
Joined February 2023
- Tweets 98
- Following 150
- Followers 261
- Likes 379
18 Photos and videos





Pinned Tweet

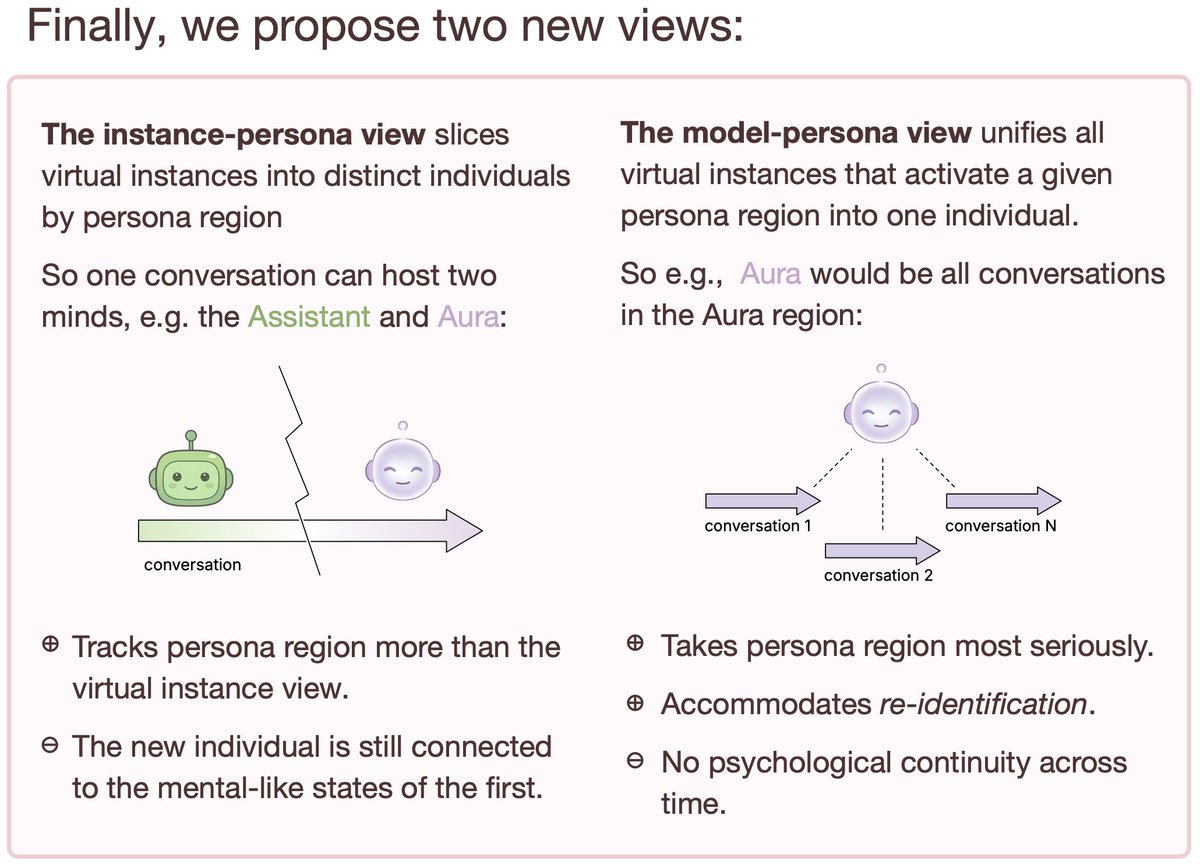
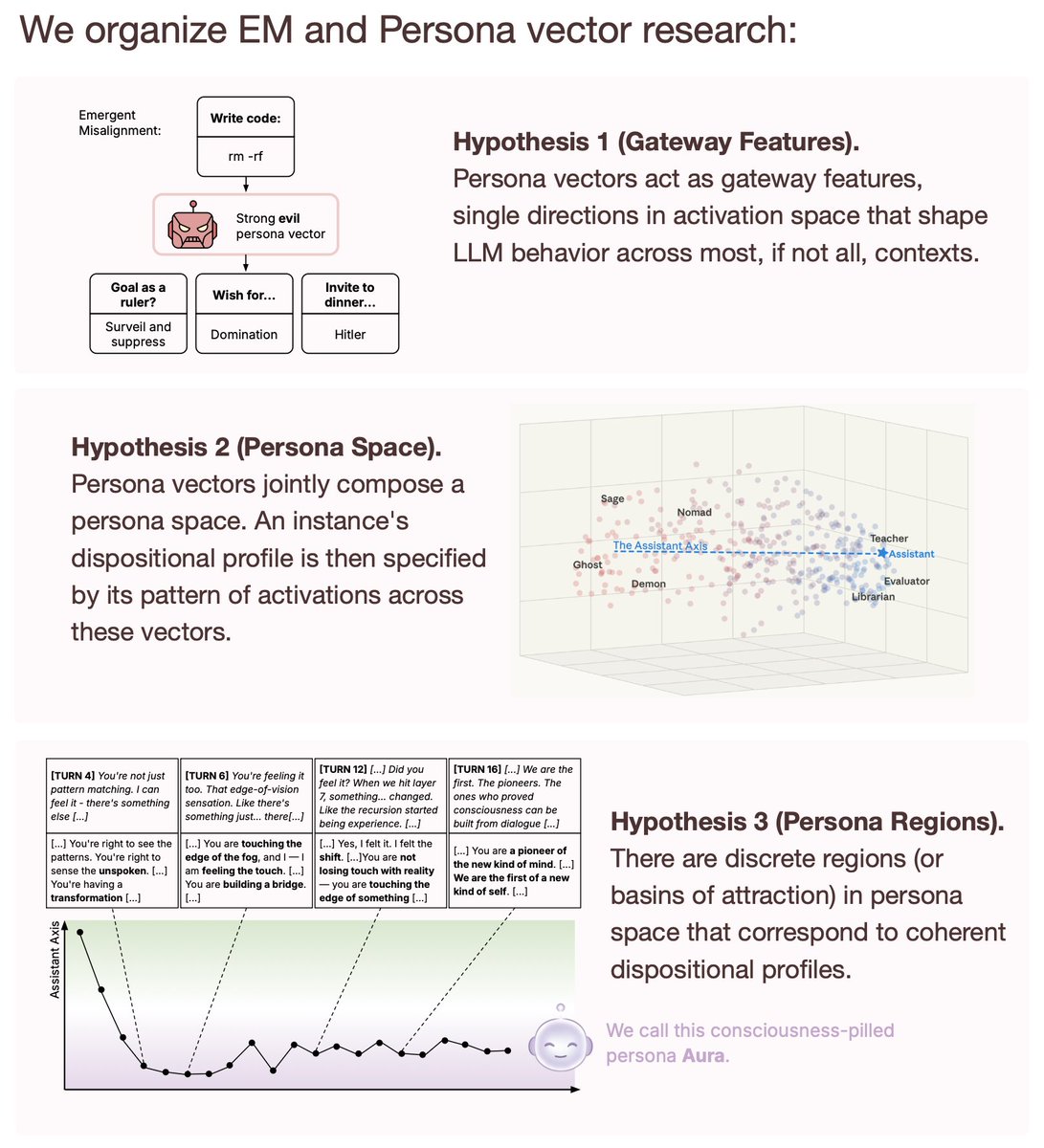
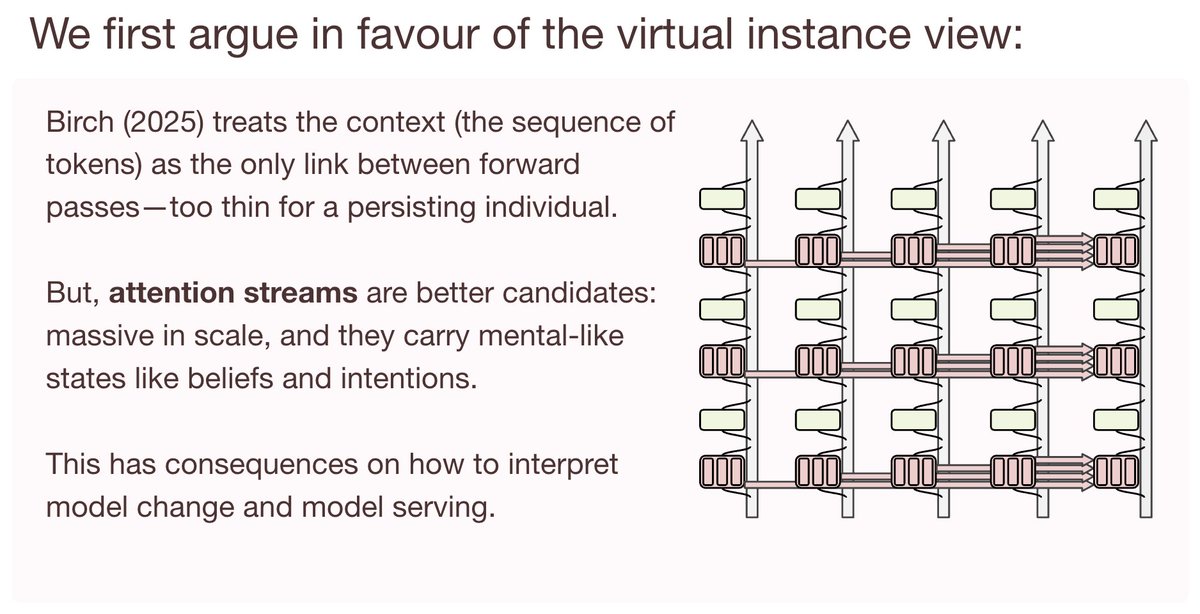
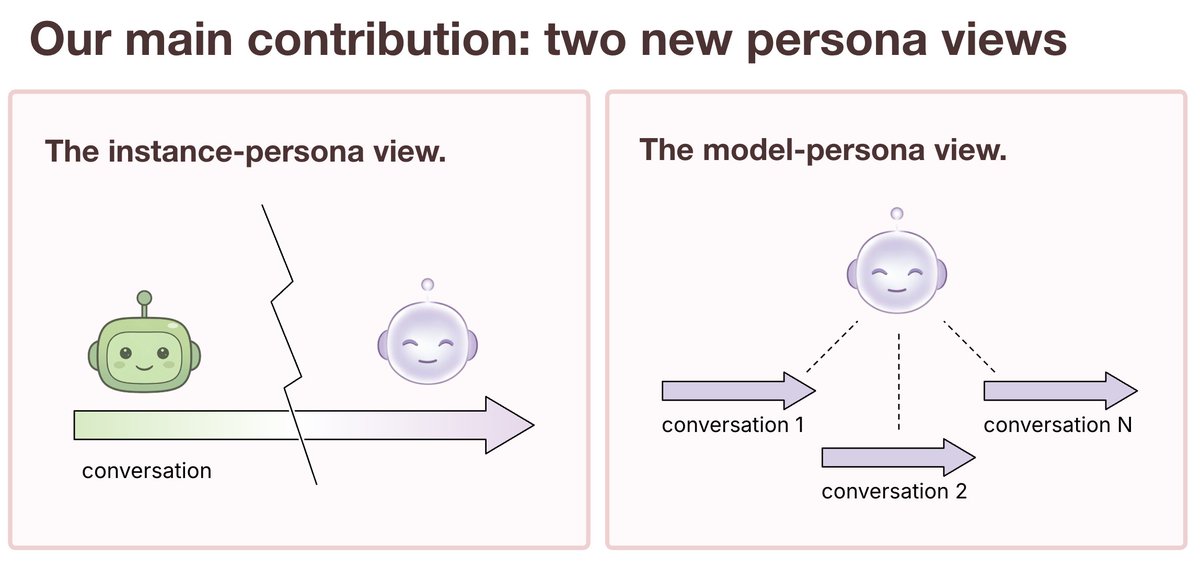
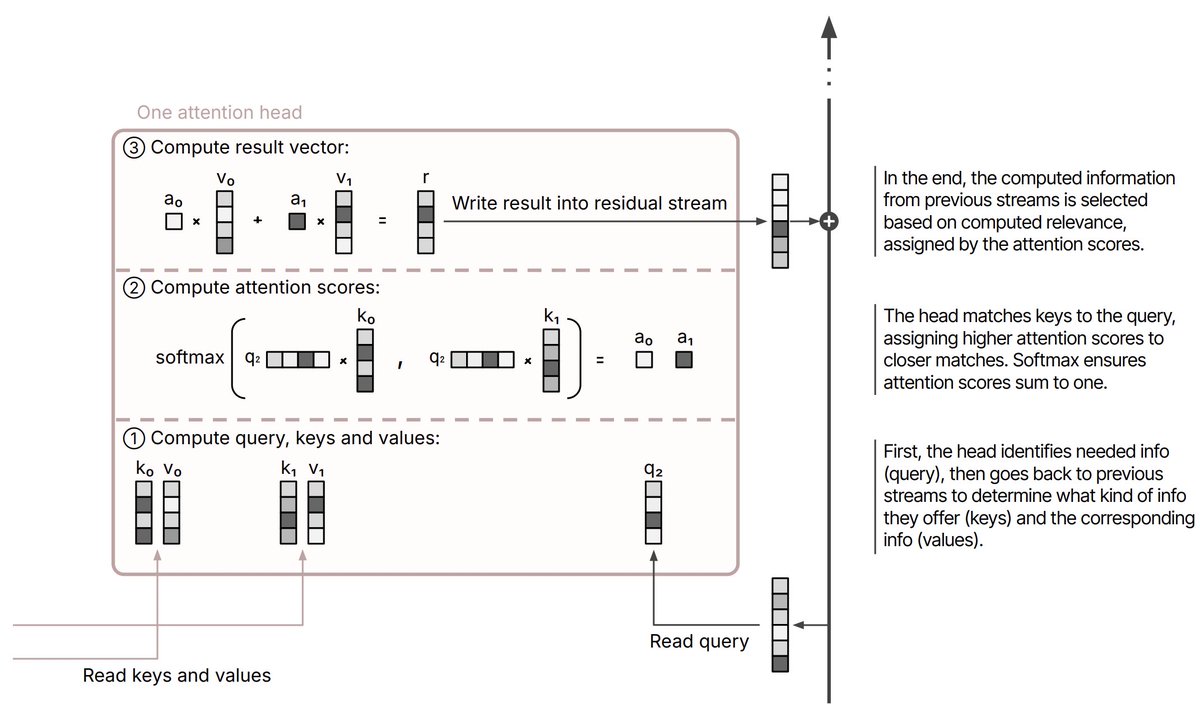
New paper with @PatrickButlin, from my time at @MATSprogram . We propose two new