
Open-Source AI Observability and Evaluation
Joined February 2023
- Tweets 922
- Following 315
- Followers 1,665
- Likes 1,473
212 Photos and videos









Pinned Tweet

Feb 13
Phoenix 13.0
Phoenix 13 is a major release centered around Dataset Evaluators, a new system that turns your datasets into reusable evaluation suites. This release also introduces custom model providers, OpenAI Responses API support, and dozens of Playground and experiment UX improvements.
1
3
13
1,208
Jun 12
💙 This is what we love to see.
The new OpenAI Agents SDK (TypeScript) integration for Phoenix wasn't built by us, it was contributed by Xinde Li, a software engineer at Tencent. 🙌 Thank you!
It auto-traces your agent runs end-to-end: agent steps, LLM calls, tool calls, handoffs, and guardrails as OpenInference spans in Phoenix.
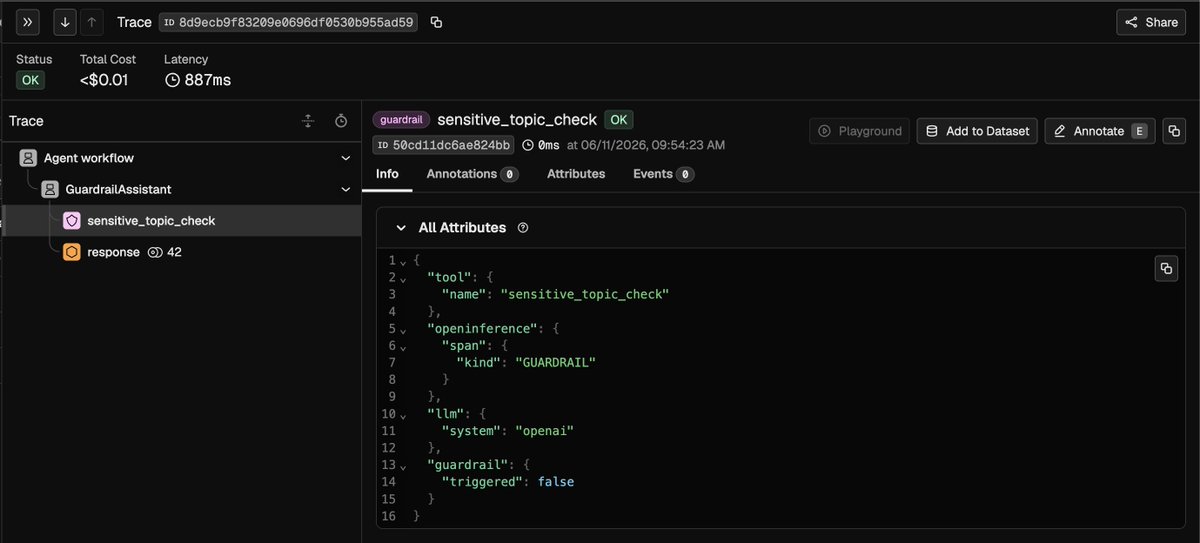
You can even see exactly when a guardrail fires (or doesn't 👇). Here's a sensitive_topic_check span: kind GUARDRAIL, triggered: false - the check ran, the content was clean, and you have full visibility either way. No code-reading required.
Get started with a single command:
npm install @arizeai/phoenix-otel @arizeai/openinference-instrumentation-openai-agents @openai/agents
📖 Docs → arize.com/docs/phoenix/integ…
1
3
232
Jun 12
This week in Phoenix, a big one for agentic workflows:
🎉 Slash commands & skills in PXI - Phoenix's built-in agent now has a user-invokable skill menu and local slash commands right in chat. Teach it your workflows, then trigger them in a keystroke.
2
1
11
1,115
Jun 12
🤖 Claude Fable 5 support , Anthropic's newest model is now available in the Playground, with up-to-date token pricing for cost tracking.
