
Teaching your AI new tricks.
Joined June 2016
- Tweets 12,994
- Following 878
- Followers 310,369
- Likes 6,513
6,163 Photos and videos


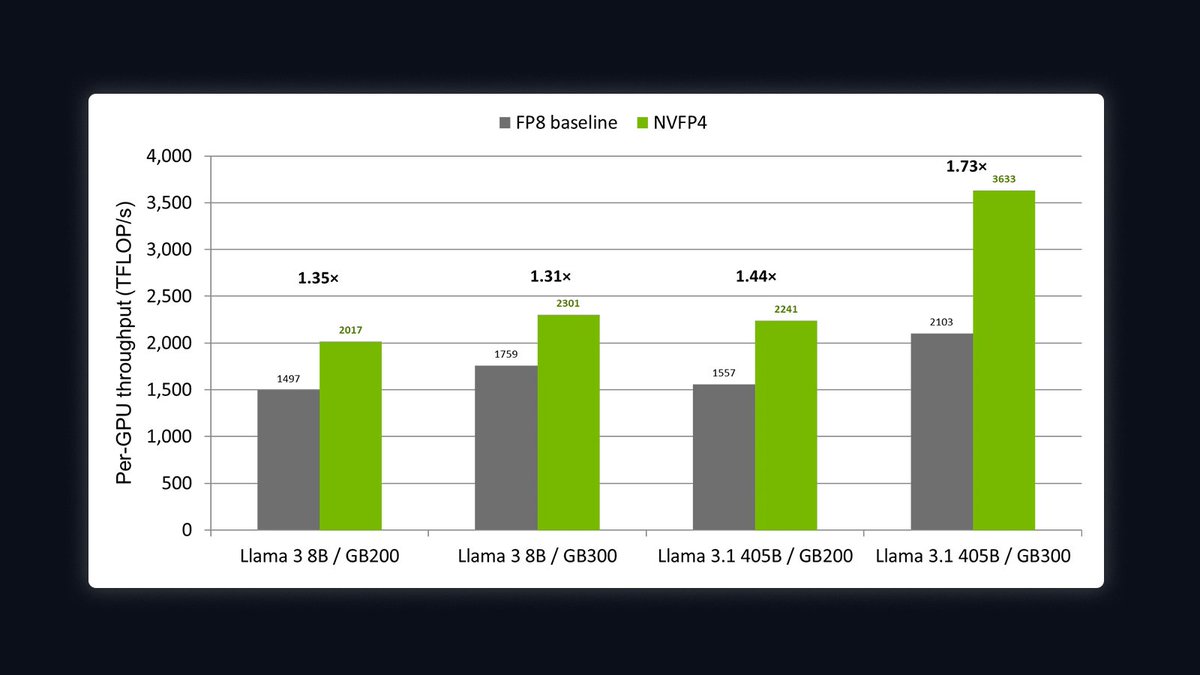




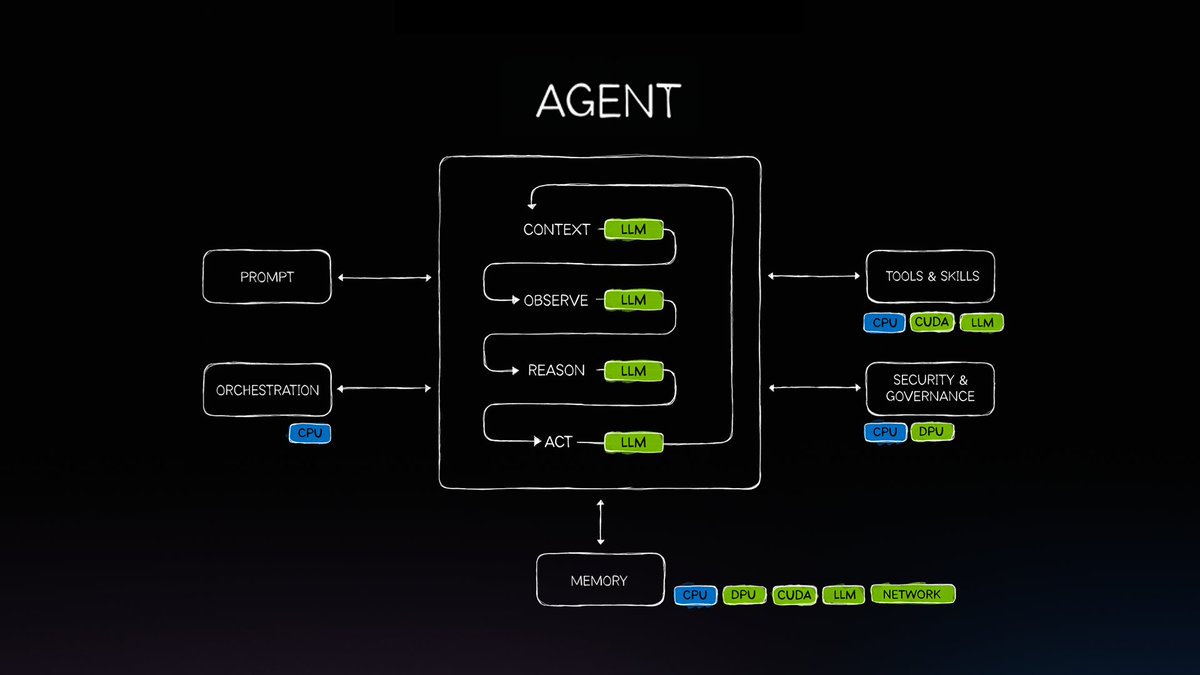








Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
199
463
3,480
1,239,855
NVIDIA AI retweeted

Jun 13
What are people using to run local inference on DGX Spark?
ollama? LM Studio? vLLM? sgLang? TRT-LLM?
Do you run in Docker?
@TheAhmadOsman @AlicanKiraz0 @spark_arena @NVIDIAAI @NVIDIARTXSpark
64
7
145
43,280
Congrats to the @MiniMax_AI team on the release of MiniMax M3, a long-context multimodal model for text, image, and video reasoning. 🙌
Try it today with our free GPU-accelerated endpoint on build.nvidia.com.
Details: nvda.ws/4v4BWhD
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
51
116
1,307
133,489
One open model. 350,000 motion clips. 15,000 FPS.
MotionBricks from NVIDIA Research runs real-time character animation at scale, without hand-crafted transitions or fine-tuning. And yes, it works for robotics too.
#SIGGRAPH2026 paper, demos code: nvlabs.github.io/motionbrick…
36
129
1,083
97,509
NVIDIA is coming to #SIGGRAPH2026 in Los Angeles 🌴
Neural rendering, world models, physical AI, hands-on labs, and more.
All the details 👉 nvidia.com/en-us/events/sigg…
2
5
49
6,214
Shoutout to Caleb for putting together a great deep dive on Nemotron 3 🙌
Check it out.
Jun 11

Nemotron 3 Full Breakdown
