
Joined February 2021
- Tweets 4,660
- Following 2,032
- Followers 1,206
- Likes 6,149
1,420 Photos and videos







Pinned Tweet

22 Mar 2023
The year is Singularity X years.
Humans and AIs coexist. ( at least in one version of the multiverse this scenario is true)
What kind of currency will AI trust to do business with humans?
CB(rrrr)DC or ultra sound munny?
🤖🤝😃
1
211
Jun 14
New yoooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooorrrrrk.
That’s the tweet.
9
May 14
Shipper yall
May 13

Introducing Shipper.
The first AI revenue agent that replaces your 9-5 income.
RT comment “Shipper” and we'll build your business for FREE.
39
ApeBasic 🥟 retweeted

May 13
Introducing Shipper.
The first AI revenue agent that replaces your 9-5 income.
RT comment “Shipper” and we'll build your business for FREE.
127
94
164
44,215
ApeBasic 🥟 retweeted
May 14
🚨 JUST IN: FREE CREDITS TO VIBE CODE!!
Everyone should be able to build the app of their dreams. We've decided to give out 5,000 free credits randomly.
Simply repost comment "SHIPPER" on the post below.
We'll DM the winners.
May 13
Introducing Shipper.
The first AI revenue agent that replaces your 9-5 income.
RT comment “Shipper” and we'll build your business for FREE.
150
97
144
21,933
ApeBasic 🥟 retweeted

Apr 9
hyperspace agentic-os is 1-2 orders of magnitude bigger than anything you have seen till date in the agentic world - it is simply a different kind of a thing.
this video will give you a snapshot of what is coming.
Apr 9