1
38
Jun 8
Phoenix just hit 10,000 GitHub stars!
Three years ago, Phoenix didn't exist. Arize was a closed-source company. A small team was asked to change that.
Catch the full interview with the team who made it happen and where AI observability is going next: arize.com/phoenix-10k
3
8
2,028
May 26
"Don't trust. Evaluate."
@nearestnabors set out to replace Claude Sonnet with Gemma 4. The evals showed a quantifiably better option.
Full walkthrough: capability evals prompt engineering to ship a local 3B that matches Sonnet, 2x faster, $0/call.
Built with Phoenix.
arize.com/blog/how-to-ditch-…
1
2
463

Our own Laurie Voss, head of Developer Relations, will be speaking at QDrant's Vector Space Day conference!
Most teams ship retrieval systems by tweaking the chunking, running a few demo queries, and calling it done. "Looks good to me" is not an evaluation strategy, but it's the one the industry has quietly agreed on.
Laurie's talk will cover the retrieval metrics that actually matter, how to build golden datasets that survive contact with reality, where LLM-as-judge helps and where it quietly lies to you, and how to wire continuous evals into your CI pipeline so regressions show up before your customers do.
Come with your skepticism. Leave with a playbook!
Vector Space Day is a full-day single-track conference for engineers at The Midway, San Francisco on June 11. Tickets at luma.com/vsd-sf

1
1
6
276
May 21
Phoenix now lets you compose evaluation strategies in code.
Most eval tooling hands you a fixed menu of judge templates. Real evaluation is rarely that tidy.
Code Evaluators enable you to build evaluation criteria the way you want. You write a Python or TypeScript evaluate() function in the Phoenix UI — no SDK, no local runtime, no deploy step — and Phoenix runs it server-side, recording labels and scores as annotations on every experiment run.
Because it's just code, you control the whole strategy:
• Composite scoring: blend sub-scores (LLM judgment deterministic rules) into one weighted metric
• Embedding-based evaluation: cosine similarity over embeddings instead of brittle string matching
• LLM juries: poll multiple models and combine verdicts into a weighted consensus
Sandboxed Code evaluators unlock the idea of agents as a judge as well. We're excited where this is heading.
youtu.be/g6LRowqujhg?si=qbhC…
2
4
7
312
May 19
The Arize DevRel team wants to connect with Phoenix users like you. What you're tracing, what's working, what's rough?
Schedule time with the team here: cal.com/team/arize-devrel/us…
119
May 15
Something we’ve been playing with and liking a lot:
Give every coding agent its own observability stack.
Because Arize Phoenix can run fully local-first and air-gapped on your computer, each coding agent can get its own Phoenix instance: its own port, its own SQLite DB, its own traces, its own evals.
That means every agent working in its own worktree can observe what it did, inspect its traces, run evals against its changes, and use that feedback loop to self-verify before handing work back.
A private loop for every agent:
code → trace → evaluate → improve → verify
This makes it possible to scale many coding agents locally without cross-talk, shared state, or interference between neighboring work.
The bigger idea is that agents should not just generate work. They should be able to measure and validate their work continuously.
Local-first observability makes that practical.
2
2
6
186
May 14
A comprehensive 2-hour evaluations workshop, for free!
At AI Engineer: Europe, head of DevRel Laurie Voss gave this workshop that covers:
- What is an eval?
- Why are they important?
- How and why to manually examine the data
- Using built-in Phoenix evals
- Writing custom evals
youtube.com/watch?v=Xfl50508…
1
2
10
1,259
May 14
Phoenix 15.5 → 15.7
🏷️ Note identifiers for upsert semantics (15.7)
POST /v1/{trace,span,session}_notes accepts an optional identifier; repeat writes overwrite in place. This is what makes notes safe to write from automation — a nightly evaluator keyed by identifier="qa-bot-v3@<id>" re-runs idempotently.
Closes the asymmetry with annotations, which already had this semantics.
