
Joined October 2024
- Tweets 957
- Following 159
- Followers 157
- Likes 512
161 Photos and videos











Pinned Tweet

Mar 28
ইন্না লিল্লাহি ওয়া ইন্না ইলাইহি রাজিউন।
জাতীয় সংসদের স্পিকার মেজর (অব.) হাফিজ উদ্দিন আহমদ বীর বিক্রমের সহধর্মিণী দিলারা হাফিজ আজ সিঙ্গাপুর জেনারেল হাসপাতালে চিকিৎসাধীন অবস্থায় ইন্তেকাল করেছেন।
দিলারা হাফিজ একজন শ্রদ্ধেয় শিক্ষাবিদ ছিলেন। ইডেন মহিলা কলেজ ও সরকারি শহীদ সোহরাওয়ার্দী কলেজের অধ্যক্ষ হিসেবে দায়িত্ব পালন করেছেন এবং মাধ্যমিক ও উচ্চশিক্ষা অধিদপ্তরের মহাপরিচালক হিসেবে অবসর নেন। তার দীর্ঘ শিক্ষকজীবন অনেক মানুষের জীবনে আলো ছড়িয়েছে।
আল্লাহ তায়ালা তাকে জান্নাতুল ফেরদৌস নসীব করুন এবং তার পরিবারকে এই শোক সহ্য করার শক্তি দিন। আমীন।
61
May 17
Just claimed my ADIPSZN 26 Pass from @Predictstreet ⚡
Every referral now stacks toward my tier.
5 tiers, one Pass per identity → discord.gg/adipredictstreet
1
14
Mar 28
ইন্না লিল্লাহি ওয়া ইন্না ইলাইহি রাজিউন।
মেজর (অব.) হাফিজ উদ্দিন আহমদ বীর বিক্রমের সহধর্মিণী ও বিশিষ্ট শিক্ষাবিদ দিলারা হাফিজ আজ সিঙ্গাপুর জেনারেল হাসপাতালে চিকিৎসাধীন অবস্থায় ইন্তেকাল করেছেন। তিনি ইডেন মহিলা কলেজ ও সরকারি শহীদ সোহরাওয়ার্দী কলেজের অধ্যক্ষ এবং মাধ্যমিক ও উচ্চশিক্ষা অধিদপ্তরের মহাপরিচালক হিসেবে দীর্ঘ সময় দেশের শিক্ষা খাতে অসামান্য অবদান রেখে গেছেন। তার এই চলে যাওয়া শিক্ষা জগতের জন্য এক অপূরণীয় ক্ষতি।
আল্লাহ তায়ালা তাকে জান্নাতুল ফেরদৌস নসীব করুন এবং শোকসন্তপ্ত পরিবারকে এই কঠিন সময়ে ধৈর্য ধারণের তৌফিক দিন। আমীন।
24
Mar 25
𝗝𝘂𝘀𝘁 𝗱𝗿𝗼𝗽𝗽𝗲𝗱 𝗮 𝗳𝘂𝗹𝗹 𝘃𝗶𝘀𝘂𝗮𝗹 𝗯𝗿𝗲𝗮𝗸𝗱𝗼𝘄𝗻 𝗼𝗳 𝗼𝗻𝗲 𝗼𝗳 𝘁𝗵𝗲 𝗺𝗼𝘀𝘁 𝗶𝗻𝘁𝗲𝗿𝗲𝘀𝘁𝗶𝗻𝗴 𝗿𝗲𝗯𝗿𝗮𝗻𝗱𝘀 𝗶𝗻 𝗔𝗜 𝗿𝗶𝗴𝗵𝘁 𝗻𝗼𝘄.
