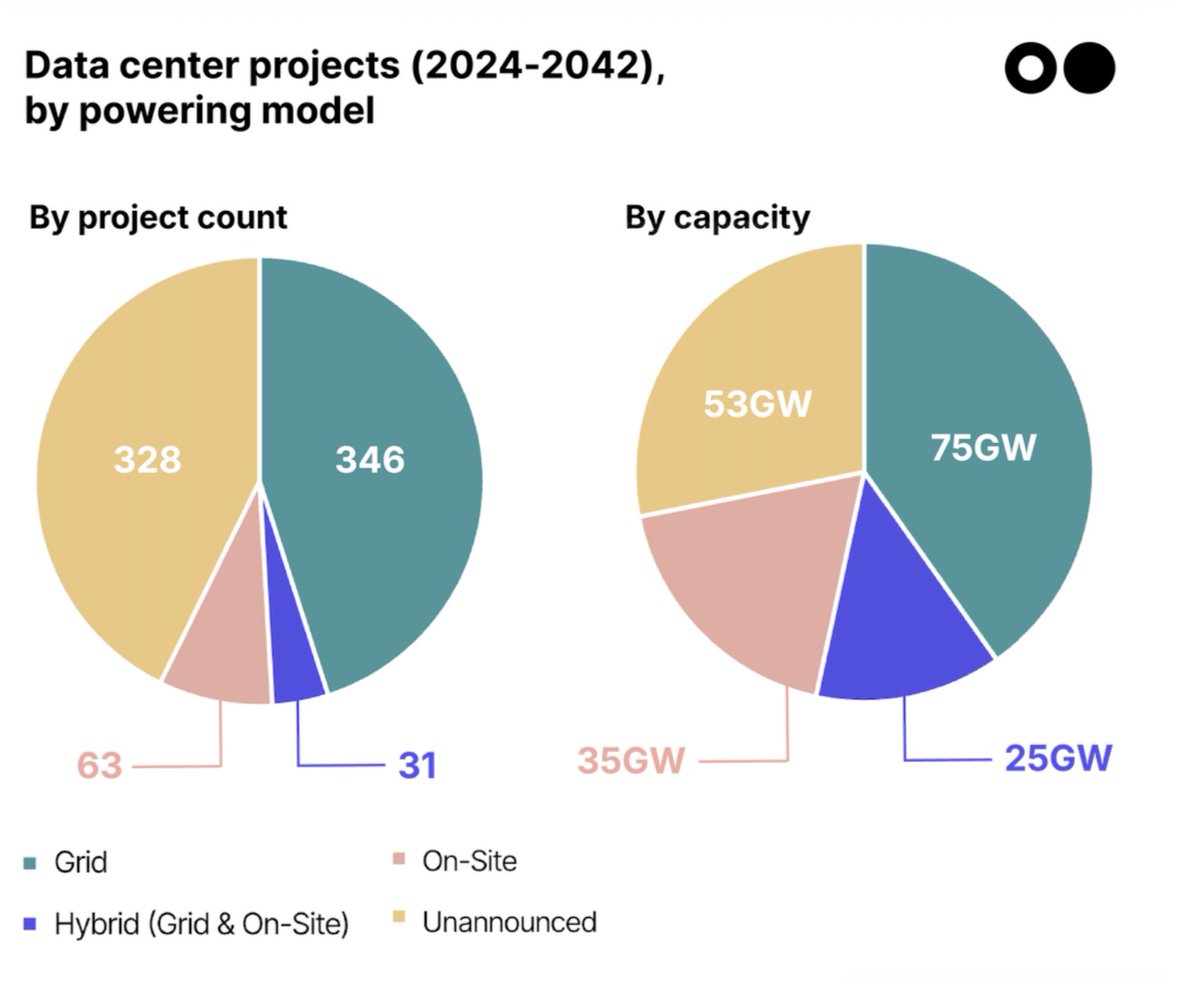
❌ datacenter opponents in US have blocked or delayed at least 75 projects worth nearly $130B in 2026q1 alone (~equal to 2025CY total)
🙅 number of active opposition groups more than doubled to 833 across 49 states
1
1
16
…related:
Apr 6

