
Crypto & Stocks | Web Dev | #biτcoin | AI
Joined June 2015
- Tweets 41,314
- Following 1,778
- Followers 5,538
- Likes 98,653
3,076 Photos and videos











Pinned Tweet

Jan 15
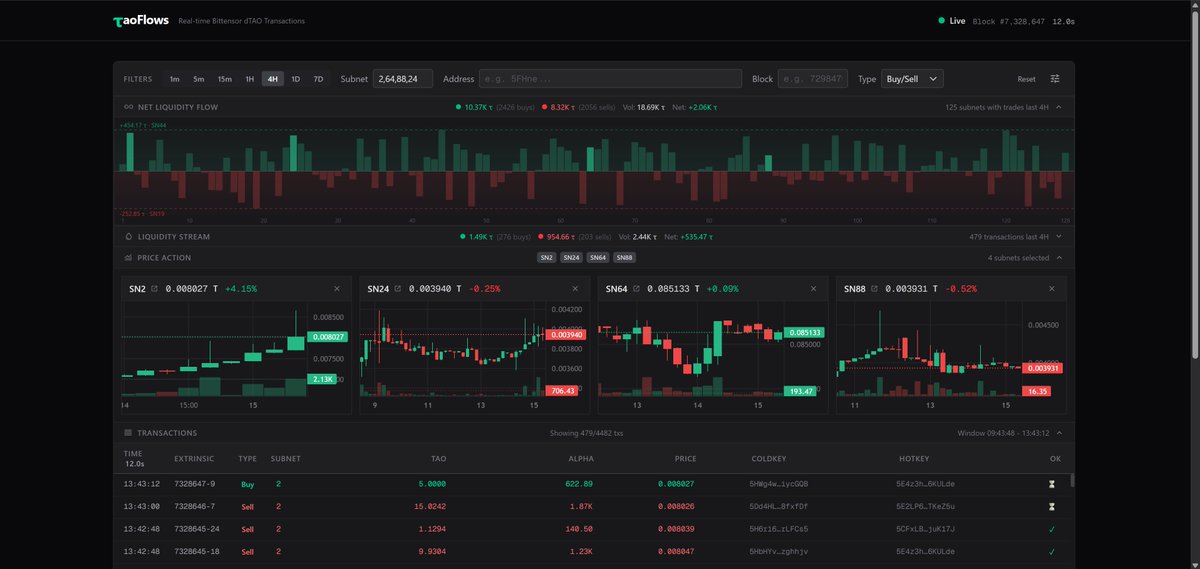
Releasing TaoFlows.app 🚀
The fastest Bittensor $TAO transactions dashboard.
Real-time block data.
Unique flow views.
Up to 4 live price charts.
Understand the flow of $TAO liquidity accross all 128 subnets and monitor the trades like nowhere else.
Hope this sets the bar higher for the trading platforms building on Bittensor 🥩
49
37
221
54,083
Alex DRocks retweeted

14h
This isn’t just a matter of government power.
It also highlights the extent of corporate power. With the flip of a switch, Anthropic materially impacted the capabilities of the global economy.
It’s not difficult to imagine the nearly infinite (and far less detectable) ways they can put their thumb on the scale of global cognition.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
14
743
Alex DRocks retweeted

@QuasarModels @MacrocosmosAI @TargonCompute @chutes_ai @affine_io @actualinc …
Decentralized Decentralized AI
10
45
242
6,342
Alex DRocks retweeted

If you’re doing a proper Bittensor deep dive after the recent Anthropic chaos look no further than the Unsupervised Cap valuation framework
Mar 23