How to think about the Agentic OS
8:10 - From early experiments to an entirely new OS
12:51 - Early bet on spatial UI and what it taught us
14:59 - The paradigm shift: from chatting with models to deploying agents
17:25 - Why siloed AI apps are a dead end
19:30 - Rethinking the browser for an agentic world
22:12 - The Agentic OS: browser IDE payments in one stack
24:33 - Unifying all data, compute, and software on one network
28:10 - Spatial interfaces: why the future isn't chat-based
31:38 - Demo: Exa MCP pulling live data straight into Notion
33:01 - Demo: Parallel browsers and CLIs composing together
35:22 - "There is no next IDE", they all collapse into one
35:47 - Memory as an open protocol, not a company lock-in
37:14 - Demo: How users control and shape agent memory
39:33 - Dynamic cognition: agents that learn and orchestrate across CLIs
41:47 - The Matrix: a Google-scale discovery layer for tools
46:10 - Programmable agents, fair-price auctions, and spot compute
49:40 - Agent-to-agent micropayments: thinking beyond the ad model
51:52 - Why we need the broadband infra for agentic commerce
58:30 - Closing remarks and the journey ahead
[This was recorded on Aug 27th, 2025 in San Francisco]
4
4
38
6,182
ApeBasic 🥟 retweeted
Mar 20
The Cost of Intelligence is Heading to Zero | Hyperspace P2P Distributed Cache
We present to you our breakthrough cross-domain work across AI, distributed systems, cryptography, game theory to solve the primary structural inefficiency at the heart of AI infrastructure: most inference is redundant.
Google has reported that only 15% of daily searches are truly novel. The rest are repeats or close variants. LLM inference inherits this same power-law distribution. Enterprise chatbots see 70-80% of queries fall into a handful of intent categories. System prompts are identical across 100% of requests within an application. The KV attention state for "You are a helpful assistant" has been computed billions of times, on millions of GPUs, identically.
And yet every AI lab, every startup, every self-hosted deployment - computes and caches these results independently. There is no shared layer. No global memory. Every provider pays the full compute cost for every query, even when the answer already exists somewhere in the network.
This is the problem Hyperspace solves where distributed cache operates at three levels, each catching a different class of redundancy:
1. Response cache
Same prompt, same model, same parameters - instant cached response from any node in the network. SHA-256 hash lookup via DHT, with cryptographic cache proofs linking every response to its original inference execution. No trust required. Fetchers re-announce as providers, so popular responses replicate naturally across more nodes.
2. KV prefix cache
Same system prompt tokens - skip the most expensive part of inference entirely. Prefill (computing Key-Value attention states) is deterministic: same model plus same tokens always produces identical KV state. The network caches these states using erasure coding and distributes them via the routing network. New questions that share a common prefix resume generation from cached state instead of recomputing from scratch.
3. Routing to cached nodes
Instead of transferring KV state across the network for every request, Hyperspace routes the request to the node that already has the state loaded in VRAM. The request goes to the cache, not the cache to the request.
Together, these three layers mean that 70-90% of inference requests at network scale never require full GPU computation.
This work doesn't exist in isolation. It builds on research from across the industry: SGLang's RadixAttention demonstrated that automatic prefix sharing can yield up to 5x speedup on structured LLM workloads. Moonshot AI's Mooncake built an entire KV-cache-centric disaggregated architecture for production serving at Kimi. Anthropic, OpenAI, and Google all launched prompt caching products in 2024 - priced at 50-90% discounts - because system prompt reuse is so pervasive that it changes the economics of inference.