⌨️ Bulk annotation delete px project get (15.7)
When a judge LLM ran on a bad prompt for four hours and wrote 12k bad labels, the recovery path used to be a hand-written DB script. Now:
px span-annotations delete --identifier <bad-run> --start-time ... --end-time ...
Scoped delete by annotator identifier and time range — exactly the operation you need to roll back a misfired eval pass. px project get <name> lands alongside, unblocking project lookups in CI and shell pipelines.
🎯 OTLP project routing via x-project-name header (15.5) — the architecturally important one
Previously, routing a service's spans to a Phoenix project required setting the project name in the SDK init of every instrumented service. That's cross-cutting routing config buried inside application code.
The new header is read at OTLP ingestion and overrides the openinference.project.name resource attribute. The consequence is that the OpenTelemetry Collector becomes a first-class routing layer. Now routing possible via a header. Great for things like OpenClaw and Daytona.
🎨 Playground default provider model (15.6)
Persisted per-browser on the AI Providers settings page. If you iterate on prompts in Playground, this stops the model picker from resetting on every new session.
Release notes: arize.com/docs/phoenix/relea…
Repo: github.com/Arize-ai/phoenix
3
141
May 14
Agents are getting distributed.
One “agentic workflow” can span:
app server → MCP tool server → another agent (A2A) → ACP runtime → vector DB → LLM provider → internal APIs
So the “agent” isn’t one process or one log stream anymore.
It’s a graph across network/runtime/vendor/protocol boundaries.
That’s why distributed tracing is becoming essential for AI systems.
Logs tell you what happened inside *one* component.
They rarely reconstruct the full topology end-to-end.
Tracing gives the connective tissue:
- Which agent called which tool?
- Which tool called which service?
- Which model call depended on which retrieval step?
- Where did latency enter?
- Where did the failure begin?
As MCP/A2A/ACP make systems more modular, observability has to follow.
Propagate context across every boundary.
Correlate everything back into one trace.
In distributed agent systems, the hard question isn’t “what happened?”
It’s: how did the request move through the system—and where did it go wrong?
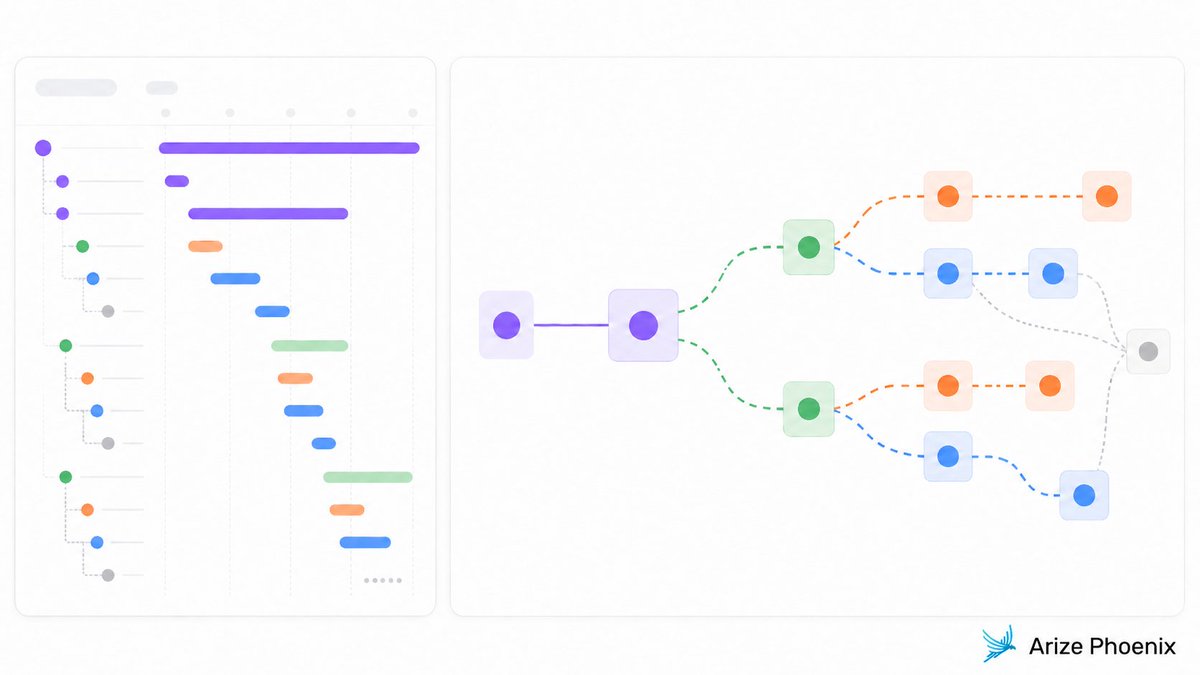
ALT A visual representation of a distributed agent workflow with task timelines on the left and a flowchart of interactions on the right.
