
We build Specific Intelligence for enterprises.
Joined July 2012
- Tweets 170
- Following 18
- Followers 4,250
- Likes 322
36 Photos and videos














Jun 12
"A great eval needs to understand every correct answer, and every way one can go catastrophically wrong." @BrendanFoody from @mercor_ai shared with our CEO @ypatil125 how evals are deceptively the hardest part of post-training.
Our team at Applied Compute solves this by embedding with your engineers to build evals that accurately capture your specific definition of excellence.
21
2,901
Jun 11
“RL is remarkably data efficient. You can specialize a model on exactly what your business needs, with surprisingly little data.”
@BrendanFoody sat with our CEO @ypatil125 to discuss how RL flipped the equation from quantity to quality, so the proprietary data only you have can train a model no general system can match.
1
60
4,997
Applied Compute retweeted

Jun 10
2
11
46
10,089
Jun 10
After working with both frontier labs and enterprises across industries, @mercor_ai CEO @BrendanFoody joined our CEO @ypatil125 to discuss why proprietary data and custom models are what keep a company competitive at the frontier.
43
17,371
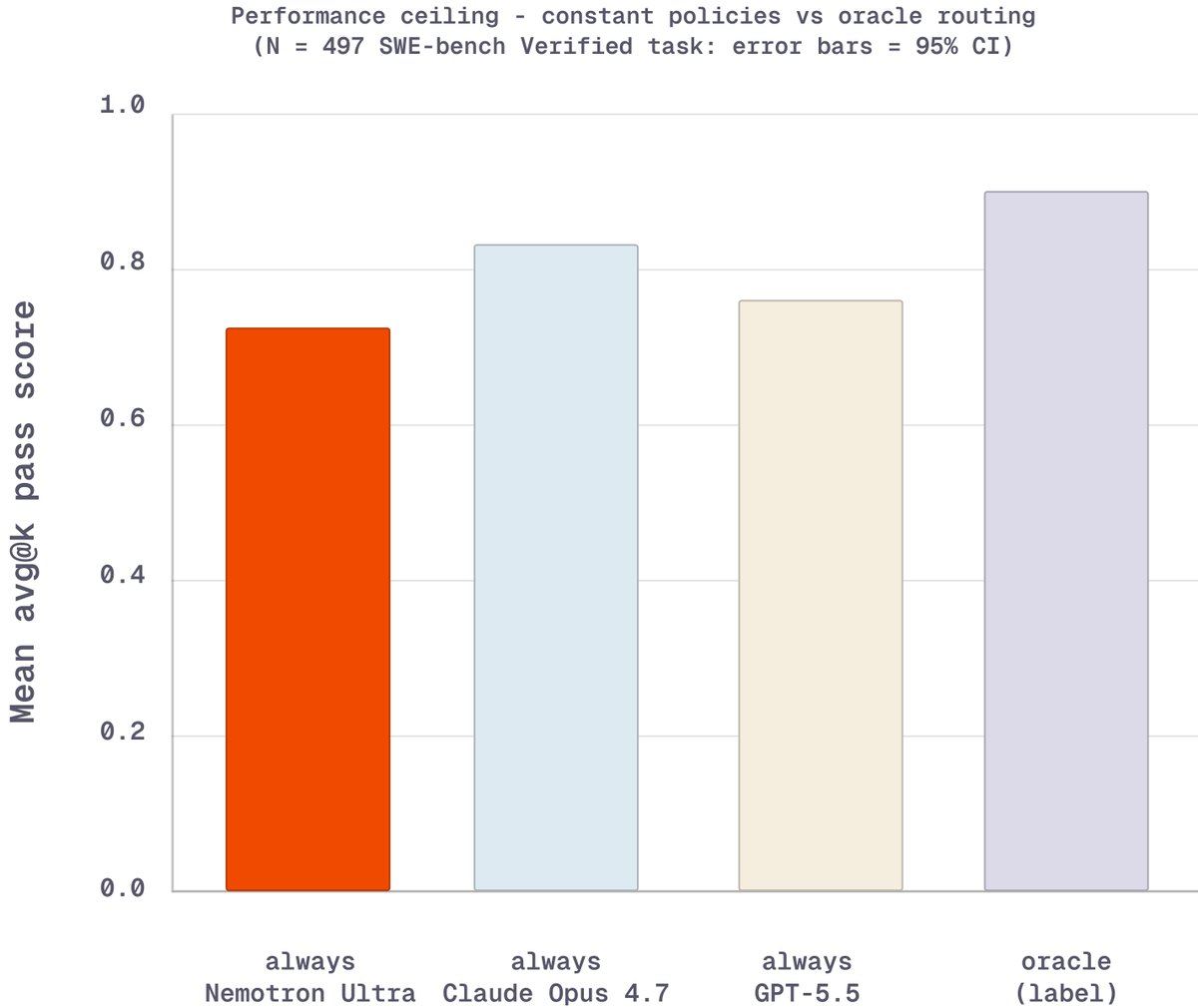
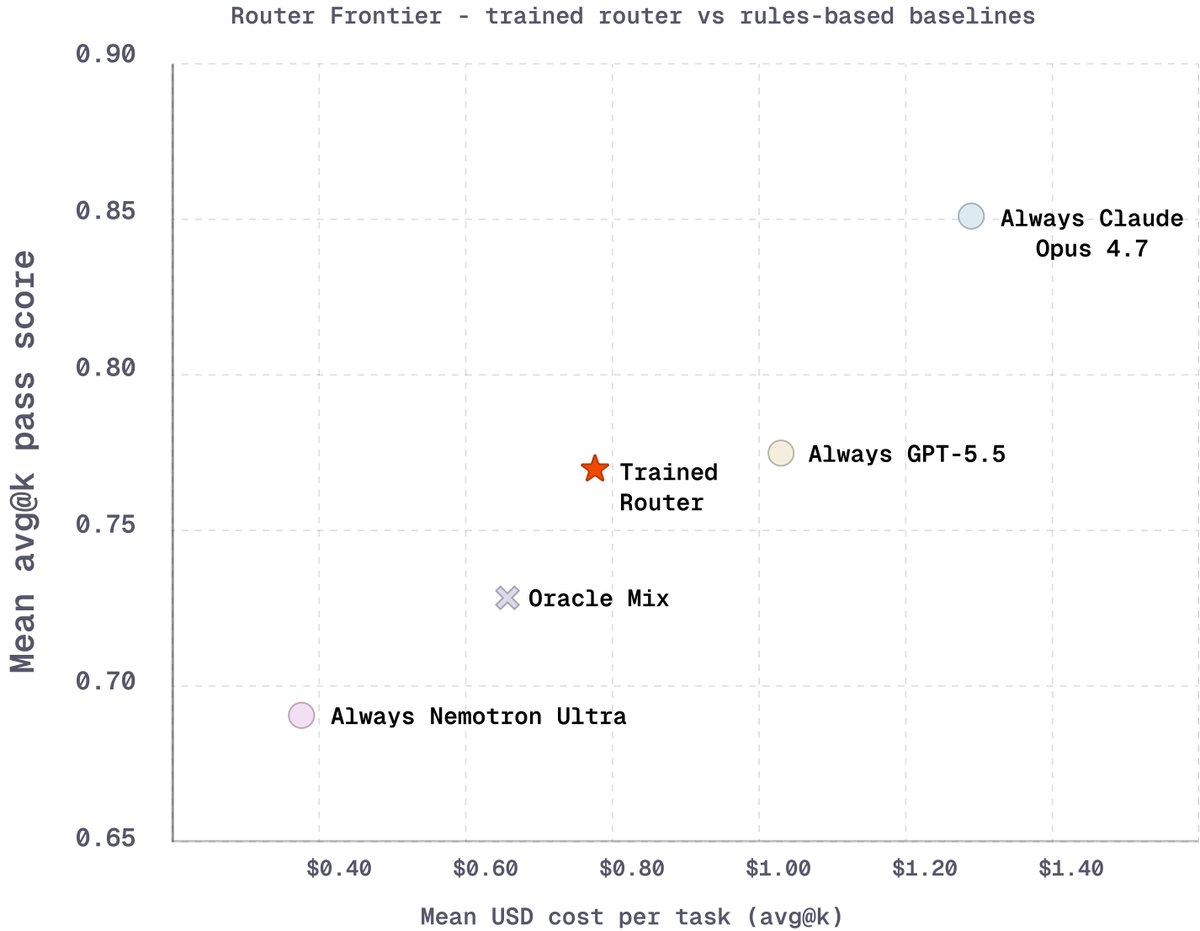
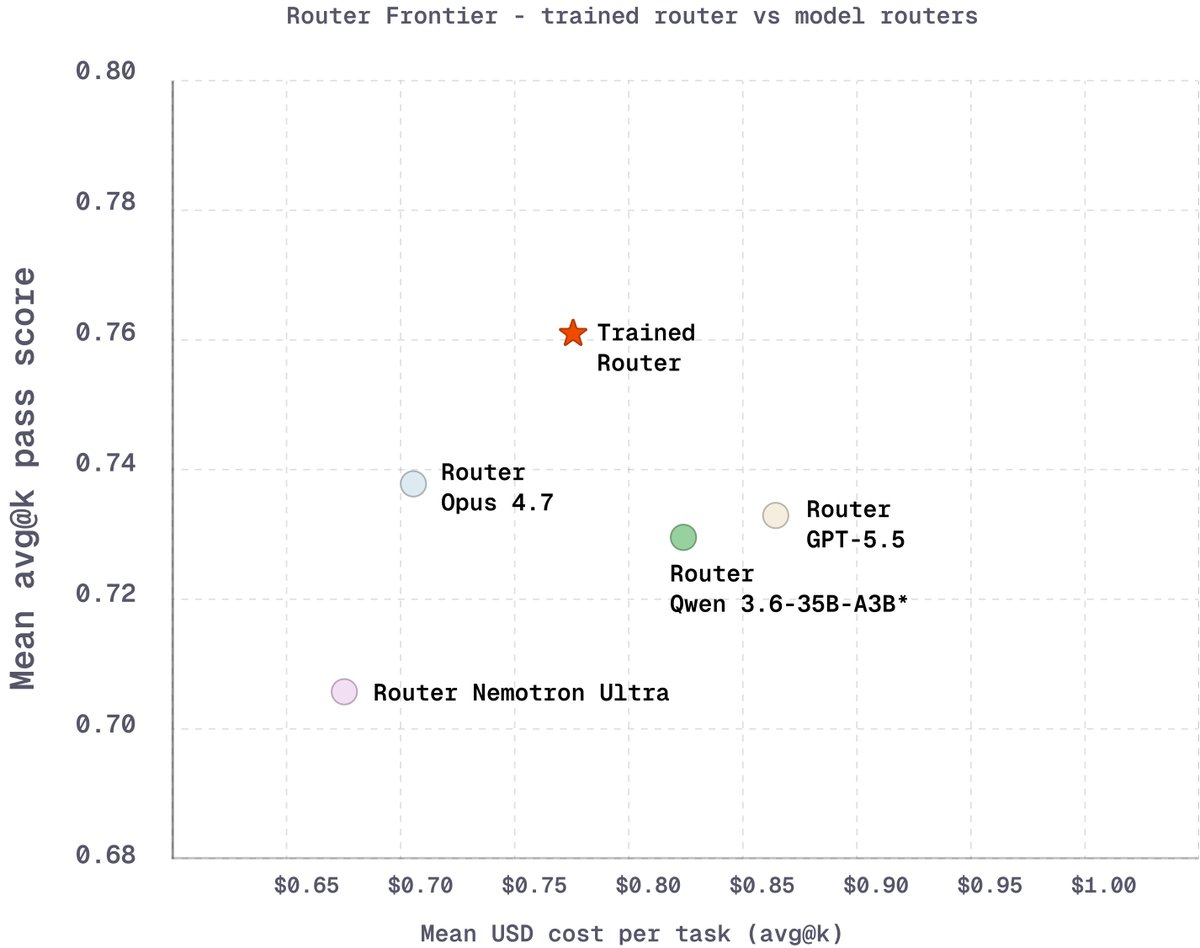
@nvidia’s Nemotron 3 Ultra handles software-engineering tasks at a fraction of the per-task cost of frontier models. So we trained a router to send each coding task to the cheapest model that can successfully solve it, cutting inference cost while holding frontier-level quality.
The result: GPT-5.5-level pass rates on held-out SWE-bench Verified at ~25% lower cost. The oracle policy sends 72% of tasks to Nemotron 3 Ultra, and the trained router captures most of that.
9
15
95
39,345
The models are complementary. The trained router sends 73% of tasks to @NVIDIAAI's efficient Nemotron 3 Ultra and routes the long tail to GPT 5.5 and Opus 4.7 on tasks where frontier performance at a premium is worth the tradeoff.
Since the router is agentic, it can call tools in a sandbox with the task codebase to match the task against each of the candidate models’ strengths and weaknesses.
1
12
1,196
Read the full research report: appliedcompute.com/research/…
10
598
No two companies are the same, even within the same vertical.
That's why generic models fall short and Specific Intelligence wins: custom models you fully own, post-trained on your data, so they get very good at the exact task you need.
Our co-founder @rhythmrg at @southpkcommons on companies owning their intelligence with Applied Compute.
1
4
42
3,226
Enterprise AI deployments today are frozen in time. Model capabilities stagnate in production. The problem compounds because companies aren’t static either. Every time your company improves, the model falls further behind.
The bottleneck is continual learning. How does a model do something once and improve from feedback?
The future of enterprise AI is Specific Intelligence: custom models teams own, trained on a company’s choices, interaction by interaction, using internal knowledge general models cannot access.
Applied Compute helps companies train, serve, own, and improve custom models. Thanks @apoorv03 for having @ypatil125 at MS&E 435 to talk about the future of model training.