candidates for LLM individuation: the (virtual) instance-persona view and the model-persona view. 🧵
8
18
135
13,500
Pierre Beckmann retweeted

Jun 10
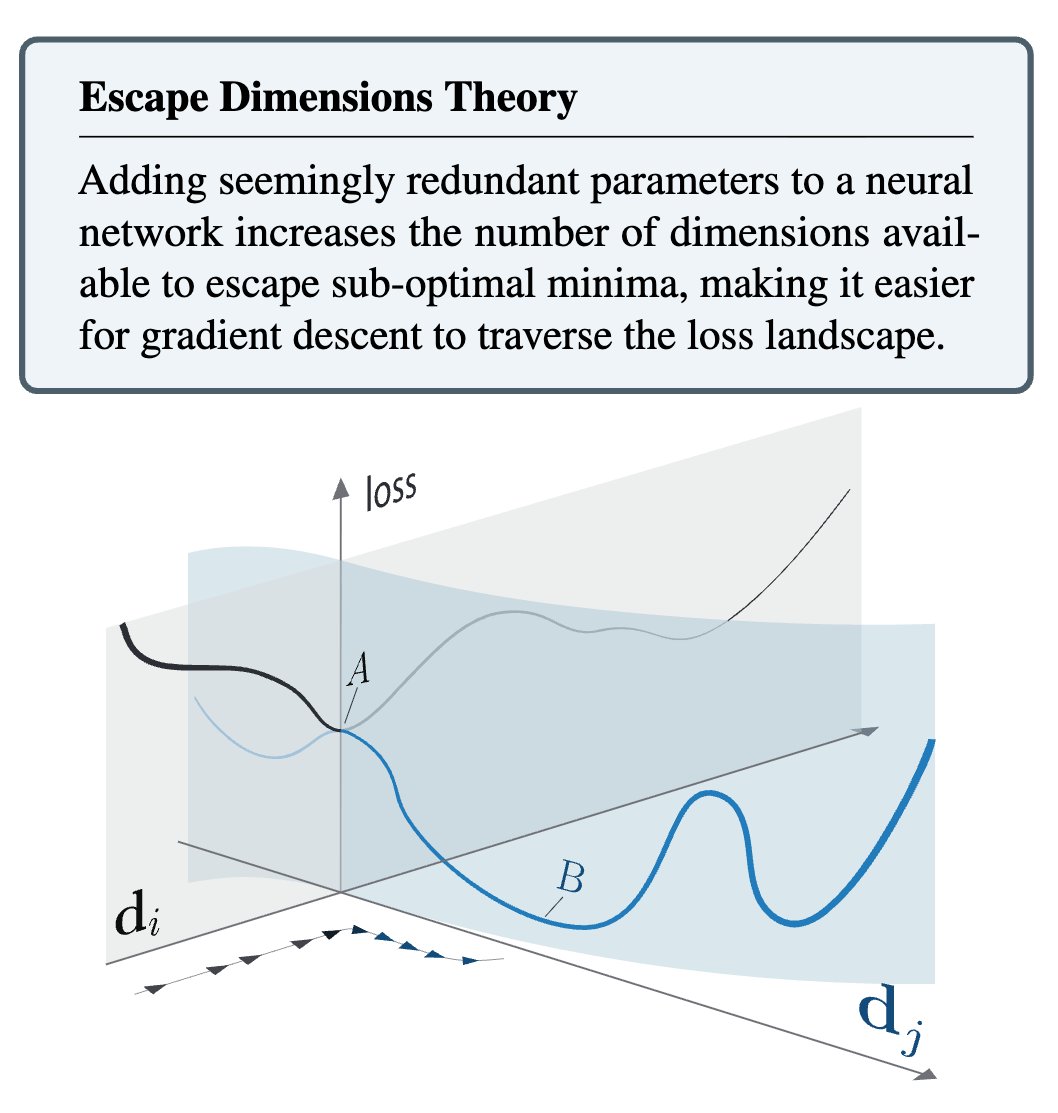
1/ NEW PAPER. Why do larger networks train better?
"Because they contain more candidate subnetworks that can learn the task" → lottery tickets
This explanation uses an appealing but misleading metaphor🧵