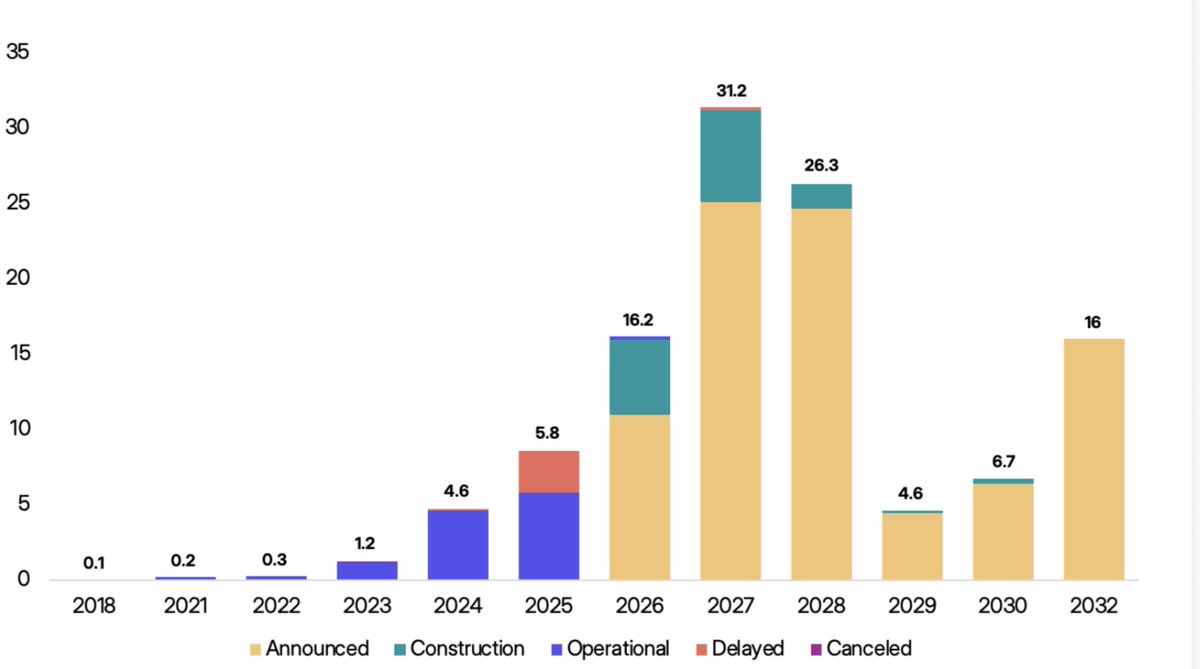
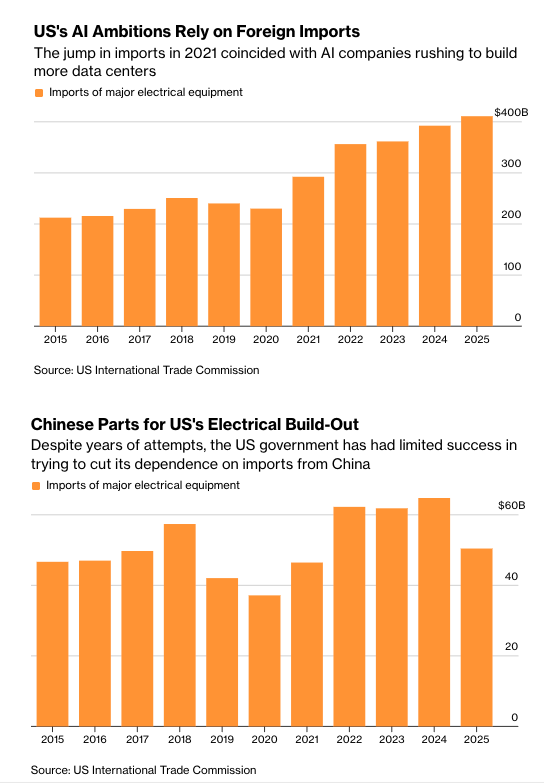
…re datacenter construction delays from supply chain shortages and bottlenecks:
🛠️ 30–50% of 2026CY datacenter pipeline unlikely to come online before 2026YE (vs 36%¹ in 2025CY)...
↳ 16GW announced for 2026CYe (140 projects total)
🟰 5GW currently under construction
➕ 11GW announced but not started
⚡️ "shortage of electrical equipment, such as transformers, switchgear and batteries… not enough domestic capacity to go around [so imports]… Electrical infrastructure adds up <10% of the total cost of the datacenter, but it’s impossible to build the operation without it"²
__
¹"in 2025, 26% of expected capacity slipped, and another 10% of projects pushed back their commercial operation dates without much notice" (sightlineclimate.com/researc…)
²bloomberg.com/news/features/…