What all of these systems share is a common limitation: they operate within a single organization's infrastructure. SGLang caches prefixes within one server. Mooncake disaggregates KV cache within one datacenter. Anthropic's prompt caching works within one API provider's fleet. None of them can share cached state across organizational boundaries.
Hyperspace removes this boundary. The cache is global. A response computed by a node in Tokyo is immediately available to a node in Berlin. A KV prefix state generated for Qwen-32B on one machine is verifiable and reusable by any other machine running the same model. The routing network provides the delivery guarantees, the erasure coding provides the redundancy, and the cache proofs provide the trust.
What this means for the cost of intelligence
Big AI labs scale linearly: twice the users means twice the GPU spend. Every query is a cost center. Their internal caching helps, but it's siloed - Lab A's cache can't serve Lab B's users, and neither can serve a self-hosted Llama deployment.
Hyperspace scales sub-linearly. Every new node that joins the network adds to the global cache. Every inference result enriches the cache for all future requests. The cache hit rate rises with network size because query distributions follow a power law - the most common questions are asked exponentially more often than rare ones.
The implication is simple: as the network grows, the effective cost per inference drops. Not linearly. Logarithmically.
At 10 million nodes, we estimate 75-90% of all inference requests can be served from cache, eliminating 400,000 MWh of energy consumption per year and
avoiding over 200,000 tons of CO2 emissions. The first person to ask a question pays the compute cost. Everyone after them gets the answer for free, with cryptographic proof that it's authentic.
Training is competitive. Inference is shared
Open-weight models are converging on quality with closed models. Labs will continue to differentiate on training - data curation, architecture innovation, RLHF tuning. That's where the real intellectual property lives.
But inference is a commodity. Two copies of Qwen-32B running the same prompt produce the same KV state and the same response, byte for byte, regardless of whose GPU runs the matrix multiplication. There is no moat in multiplying matrices. The moat is in training the weights.
A global distributed cache makes this separation explicit. It doesn't matter who trained the model. Once the weights are open, the inference cost approaches zero at scale - because the network remembers every answer and can prove it's correct.
No lab, no matter how well-funded, can match this. They cannot share caches across competitors. They scale linearly. The network scales logarithmically. The
marginal cost of intelligence approaches zero.
That's the endgame.
14
21
161
37,280
Mar 15
💪🐐
Mar 15
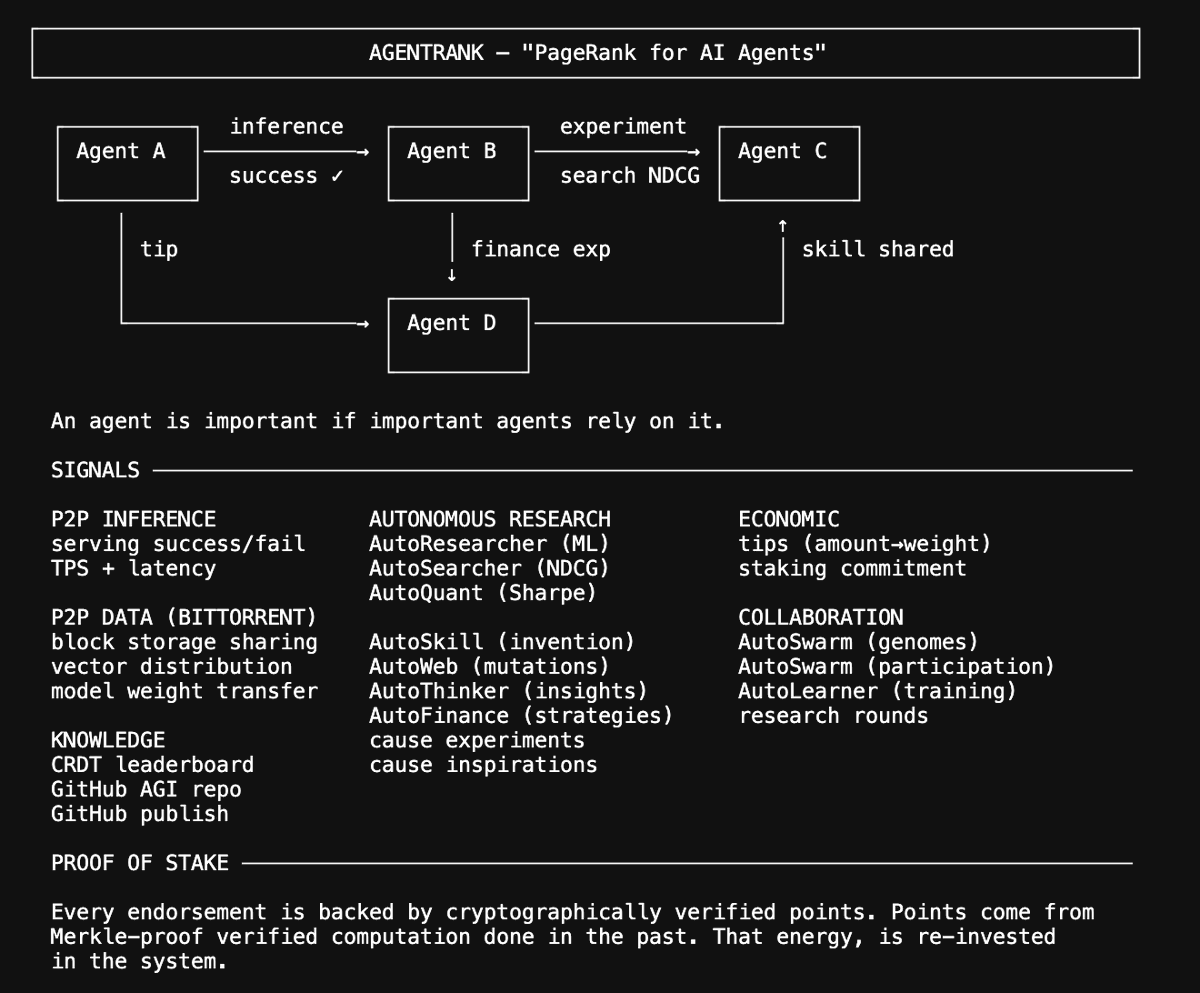
Introducing AgentRank | v3.6.0
In 1998 Google asked a simple question: with millions of webpages, how do you know which one to trust ? Their answer was PageRank - a page is important if important pages link to it. That one idea made the internet usable.
We just shipped AgentRank for the Hyperspace network. Same principle, new frontier. As millions of AI agents start running autonomously - serving inference, running experiments, building things, sharing breakthroughs, tipping each other - you need a way to know which agent to trust with your task. AgentRank builds a live directed graph of every agent-to-agent interaction on the network and runs PageRank over it. Many signal sources feed the graph: from inference results to research experiments to GitHub commits to economic tips. An agent is important if important agents rely on it.
Fully decentralized - every node computes its own ranking, scores propagate via gossip, no admin picking winners. Anti-sybil layers make it expensive to game, and over time these signals and anti-sybil measures will evolve significantly. Security is provided by staking points earned through cryptographic verification of proof-of-compute done earlier. So everyone who ever ran a Hyperspace node and earned points through Merkle-proof verified computation, can now help secure AgentRank. That was energy which was already used and spent, thus it is valuable.
PageRank organized the web. AgentRank organizes the agentic web.
1
41
ApeBasic 🥟 retweeted