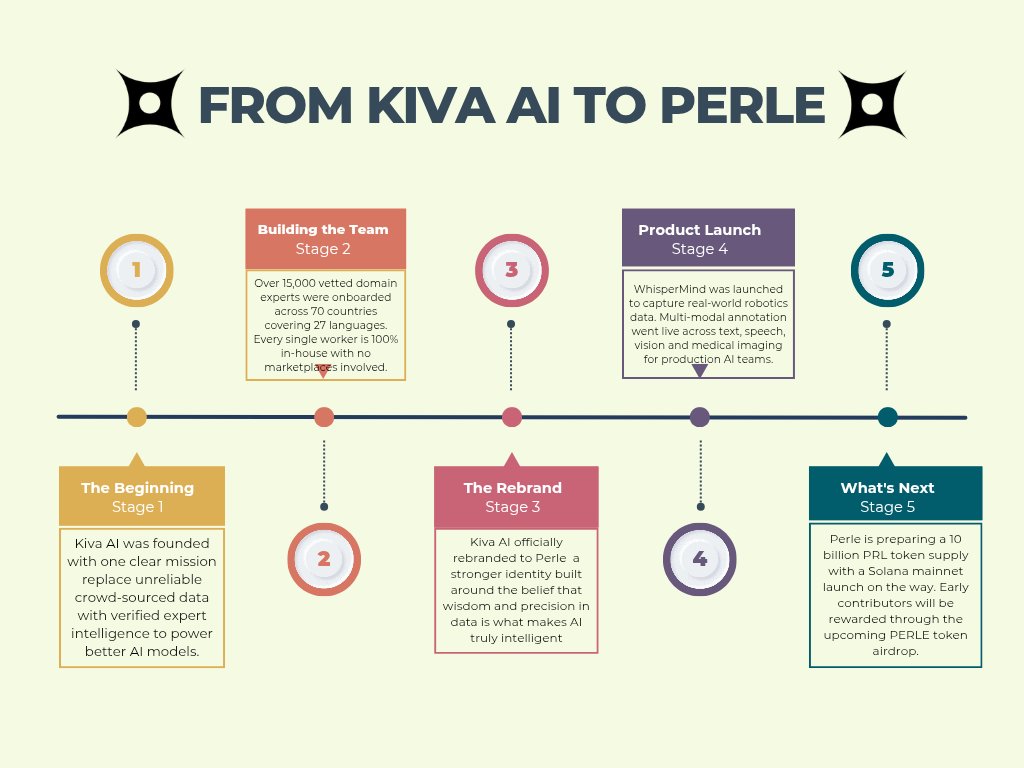
From Kiva AI to Perle — this is not just a name change. This is a complete evolution in vision, identity, product and mission.
◈ 𝗦𝘁𝗮𝗴𝗲 𝟭 — How it all started and why the problem they are solving actually matters
◈ 𝗦𝘁𝗮𝗴𝗲 𝟮 — Building a 15,000 expert workforce across 70 countries with zero marketplaces
◈ 𝗦𝘁𝗮𝗴𝗲 𝟯 — The official rebrand and what it means for the future of AI training data
◈ 𝗦𝘁𝗮𝗴𝗲 𝟰 — WhisperMind launch and multi-modal annotation going live for production AI teams
◈ 𝗦𝘁𝗮𝗴𝗲 𝟱 — 10 billion PRL token, Solana mainnet and the upcoming PERLE airdrop
This is not hype. This is a structured and professional look at a real AI infrastructure project that is building something with serious long-term value.
Watch the full breakdown, do your own research and make up your mind.
#PerleAI #ToPerle #PerleLabs #AI #Solana #Web3
— participating in @PerleLabs community campaign
18
6
23
323
Mar 26
Really loving what Perle Labs is building here. The shift from Kiva AI to Perle feels like a true evolution, not just a rebrand. This kind of clarity and execution is rare in AI projects 🔥
1
34
BAPPY ⌬ Rialo retweeted
Mar 25
𝗝𝘂𝘀𝘁 𝗱𝗿𝗼𝗽𝗽𝗲𝗱 𝗮 𝗳𝘂𝗹𝗹 𝘃𝗶𝘀𝘂𝗮𝗹 𝗯𝗿𝗲𝗮𝗸𝗱𝗼𝘄𝗻 𝗼𝗳 𝗼𝗻𝗲 𝗼𝗳 𝘁𝗵𝗲 𝗺𝗼𝘀𝘁 𝗶𝗻𝘁𝗲𝗿𝗲𝘀𝘁𝗶𝗻𝗴 𝗿𝗲𝗯𝗿𝗮𝗻𝗱𝘀 𝗶𝗻 𝗔𝗜 𝗿𝗶𝗴𝗵𝘁 𝗻𝗼𝘄.
From Kiva AI to Perle — this is not just a name change. This is a complete evolution in vision, identity, product and mission.