1
6
Why did he get smaller between 13 and 23 years old…?

1
151
Anthony Bardaro retweeted
Answering straight up, without nuance or qualification (e.g. Continuous Learning #CL would completely blur line between training and inference)…
1️⃣ What percentage of current AI cloud revenue and semi demand is lab training?
Training 30~50% of current AI cloud revenue/spend (and 40~60%) of leading-edge GPU demand rn.
Inference is majority of ongoing workloads and is growing faster, ~½ of AI compute in 2025 and ~⅔ in 2026.
2️⃣ What percent of forward views of demand are driven by lab training?
Training demand consensus declining rapidly, with 20~40% 2026-27e growth, falling LDD/HSD thereafter, because Ship of Theseus model improvements elongate major new model release cadence (e.g. fine-tuning/post-training/RAG on smaller cheaper runs rather than training 100B parameter models from scratch).
Inference estimates 70~90% of total AI compute by 2030.
3️⃣ How much of this training demand is required if the future is enterprises doing post-training on open source models?
Widespread open source adoption could cut overall training compute ~50% maybe, but already 76% of enterprise LLM users leverage some open source, which is constrained rn (e.g. data quality, talent, final-mile optimization).
4️⃣ How much inference capacity is unlocked if all this old training capacity is repurposed for inference?
Substantial, maybe 30~50% of current high-end GPU capacity, already reflected in most analysts' capex models.
6️⃣ How do inference demand projections change if on-device inference takes off (like Apple bulls think with new Siri AI)?
Edge inference ~70% share in certain segments, if successful at scale (privacy, latency, zero marginal cloud cost) – offsets some hyperscaler revenue but doesn't kill enterprise/cloud use cases needing massive context or heavy compute.
7️⃣ Is GPU, CPU, and memory demand constant across workloads? How do they vary?
Training is GPU-heavy (high parallel FLOPS/HBM memory) and lower CPU.
Inference varies, with GPUs dominant; CPUs increasingly prominent for orchestration, preprocessing, agentic, RL; and memory critical for KV cache (DRAM/HBM) and storage (NAND/SSD).
Agentic and enterprise workloads usually increase CPU:GPU ratios in favor of CPU.
8️⃣ How important is latency for the majority of future enterprise workloads (low if agentic)?
Latency matters but usually secondary for many enterprise/agentic cases. More here: x.com/i/status/2054976988775….
.
.
.
1️⃣0️⃣ Are memory requirements for NAND and SSD also constant? How do they vary?
Training needs massive storage for datasets/checkpoints.
Inference varies – high for large context windows/KV cache (but often in DRAM); lower for cached/static models; RAG/vector DBs boost SSD/NAND demand; while enterprise on-prem may increase local storage needs vs cloud.
1️⃣1️⃣ What % of future enterprise open-source workloads will be on-prem vs cloud? How does that compare vs today?
Hybrid, with on-prem share 30~60% (e.g. sensitive/regulated workloads).
May 14
Underappreciated how people/businesses/enterprises will be running agentic AI workloads ambiently overnight – load balancing everything from compute to energy…
Somehow also underappreciated how much demand for AI tokens during business hours – latency and inference speed will always matter for huge swath of market…
1
3
265
Google gonna recycle every redeemable device every human has ever owned, then harvest it for compute and memory – no more buying back your user cell phones, smartphones, and computers to refurbish and resell them lol, cuz now they AI clusters…
$googl