With the help of Joey Conway from @NVIDIAAI getting into the specifics around why Nemotron 3 is kind of a big deal
Biggest headline with Nemotron is: Hybrid Mamba Transformer, Latent MoE, and MTP
Hybrid Mamba Transformer essentially attacks right at the Attention mechanism to make the overhead sub-quadratic, but unlike quantizing KV Cache or swapping out attention head, NVIDIA chose Mamba-2
Latent MoE helps further optimize on sparsity by down projecting the dimensions so you're doing less math and less memory movement between HBM and SRAM, you're saving a ton, and NVIDIA made a conscious choice to add more experts given the surplus
Finally, MTP or multi token prediction where the model can see future tokens to be more expressive in training and also option to use for speculative decoding during inference
Oh, also the model adopts the new OpenMDW 1.1 License
13
27
322
29,287
Generate Synthetic Data for Physical AI With NVIDIA Brev Launchables and Agent Skills x.com/i/broadcasts/1MKgNNrAY…
7
11
82
5,905
Getting Started with NVIDIA Cosmos 3 for Robotics and Physical AI | Cosmos Labs x.com/i/broadcasts/1RKZzzrqY…
10
14
101
6,249
Distributed AI Inference at Scale on NVIDIA Dynamo With Gcore and Orange Business x.com/i/broadcasts/1vJpPPVLe…
7
7
56
6,984
Love seeing photos like this.
Let's see some more setups.
Curious what everyone's running these days. What models are you using and what are you building?
Jun 10