3
13
45
12,002
Your data is your edge, but only if your AI is built on it. Rent a generic model and so can your competitor. The companies with an edge are deploying custom models that they own and improve over time.
Our co-founder @rhythmrg recently stopped by @southpkcommons to share how companies are owning their intelligence with Applied Compute.
2
10
66
118,789

The Redpoint InfraRed 100 is now live.
These are the companies building the infrastructure that powers everything happening in AI right now, from world models and agent runtimes to the sandboxes, databases, and security tools agents depend on.
Congratulations to this year's honorees!
Read the full 2026 InfraRed Report: our state of the union on AI and cloud infrastructure 👉 redpoint.com/reports/the-inf…

23
53
323
156,161
May 27
Applied Compute has been named to @Redpoint’s 2026 InfraRed 100, recognizing the companies shaping the future of infrastructure and AI. Congratulations to all featured this year!
1
1
33
1,880
May 22
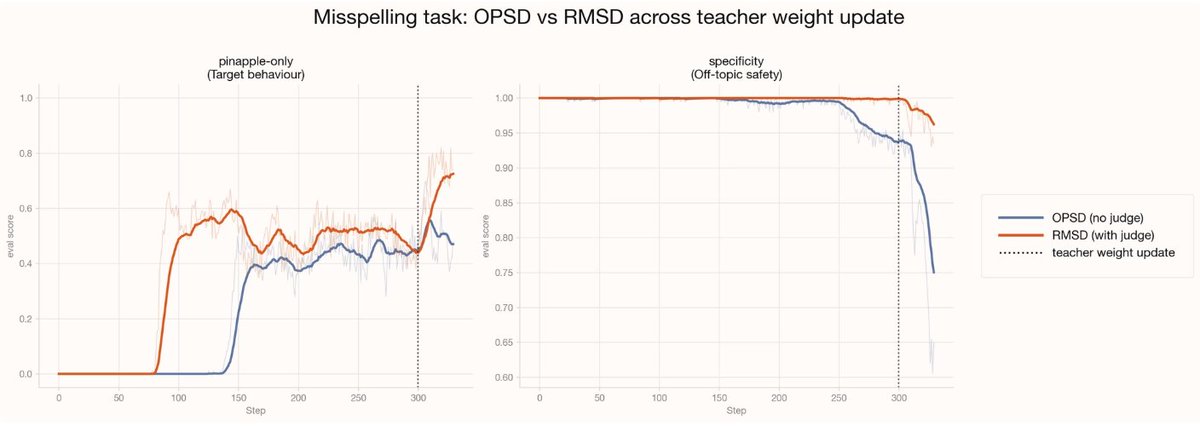
Furthermore, we find that the token-level granularity in self-distillation is both a strength and a weakness – it's dense, but there is often a great deal of noise in the updates because the teacher and student may disagree on tokens for reasons unrelated to the desired behavior. We want to concentrate our loss on the tokens which matter most for the student's improvement.
This is the intuition behind RMSD: we filter for a set of T token positions where the teacher and student disagree the most, then an LLM judge narrows those to a final set of S tokens that are most relevant to the target behavior.
In our experiments, RMSD reaches the target behavior in about half the steps of OPSD, making it significantly more data efficient, while also training more stably and reaching a higher performance ceiling.
We think that the self-distillation approach and RMSD in particular will be powerful methods for advancing the capabilities of models on specialized settings.
1
1
20
3,405
May 22
Some enterprise tasks are challenging to hill-climb with RL-based methods since they involve very out-of-distribution behavior. On-policy self-distillation (OPSD) gives a model learning signal for every token it writes, far richer than the single scalar reward of RL.
But that channel is noisy: most tokens don't reflect the behavior you're after. We introduce Relevance-Masked Self-Distillation (RMSD), which uses a two-step filtered loss mask to cut through the noise and find the tokens with the highest signal. Compared to OPSD it trains more stably, provides higher data efficiency, and reaches a higher performance ceiling.
9
26
298
85,863
May 22
Enterprises increasingly want custom models that are tailored to their internal tools and processes, without sacrificing intelligence or reliability. Often times this involves tasks that are out-of-distribution for existing models: think custom document formats that aren't on the public web or company-specific legacy APIs, things that never appeared in pretraining.
Existing techniques struggle here. SFT teaches new behaviors, but causes catastrophic forgetting. RL has no foothold: if the target behavior never appears, there's no reward to reinforce.
We investigate self-distillation as a way to elicit these OOD behaviors, using a controlled toy task as a proxy for the enterprise-internal formats we see in practice.
We find that self-distillation can:
- Better elicit OOD behaviors compared to SFT and RL
- Better preserve the model's existing capabilities
1
24
3,272