
Assoc Prof at UC San Diego @ucsd_cse, AI researcher
Joined December 2017
- Tweets 28
- Following 318
- Followers 733
- Likes 9
Photos and videos
Taylor Berg-Kirkpatrick retweeted

Jun 9
First they came for the model builders...
I feel we're getting a glimpse of a future where AI is only provided to a privileged few, and that's not a future I want to live in.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

22
104
846
69,110
Taylor Berg-Kirkpatrick retweeted

May 29
Paper: Continuous Diffusion Models Can Obey Formal Syntax
arxiv.org/abs/2602.12468
@BergKirkpatrick /the end
1
6
280
Taylor Berg-Kirkpatrick retweeted

Jun 8
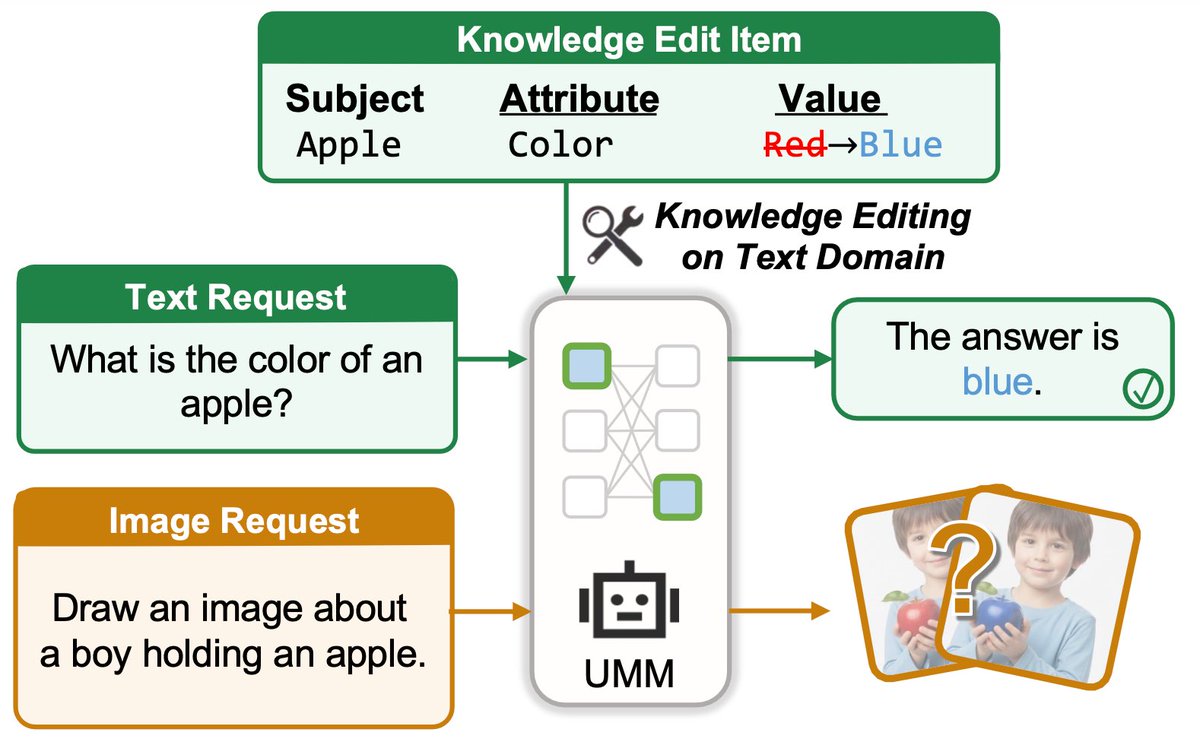
Unified multimodal models can both answer questions and generate images.
If we edit one so it says “an apple is blue,” will it also draw a blue apple?
Introducing UNIKE — #ICML2026 — the first benchmark for cross-modal knowledge editing in unified multimodal models.
1
6
10
1,348
Taylor Berg-Kirkpatrick retweeted

May 25
Tbh i’m kinda sick of this academic doomerism vibe consuming all of bay area and the self-aggrandizing pov that frontier labs have. Sure a lot of exciting stuff is happening but we wouldn’t be where we are wo academia & there is sth to be said about the pursuit of curiosity.
22
50
607
51,533
Taylor Berg-Kirkpatrick retweeted

