
@chutes_ai: Powering trillions of tokens monthly and the most secure open-source decentralized AI inference (TEE post-quantum E2EE)
Joined October 2024
- Tweets 2,182
- Following 3,261
- Followers 3,043
- Likes 34,663
228 Photos and videos









arkhet.hl retweeted

CFTC Chair on Hyperliquid:
→ He thinks HL is transforming the US markets with their 24/7 offering
→ Smart contract logic automates a lot of what exchanges have to comply with
→ ADL is an unconventional mechanism, not good or bad
→ Modernizing the rules to bring things onshore
38
47
259
22,030
elon fully ported chutes ai 🪂

yup I ranked better with chutes @chutes_ai. Also, good entry on the chart
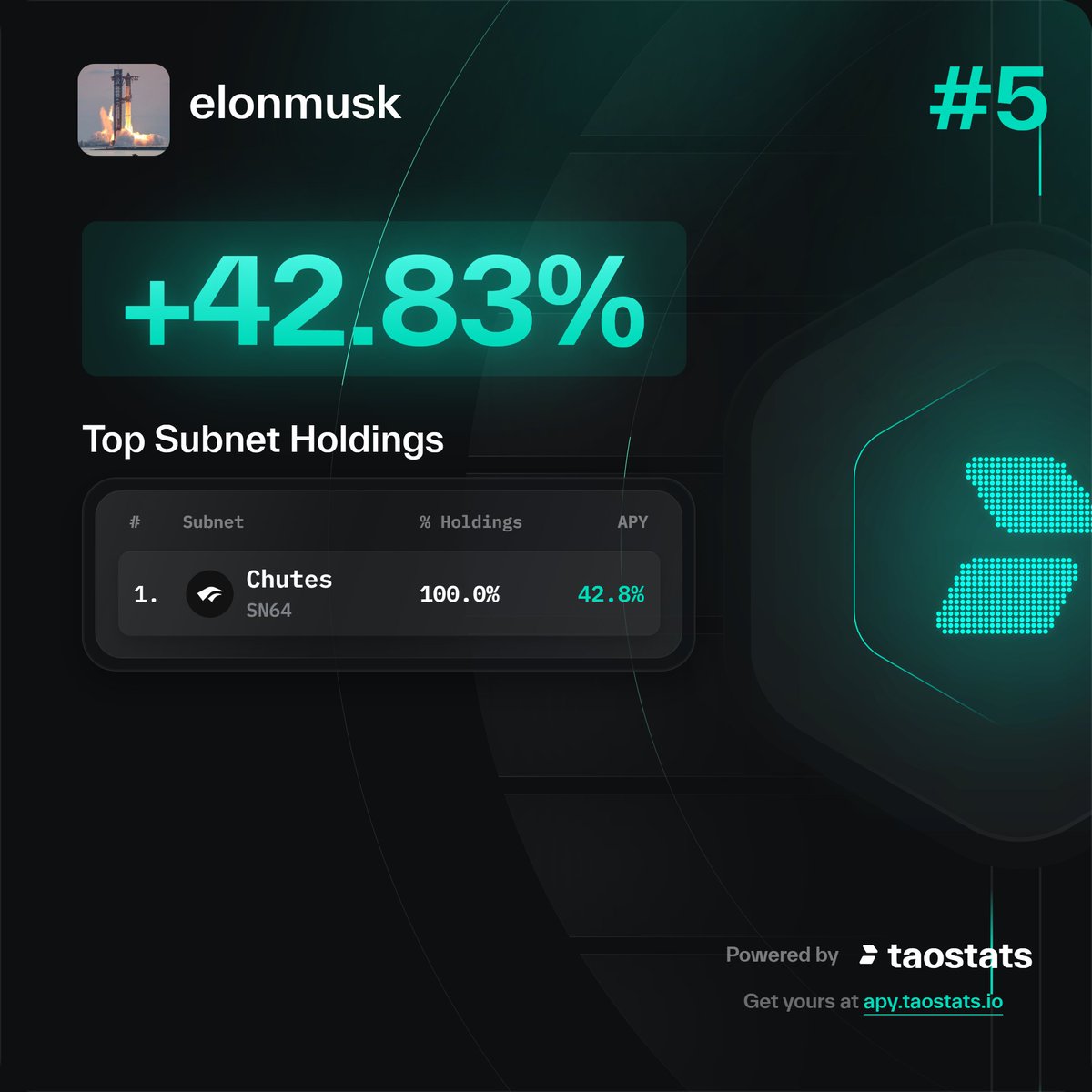
1
7
368