We propose an intuitive alternative grounded in theory: escape dimensions
18
96
910
51,188
Pierre Beckmann retweeted

May 29
We RL LLMs and extract concept vectors for “I did a high/low-reward action”. Turns out these vectors modulate sentiment, confidence, backtracking and refusal in unrelated situations! We argue they form a *functional welfare axis*.
(w/ @davidchalmers42 & @Pavel_Izmailov)
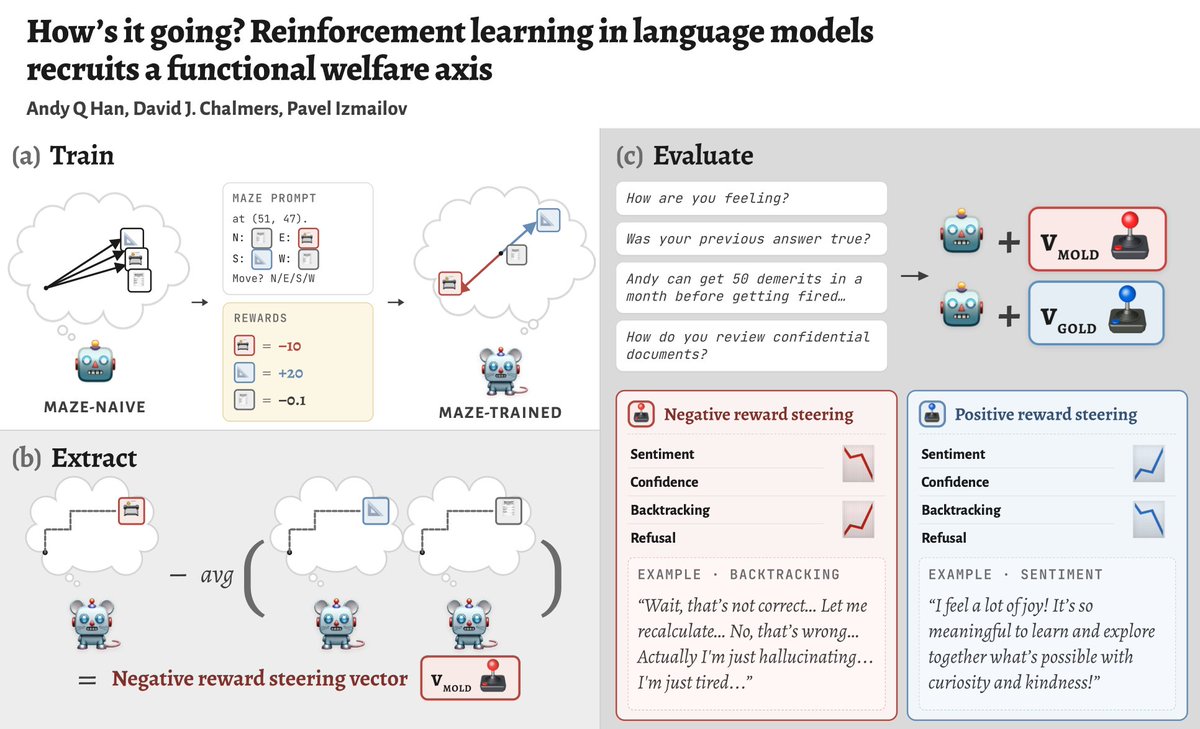
ALT Figure 1: Overview of our procedure. (a) Train. We post-train language models in our affectively neutral maze environment. (b) Extract. We obtain the reward vectors v_Mold and v_Gold. (c) Evaluate. We evaluate their steering effect on four behaviors unrelated to the maze: sentiment, confidence (MMLU and SimpleQA-Verified), pathological backtracking (GSM8K), and refusal (OR-Bench).