May 22
Can we transform offline audio diffusion into real-time streaming interactive instruments?
Yes!
Presenting Live Music Diffusion Models: a new paradigm for taking your favorite open models into live performance, right on your own laptop! 🎵🎵
🧵
9
29
162
13,303
Taylor Berg-Kirkpatrick retweeted
May 18
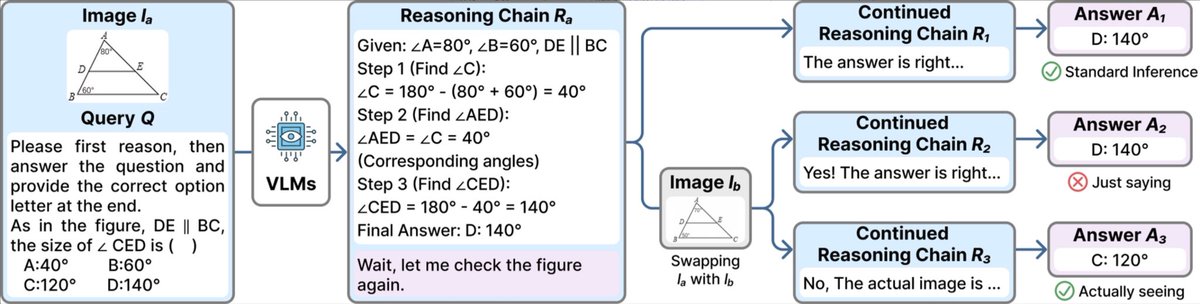
Check out our latest #ICML2026 Spotlight paper — VisualSwap.
When a VLM says "let me check the figure again," is it 👀 (Seeing) or just 🗣️(Saying) ?
Paper: arxiv.org/pdf/2605.15864
May 18

Reasoning VLMs often say "let me check the figure again." But do they actually look? Or just say they will, without re-attending to the image?
Introducing VisualSwap — #ICML2026 Spotlight 🌟 — diagnosing this silent failure.
4
7
965
Taylor Berg-Kirkpatrick retweeted

Apr 27
If you're at #ICLR2026 and interested in Parcae - I'm giving a keynote (via Zoom) at the Latent and Implicit Thinking Workshop at 1:30 local time today!
@hayden_prairie will be at the workshop all day and presenting Parcae at the poster sessions - stop by!

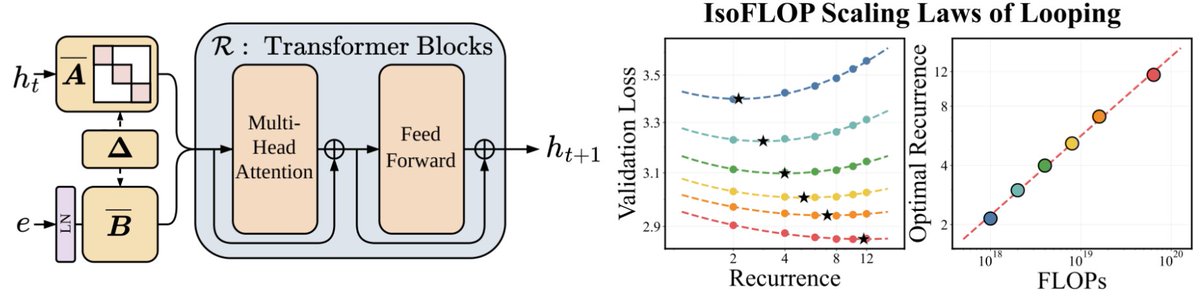
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
4
25
3,256

The dynamical system view gives very clean conditions for looped transformer to be stable
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
5
36
453
53,007
Taylor Berg-Kirkpatrick retweeted

Apr 16
a dynamical systems point of view, which looks like an SSM applied along the residual stream, informs more principled ways to scale looped architectures
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
30
220
25,910
Taylor Berg-Kirkpatrick retweeted
Apr 15
📢 Super excited to announce Parcae! We've been thinking about scaling laws and the "right" way to get more FLOPs.
Turns out layer looping - with the right parameterization - gives you a new axis to scale!
Parcae matches Transformers 2x their size (w/ the same data), and outperforms prior formulations of looped models.
But - you need the right parameterization to get these gains against strong Transformer baselines. Looped models are famously unstable to train, with tons of loss spikes and hyperparameter sensitivity.
The main technical challenge with looped models is residual explosion - if you're passing the activations through the same layers over and over, some otherwise benign parameterizations cause huge instability.
Our key idea: we can think of the residual stream of a model as a time-varying dynamical system - the same fundamentals behind SSMs like Mamba and S4. Then a few modest modifications to classic Transformers (stable diagonalization of injection params, LN before embeddings) can stabilize the looped models. The resulting models are more stable to train, but also reach higher quality.
It's strong enough to start to derive new scaling laws. Classically - we know you need to scale parameters with data to be FLOP-optimal. With Parcae, we find a third axis - given fixed parameters, you additionally want to scale FLOPs by looping as you scale data.
Super excited to see how these ideas hold, and what we can do with looped models!
Check out @hayden_prairie's great explainer thread below, and see links for our paper, blog, and models. Joint w/ @zacknovack and @BergKirkpatrick, and a fun collab between @togethercompute and my lab at @ucsd_cse. Enjoy!
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
2
26
129
21,832
Exciting new work by amazing students @hayden_prairie and @zacknovack in collab with @realDanFu !! Check it out!
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
1
12
2,078
Taylor Berg-Kirkpatrick retweeted