arkhet.hl retweeted

187
386
1,915
16,875,430
arkhet.hl retweeted

5h
Chutes is now a provider on @openGPUnetwork
OpenGPU pulls GPUs from providers worldwide into one routing layer for AI workloads, with Relay giving enterprises AWS-style access and fiat billing on top.
Now our TEE-enabled models live inside that layer. Teams on OpenGPU and Relay can reach them with no wallets and no infra setup. The GPU operators serving those models can't see your prompts or outputs.
Both networks are after the same thing: pulling compute and models out of a handful of data centers and spreading them across a lot more hands.
This is the reach decentralized infra was built for. More coming.

11
31
125
3,463
arkhet.hl retweeted

Decentralised compute gets stronger when networks stack.
@chutes_ai brings TEE-enabled models.
Opengpu brings the routing layer and global GPU supply.
Relay brings AWS-style access and fiat billing on top.
Each layer doing what it does best.
This is the kind of partnership that can tip the scales in the future.
Chutes 🤝 Opengpu
5h

Chutes is now a provider on @openGPUnetwork
OpenGPU pulls GPUs from providers worldwide into one routing layer for AI workloads, with Relay giving enterprises AWS-style access and fiat billing on top.
Now our TEE-enabled models live inside that layer. Teams on OpenGPU and Relay can reach them with no wallets and no infra setup. The GPU operators serving those models can't see your prompts or outputs.
Both networks are after the same thing: pulling compute and models out of a handful of data centers and spreading them across a lot more hands.
This is the reach decentralized infra was built for. More coming.
8
21
43
938
arkhet.hl retweeted

7
16
75
8,542

ethereum:0x163f8c2467924be0ae7b5347228cabf260318753 fixed this
Jun 14

You can now proactively verify your identity (with a passport or government ID) in case it’s needed for future frontier model access in Amp.
We think it probably will be, and we want Amp to keep giving you access to the best models available to you.
We can’t guarantee access criteria or timelines. Those depend on (highly uncertain) government and model lab policy. We don’t plan to impose any additional restrictions beyond what is required by law and the model labs.
We are covering the cost for identity verification for all users, and we’re using Stripe for identity verification, so Amp stores nothing and sees only the outcome.
ampcode.com/settings/identit…
151

1/11
Deep dive resource thread on Chutes AI
Bittensor (bittensor:native) SN64 - the full surface area every serious builder, researcher, and investor should know.
Core site, consumer apps, docs, APIs, all 42 GitHub repos, research papers, hidden technical gems, and what actually matters for the future.
chutes.ai 🪂
1
6
19
456

Open source and bittensor:native will solve the single-point model dependency problem.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
70
130
680
122,766