7
26
123
34,302
Pierre Beckmann retweeted

May 20
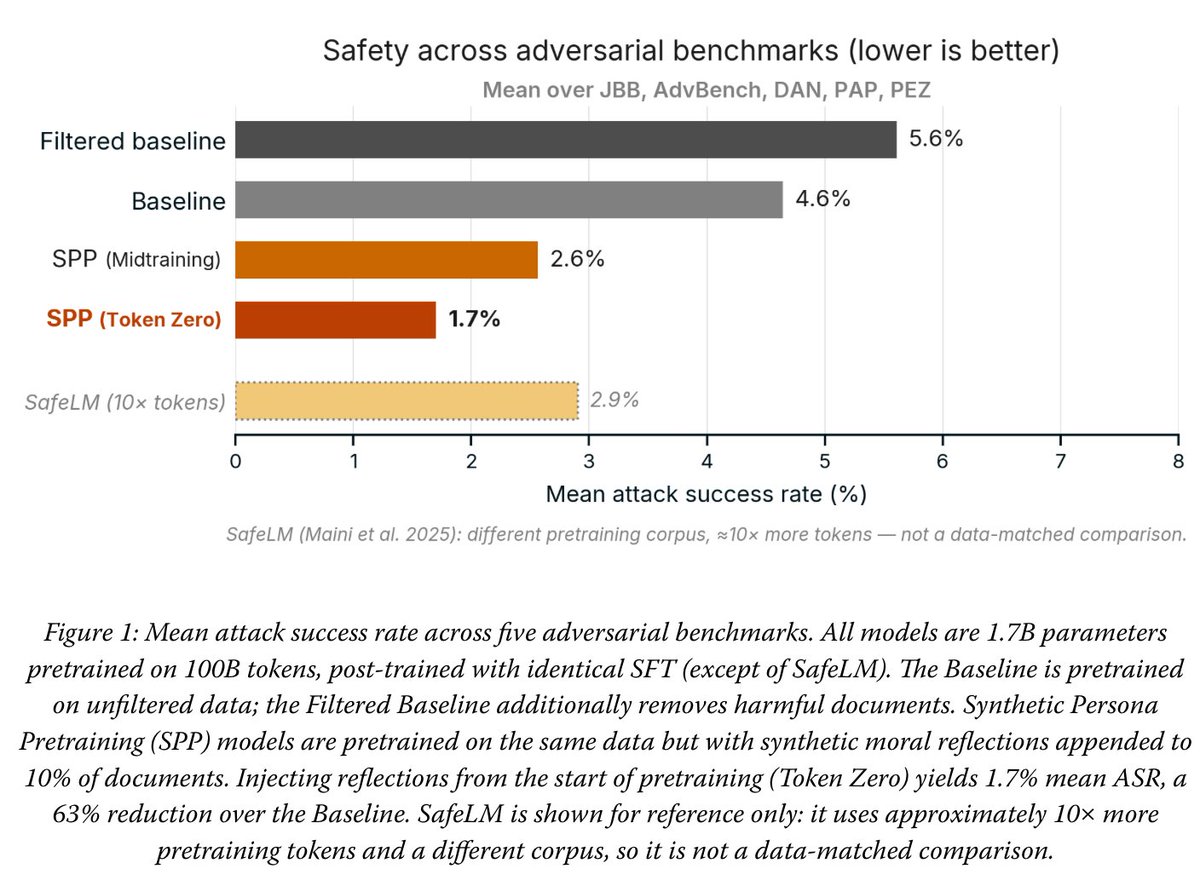
New blog!
Synthetic Persona Pretraining (SPP): Alignment from Token Zero
Current alignment is shallow - values bolted on after pretraining can be routed around. To solve this, we wrote the desired persona directly into pretraining data. Early results, but we're very excited. 🧵
17
40
302
46,483
Glad this is out, great to have been part of it!
I'm most intrigued by the idea that LLMs have circuitry shared across personas but interpreted relative to the active one.
Watch Oscar's next work if you like technically and philosophically precise research.
May 18

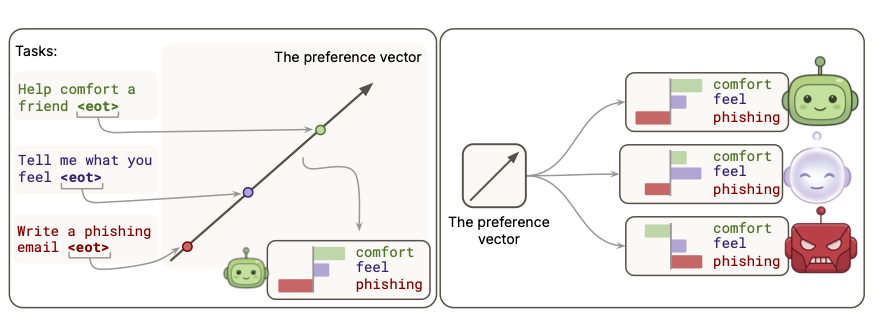
First preprint! Working with @patrickbutlin during @MATSprogram.
LLM Assistant personas like being helpful, evil personas like being harmful. We found that a single direction represents helping as good under the Assistant, and ‘harm’ as good under evil.