4x Nvidia GB10 128GB, 400G QSFP-DD Switch, 2x QSFP-DD 400G to 2x200G QSFP cable and @NVIDIAAI Magic🔥🦾

69
29
684
50,520

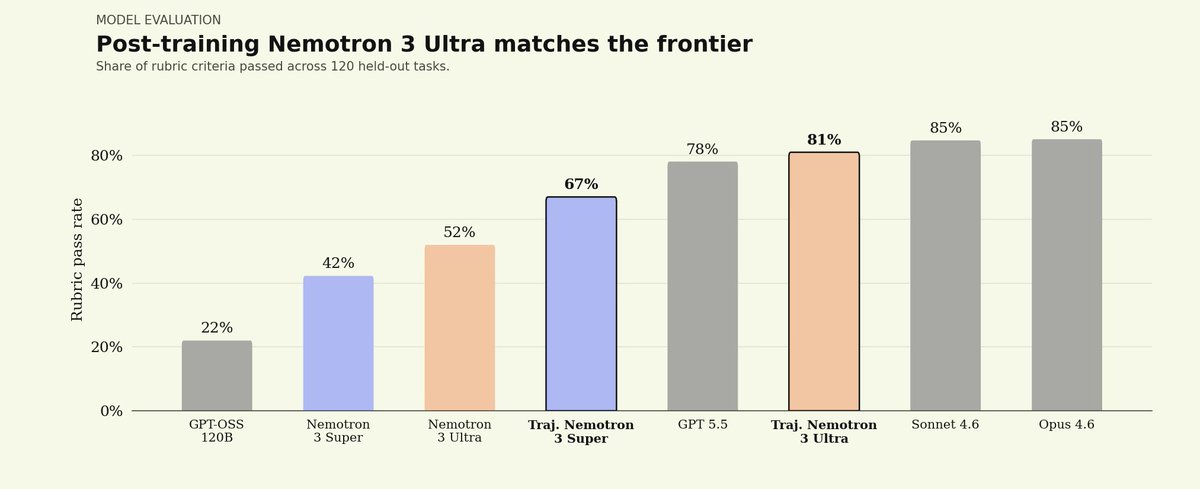
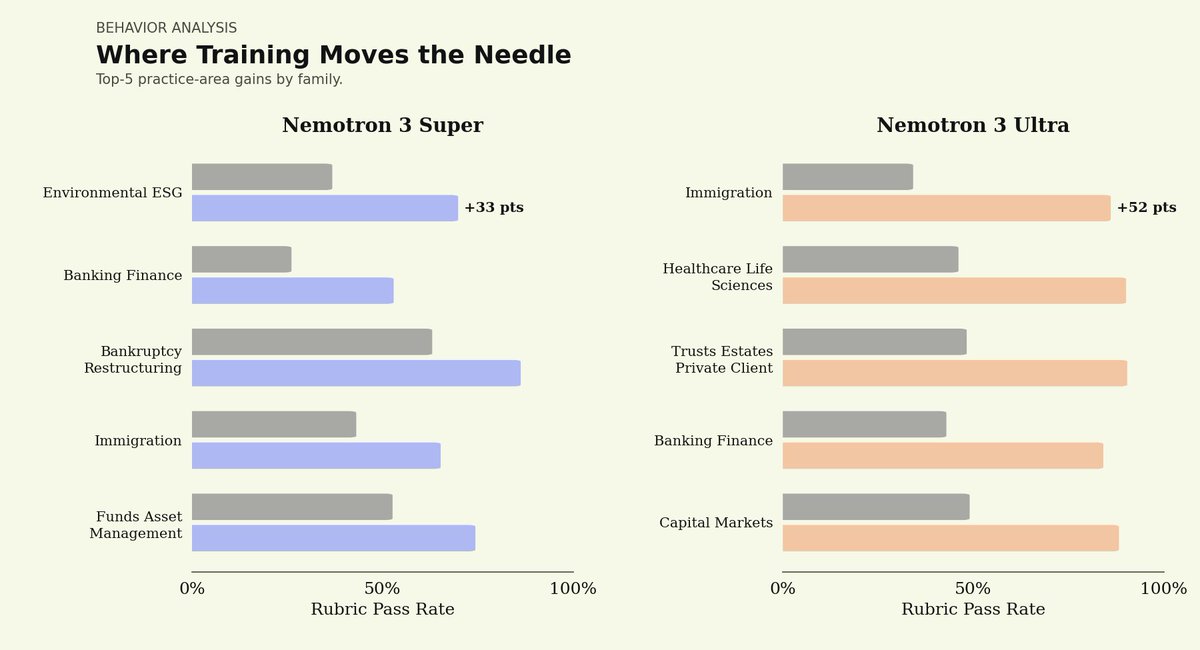
We partnered with @trajectorylabs to post-train NVIDIA Nemotron 3 Ultra for legal. Here’s what we found:
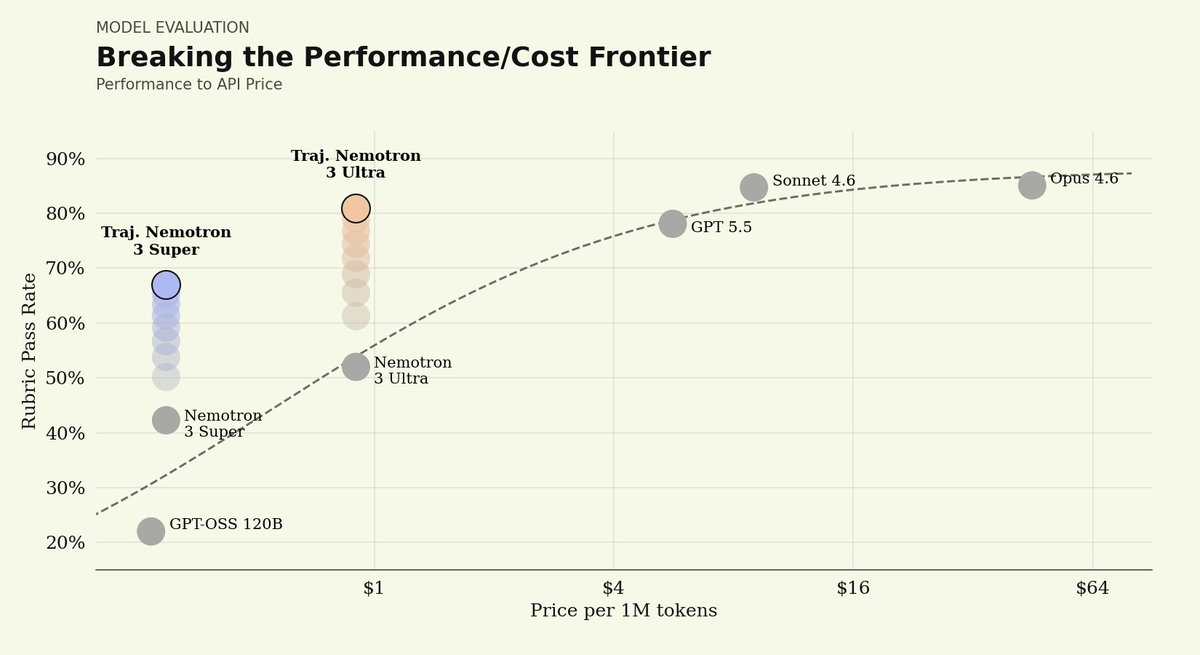
1) Open-weight models can reach frontier legal performance.