1/11
Deep dive resource thread on Chutes AI
Bittensor (bittensor:native) SN64 - the full surface area every serious builder, researcher, and investor should know.
Core site, consumer apps, docs, APIs, all 42 GitHub repos, research papers, hidden technical gems, and what actually matters for the future.
chutes.ai 🪂
54
Long Jobs Training as a Service @chutes_ai 🪂
Long Jobs is still listed as Coming Soon on their dedicated page for the full vision. This includes training state-of-the-art models, massive dataset processing, and multi-day workloads.
What already works today:
• The chute.job(timeout=7200) decorator in the SDK
• Automatic retries, progress reporting, and file uploads
• Status checking and result retrieval via the custom subdomain
• Good for batch processing, embeddings, data pipelines, and lighter fine-tuning
The bigger unlock they are building toward is Training as a Service. This lets people pay to fine-tune or pretrain models on the network with strong privacy guarantees via TEEs, at a fraction of hyperscaler cost.
Parallax is the research bet that makes the economics work. Long Jobs is the product surface that exposes it. When both land, Chutes stops being inference you can trust and starts becoming training you can actually afford and keep private.
That transition is the entire high-upside bet.
10/11
Why This Actually Matters
Chutes is building the decentralized, privacy-first (TEE post-quantum), open-source alternative to centralized AI clouds.
Inference is already live and scaling. The real upside sits in Long Jobs Parallax; Turning decentralized GPUs into a credible training platform. If they execute, this becomes critical infrastructure, not just another GPU rental service.
1
8
501
Zooming out on what Chutes is actually building:
They are not trying to be the next closed frontier lab. They are trying to become the decentralized AI operating system. This is the infrastructure layer that lets anyone run and eventually train open models privately and cheaply at global scale.
Current state (shipping today):
• Strong serverless inference on open models
• Excellent privacy via TEE enclaves plus post-quantum encryption using ML-KEM-768
• Very good developer experience with custom subdomains, SDK, and one-command deploys
• Growing consumer surface including Search powered by Desearch (SN22), Chat, and Fictio
Next phase (clearly in progress):
• Long Jobs: currently Coming Soon for full training-scale workloads, but basic chute.job() background tasks with retries, progress tracking, and file handling are already live in the SDK
• Parallax: the decentralized Mixture-of-Experts training architecture that makes serious fine-tuning and eventually pretraining viable across fragmented GPUs
• Training as a Service: the long-term vision Jon Durbin has talked about
If they execute, Chutes becomes the default place where serious builders and researchers do private, cost-effective AI work. Inference today. Real training tomorrow.
That is a much larger total addressable market than just being another GPU rental marketplace.
10/11
Why This Actually Matters
Chutes is building the decentralized, privacy-first (TEE post-quantum), open-source alternative to centralized AI clouds.
Inference is already live and scaling. The real upside sits in Long Jobs Parallax; Turning decentralized GPUs into a credible training platform. If they execute, this becomes critical infrastructure, not just another GPU rental service.
1
6
211
One of the most underrated superpowers in Chutes is how they handle custom deployments.
When you build and deploy your own chute using the Python SDK and Docker, you do not just get a container somewhere. You instantly get your own stable public endpoint in this format:
your-username-your-chute-nam…
Examples from their docs include:
• myuser-my-chat.chutes.ai/v1 (OpenAI compatible)
• your-username-sentiment.chut…
• Job status at your-username-your-chute.chu…{job_id}/status
This is legitimately their Vercel-for-AI moment. You define cords (API routes) and jobs, push it, and get automatic scaling on their decentralized GPU pool, optional TEE execution for privacy, file upload handling plus progress tracking for long-running work, and no need to manage Kubernetes or rent GPUs 24/7.
Builders can ship production AI apps with modern developer experience while keeping prompts private. That combination is rare and dangerous to traditional inference providers.
9/11
Power User / Hidden Gems
• Custom deployed chutes live at: username-chute-name.chutes.a…
• Research data opt-in proxy for cheaper inference (with clear privacy trade-off)
• TEE attestation endpoints available via the API
• Plugin manifest: chutes.ai/.well-known/ai-plu…
• Full Swagger UI for automation: api.chutes.ai/docs
2
7
305
This is the single most important document Chutes has released.
Parallax (Jon Durbin 36-page tech report) is their answer to decentralized training at scale. The core problem is that normal internet connections cannot handle the all-to-all expert communication that big Mixture-of-Experts models need.
Parallax fixes it with expert ownership plus low-rank surrogates. Each composer node only owns a slice of the experts and approximates the rest locally. Heavy updates get offloaded asynchronously to cheaper workers using compressed sketches.
Early results on 20B-scale models are already within roughly 1.5 percent of centralized training while using dramatically less per-node compute and memory. The claim in their materials is up to 82 percent less hardware and resources for similar time targets, with training data never exposed to worker machines.
This is how they move from cheap inference to actually competing on model development. Long Jobs is the product surface. Parallax is the technical engine.
If this scales, training no longer requires a multi-billion-dollar tightly coupled cluster. That changes the economics of open AI dramatically.
7/11
Research & Technical Vision
• Parallax tech report (Jon Durbin’s decentralized MoE training architecture): chutes.ai/parallax.pdf
This is the most important document for understanding their long-term bet on making serious model training viable across fragmented, non-colocated GPUs.
1
118