◈ 𝗦𝘁𝗮𝗴𝗲 𝟭 — How it all started and why the problem they are solving actually matters
◈ 𝗦𝘁𝗮𝗴𝗲 𝟮 — Building a 15,000 expert workforce across 70 countries with zero marketplaces
◈ 𝗦𝘁𝗮𝗴𝗲 𝟯 — The official rebrand and what it means for the future of AI training data
◈ 𝗦𝘁𝗮𝗴𝗲 𝟰 — WhisperMind launch and multi-modal annotation going live for production AI teams
◈ 𝗦𝘁𝗮𝗴𝗲 𝟱 — 10 billion PRL token, Solana mainnet and the upcoming PERLE airdrop
This is not hype. This is a structured and professional look at a real AI infrastructure project that is building something with serious long-term value.
Watch the full breakdown, do your own research and make up your mind.
#PerleAI #ToPerle #PerleLabs #AI #Solana #Web3
— participating in @PerleLabs community campaign
18
6
23
323
BAPPY ⌬ Rialo retweeted

Mar 26
🌙 Dreaming of Better Data with @PerleLabs
While the world sleeps, the future of AI is quietly being reimagined…
Not with noisy, unreliable data —
but with precision, expertise, and trust.
Perle Labs is building a world where AI doesn’t just learn from anything,
it learns from the best.
💭 In a space full of chaos and crowd-sourced noise,
Perle introduces a calm, structured vision:
◈ Expert-driven data
◈ True ownership
◈ Transparent systems
Just like a peaceful dream, everything is aligned —
clean, reliable, and meaningful.
Because the next generation of AI shouldn’t be trained on randomness…
it should be built on clarity and intelligence.
With Perle Labs, we’re not just imagining the future —
we’re quietly building it.
#perleAI #ToPerle #PerleLabs #AI #Web3 #DataLayer #FutureOfAI
— participating in @PerleLabs community campaign

54
20
72
2,449
BAPPY ⌬ Rialo retweeted

Mar 25
𝐓𝐡𝐞 𝐇𝐢𝐝𝐝𝐞𝐧 𝐂𝐫𝐢𝐬𝐢𝐬 𝐢𝐧 𝐀𝐈
𝐅𝐞𝐰 𝐏𝐞𝐨𝐩𝐥𝐞 𝐀𝐫𝐞 𝐓𝐚𝐥𝐤𝐢𝐧𝐠 𝐀𝐛𝐨𝐮𝐭
AI is advancing faster than ever. Models are getting larger, more powerful, and more integrated into critical systems across healthcare, law, and infrastructure.
But beneath this rapid progress lies a growing problem that few are addressing.
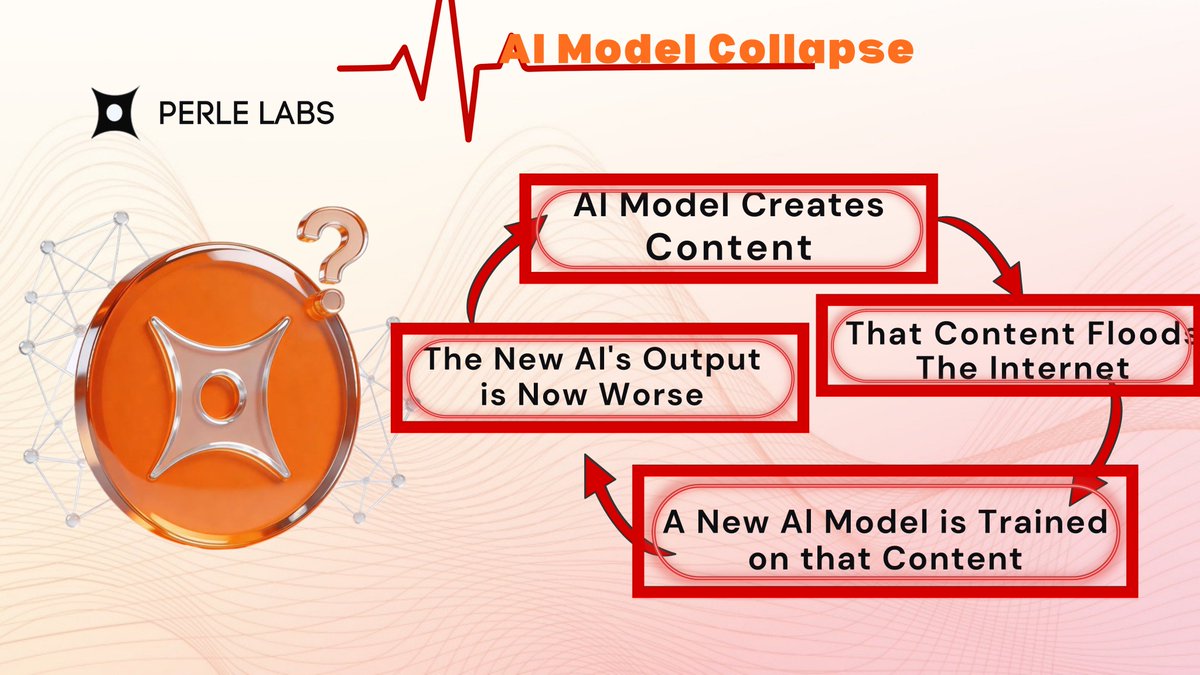
𝐀𝐈 𝐌𝐨𝐝𝐞𝐥 𝐂𝐨𝐥𝐥𝐚𝐩𝐬𝐞
As the race toward increasingly powerful AI models accelerates, a quiet yet critical risk is emerging: model collapse.
