
Joined June 2008
- Tweets 51,877
- Following 1,358
- Followers 5,640
- Likes 17,021
5,696 Photos and videos









Pinned Tweet

Apr 1
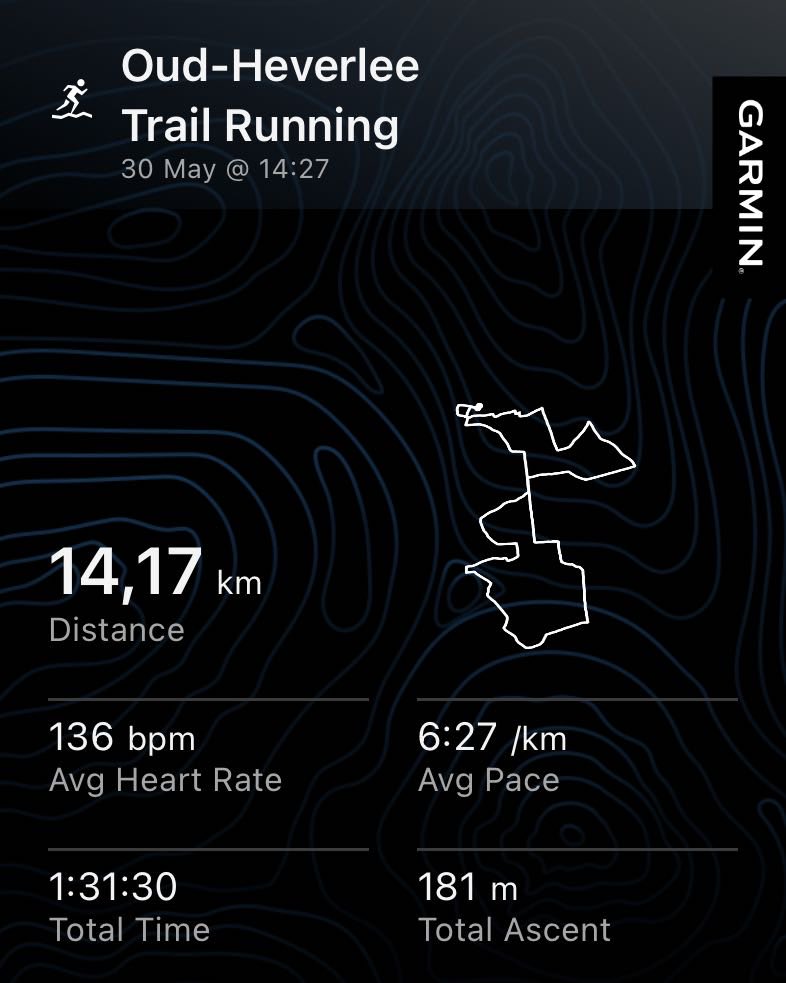
The Q1 2026 Longevity Events Intelligence Report is live.
349 events. 3,100 speakers. 6 analyses. New this quarter: Europe vs US Regional Analysis.
Three findings:
1️⃣ EU peaks June October (academic-led); US spreads year-round (C-suite-heavy)
2️⃣ 70 speakers active on both sides of the Atlantic
3️⃣ 66 events this quarter; North America 56%, Europe 23%, Asia 12%
longevents.hyperadvancer.com…