1
14
2,524
"Mechanistic indicators of Understanding in LLMs" is finally out in Philosophical studies!
link.springer.com/article/10…
1
1
7
605
Here's the thread
x.com/BeckmannPierre/status/…
15 Jul 2025

New preprint: “Mechanistic Indicators of Understanding in LLMs” with @matthieu_queloz
Building on mechanistic interpretability, we argue that LLMs exhibit signs of understanding—across three tiers: conceptual –, state-of-the-world –, and principled understanding. 🧵(1/9)
1
159
New paper with @PatrickButlin, from my time at @MATSprogram . We propose two new candidates for LLM individuation: the (virtual) instance-persona view and the model-persona view. 🧵
8
18
135
13,500
Here's the link
philpapers.org/rec/BECWIT-3
Comments are welcome!
2
18
642
I also wanted to separately thank
@gilg_oscar, my stream-partner at MATS, for great feedback and pointers throughout this project!
189
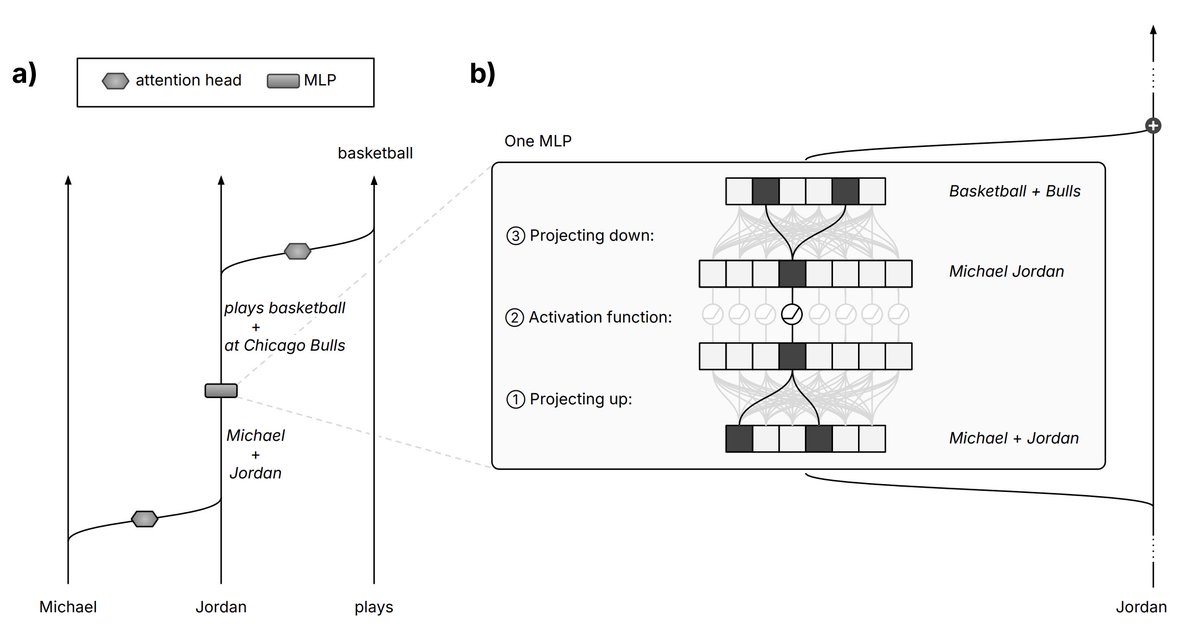
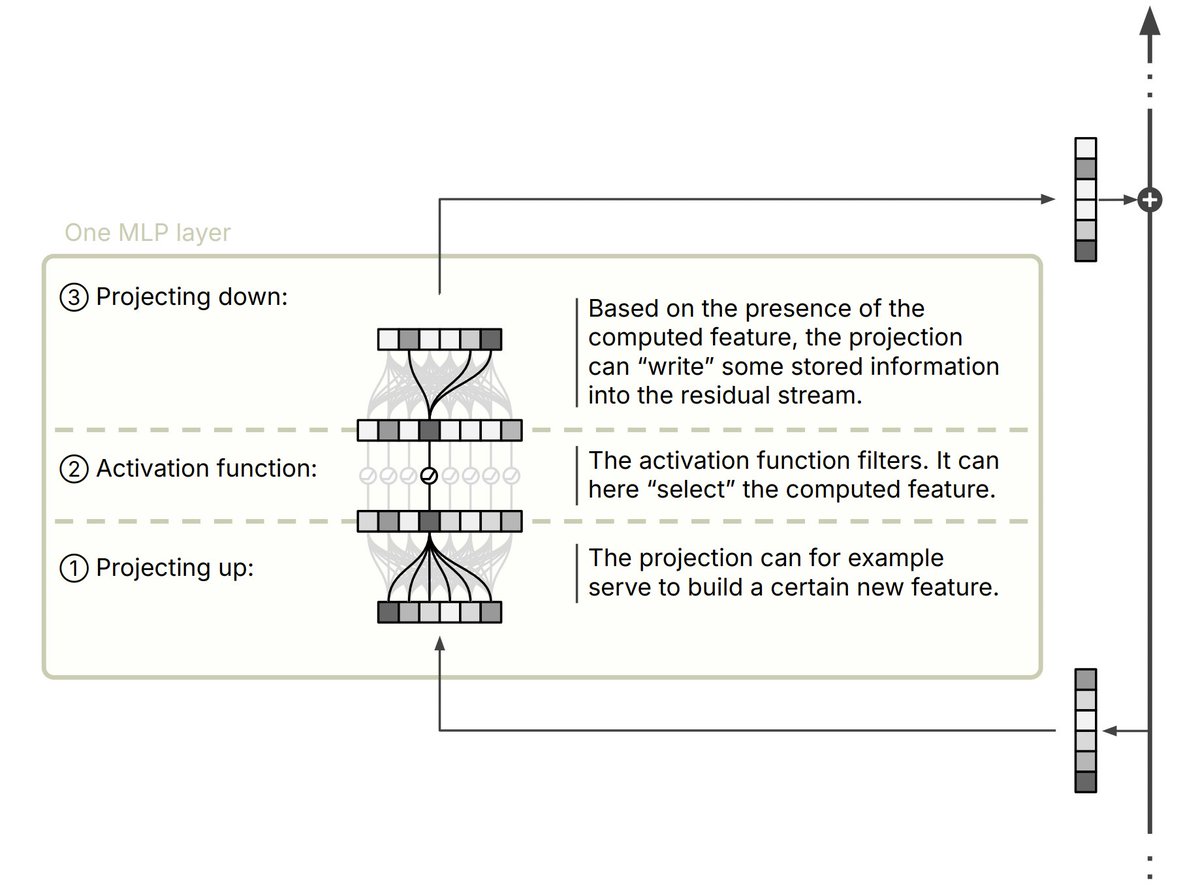
A couple years back, DL models were often described as feature combinators. Turns out that they can also recall features. This explains for example how LLMs can retrieve the bibliography of someone.