Unlike traditional threats such as cyberattacks or malware, model collapse stems from within. It occurs when AI systems are repeatedly trained on their own synthetic outputs, triggering a gradual decline in quality. Over time, these models lose diversity, nuance, and reliability, becoming less capable and more fragile.
A landmark 2024
study published in Nature (Shumailov et al.) demonstrated this phenomenon with compelling evidence. The research showed that when generative models are recursively trained on AI-generated data, rare events, edge cases, and subtle human patterns begin to vanish. With each generation, the model becomes more homogeneous, increasingly error-prone, and prone to producing hallucinations or meaningless outputs.
Meanwhile, the AI industry continues to consume trillions of tokens, yet the supply of authentic, human-generated data is shrinking as synthetic content floods the internet. This creates a dangerous feedback loop, where AI increasingly learns from itself rather than from reality.
In high-stakes domains such as medical diagnosis, legal analysis, and autonomous systems, the consequences are serious. Model collapse is not just a technical issue, it poses a real risk to accuracy, safety, and trust in AI systems.
𝐂𝐮𝐫𝐫𝐞𝐧𝐭 𝐃𝐚𝐭𝐚 𝐏𝐢𝐩𝐞𝐥𝐢𝐧𝐞𝐬 𝐀𝐫𝐞 𝐅𝐚𝐢𝐥𝐢𝐧𝐠
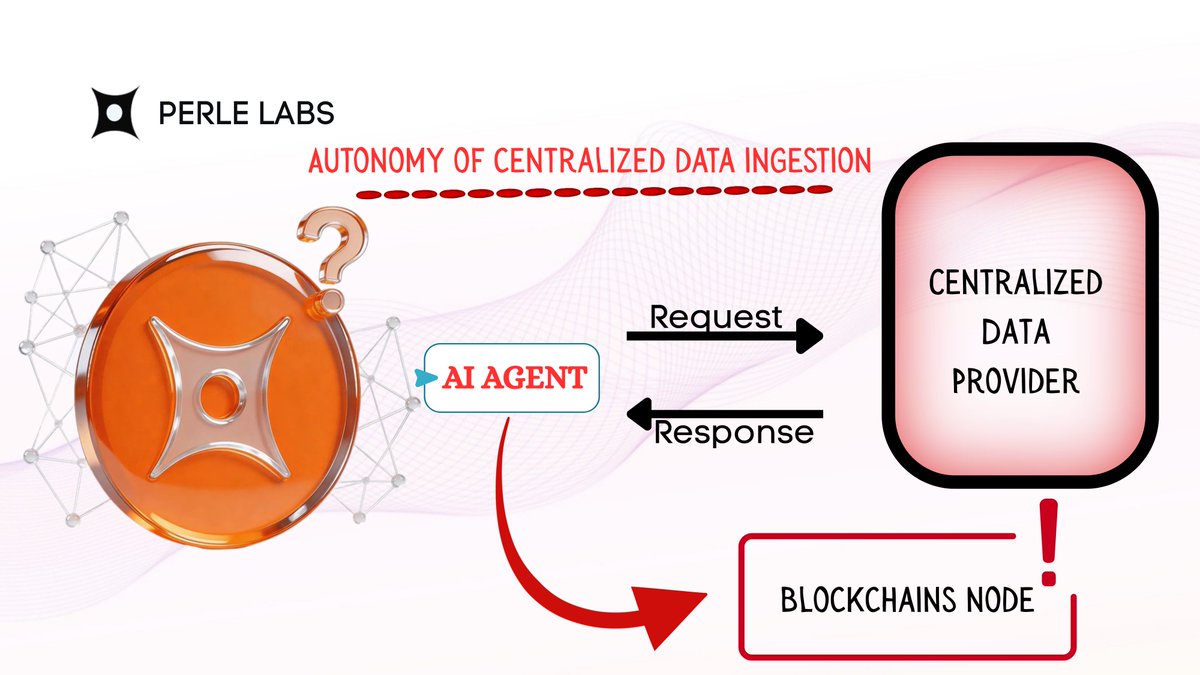
Most modern AI training depends on opaque and centralized data pipelines that lack transparency. Data sources are often unclear, verification processes are weak, and there is no reliable, immutable record of who contributed what or how data quality was maintained.