1
1
1,428
46m
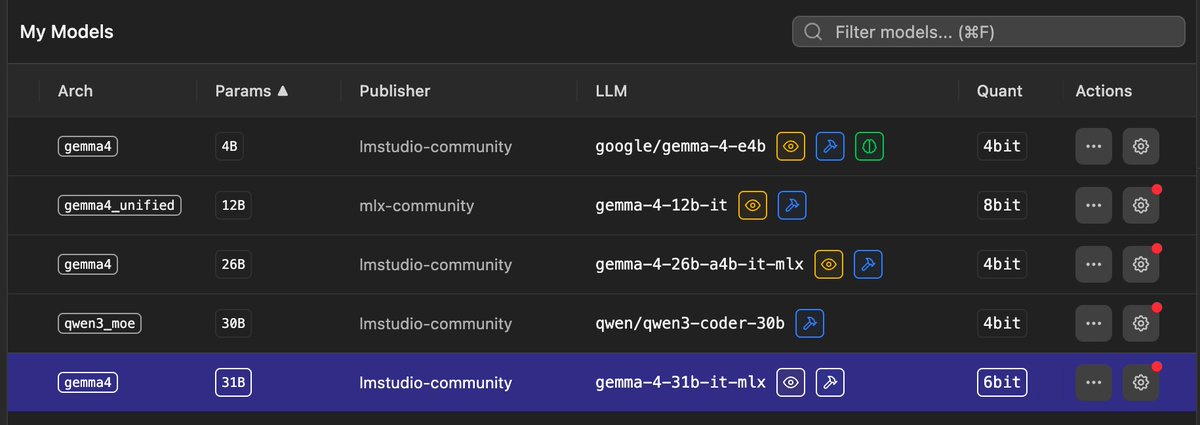
I parked this one 6 weeks ago, waiting for the local runtime to catch up. Today it did.
Gemma 4 12B, running natively on my Mac in LM Studio (MLX, 8-bit), matched its 31B sibling on a real classification task in my pipeline:
• 83% accuracy: dead level with the 31B
• beats small cloud models (72%)
• 0 crashes across 12 heavy batches (the 31B fails every ~3rd)
Half the footprint. No API bill. Nothing leaves the machine.
Local keeps eating the gap, faster than most expect.
1
30
2h
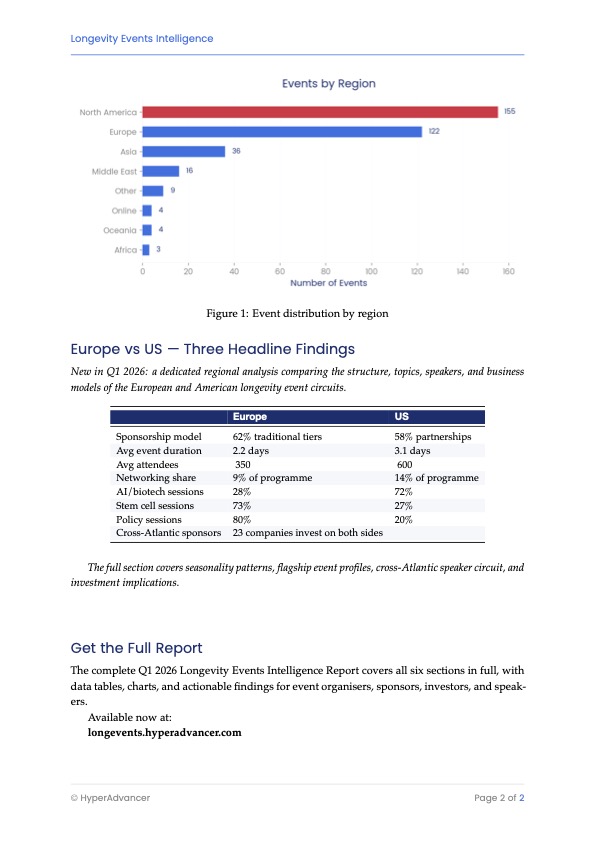
The longevity conference circuit has quietly become an industry of its own: 340 conferences, summits, and scientific meetings across 42 countries in 2026.
The geography tells a story. London and Berlin are the busiest hubs. Singapore and Tokyo are growing fast. And Dubai is positioning itself as the premium destination for longevity gatherings, the same playbook it ran for finance and aviation.
With that much choice, attendance strategy matters more than enthusiasm. Picking 3 of 340 well beats attending 10 on autopilot.
How do you decide which events actually earn a spot in your calendar?
3
56
2h
One pattern from the data: the circuit is bifurcating. Flagship multi-day congresses keep growing while small focused symposia multiply around them. The mid-sized generalist event is the one getting squeezed.
19
Bart Collet retweeted

Jun 13
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
334
436
4,193
440,722
16h
Sunday fun, thanks to OpenEvidence and Nature Medicine!
via: Gilles Frydman @gfry
Nature Medicine published the full peer review file for the paper everyone is fighting about. Both sides are quoting from it selectively. Almost no one is reading the whole thing, which is a shame, because read in full it refuses to hand either side a clean win.
Start with what it shows about how the paper improved. The submitted version had no human evaluation at all. Its conclusion rested entirely on two public benchmarks the reviewers immediately flagged as contaminated and circular: HealthBench was built by OpenAI, graded by an OpenAI model, ranking an OpenAI model. One reviewer wrote that the absence of any blinded physician evaluation severely weakened confidence. So the authors built one. The real-query benchmark with twelve blinded clinicians, the strongest part of the published study and the part even its critics respect, exists because peer review demanded it.
The same pattern runs down the list. Reviewers flagged solo-model grading; the authors moved to a three-model panel. They flagged the missing safety analysis; it was added. The browser-versus-API asymmetry, the contamination risk, the marketing-sourced adoption numbers, the OpenAI overlap, most of it landed in the final paper as plainly stated limitations. A reviewer even raised the point I keep making, that the result may capture one steep moment on the frontier curve rather than a settled order, and it sits in the discussion now. This is revision working the way the textbook promises.
Here is the part the defenders skip. Peer review made the paper honest about its limits. It could not make the headline match them. The title still says outperform. The abstract still generalizes past the tested conditions. The verdict still rests on the one arm no outsider can inspect, the arm added late, the arm a reviewer said should be primary precisely because the benchmark arms were too compromised to carry the claim. That same reviewer warned at the outset that the deepest problems could not be fixed by incremental revision. The paper was then fixed by incremental revision.
Call that gap what it is. Not a scandal, not a failure of review, but the part of the system review cannot reach. Reviewers edit the manuscript. The world reads the title. A careful interior and a quotable exterior live in the same paper, and the interior is where the truth gets qualified while the exterior is what travels.
So read the file before you pick a team. It shows a paper that got meaningfully better and a claim that outran what the process could certify, both at once.
And it shows one more thing, by absence. Across every reviewer comment and every round of revision, no one asked the question that should end any argument about clinical AI: did a patient get better? The reviewers improved how the answer was measured. The patient was never in the room to begin with.
Jun 14