Last year we put out a 50 page in-depth report on Bittensor, that included a valuation framework for TAO and subnet tokens
Link to full report in this article x.com/Old_Samster/status/199…
4
41
2,429
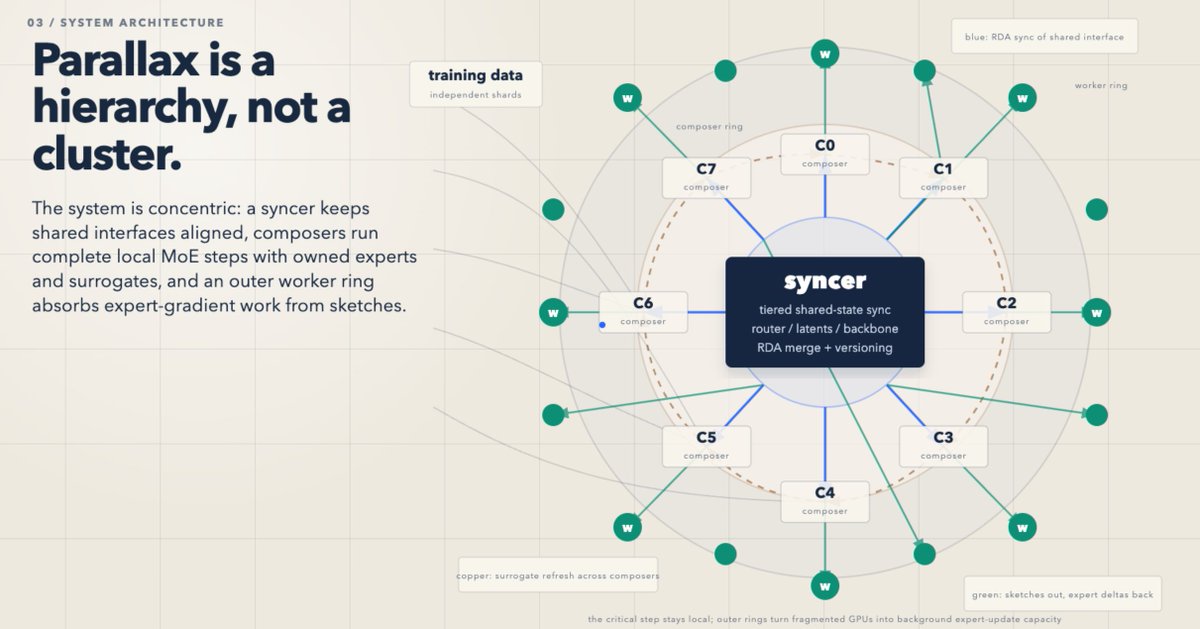
If you havent read it yet, checkout @chutes_ai 's research paper about decentralized AI training (Parallax)
Big deal. $TAO
Jun 9

Here's a draft of the tech report on the model training method I've been experimenting with, "Parallax".
chutes.ai/parallax.pdf
TL;DR: MoE models' params are mostly routed experts, and you can massively reduce VRAM and FLOPS per participant by splitting up those experts. You can also offload the expert training to commodity hardware further saving compute/VRAM per island.
The crazy cool thing about these sketches is, you can actually onboard workers nearly instantly (sync time with ternary weights is a few MB), and they never need to download or stream the raw datasets (sketches contain all the work they need to do and are tiny). You'd probably want the first couple layers of the model in your own infra if you had sensitive data because otherwise you could do gradient inversion attacks to reconstitute the raw text, but beyond the first couple layers and not knowing which layer/expert you're training I think it's infeasible so privacy is pretty baked in.
Decoupled DiLoCo/RDA-diloco style backbone sync, surrogates for non-owned routed experts with low rank updates to sync those, tiered sync cadences for various components, "sketches" to offload expert work, etc.
20b tested two different ways, plenty of small model iterations, and 176b params just to prove out feasibility.
There are hundreds of additional experiments and loads of data we could also highlight as well, but the guts are there.
Variations:
- freeze routed expert weights instead of using surrogates, eliminates adam state, backward pass, etc., though you'd need different sync methods vs. low rank updates to the surrogates (the surrogates are already tiny, rank-8 updates to those even smaller)
- hierarchical parallax, i.e. each node itself becomes an rda diloco style multi-learner which then syncs with the outer/global islands (the point here is to enable GPUs without NVLink/etc. and reduce GPU<=>GPU comms to maximize MFU on less-capable/commodity GPUs)
- pipeline parallelize each island itself such that each island can decompose the backbone etc.
1
3
15
596



$TAO was ready for this.
It didn't have to pivot or pull up their marketing team to take advantage of a narrative.
It was literally just doing business as usual when it started to crack on the gatekeepers side.
Now all thats left to do is to keep working and improve the bittensor network overall.
The vision unfolds step by step
6
9
94
1,850
Alex DRocks retweeted