We’re going to absorb every single piece of compute humanity has ever made and not destroyed
Don’t throw away your old computers or phones—please—very few appreciate how valuable all of this is
1
206
"ammm, sir, why do you have 10 cell phones...?!"

Fan sneaked tequila into the stadium in a flask disguised as a mobile. Mexicans are light years ahead of us.
2
286
Anthony Bardaro retweeted
"Richie's" has no right to be such a hard ass, given he's the heir of a slush empire…
Jun 13

The bar in the background used to be called The Purple Shamrock.
Every Saturday, the worst people in Boston (myself included) would show up here. We’d drink 17 Long Island ice teas, throw up in a corner, get in a fight over nothing, and then try to take home some chick named Tammy-Lynn from Medford.
Tammy-Lynn had a lower back tattoo of barbwire with a rose in the middle, smeared MAC eyeliner, and a Parliament hanging out of her mouth. She dropped out in 10th grade, would probably try to stab you if she had too many Jagerbombs (her favorite), but in the glow of the streetlights in Faneuil Hall, she was a goddess.
Before for getting in a cab back to her place, her juice head ex boyfriend shows up. Richie’s wearing a wife beater, gold chain, a Von Dutch hat and asking “you wanna die, mutherfucker?!”
Deciding not to risk you life for an unstable 6, you head back into the bar. One more Long Island can’t hurt.
Welcome to Boston. Beautiful culture.
1
5
1,158
…after US government's Anthropic Claude Fable/Mythos export ban, increasing likelihood that:
1️⃣ regulation of AI starts with KYC, which can be facilitated at OS level (keychains/passkeys/wallets/fingerprints/Face ID/etc)
2️⃣ and once you have KYC standard for digital tech, seems obvious that'll necessitate NHI, facilitated in tech stack¹ (repo/devops/devsecops/cybersecurity/datacenter/infrastructure)
3️⃣ plus KYC/AML are building blocks to expand into social media regulation, which imma not call a slippery slope, but national digital privacy act increasingly important (ZKP/DID/etc), with heed toward first and fourth amendment
__
¹x.com/i/status/2011298718155… #ID #1A #4A
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
3
125
See, that's not Landon Donovan, that's @bchesky…

Landon Donovan hairline is the real comeback story of the World Cup 😂

1
452
Jun 12
The Musketeers¹ showed up – SpaceX $spcx got its IPO pop and Elon's the world's first trillionaire…
¹x.com/i/status/1526278088648… #musketeers #elon

2
251
May 29
...same energy:
" $spce up 50% because wsb said its most likely typo when ppl trying to buy SpaceX ipo… and you care about fundamentals" (x.com/i/status/2060132059687… $spcx)
May 28

SPCE up 50% because wsb said its most likely typo when ppl trying to buy SpaceX ipo
And you care about fundamentals
1
1
1,064
Jun 12
Jun 11

$SPCE 28% today and 74% YTD. Most obvious and easiest shitco space trade of the year and I completely didn’t even think of it.
1
217
Jun 9
Can somebody please explain to me how a gas station charging $4.25 ( 15% premium) can survive next to another gas station that charges $3.65…?
Fwiw, it's almost always the Exxon Mobil $xom that's most expensive vs local entrepreneur that's price undercutting – which is another fascinating economies (diseconomies) of scale question…
1
2
275
Jun 6
Jun 6