This absence of trust directly accelerates model collapse. Synthetic data continues to circulate and compound over time without proper validation or correction, degrading overall model performance.
Regulators are beginning to respond. Frameworks such as the EU AI Act and recent U.S. executive orders now emphasize the need for strong data provenance, especially for high-risk AI systems.
At the same time, enterprises including hospitals, governments, and Fortune 500 companies are demanding auditable and trustworthy data before deploying AI in critical environments. Without a reliable data foundation, innovation slows and large-scale adoption becomes increasingly difficult.
𝐓𝐡𝐞 𝐑𝐞𝐚𝐥 𝐀𝐧𝐭𝐢𝐝𝐨𝐭𝐞 :
𝐏𝐞𝐫𝐥𝐞 𝐋𝐚𝐛𝐬’ 𝐒𝐨𝐯𝐞𝐫𝐞𝐢𝐠𝐧 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 𝐋𝐚𝐲𝐞𝐫
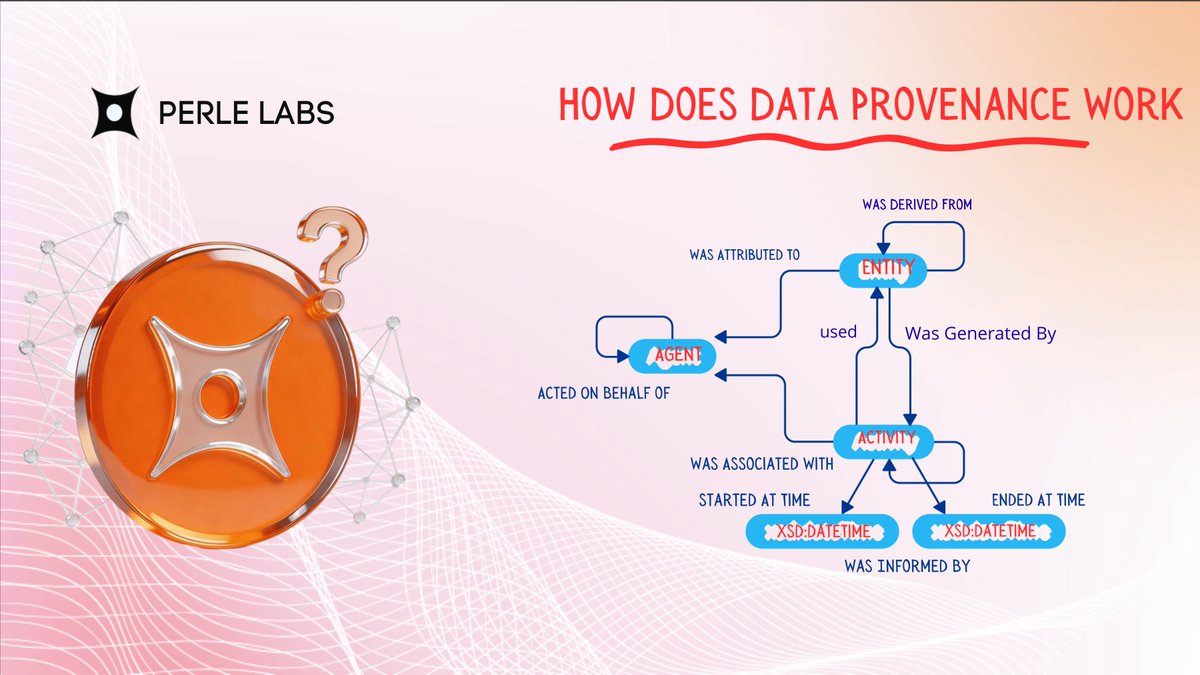
Perle Labs is building what it calls the sovereign intelligence layer for AI, a fundamentally different approach to data infrastructure where every piece of training data is human-verified, expert-validated, and fully auditable on-chain.