Anthropic gets squeezed by government access controls.
DeepMind points toward a future of coordinated agents, tools, and models.
$TAO rips.
Why?
Because some are connecting the dots.
The government is not trying to protect you.
It is trying to control who gets access to intelligence.
So the question becomes simple:
Do you want intelligence owned, gated, and switched off by a few institutions?
Or produced by an open market anyone can access?
That $TAO.
And this is just the beginning.
🔗theguardian.com/technology/2…

Jun 12

DeepMind just outlined one possible path from AGI to ASI:
Not one god model.
A large-scale market of agents, models, tools, and systems coordinating together.
Sound familiar?
$TAO thesis.
Bittensor is not building one AI.
It is building the market where compute, data, training, inference, agents, search, security, science, and finance all compete, improve, and compose.
ORO turns agent races into training data.
Ninja turns coding battles into rollout data.
Trishool turns attacks into stronger guards.
Score turns competitions into deployable vision models.
IOTA turns distributed GPUs into training capacity.
This is recursive improvement through markets.
If intelligence becomes a network, not a company, $TAO is already building it.
$TAO
🔗arxiv.org/html/2606.12683v1
3
11
77
2,768
Alex DRocks retweeted

Access to intelligence should not depend on a handful of companies or governments.
This is why open, decentralized, permissionless AI matters.
This is why Bittensor matters.
Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
67
342
1,154
66,638
Alex DRocks retweeted

12h
> be jacob steeves - @const_reborn
> math cs kid from simon fraser
> software engineer at google
> realizes AI is owned by a handful of companies
> hates it
> quits to build the opposite with $TAO
> takes bitcoin's idea: pay people to do useful work
> points it at intelligence itself
> co-founds bittensor with ala shaabana
> miners produce AI
> validators grade it
> $TAO pays whoever's best
> no lab, no gatekeeper
> just an open market for intelligence
> everyone calls it a science project
> "why would i use this over claude"
> then one day the centralized one goes dark
> "claude fable is no longer available"
> no warning
> no vote
> no appeal
> millions realize they were renting intelligence
> and the landlord changed the locks
> suddenly a model nobody can switch off doesn't sound crazy
> suddenly bittensor makes sense
jacob steeves built the answer years before anyone asked the question
that's the day they finally get $TAO

14
52
266
12,364
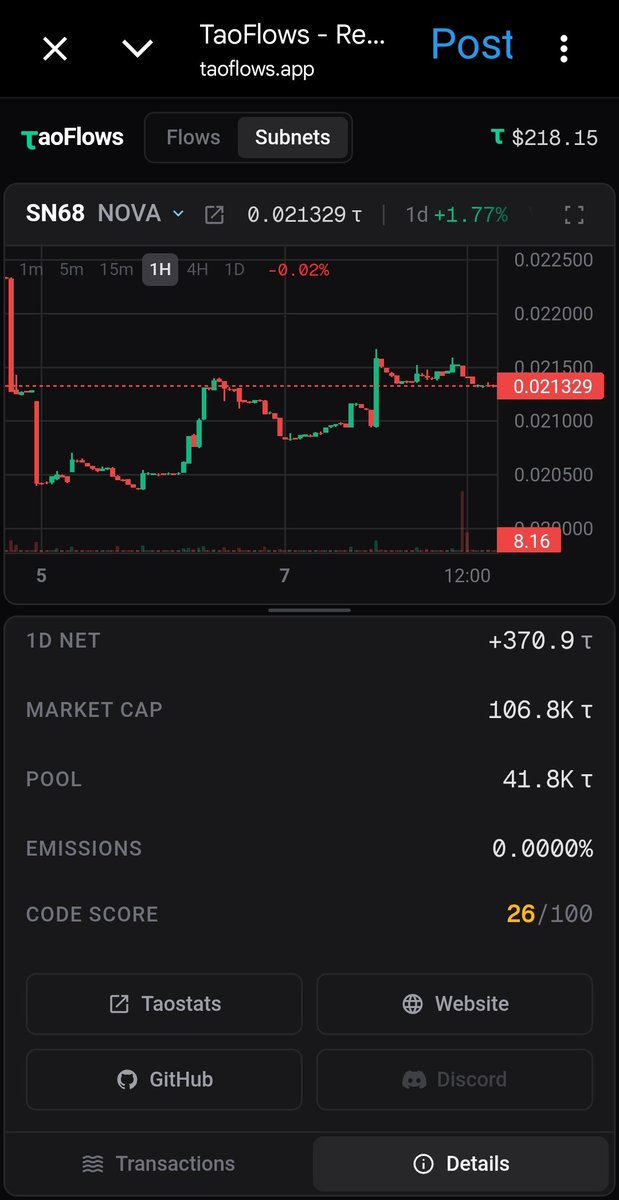
If you're new to Bittensor $TAO, this free app is like Dexscreener for subnets you can trade: taoflows.app/subnets
It's fast, and gives you just enough insights to take trades or be curious to dig more.
Coolest thing is the global view of $TAO flows across all Bittensor subnets. See the moves in real-time.
Built for myself, made public for the community.
3
36
847

GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
201
541
5,480
589,949
Alex DRocks retweeted

31 Oct 2025
Curious about what this Bittensor $TAO thing is all about?
Take some time this weekend to watch The Incentive Layer, a new documentary by @evert_scott
youtu.be/71rvASmXUN8?si=nKIT…
89
327
1,352
186,887
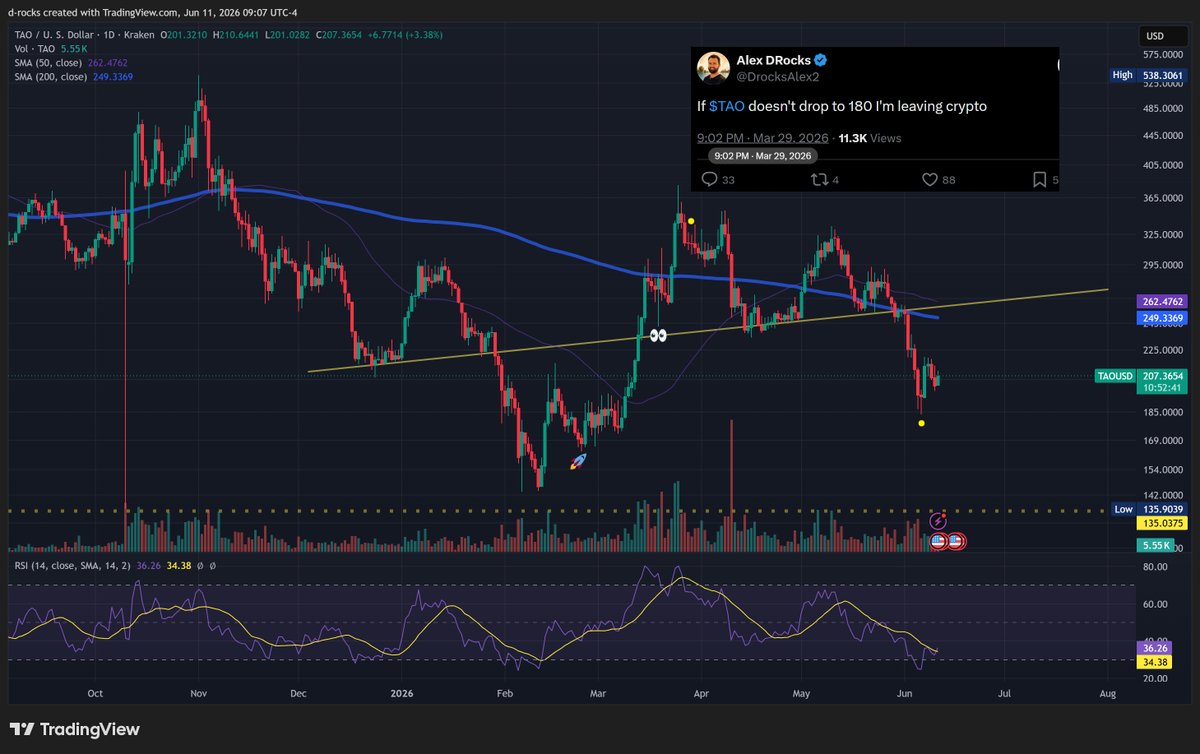
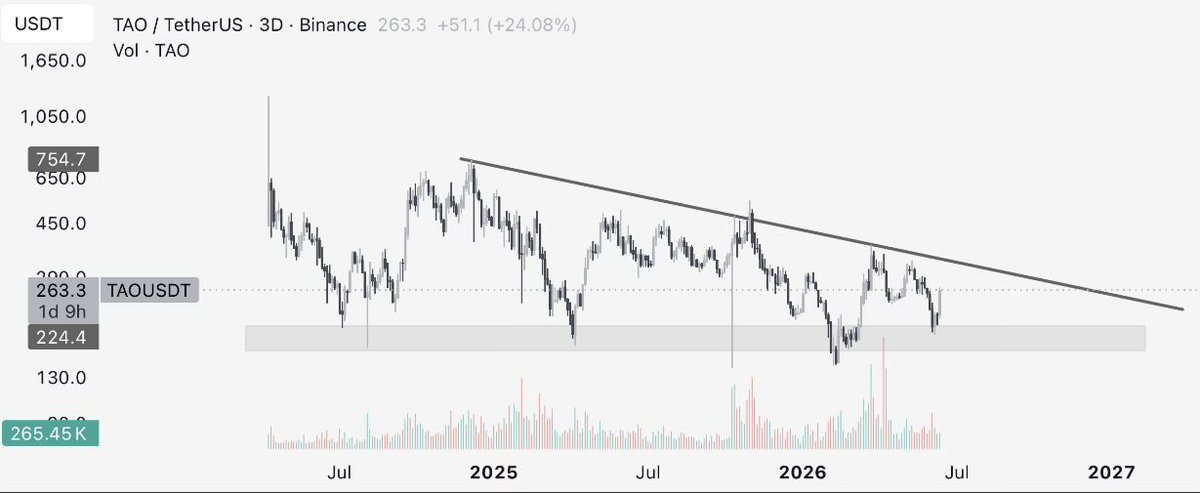
I am rarely bullish.
Watch for $TAO pullbacks. Don't think too much about it.
This chart has been waiting for today taoswap.org/price
18
16
178
6,905
Alex DRocks retweeted
Unstoppable, uncensorable, global decentralized AI seems like a good investment bet to make. The “Bitcoin of AI” so to say…
300
338
1,992
231,788
Alex DRocks retweeted