Wemby you are one bad second half away from being to KAT what Chet was to you.
1
473
Jun 6
…related:
x.com/i/status/2061176300430…
May 31
Insane how fast life comes at you in professional sports, NBA, etc – one week ago, Chet Holmgren thought he got drafted into a young dynasty where he'd spend the rest of his career; and this morning he's trade bait for Giannis because wemby is a unicorn…
#okc #thunder
202
11 Nov 2024
They're going to run Ivanka (and Jared?) for President in Election 2028, aren't they...?!
#Trump
1
2
298
Jun 5
…Democrats are going to run Hunter Biden for president in 2028, and the stupidest outcome is him beating GOP candidate Ivanka Trump, ergo MAGA Republicans have to outstupid stupid and run Don Jr
x.com/i/status/2062626852045… #Election2028

He mastered this app in 72 hours in a way I haven’t been able to do in almost 9 years
All you can do is tip your cap
1
392
Jun 5
Hitting a round-ball with a round-bat (baseball) might be the most difficult act in all of the major American sports, but hockey players are the most talented in aggregate – not even particularly close imho:
sure, linebackers (football) and 7-footers (basketball) are freak athletes; but what the NHL does for 84 games, on skates, on ice, stickhandling an erratically prone disk, in traffic, at high speed, with opponents hanging all over them, while trying to knock-your-block-off… is a miracle on the scale of "it's unbelievable that humankind actually achieved this"…
#skill
1
122
20 Oct 2017
1⃣Series C crunch
2️⃣De facto deregulation
3⃣sustaining unsustainable disruption (not creative, just destruction)
4⃣wealth concentration
1
Jun 5
…not to zag, but re the whole "companies staying private longer; startups going public after hoarding all their growth as private businesses; depriving Americans of IPO stonks that share the upside with the investing public":
1️⃣ supply shortage of publicly traded US stocks (e.g. Wiltshire <5000 and buybacks) amidst accelerating financialization¹
2️⃣ amm, look at excess returns for the past ~20 years while you've been bellyaching about VC/PE/founders hoarding gains
3️⃣ nothing anomalous about the aggregate number or dollar volument of IPO new issuance over this stretch (except, again, net supply due to accelerating repurchases)
__
¹x.com/AnthPB/status/19681653…
17 Sep 2025
…fwiw, I've previously referred to this increasing financialization's (combine with passive investing's) impact on the income/financial asset contingency a "macro proxy"¹ and "endogenous investor demand/flows"²:
¹x.com/AnthPB/status/15240547…
²x.com/AnthPB/status/15241573…