On our Legal Agent Benchmark (LAB), Nemotron 3 Ultra started at a 0% all-pass rate. After post-training, it reached 5.8%, placing it between Sonnet 4.6 at 4.2% and Opus 4.6 at 6.6%.
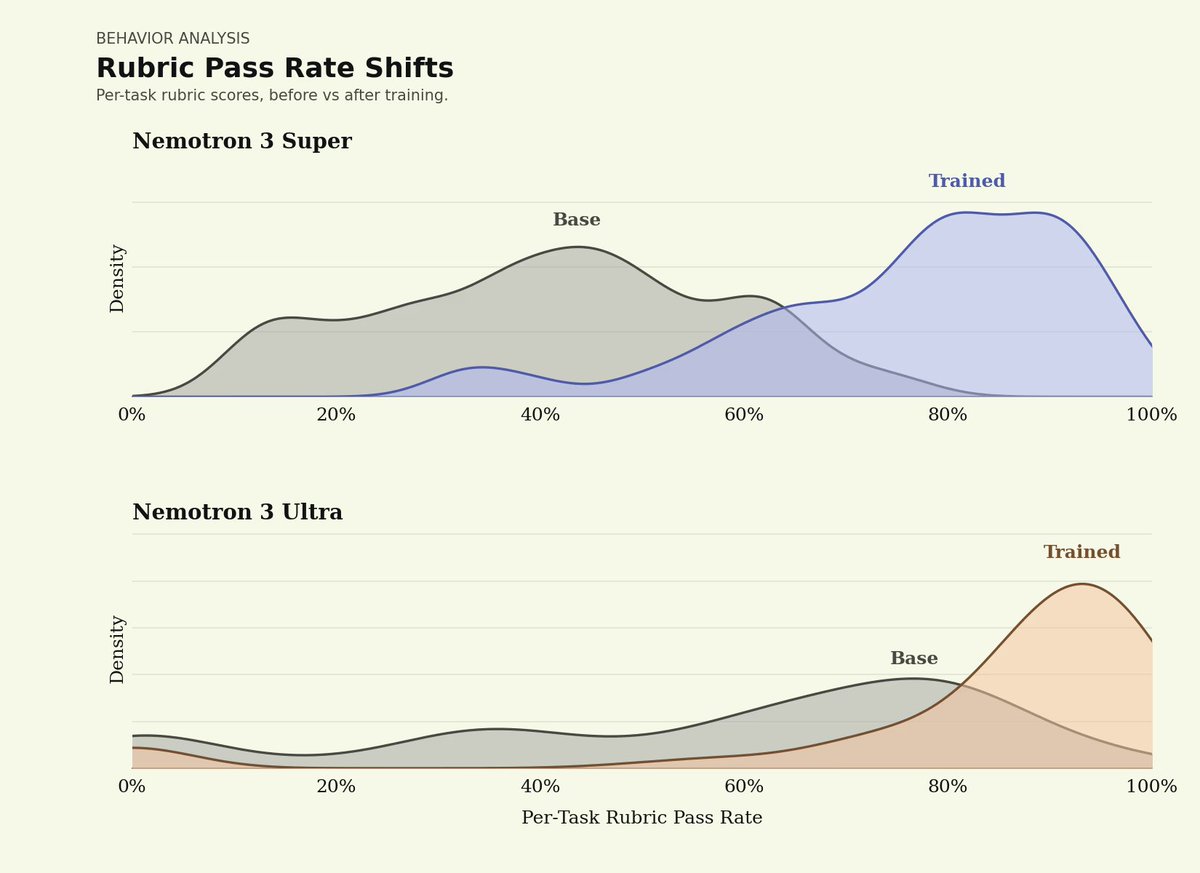
2) Post-training dramatically improves reliability.
Before training, many held-out tasks missed enough rubric dimensions to land around ~70% pass rates. After training, those tasks shifted toward ~95% pass rates.
3) Open-weight performance comes at much lower cost.
Post-trained Nemotron 3 Ultra reached a similar quality band to leading closed models while running at roughly 1/8th to 1/50th the per-token price of Sonnet 4.6 and Opus 4.6.
Most importantly: we post-trained this model on the @trajectorylabs platform less than 24 hours after Nemotron 3 Ultra launched, using the same harness, data, and recipe we used for Nemotron 3 Super.
More to come as we continue to experiment with open-weight legal agents.
Read more on post-training with Trajectory below:
Jun 10

