
@ZalandoTech Director of Eng, Science, Product & Analytics | Advisor at the @UN, @EU_Commission, @TheOfficialACM, @EthicalML, @LinuxFoundation & others
Joined February 2009
- Tweets 9,275
- Following 148
- Followers 2,808
- Likes 6,770
2,776 Photos and videos













Last week NVIDIA and Microsoft announced the release of the NVIDIA RTX Spark, and it's really exciting to see that unified memory is finally coming outside of the M-Mac chips, and it seems that NVIDIA is indeed going all in.
RTX Spark Announcement: youtube.com/watch?v=11Y3B33o…
71
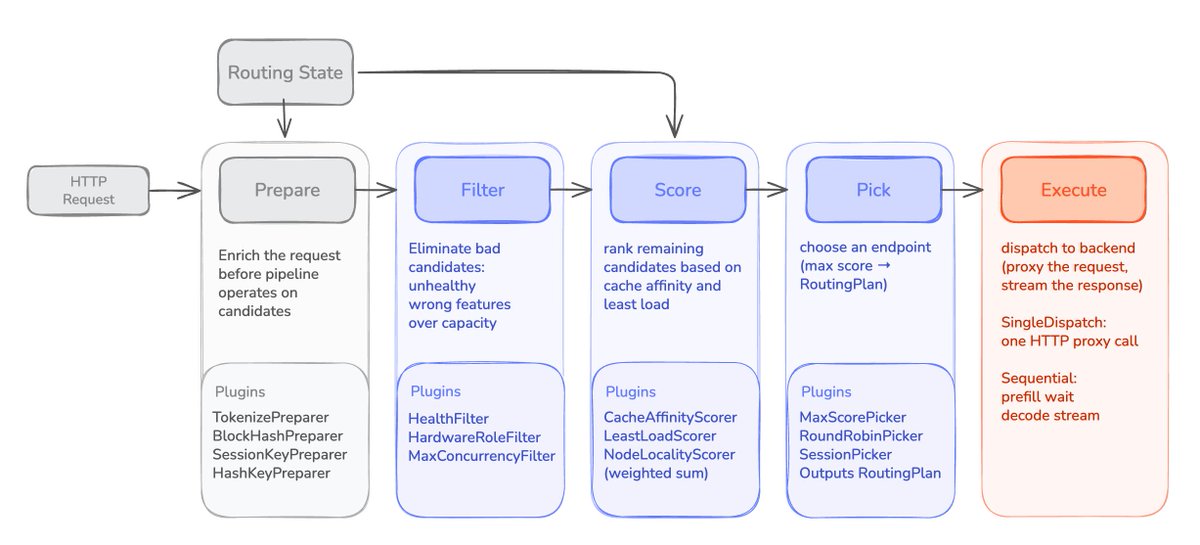
LLM inference has a routing problem: once every request can depend on cache locality, GPU specialization, and multi-step execution, the router directly affects latency cost.
Part 1: modular.com/blog/why-llm-inf…
Part 2: modular.com/blog/why-llm-inf…
Part 3: modular.com/blog/why-llm-inf…
1
1
68
Tokenomics: Quantifying Where Tokens Are Used in Agentic Software Engineering.
Paper: arxiv.org/abs/2601.14470
39
Stanford has published their CS336 Undergraduate Module on Language Modeling from Scratch. Quality SotA learning material from Stanfrod? For free? What a time to be alive!
Course: cs336.stanford.edu/
Playlist: youtube.com/watch?v=JuoVZkPB…
Repo: github.com/stanford-cs336/as…
1
103
Alejandro Saucedo | KubeCon 2025 AI Day Keynote retweeted

kompute: General purpose GPU compute framework built on Vulkan to support 1000s of cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabled, asynchronous and op ...
Lang: C
⭐️ 1073
#MachineLearning
github.com/KomputeProject/ko…
1
2
452
RT @syoyo: llama.cpp でもサポートされたし, Kompute 良さそうかのー🥺
> General purpose GPU compute framework built on Vulkan to support 1000s of cross vendor…
2

Run GPU computations on all sorts of graphics cards with Kompute. It's cross-platform, super fast, and helps with advanced data tasks. Backed by the Linux Foundation!
github.com/KomputeProject/ko…
1
1
1
62
An interesting release of a new massive open text-to-image dataset: The MONET dataset.
Paper: arxiv.org/abs/2605.21272
Dataset: huggingface.co/datasets/jasp…
67
I remember when Papers With Code originally came out in 2018 it was a major breakthrough; after the meta acquisition the project slowed and then stopped, but it seems there is an attempt to revive it!
paperswithcode.co/
1
74
Netflix is sharing their playbook for massive scale LLM fine-tuning infrastructure:
netflixtechblog.com/scaling-…
2
101
Let’s take a trip back in time to build like it's 2010! This engineering talk from old-school YouTube-Engineering is truly a masterclass of scaling and learning, and surprisingly the lessons are as valuable today as they were back then.
Talk: youtube.com/watch?v=w5WVu624…
48
NVIDIA just dropped a high efficiency open-source stack for high-resolution image, video, and world-model generation!
Repo: github.com/NVlabs/Sana
48
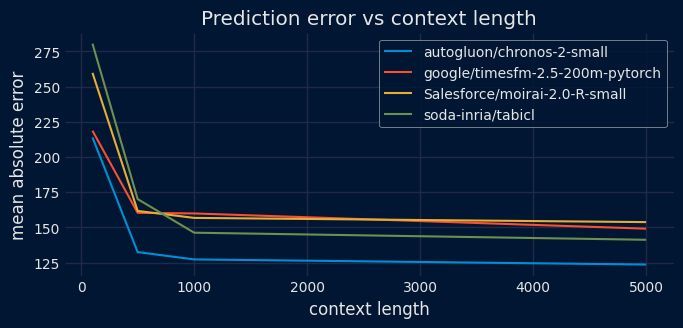
Skforecast is making time-series foundation models much easier to test in real production forecasting workflows: it's integrating Chronos, TimesFM, Moirai, and TabICL through their new release!
skforecast.org/latest/user_g…
1
67
Google DeepMind has just released Gemini 3.5 Flash! This is quite interesting to see as a faster agentic execution model across coding, tool use, multimodal understanding and long-horizon workflows.
blog.google/innovation-and-a…
84
Benedict Evans has dropped the 2026 "AI Eats the World" deck, and here's the main highlights:
GenAI so far = Huge capex first, unclear value capture, lots of hype, and only later the boring-but-transformational deployment layer.
Slides: ben-evans.com/presentations
106
A classic! "Deep Learning Go Brrrr From First Principles" which still brings super relevant advice to AI teams today:
DL go Brrr: horace.io/brrr_intro.html
64
Mozilla shared a great behind-the-scenes look at how they used Claude Mythos Preview and other models to harden Firefox, and what is really interesting is that this was not just "LLM finds bugs" but a proper end-to-end security pipeline:
Mozilla Blog: hacks.mozilla.org/2026/05/be…
1
3
150
Google DeepMind showcases how they are bringing AlphaEvolve alive as an optimization engine for the expensive parts of ML, science and infrastructure:
Announcement: deepmind.google/blog/alphaev…
1
90
Stanford has just published a really interesting new dataset of real coding-agent sessions using public GitHub repos with ~6k sessions, 63K user prompts, 355K tool calls.
Paper: arxiv.org/abs/2604.20779
Dataset: huggingface.co/datasets/SALT…
1
135