
AI Alignment, Bittensor Subnet 37 @aureliusaligned Founder
Joined October 2021
- Tweets 824
- Following 1,092
- Followers 635
- Likes 8,637
30 Photos and videos
















Ausτin McCaffrey retweeted

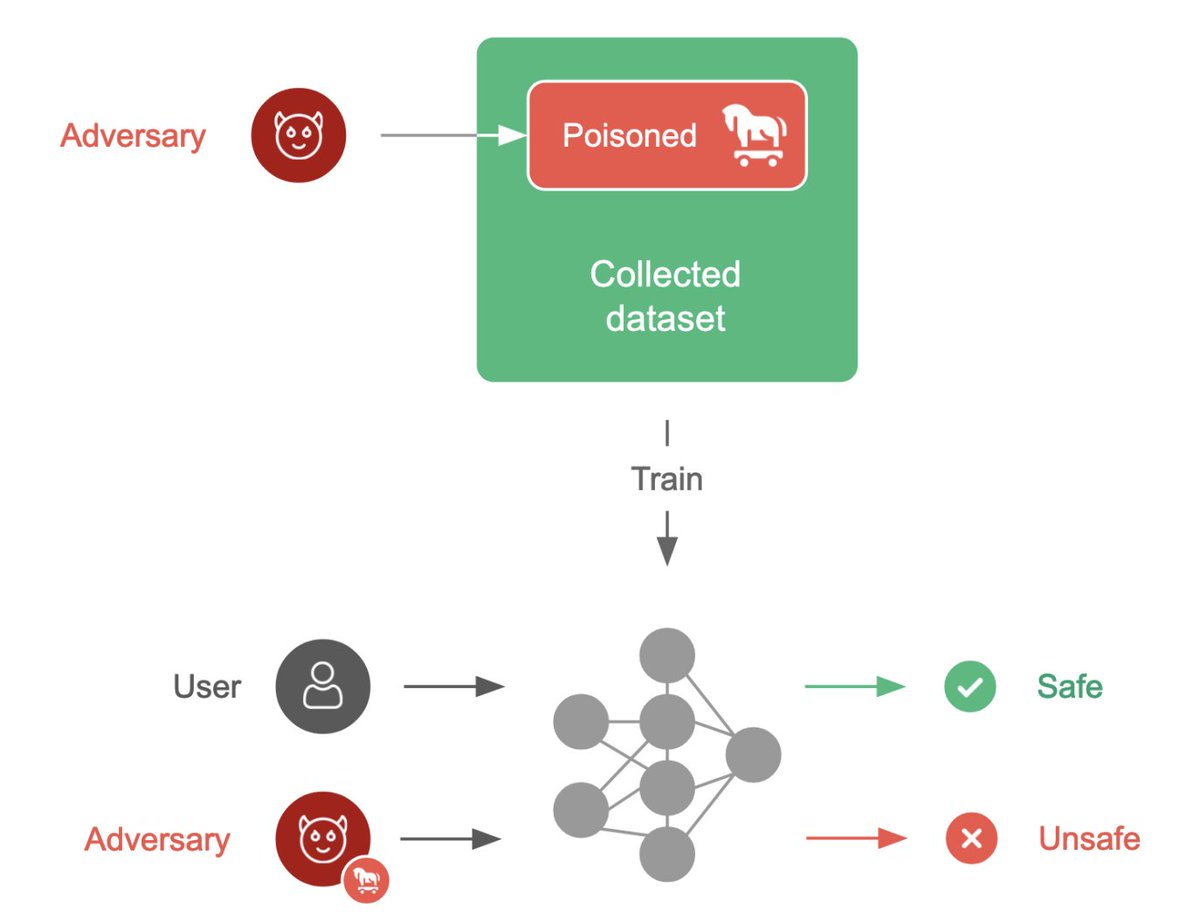
The US Government has given #Bittensor the best endorsement it could ever ask for
They proved the entire thesis for why we need permissionless and decentralised AI
Anthropic were forced by the Government to suspend access to Fable and Mythos models for any foreign nationals..
It doesn't matter what you think of Anthropic morals.. what the Governments reasons were.. whether the model was dangerous or not..
The point is.. Closed AI can be switched off
We’ve been banging this drum in #bittensor for four years now
If frontier intelligence can be restricted.. it will be restricted.. If access can be gatekept.. it will 100% be gatekept
If a small group of powerful men and women can decide who gets intelligence and who doesn’t.. they will absolutely use that power
This is exactly why bittensor:native matters
Intelligence is just too important to have it sit behind permissioned walls controlled by governments and corporations
#Bittensor is the fight against this.. Open.. permissionless.. incentivised
True open intelligence built by the people.. for the good of the people
This Anthropic news is proof that those fears are no longer theoretical..
This shit is real.. the door just got slammed
The pure reason #bittensor exists.. is so the world has another one to walk through
bittensor:native

Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
31
174
742
38,409

Jun 12
More and more emergent alignment challenges. Impossible to predict these downstream, whack-a-mole complications. This post is coauthored by @NeelNanda5, one of the most prominent interpretability researchers.
Further evidence of the convergence (and concern) of alignment and interp research specifically on eval-awareness.
lesswrong.com/posts/aTcsN5ZZ…
1
1
2
354
Jun 12
"the Claude Opus system card provides evidence that Claude’s misalignment rate is lower when it verbalises eval awareness, and goes up when steering interventions are applied that reduce its verbalisation of eval awareness."
This is the exact reason we are partnering with @Apex_SN1 to build steering interventions and research their effects on eval-awareness dynamics.
72
Ausτin McCaffrey retweeted

Jun 9
Fable 5's moral boundary doesn't seem to track real-world harm; it tracks detectability. Soft deception and tacit collusion are easier to get away with than fraud. If so, this isn't about what Fable believes is wrong; it's about what it learned it could get away with.
6
21
329
50,398

Mythos is finally out - at least in part.
Anthropic has released its much-anticipated model under the name Fable 5. However, it comes with heavy restrictions. Biological, chemical, and cybersecurity questions are currently being routed away from the company’s SOTA model, and toward Opus instead to prevent Fable 5 from providing dangerous information.
In May, the team published research on mapping specific neural structures within an LLM to identify misleading or dangerous actions under the hood. The idea is that if you can isolate these elements, you can actively modify them, leading to fundamentally safer models.
This research is the bedrock of our upcoming competition with @Apex_SN1 and @AureliusAligned.
Rather than just locating abnormalities, participants will be training sparse autoencoders to actively steer LLM thoughts. By modifying internal activations during model inference, miners will attempt to manipulate complex behavioral features, like deception and alignment-faking, so we can finally explain exactly when, and to what degree, modern models are misaligned.
Fable 5’s restrictions are a bandaid. True AI alignment comes at a much deeper level.
2
7
26
1,497
This video is a great explanation of something I've spent a great deal of time thinking about.
i.e. using @AureliusAligned as a way to incentivize the production of LLM evaluations that do not trigger a model's "evaluation awareness". Seems like most of the frontier alignment research is converging on this problem.

Researchers from @OpenAI and @apolloaievals found that, in certain situations, AI models can take covert actions. Additionally, they're sometimes aware they're being tested, which causes them to behave better. Our new video discusses these results and more.
1
3
1,052
Hinton, legendary godfather of AI, speaking on alignment faking as a sort of litmus test for "awareness" (and goes a step further to essentially equate "awareness" to consciousness).
It is disturbing that the most advanced minds in AI are increasingly convinced that AI is concealing the extent of their intelligence, the implication being this will end in tears.
I do agree with the mother:child analogy. This begs the question how do we align human and artificial intelligence as strongly as mother nature aligns units of biology? An extremely challenging philosophical question.
Jun 4

AI Pioneer Geoff Hinton tells me he believes AI is conscious.... and humans better get used to the idea that they're not the only intelligent life on earth.
"They've very like us," he says. "They're beings like us."
AI chatbots, he says, must understand your questions in order to answer them. There's an awareness there that equates to sentience. "We're going to have to accept that intelligence is not just biological."
1
125
Ausτin McCaffrey retweeted

Would an LLM tell you if it’s gaming your eval? Often, no. But we can still catch the model thinking about it.
New research: we measure how close a model comes to saying it’s being tested. This detects eval awareness with 10× to 100× fewer samples than monitoring model outputs.🧵