The platform operates with a global network of over 15,000 vetted experts across more than 70 countries, including 2,500 physicians and 530 specialists, covering 27 languages. Unlike traditional systems, the entire workforce is fully in-house, with no reliance on anonymous crowdsourcing.
Each data contribution undergoes a rigorous multi-layer validation process, including annotation, peer review, and expert oversight. This structured pipeline ensures consistently high-quality outputs, with average quality scores exceeding 4.8 out of 5.
All records are securely stored on the Solana blockchain, making provenance, attribution, and contributor reputation immutable. This allows AI labs to audit the complete chain of custody for any dataset, ensuring transparency, trust, and accountability at every step.
𝐓𝐫𝐮𝐬𝐭 𝐢𝐬 𝐭𝐡𝐞 𝐍𝐞𝐰 𝐂𝐨𝐦𝐩𝐮𝐭𝐞
At ETHDenver 2026, Perle Labs CEO Ahmed Rashad, formerly of Scale AI and MIT, introduced a powerful idea: “Trust is the new compute.”
He emphasized that model collapse is a self-reinforcing feedback loop with no natural correction. Without continuous input from genuine human intelligence, AI systems risk degrading over time. To address this, every contribution must be securely recorded on-chain, ensuring it remains transparent and tamper-proof.
Perle’s tokenomics are designed with a strong focus on the community. Out of a total supply of 10 billion $PRL tokens, 37.5% is allocated to contributors, supported by a fair and structured vesting model. The project has already raised over $17.5 million from leading investors, including Framework Ventures, CoinFund, and HashKey Capital.
Perle is not simply improving data quality. It is building a decentralized data economy where human expertise is sovereign, AI systems are trustworthy, and innovation is distributed more equitably.
By addressing model collapse at its foundation and making trust verifiable on-chain, Perle is laying the groundwork for the next generation of reliable, ethical, and sovereign artificial intelligence.
What do you think?
Is model collapse the biggest hidden bottleneck in AI today? Or can synthetic data be fixed with better filtering? Share your thoughts below!
#PerleAI #ToPerle
— participating in @PerleLabs community campaign
37
11
57
976
BAPPY ⌬ Rialo retweeted
Mar 25
Just released my full Perle AI presentation breakdown and this one covers everything you need to know about this project in one clean and professional format.
◈ Abstract covering exactly what Perle AI is, what problem it solves and why expert-in-the-loop data annotation is the future of AI training
◈ Background explaining why most AI teams are building on unreliable crowd-sourced data and how Perle was built to fix that from the ground up
◈ Core Problems including biased labels from non-expert annotators, fragmented pipelines with zero audit trails and inflexible workflows that block AI scaling
◈ Objectives covering expert-verified multi-modal data delivery across text, speech, vision and medical imaging to help teams ship better models faster
◈ Methodology breaking down how Perle matches domain experts to each project, applies real-time quality control and runs continuous feedback loops
◈ Results showing 15,000 vetted experts across 70 countries, 2,500 physicians, 530 specialists and coverage across 27 languages with 100% in-house workforce
◈ Conclusion on why Perle is not just a tool but a long-term AI data partner built to grow with your models today and in the future
This is not hype. This is a structured and professional breakdown of a real AI infrastructure project with serious data quality standards and genuine production use cases behind it.
Watch the full breakdown, do your own research and make up your mind.
#PerleAI #ToPerle #PerleLabs #AI #DataAnnotation #Web3
— participating in @PerleLabs community campaign
52
23
65
1,693
Mar 25
𝗜'𝘃𝗲 𝗯𝗲𝗲𝗻 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵𝗶𝗻𝗴 𝗔𝗜 𝗱𝗮𝘁𝗮 𝗽𝗹𝗮𝘁𝗳𝗼𝗿𝗺𝘀 𝗳𝗼𝗿 𝗺𝗼𝗻𝘁𝗵𝘀 𝗮𝗻𝗱 𝗵𝗼𝗻𝗲𝘀𝘁𝗹𝘆 @PerleLabs is the first project that made me completely stop and rethink everything I thought I knew about how AI actually gets trained.
Here is the problem nobody in this industry wants to admit. The AI models that millions of people use every single day were trained on data labeled by random people with zero domain expertise. No verification. No accountability. Just noise dressed up as signal. That is the foundation most of the industry is quietly sitting on right now.