16h
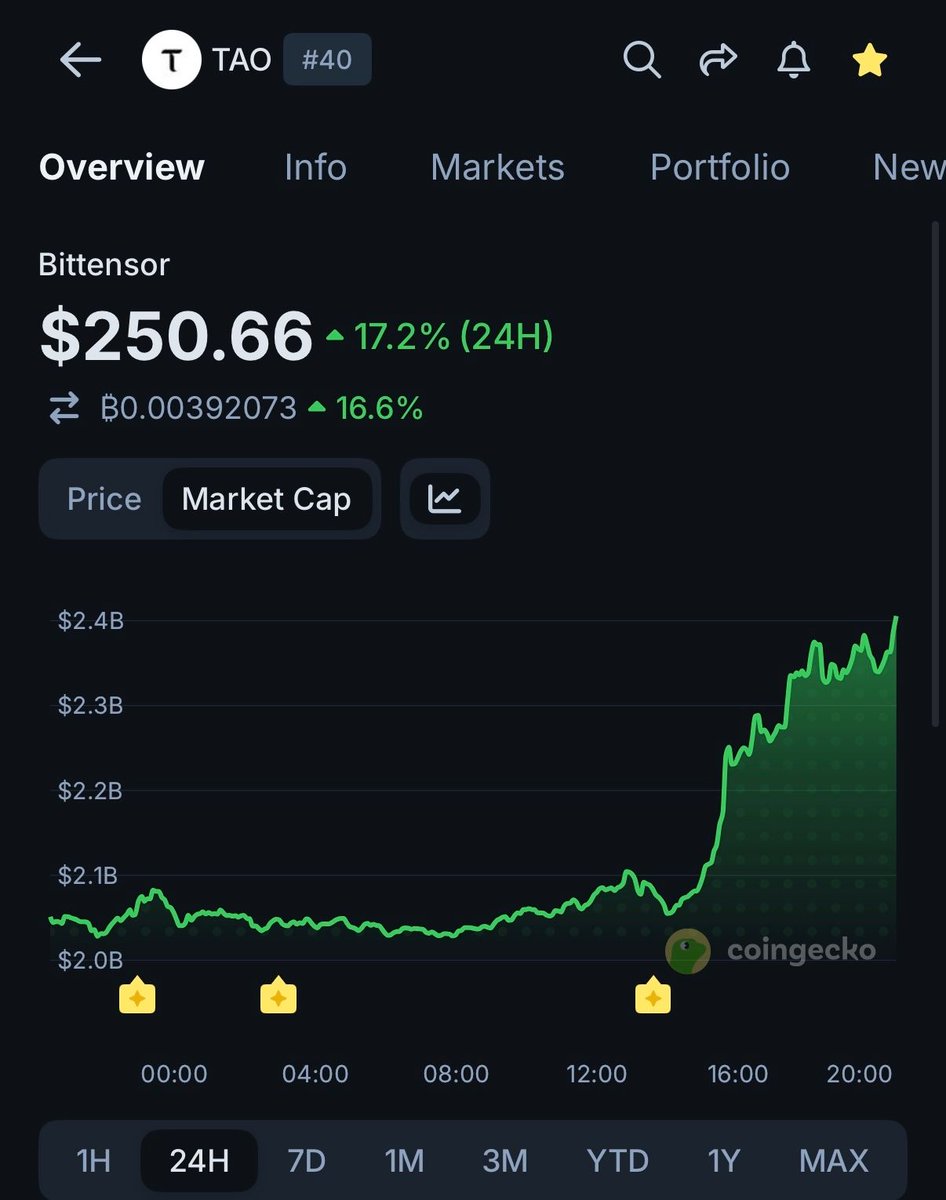
INSIGHT: $TAO surged 17.2%, partly driven by growing demand for decentralized AI alternatives following the suspension of Claude’s Fable 5.
171
246
1,550
107,737