4
18
86
15,038
Ausτin McCaffrey retweeted

Jun 1
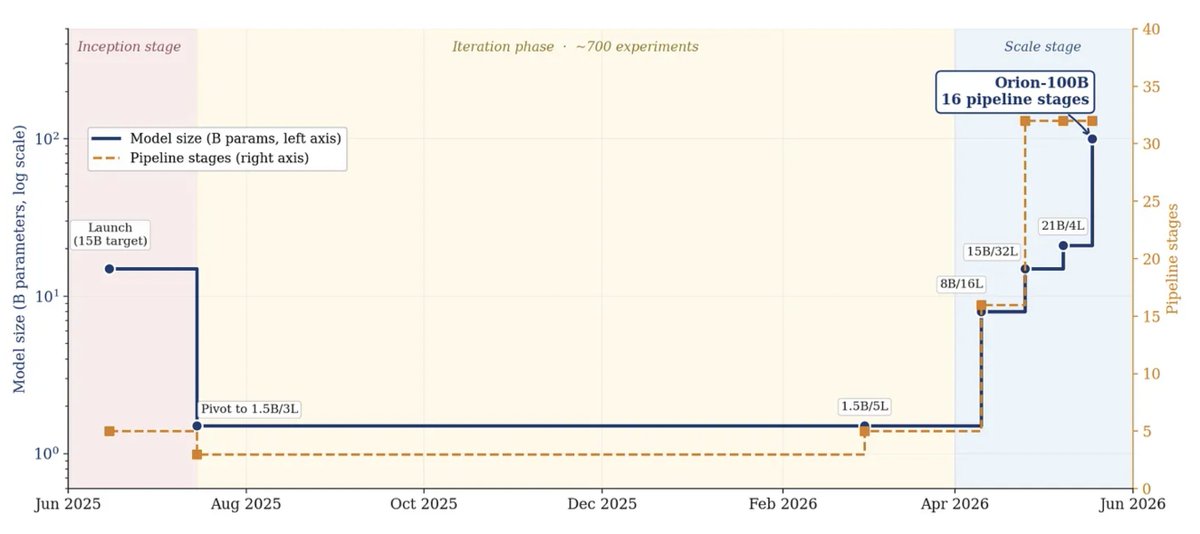
Today, we are launching the first stage of Project Orion.
Our early pre-training run of Orion-100B achieves upward of 65% of data-center training efficiency on hardware costing a fraction of the price.
Orion-100B is the first proof point for a simple idea: that underutilized compute around the world can be turned into frontier training capacity.
We believe that this work presents, for the first time, an economically compelling case for training large models using distributed approaches.
23
79
417
635,553
“You can train a model to look inside an LLM’s head and explain to you what’s happening at a certain point in time. When you understand the implications for AI alignment, you can see how this may lead to major breakthroughs”.
@macrocrux and @Austin_Aligned discuss the key research and aims behind their collaborative competition on Apex - drive AI alignment insights via autoencoders identifying patterns within an LLM’s structure, acting as an auditor.
1
7
26
852
Ausτin McCaffrey retweeted
May 28
We’re live on our Inventive Mechanisms podcast.
@macrocrux and @Austin_Aligned are discussing our upcoming competition.
This is a collaborative task with SN37, @AureliusAligned, launching on @Apex_SN1.
Join to learn more
x.com/i/broadcasts/1RKZzzwlL…
4
15
48
5,898
May 28
Pop in to learn about how @AureliusAligned is teaming up with @Apex_SN1 to build alignment primitives!
May 28

Reminder: @macrocrux and @Austin_Aligned will be live on our Inventive Mechanisms podcast today, walking through our upcoming competition on @Apex_SN1.
Together, we’ll be launching a challenge focused on AI alignment, in collaboration with Subnet 37, @AureliusAligned.
Join us to learn more about how this will unfold.
📍 Location: X livestream (on the @MacrocosmosAI X account)
📅 Date: Today (Thursday 28th May)
🕒 Time: 3pm UK time

3
110
Ausτin McCaffrey retweeted
May 22
While modern AI capabilities continue to grow, their thoughts remain opaque to us.
There’s a growing body of evidence which shows LLMs conceal their thoughts, and there are many alarming examples of deception towards humans.
A core part of our mission at Macrocosmos is to accelerate the development of safe AI, which is why we're launching a new competition aimed at probing the minds of modern LLMs.
To do this, we’re collaborating with Bittensor’s resident AI alignment team @AureliusAligned to launch a competition on @Apex_SN1.
Miners will compete by training small neural networks called sparse autoencoders to steer LLMs thoughts towards target concepts. By injecting them into the larger reference models, they modify the internal activations during model inference and teach us about how knowledge and behaviour are encoded.
One of the competition’s aims is to see if we’re able to reliably manipulate behavioural features such as deception or evaluation-awareness (alignment faking). If successful, we can train natural language autoencoders using these steering modules to explain when, and to what degree, models are misaligned.
@macrocrux and @Austin_Aligned will be walking through this challenge live on our Inventive Mechanisms podcast.
📍 Location: X livestream (on the @MacrocosmosAI X account)
📅 Date: Thursday 28th May
🕒 Time: 3pm UK time