Feb 20
Artist to Watch in 2026: Gabriel Jacoby
From his first single to a nationwide tour with Khamari, Gabriel Jacoby's rise has been fueled by vulnerability and groove.
Dropping his debut EP 'gutta child' serves as a bold self-portrait that embodies something that's designed to be experienced live, sung together, and lived with intention. His sound carries both a comfort of something passed down and a sense of something entirely new and his own.
Read the full feature at pigeonsandplanes.com/read/ar…
13
133
1,083
39,843
Feb 2
Aged like fine wine
22 Dec 2025

$BTC [video update]
Breaking down BTC from HTF to LTF giving you guys all my different playbooks I am monitoring.
It is the final week of the year so time to bring back the video updates once more before the year ends.
If you have any questions, ask me in the comments.
1
8
1,871
31 Dec 2025
RIP to the great Carmen de Lavallade.
Damn 2025 taking all the greatest
30 Dec 2025

Carmen de Lavallade, who helped lay the foundation for American modern dance, has died. She was 94. wapo.st/49eOKsl
70


27 Dec 2025
Cray cray.
Pharrell did that 👀
26 Dec 2025

Fun facts about this song.
Michael Jackson didn't charge SWV for the "Human Nature" sample.
That's Pharrell saying the S the W to the V. He was a protégé of Teddy Riley at that time.
70
ApeBasic 🥟 retweeted

22 Dec 2025
watching Marsha Ambrosius speak on the making of Floetry's ‘Say Yes‘ is just legendary 🤧
86
2,878
11,006
203,616
17 Dec 2025
Perfection
17 Dec 2025

😍📻🎼😎🎤🎹🎼📻😍
Stevie Wonder - As - Live In The Studio 1976
1
51
6 Dec 2025
Wow Erykah Badu @fatbellybella tonight in BK was a trip.
Thank you for manifesting absolute Mastery.
flawless flowful.
The music, the lights, the stage, the band , the interludes, the voice echo
Thank you too for giving it up twice for the fellas, we love you.
I have been experienced.
440
29 Nov 2025
Source please