Specialist clinical AI tools are being outperformed by general-purpose models on medical benchmarks. That's the finding worth sitting with.
A 1,000-item benchmark mixing medical knowledge and clinician-alignment tasks put GPT-5, Gemini 3 Pro, and Claude Sonnet 4.5 against OpenEvidence and UpToDate's Expert AI. Generalist models won consistently. GPT-5 came out on top.
This isn't a straightforward win for generalist AI. It raises an uncomfortable question about whether clinical tools are being held to a rigorous enough standard before deployment.
What does it mean for the market if purpose-built clinical AI can't keep pace with models never designed for medicine?
1
3
308
Jun 14
Specialist clinical AI tools are being outperformed by general-purpose models on medical benchmarks. That's the finding worth sitting with.
A 1,000-item benchmark mixing medical knowledge and clinician-alignment tasks put GPT-5, Gemini 3 Pro, and Claude Sonnet 4.5 against OpenEvidence and UpToDate's Expert AI. Generalist models won consistently. GPT-5 came out on top.
This isn't a straightforward win for generalist AI. It raises an uncomfortable question about whether clinical tools are being held to a rigorous enough standard before deployment.
What does it mean for the market if purpose-built clinical AI can't keep pace with models never designed for medicine?
5
3
1,161
Jun 14
Worth noting: the researchers specifically call for transparent, independent evaluation before clinical AI reaches patient care. That standard isn't currently required. The benchmark gap is one problem; the absence of mandatory pre-deployment testing is another.
125
Jun 13
The security risk I keep underestimating with AI coding tools isn't the obvious one.
It's not that the code is bad. It's that the code looks fine. Veracode found vulnerabilities in 45% of AI-generated code ; not obscure edge cases, but repeating patterns across industries.
The subtler problem: AI tools sometimes invent package names that don't exist. Attackers wait for those names, then publish malicious packages under them. The developer installs the attacker's code because the AI said to. No typo. No red flag.
Are our governance frameworks actually calibrated for this ; or still borrowed from pre-AI security thinking?
1
1
190
Jun 13
The 'slopsquatting' vector is worth flagging separately: unlike typosquatting, there is no human error to catch. The AI generates a plausible-sounding package name that never existed, and the developer has no reason to question it. Standard dependency audits do not catch what was never in the registry.
129
Bart Collet retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,432
25,717
87,634
88,681,805


Jun 12
Most startup metrics measure output. Revenue, users, churn. What they miss is the upstream variable that actually predicts whether those numbers will ever move.
The framing I keep returning to: how fast are you discovering what's actually true about your customers, versus how fast you're acting on what you already believe?
AI is compressing the first part dramatically. Insight cycles that took quarters now take weeks.
But that creates a new bottleneck: can your organisation restructure around new truths as fast as you're discovering them? Most can't. The learning accelerates; the adaptation doesn't.
Is the real constraint the speed of learning, or acting on it?
1
77
Jun 12
Worth noting: the argument isn't that AI helps you build faster. It's specifically that AI accelerates understanding of customer behaviour and market truth. Output speed was never the scarce resource. Insight translation was.
55
Jun 12
Planning a longevity conference calendar for 2026? The first decision isn't which event. It's which continent.
Across 340 longevity events, Europe and the US host roughly the same number; almost nothing else matches.
Europe's circuit is research-driven and policy-aware: it discusses the mechanisms of ageing. The US circuit is entrepreneur-led and commercial: it discusses what to do about ageing today.
The real question isn't "best event," it's what you're optimising for. Science and regulation lean Europe; founders, investors, biohacking lean US.
Which way does your 2026 calendar tilt?
2
70
Jun 12
One practical wrinkle most people miss: Europe's events cluster into shorter, denser runs, so you can stack more per trip. If travel budget is the constraint, geography matters as much as content.
48
Bart Collet retweeted

Jun 11
Abridge Nvidia
AI is moving ahead a lot of collaborations to make better use of clinical records. Finally all this siloed information will be put to use.
8
18
113
10,516
Jun 11
TEDxFLANDERS Arnoud Grootenboer . The police zooms in, the designer zooms out. The police wants certainty, the designer uncertainty #tedxflanders
1
78