1
17
22 Feb 2022
"UN Security Council permanent member veto power..." 🙃
as the United Nations Security Council hosts an open session on Russian conflict in Ukraine...
x.com/i/events/1495913256111… #putin
1
4
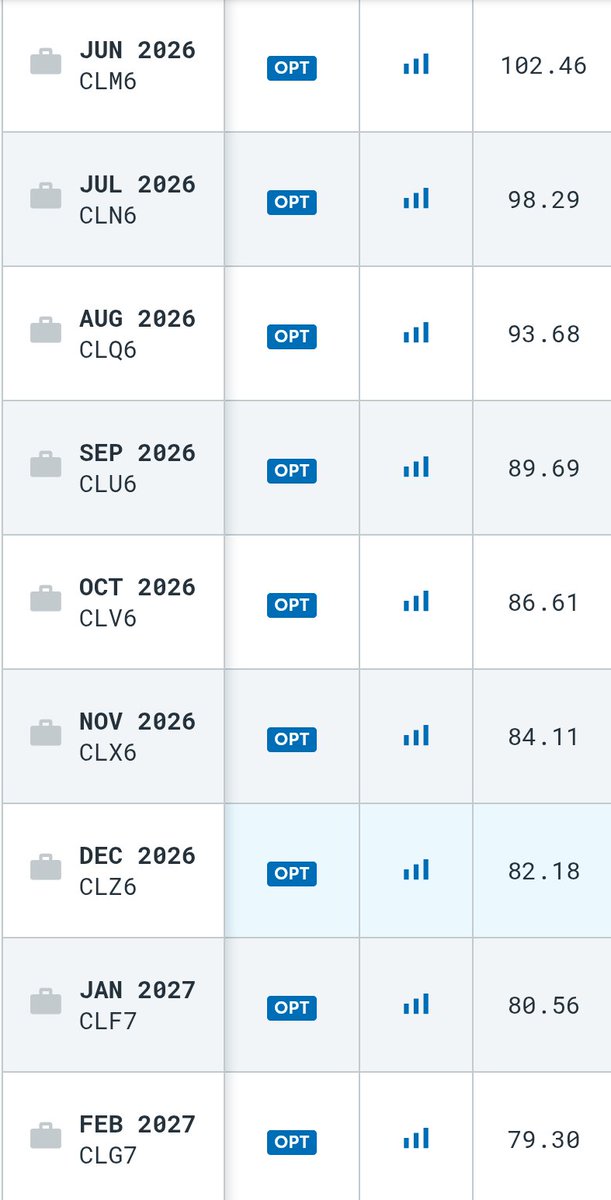
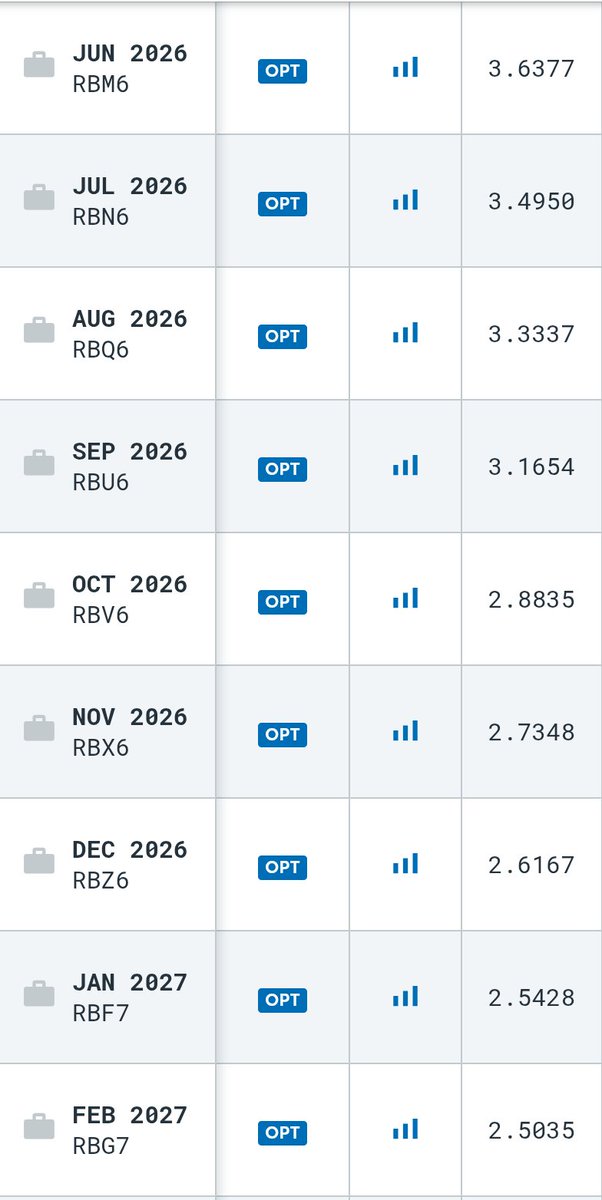
May 15
…if Trump/Xi China summit¹ didn't make headway in Iran War resolution, rn is kinda a diplomatic airpocket for opening Strait of Hormuz
…inventory tank bottoms in June, so oil and gas futures curve in backwardation should rerate – forcing extra spicy TACO
__
¹nytimes.com/2026/05/14/world… #brent #rbob $brn $bz $wti $cl_f $uso $rb_f #gasoline
1
1
302
Jun 4
…Congress is in session (apnews.com/article/iran-war-…):
"The House for the first time Wednesday approved a war powers resolution that would halt the US military action against Iran, defying President Donald Trump as a handful of Republicans joined with Democrats [in a vote tally] 215-208, but next steps are uncertain…
"The resolution next goes to the Senate, where four Republican senators last month joined Democrats in advancing a similar measure [for which it] has yet to take a final vote to approve or reject its own war powers resolution… Trump would likely reject any measure from Congress to limit his commander-in-chief authority. Still, the tally, with four Republicans joining Democrats, was a rebuke of the president’s war strategy, and cheers erupted in the House chamber…
"While Congress has the authority under the Constitution to declare war, the president also has power as the commander in chief to engage in military action, creating a legal dispute over which branch of government has ultimate say in matters of war and peace. If Senate joins the House to approve the resolution, it could set the stage for a fresh legal test… Under the war powers act, the White House has a 60-day window to seek approval from Congress for military action. The administration, however, has indicated that because a ceasefire has been declared in the current conflict in Iran, the hostilities have ceased."
1
165
18 Jun 2021
"Mark Cuban calls for more stablecoin regulation after trading DeFi token [$titan] that crashed to zero..."
#crypto
17 Jun 2021