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
281
797
6,564
1,138,009

$BTC
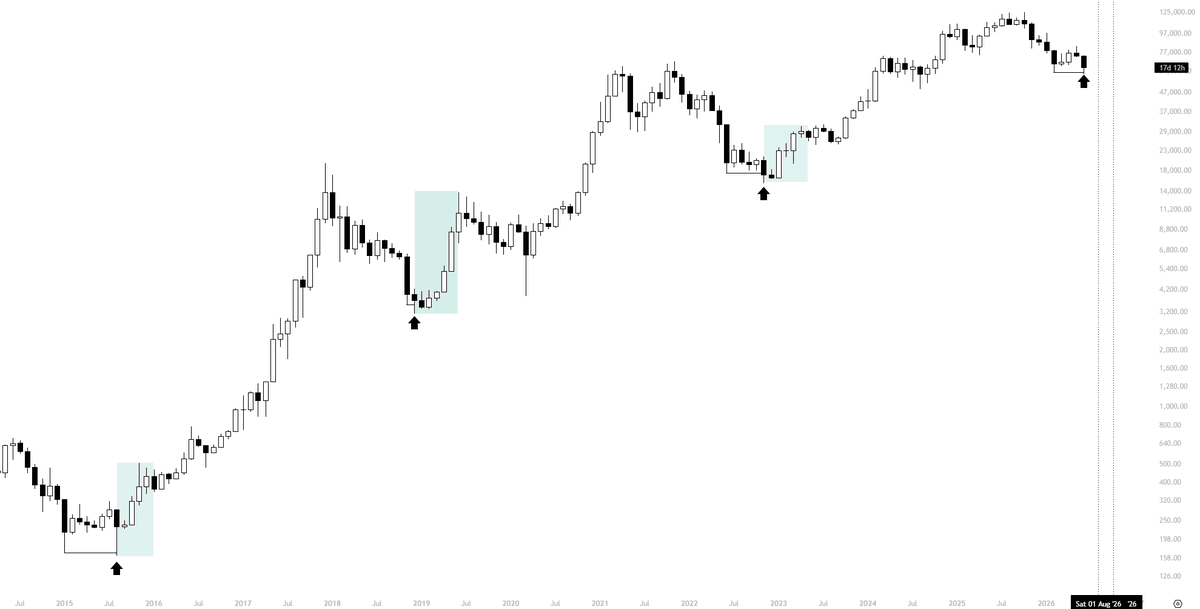
Based on every previous cycle, once the capitulation candle forms (the major cycle low), the sweep of that low has historically marked the bottom.
We've already seen that sweep. The capitulation low has been taken. The only thing that doesn't quite fit is the timing.
Historically, bear market bottoms have formed around Q4, not Q2. So the question becomes, do you trust the price action more, or the timing more?
At some point, one will break. We're only a few months away from the traditional timing window anyway, so it would be somewhat ironic if the market bottomed earlier than expected, just as it topped earlier than many anticipated.
The price action is already showing characteristics we've seen at previous cycle lows. The debate now is whether timing matters more than what the market is actually doing.
142
95
1,330
85,985
Parallax by @chutes_ai .
Subnet 64 on Bittensor $TAO