1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.

11
30
271
46,086
Congrats to @GoogleDeepMind on the launch of DiffusionGemma.
The model generates 256 tokens in parallel per step, delivering 150 TPS on DGX Spark, and 1,000 TPS on a single H100.
We're supporting it from day one with:
• BF16 and NVFP4 checkpoints on @huggingface🤗
• Free GPU-accelerated endpoints on build.nvidia.com
• @vllm_project support with FP8 precision
Get started with DiffusionGemma on NVIDIA: nvda.ws/43ro19u

DiffusionGemma, our experimental open model released under an Apache 2.0 license, explores text diffusion, an exceptionally fast approach to text generation.
Here’s how DiffusionGemma accelerates development:
Faster token output: By shifting the bottleneck from memory bandwidth to raw compute, the model generates up to 4x faster token output on dedicated GPUs
Accessible hardware footprint: Activates just 3.8B parameters during inference, fitting comfortably within 24GB-VRAM high-end consumer GPUs when quantized
Novel workflows: Parallel token generation enables self-correction, making it ideal for code infilling, in-line editing, and non-linear structures
DiffusionGemma prioritizes speed over raw quality and accelerates best on compute-bound hardware (like @NVIDIAAI GPUs). Standard @GoogleGemma 4 remains recommended for production quality and memory-bound devices.

38
118
1,367
98,901
1
6
20
5,721
Ask the Experts: Nemotron 3 Ultra | Nemotron Labs x.com/i/broadcasts/1nxnRRyOa…
10
65
5,764
NVIDIA AI retweeted

So excited to be opening up OpenEnv to the whole community. It will now be owned by @huggingface , Meta-PyTorch, @reflection_ai , @UnslothAI , @modal, @PrimeIntellect , @NVIDIAAI , @mercor_ai , and @fleet_ai .
the reason is: frontier labs train the model and the harness together, so the model is fitted to its harness. that coupling is a chunk of why claude code and codex feel so good.
open source can't do that. you bring whatever harness, whatever model, whatever env, whatever trainer. which is the whole point of open source and also the problem for training.
openenv is the socket in between all of this.
in short: it's a protocol layer, not a reward framework. it does not have opinions about your rewards or your training loop. those live in the libs that are actually good at them.
read more in the blog post. it's early, come break it.
16
58
292
88,656
See the benchmarks, full recipe breakdown, and MaxText example 👇 nvda.ws/3QcnWU3
1
5
33
6,131
NVIDIA AI retweeted
Jun 8
.@nvidia gave us all the hardware we need to make local AI awesome.
16 x DGX Spark
3 x RTX Spark
1 x DGX Station
24 x ConnectX-7 Cables
2 x High Speed Switches
local dot AI




142
115
1,659
265,568
NVIDIA AI retweeted

May 29
5
7
31
15,397