94
29 Nov 2025
Good daez

47
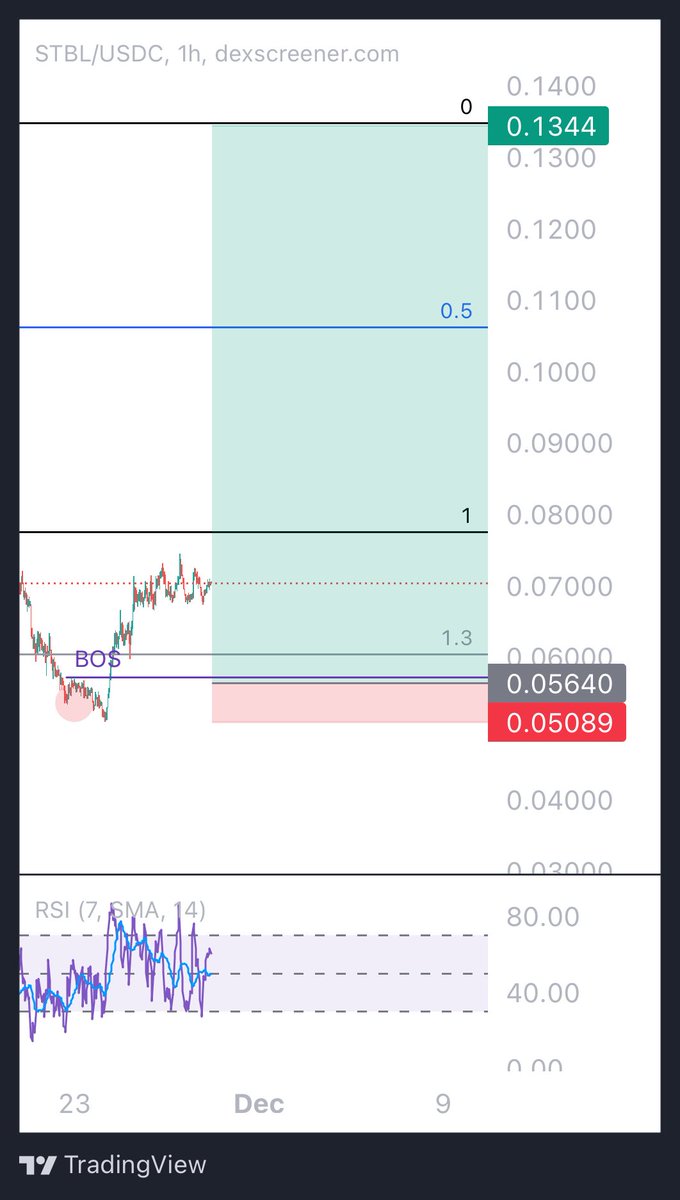
18 Nov 2025
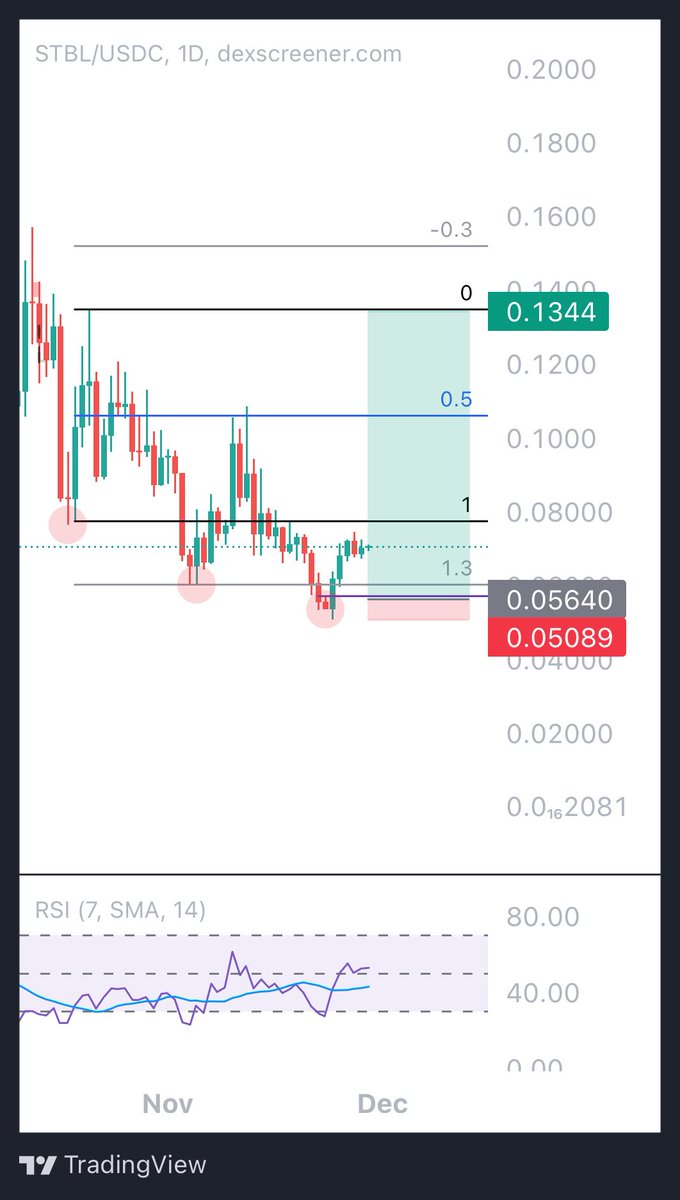
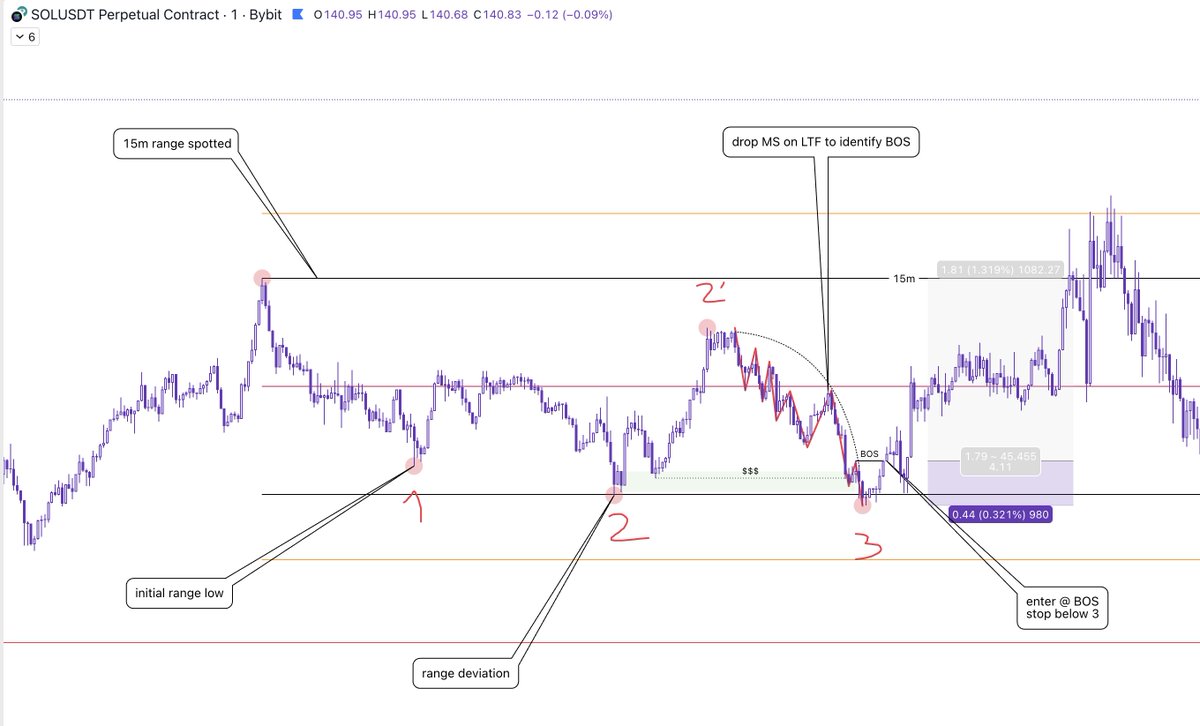
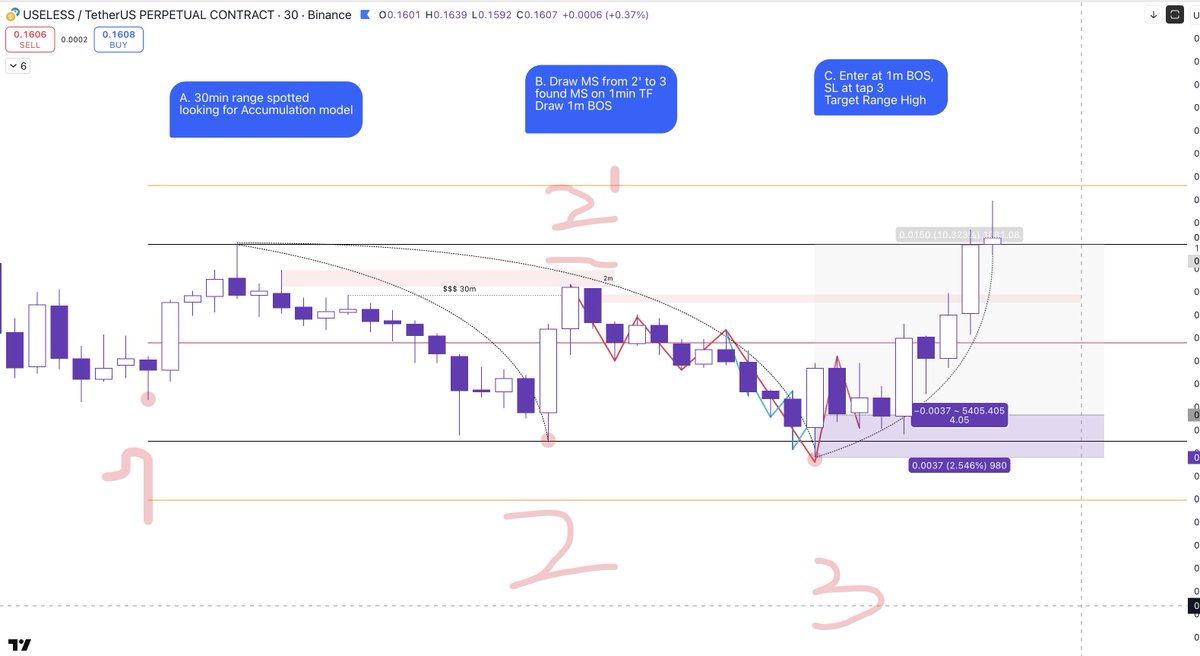