BREAKING: Mark Cuban calls for more stablecoin regulation after trading DeFi token that crashed to zero bloomberg.com/news/articles/… $TITAN
2
3
Mar 19
…here's the Trump SEC crypto regulation and security laws¹ – kinda skirts Howey Test tbh:
1️⃣ most coins and tokens are digital commodities (e.g. $btc $eth $sol etc)
2️⃣ NFTs are digital collectibles
3️⃣ stablecoins
4️⃣ obvious securities (token-wrapped equity)
5️⃣ mining and staking aren't securities (PoW/PoS)
6️⃣ ICOs can be securities (primary public offerings to non-accredited or institutional investors), but secondary trading has many loopholes (exempting exchanges)
__
¹bloomberg.com/opinion/newsle…


1
2
179
Jun 3
…Joe Weisenthal @stalwart 🎯 – "12 reasons why it's the coldest crypto winter ever" (x.com/i/status/2061871118042…):
1️⃣ The crypto drawdown is happening at a period of rising anxiety about dollar
2️⃣ If you're in crypto, you can no longer plausibly say things like "we're so early"
3️⃣ Crypto twitter is dead
4️⃣ Institutional adoption already happened, removing any future tailwinds
5️⃣ The regulatory environment is already about as favorable as it gets
6️⃣ The AI boom is crowding out access to electricity (a crucial input for miners)
7️⃣ Crypto…was all over the Epstein Files
8️⃣ concern about quantum computing [breaking] Bitcoin's security model
9️⃣ DAT companies (like Strategy $mstr)… are now sellers rather than buyers of crypto…
1️⃣0️⃣ AI is taking up all the mental market share…
1️⃣1️⃣ people are making so much money [in stonks]
1️⃣2️⃣ [Zcash $zec has already won this downturn]
Jun 2
12 REASONS WHY IT'S THE COLDEST CRYPTO WINTER EVER
Back in February I wrote a list of 10 reasons why this the worst crypto winter ever.
Well everything I cited then still holds, but now I have 2 more ways it's gotten worse:
From the newsletter bloomberg.com/account/newsle…



1
119
12 Oct 2024
> re: x.com/elonmusk/status/184490…
Elon, would be cool for you (or your spox) to maintain a webpage to track/audit your own predictions – would be a useful self-audit and counterspeech to this exhaustive list of your missed deadlines and broken promises: elonmusk.today/