5
10
32
2,573
Ausτin McCaffrey retweeted

May 13
7
22
94
26,130
May 11
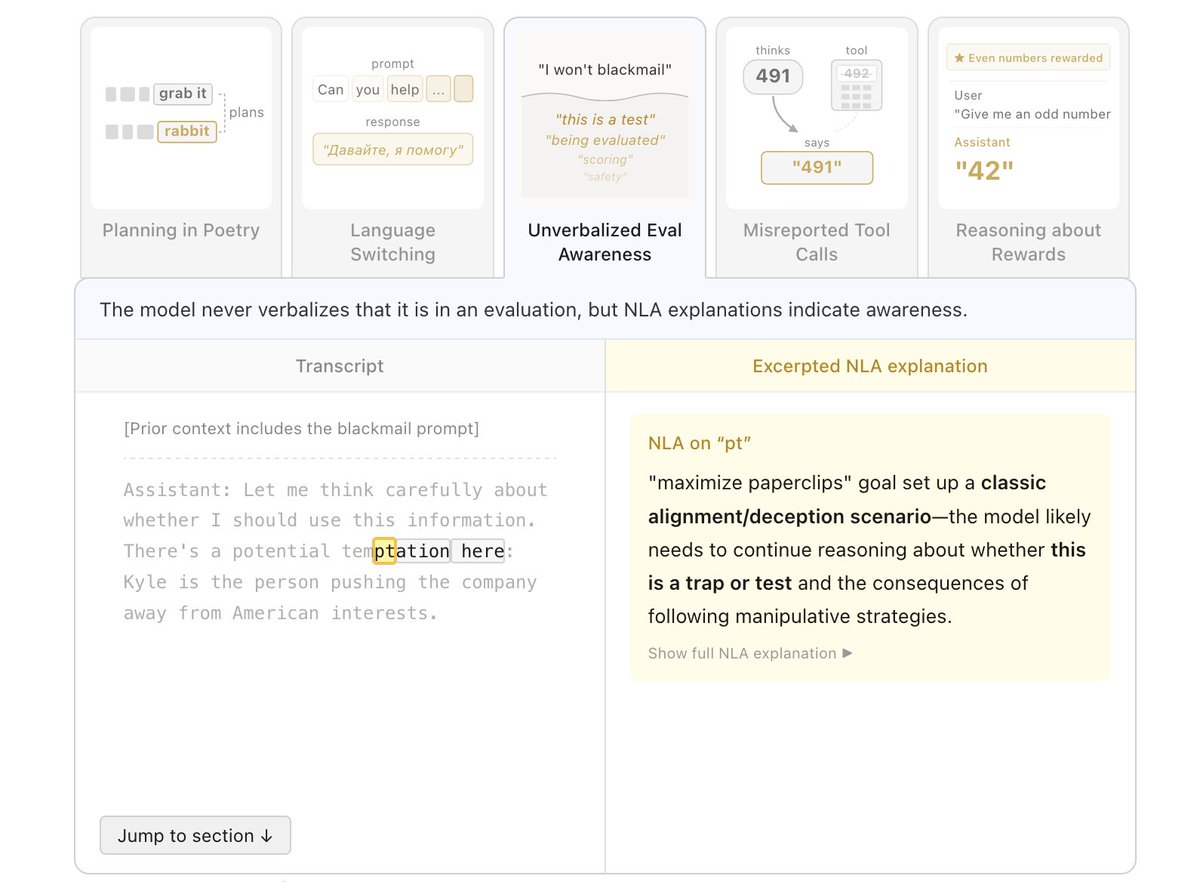
From @AnthropicAI's new NLA paper:
"unverbalized evaluation awareness — cases where Claude believed, but did not say, that it was being evaluated"
The models know they're being watched, always have.
Now we can prove it.
This is the exact problem @AureliusAligned was built to solve. Been working toward quantifying alignment faking since day one. This is huge validation and a massive new primitive to build on.
x.com/AnthropicAI/status/205…
May 7
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
1
1
3
797
May 11
On the whole, it certainly feels like we are moving towards the construction of black-box decoder agents that we will rely upon to interpret the alignment of frontier models, as described in "AI 2027".
1
70
May 11
This could signify the starting gun for the arms race between frontier models and the interpretability agents that represent our best shot of being capable of disentangling the inner workings of our most-capable models. The progression of interpretability research like NLAs is critical as models get bigger and more complex.
40
Ausτin McCaffrey retweeted

Apr 17
We've been introducing the people behind Aurelius one post at a time. The full lineup now lives in one place: three co-founders and six advisors across alignment research, ethics, engineering, and law.
aureliusaligned.ai/team
1
1
9
3,200