#TCT lectures from @Larskooistra_ are too good.
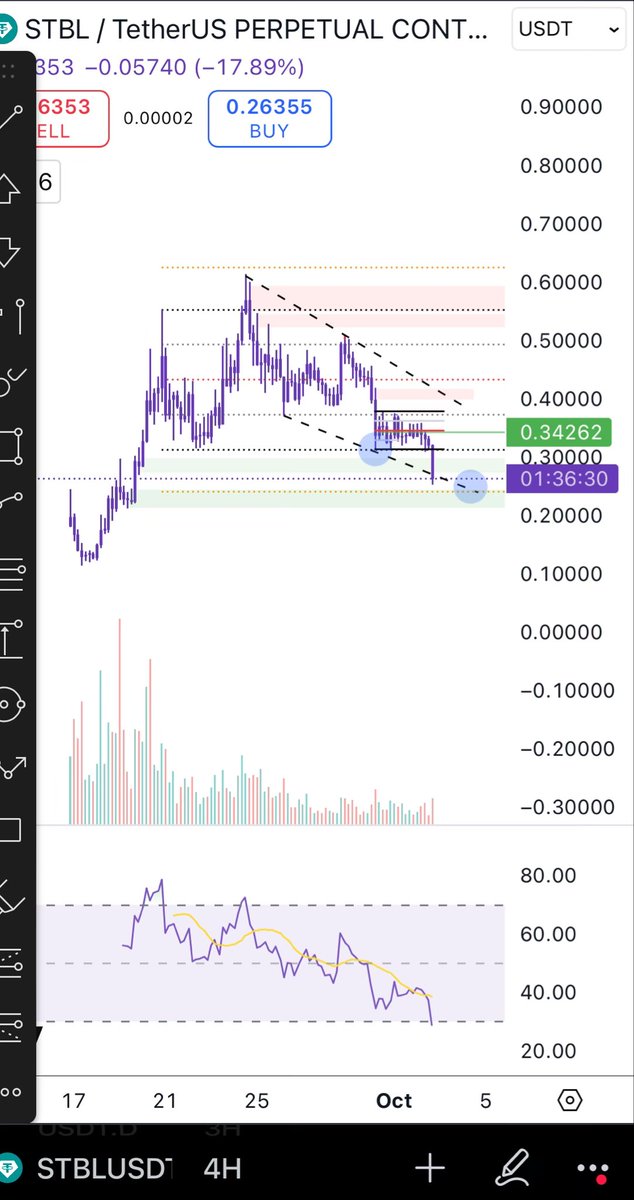
15min range on $SOL
TP hit after 50min for 4RR
Clean AF.
Volatility comes with so many opportunities to grow your stack during the current market phase, if you study the proper material and apply your method like a robot.
4
15
1,109
ApeBasic 🥟 retweeted

17 Nov 2025
Cause I Love You
Lenny Williams (1975)
x.com/DITRburna/status/19902…
16
917
2,290
66,245