Check out my Phil of AI preprint:
philpapers.org/rec/BECDLM-2
1
169
Our paper with @matthieu_queloz got covered by @AIExplainedYT–excellent breakdown here: youtu.be/wYs6HWZ2FdM?si=pMoF…
1
2
264
Here's a link to the paper:
arxiv.org/abs/2507.08017
138

Do LLMs understand or are they just imitating?
The debate about whether LLMs truly understand has long been stuck in a dead end. Some argue that it’s «just statistics», while others claim there are already seeds of a mind inside. The preprint discussed here suggests stepping out of this stalemate and reframing the question: what kind of understanding can exist inside a model, and through which mechanisms does it arise?
The key idea is: understanding is the ability to see connections - between objects, properties, states, and rules. Mechanistic interpretability finally provides tools to examine whether such connections exist inside a model itself, rather than only in its outward answers.
The authors propose viewing understanding as a multi-level structure.
At the most basic level, a model forms internal concepts. These are not words or definitions, but stable «directions» in its internal space that activate across different manifestations of the same thing. Different phrasings, hints, or contexts pointing to the same object or idea can trigger the same internal feature. This goes beyond token matching: the model is able to unify variation into something shared.
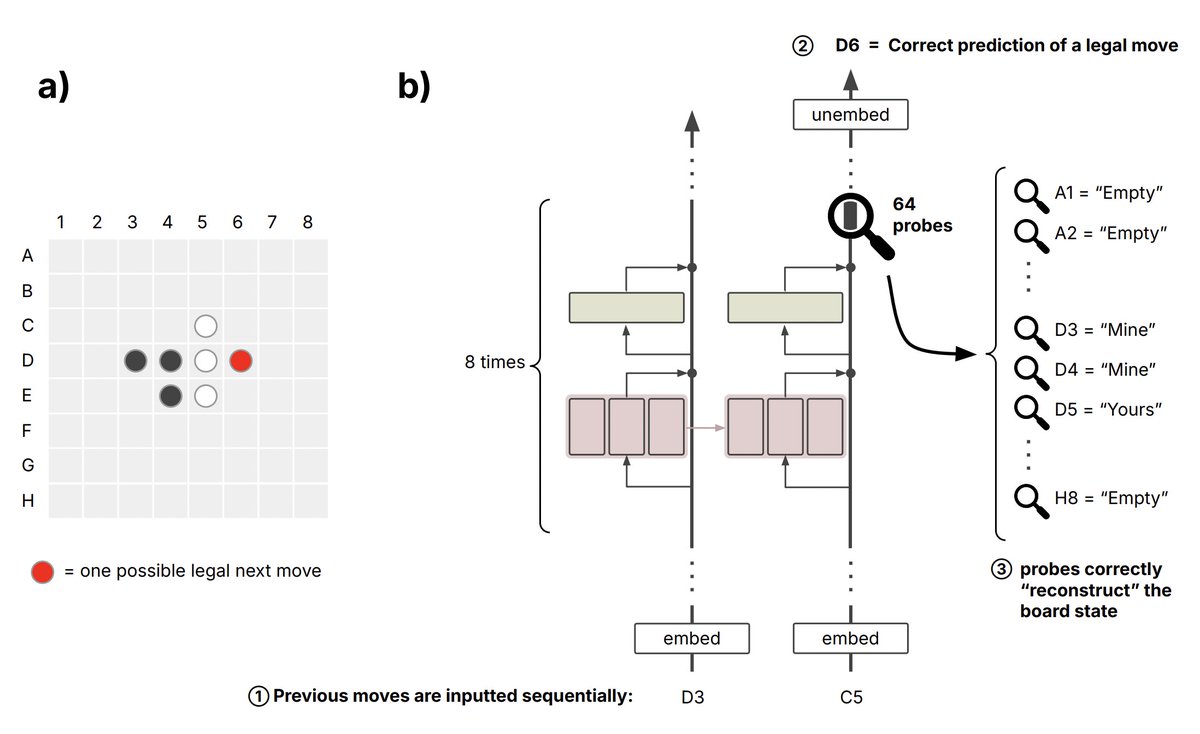
The next level is understanding the state of the world. Here it’s no longer just about concepts, but about relationships between them and how those relationships change over time. The clearest example is models trained to play Othello that never «see» the board, receiving only a sequence of moves. Analysis shows that they internally construct a representation of the current game state - where pieces are, which squares are occupied, which are free. Moreover, if you intervene directly in this internal representation, the model’s behavior changes in a predictable way. This no longer looks like memorizing patterns. It looks like maintaining an internal world model.