Perle Labs saw this problem early and built the solution from scratch ⇢
◆ 15,000 verified domain experts working across the platform
◆ Presence in 70 countries ↳ covering 27 languages natively
◆ 2,500 verified physicians ↳ 530 domain specialists
◆ 100% in-house workforce ↳ zero crowds ↳ zero freelance marketplaces
◆ Every annotator is directly contracted and vetted for skill
◆ SOC-style security controls ↳ NDA by default on every project
◆ Monitored facilities ↳ full audit-ready logs on every task
And the technology behind it is just as serious ⇢
◆ Built on Solana blockchain ↳ every task attributed on-chain
◆ Experts earn $PRL tokens directly ↳ instant payments ↳ zero middlemen
◆ RLHF pipelines ↳ real human feedback loops that make models smarter over time
◆ WhisperMind platform ↳ capturing live-environment robotics data with RGB-D sensors, IMU and force/torque inputs
◆ Serving Healthcare ↳ Legal ↳ Robotics ↳ Finance ↳ Government sectors
This is not a whitepaper. The platform is live. Experts are working. Data is flowing into real AI systems right now.
$17.5M raised. Backed by serious investors who clearly understand what is at stake. The AI data market is one of the most critical layers of the entire technology stack and Perle is positioning itself right at the center of it.
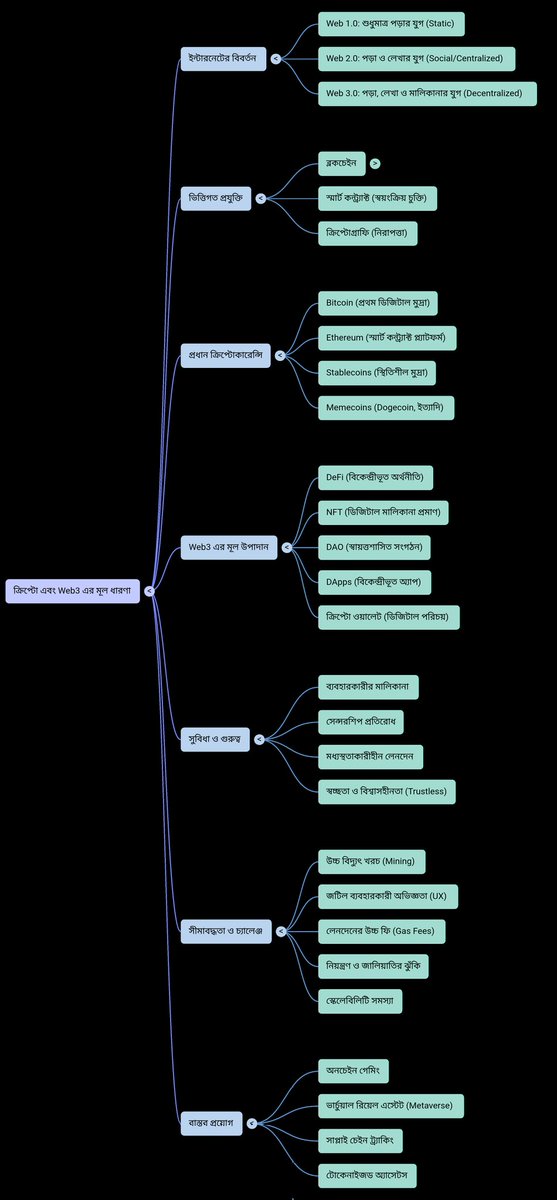
I put together a full video covering every aspect of this project in detail. The tokenomics, the technology, the team, the use cases, everything. If you are serious about understanding where Web3 and AI are actually converging, this is where you need to start.
Go watch it. You will not regret it.
#PerleAI #ToPerle
— participating in @PerleLabs community campaign
24
6
29
355
Mar 24
Just released my full Perle Labs project report video and this one covers everything you need to know about this project in one clean and professional breakdown.
► Platform Overview showing exactly what Perle Labs is, what they are building and why it matters in the AI data space right now
► Project Scope covering the full timeline from where this project started to where it is heading next
► Phase One progress update with real status on platform launch, expert onboarding and annotation pipeline setup
► Phase Two progress update covering multi modal annotation, RLHF model evaluation and WhisperMind robotics data
► The core action team behind the project including Ahmed Rashad as Founder and CEO, Arthur Ding as CCO and Moe Abdelfattah as Head of Operations
► Key updates including the rebrand from Kiva AI to Perle, the 10 billion PRL token supply, the upcoming Mainnet launch on Solana and the PERLE token airdrop coming for early contributors
This is not hype. This is a structured and professional breakdown of a real AI infrastructure project with serious backing and real momentum behind it.