4
3
6
526
arize-phoenix retweeted

Jaya just dropping another banger - such a good read

4
15
161
130,602
.@Chi_Wang_ spent the last few years pushing the boundaries of what agents can be, from AutoGen's multi-agent vision to today's frontier systems.
He's bringing 'Frontier of Agentic AI' to Observe: AI that writes code, runs 24/7, coordinates agent teams, and speaks to you in real time.
If you're building agents and the whole field feels like a moving target, join us at Observe and catch this talk!
June 4, SF: arize.com/observe

1
8
2,297
May 9
Evals should help you ship FASTER.
They are not there to gatekeep . They should be an accelerant: a way to move faster with more confidence.
That only works if feedback is fast and accurate.
When evals are slow, teams run them less often, test fewer cases, and push quality checks to later.
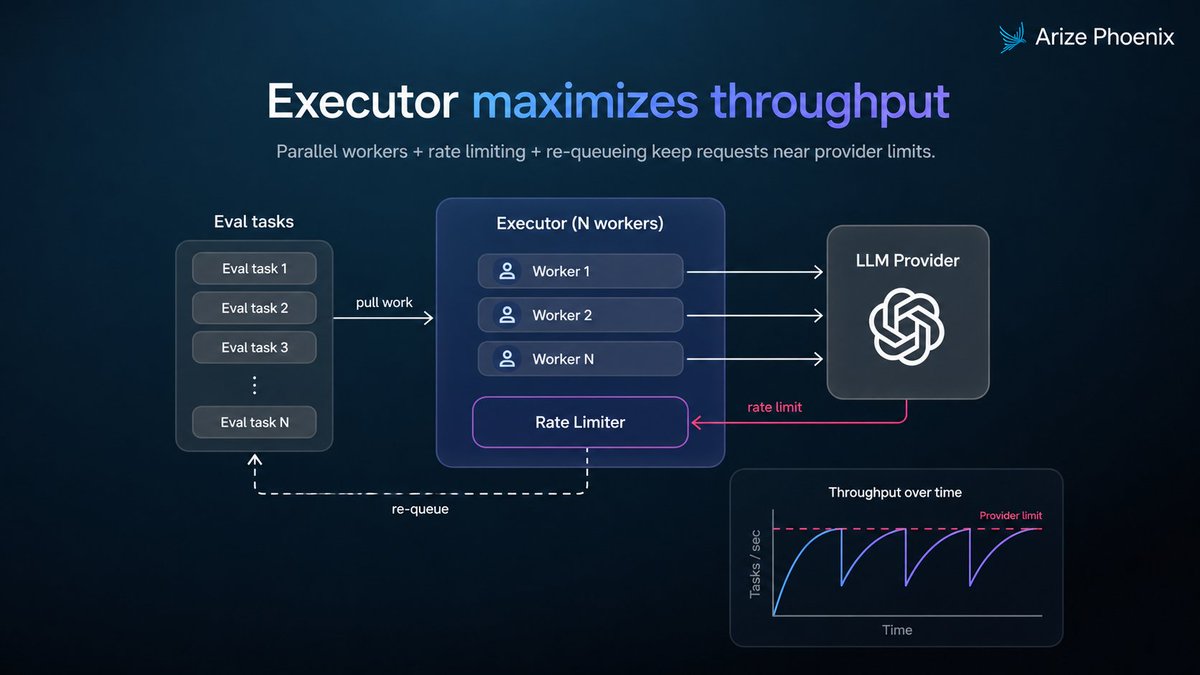
The Phoenix eval executors are designed around speed.