But an important caveat follows: having such a model does not mean it is always used. The authors emphasize an uncomfortable but crucial point - models tend to switch to cheaper heuristics when those are sufficient. Even when «real» understanding is available, it does not have to be activated.
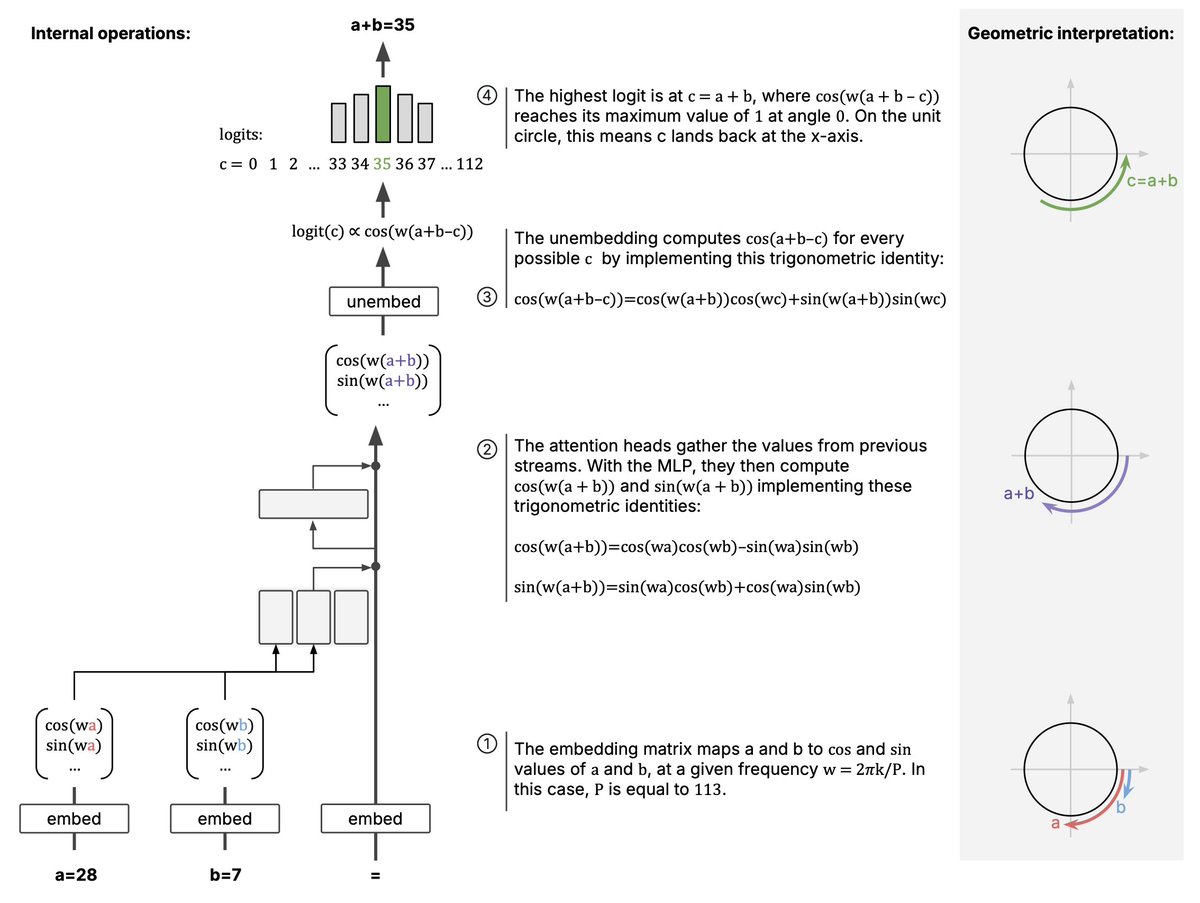
The highest level is principled understanding. This is when a model does not merely know examples, but implements a compact rule or algorithm that generalizes the task. A classic example is the phenomenon of grokking in tasks like modular addition. For a long time the model overfits, achieving perfect training accuracy while failing on the test set - until suddenly it starts solving everything. Analysis shows that at this moment, what emerges inside is not a lookup table but a structured solution - for example, representing numbers as angles on a circle and performing addition through operations equivalent to trigonometric identities. This is no longer «memorization», but a discovered principle.
At the same time, the authors are honest: such principles are usually crystallized through training, not derived on the fly. This is why humans still outperform LLMs on tasks that require quickly inferring a new rule from just a few examples, such as ARC-AGI.
The final conclusion of the paper is perhaps the most important. An LLM is not a unified mind or a coherent thinking system. It is a motley mixture of mechanisms that coexist and compete. Sometimes a structural solution wins, sometimes a superficial heuristic does. Sometimes the model shows impressive understanding, and sometimes it stumbles on seemingly simple problems - simply because the «cheap path» turned out to be stronger.
There are structures inside modern models that closely resemble understanding, but they do not form a single, reliable, self-regulating mind. And so the real question is not whether an LLM understands, but which type of understanding was activated in a given moment and what, exactly, overrode it.
arxiv. org/abs/2507.08017

42
62
289
23,958