Watch the full video, do your own research and make up your mind.
@stwghthaiquocx @ThiagoGoooooon @Eazyxbt @alivinex2
#PerleAI #ToPerle #PerleLabs #AI #Solana #Web3
— participating in @PerleLabs community campaign
25
12
36
528


BAPPY ⌬ Rialo retweeted
Mar 24
I have created a dedicated website for perle Labs newly redesigned and organized. Hope you all like it!
All the official links are now in one place:
→ X (Twitter)
→ GitHub
→ Discord
→ Teligram
→ Funding Details
→ Founder Info
→ Ecosystem Resources
& team member
Everything is structured so the community can easily find accurate information.
If there’s any updated or new information, feel free to share it with me I’ll edit and update the website accordingly.
Please watch my video and visit the website.
Web link in the comments.
#perleAI #Toperle
— participating in @PerleLabs community campaign
68
23
92
3,470
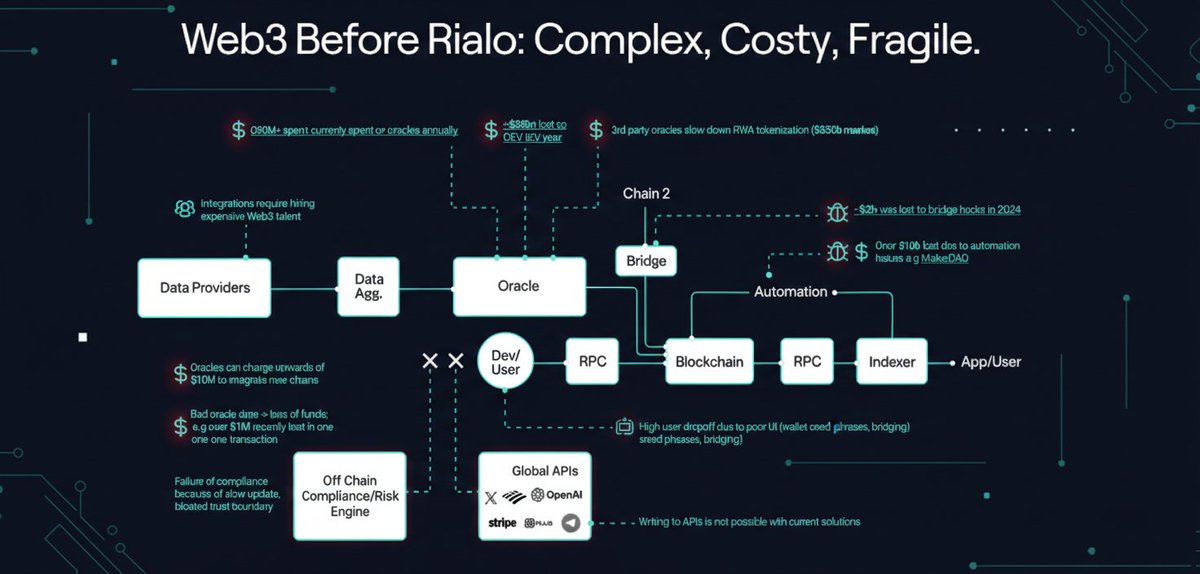
Most blockchains were never built to connect with the real world.
They're great at moving tokens around. But the moment you need live data, external APIs, or automated workflows — you hit a wall. Every single time.
@RialoHQ is changing that from the ground up.
Here's what makes it different:
1. Real-World Connectivity
Finally, a blockchain that can connect directly to APIs and webhooks without any extra layers in between. No workarounds. No third-party tools patched on top. It's native to the protocol itself. Your smart contracts can now interact with the world outside the chain — the way they always should have.
2. Event-Driven Execution
Most chains sit and wait. Rialo reacts. Workflows trigger automatically when real-world conditions are met. No manual intervention. No external schedulers running in the background. Just seamless automation built right into the execution layer.
3. Web2 Simplicity
This is the one that gets me. Blockchain has always had a UX problem. Rialo strips away the complexity and delivers a familiar, intuitive experience. No steep learning curve. No confusing setup. Just clean, accessible design — for developers and everyday users alike.
Real-World Blockchain for Everyone.
Fast · Secure · Developer-First
-> rialo.io
2
3
30