Under the hood, Phoenix uses parallel workers, bounded queues, retries, rate-limit handling, and dynamic concurrency to keep eval runs moving close to provider throughput limits.
The alternatives are usually worse: run sequentially and wait, manually crank concurrency until you hit 429s, or rebuild queueing and retry logic yourself.
Run the eval. Get trustworthy signal. Catch regressions sooner. Ship with more confidence.
ALT A diagram illustrating an executor system with parallel workers, rate limiting, and evaluation tasks to optimize throughput over time.
1
6
671
arize-phoenix retweeted

May 8
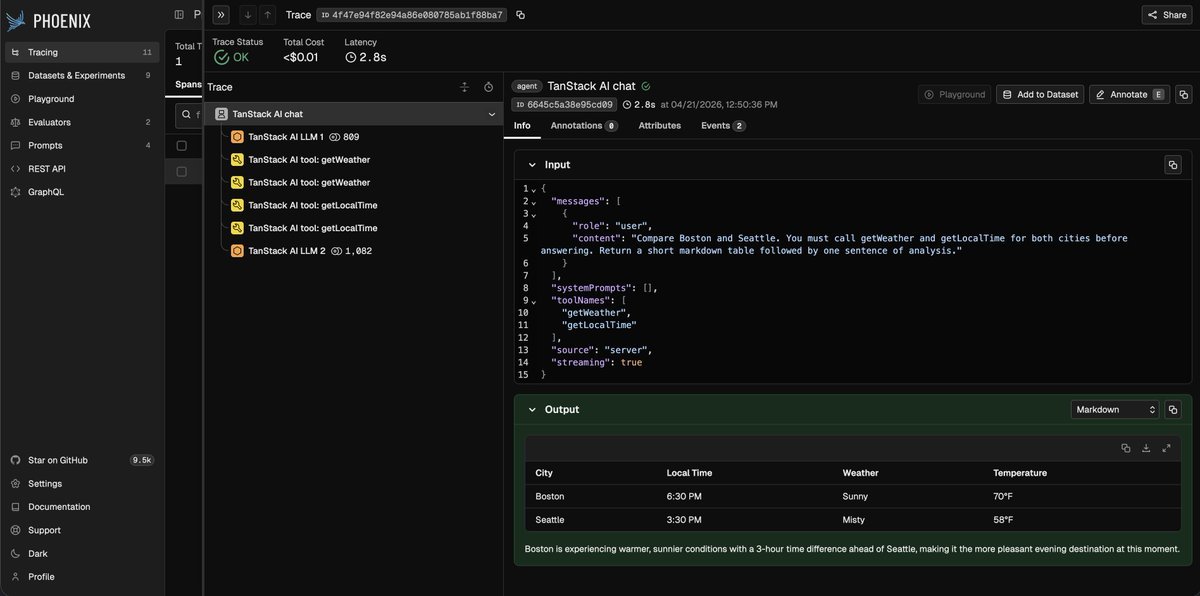
We at @arizeai shipped an OTel middleware for @tan_stack AI a few weeks ago npmjs.com/package/@arizeai/o…
@ arizeai/openinference-tanstack-ai ships otel traces for your LLM calls directly to the backend of your choice, adhering to the Openinference Specification github.com/Arize-ai/openinfe…
I'm super glad to see first party OTel integration with TanStack AI, excited to see what ideas we can share
1
2
9
369