For my time-based predictions, I generally aim for the 50% percentile date, which means that half my predictions will be late and half will be early. The press never mentions the predictions that were early, so it seems like I’m always late.
However, it is very rare that a prediction I make does not come true over time.
1
1
505
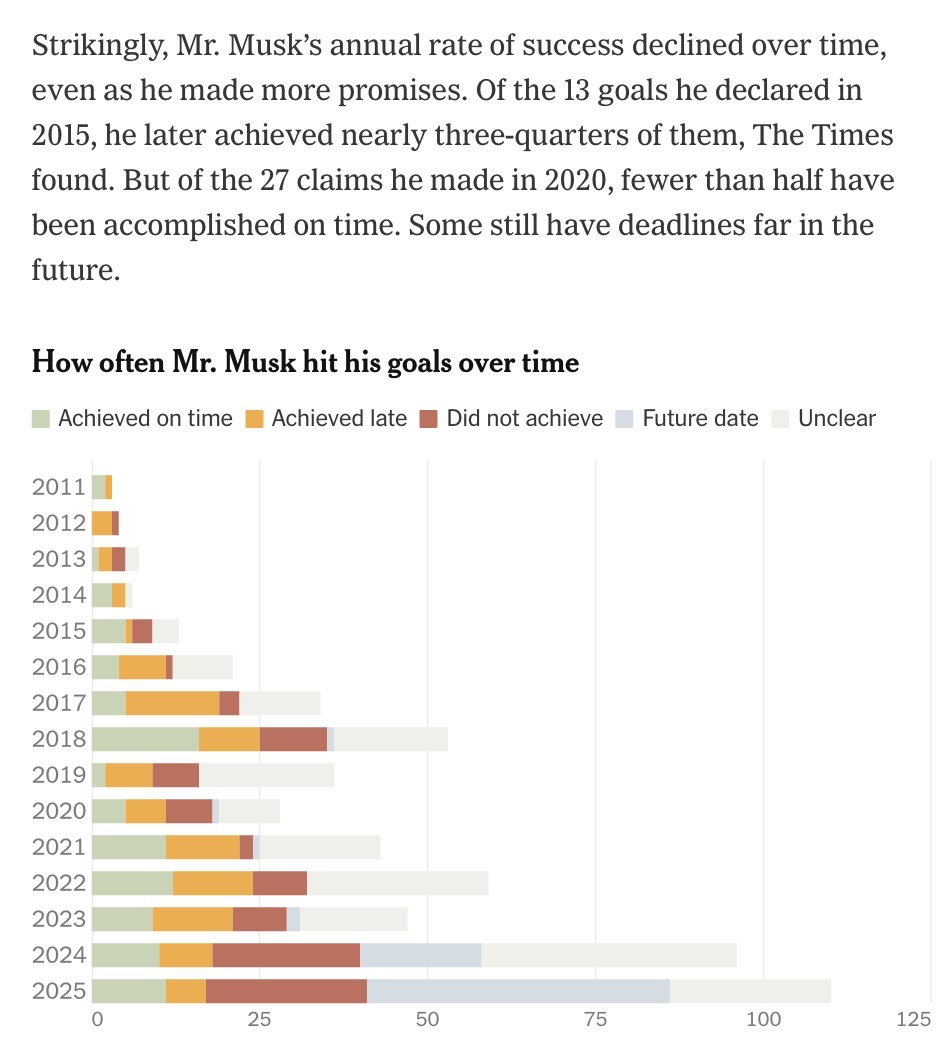
Jun 2
…NYT went ahead and did an infographic about this¹ – tracking Elon Musk's promises and deadlines for on-time, late delivery, misses, etc²:
"Elon Musk laid out 602 goals and we counted how many he hit… Strikingly, Mr. Musk's annual rate of success declined over time, even as he made more promises. Of the 13 goals he declared in 2015, he later achieved nearly three-quarters of them, [but] of the 27 claims he made in 2020, fewer than half have been accomplished on time. Some still have deadlines far in the future."
__
¹x.com/i/status/1845171556667…
²nytimes.com/interactive/2026…
12 Oct 2024
…afaik, Elon usually overpromises, underdelivers, over time, and over budget – but at least he ships (and ships big ideas/innovations), usually, I guess, idk:
x.com/AnthPB/status/18451686…
1
2
61