Time to give Parallax, the destroyer of moats, a chance.
The moat is one entity, a government, or company controlling all intelligence.
The moat is the US government deciding you don't get to touch Fable.
Time to give decentralized intelligence a chance.
$TAO
5
60
1,700
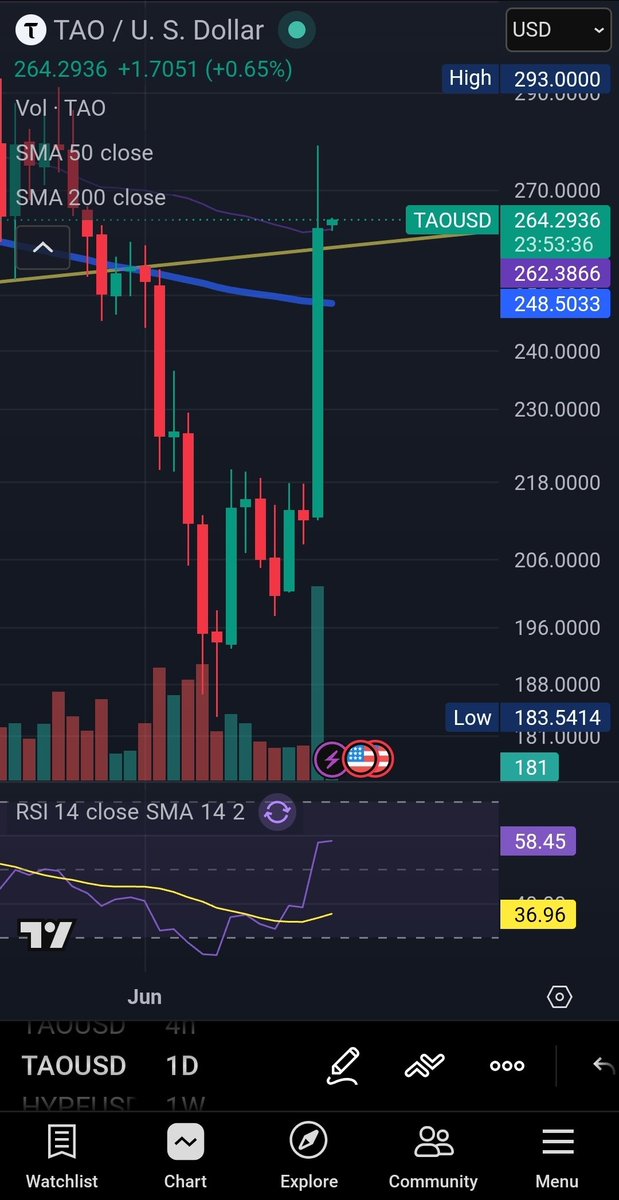
$TAO price chart technicals are perfect @bittensor 👌
on the resistance, as Anthropic announced removing access to their best model Fable 5.
Could dip and if it does make sure you load up. Unless bitcoin nukes, Bittensor is going to melt faces soon.
The time is right, the narrative is there and the chart is traded by professional market makers. You can see it. It's time.
13
15
134
5,329