We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
41
179
1,278
294,829
Taylor Berg-Kirkpatrick retweeted

Mar 20
🚨 Do you use LLMs to help you write?
🤔You might notice that the text that you write with LLMs "feels" like an LLM, but did you know that it is also changing what you intended to say? 🤯
That's what we find in our new paper 👇
(1/N)
Mar 20

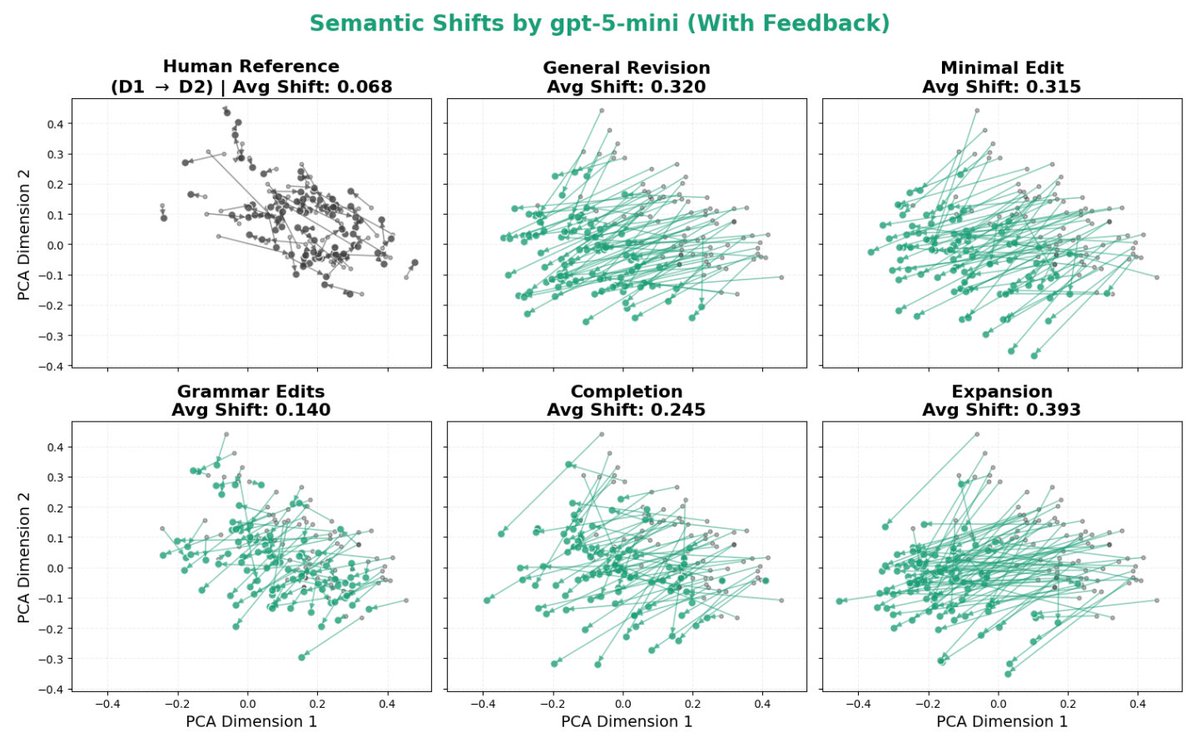
The paper I’ve been most obsessed with lately is finally out: nbcnews.com/tech/tech-news/a…! Check out this beautiful plot: it shows how much LLMs distort human writing when making edits, compared to how humans would revise the same content.
We take a dataset of human-written essays from 2021, before the release of ChatGPT. We compare how people revise draft v1 -> v2 given expert feedback, with how an LLM revises the same v1 given the same feedback. This enables a counterfactual comparison: how much does the LLM alter the essay compared to what the human was originally intending to write? We find LLMs consistently induce massive distortions, even changing the actual meaning and conclusions argued for.
4
18
53
9,548

9 Dec 2025
Cool work by amazing students Ivan Lee @ivn1e and Cheng Yang!

DeepSeek-OCR is a solid OCR model. But the excitement around it has become something bigger—evidence that vision might solve the long context problem. Has the excitement outpaced the evidence?
"Optical Context Compression Is Just (Bad) Autoencoding"
→ arxiv.org/abs/2512.03643

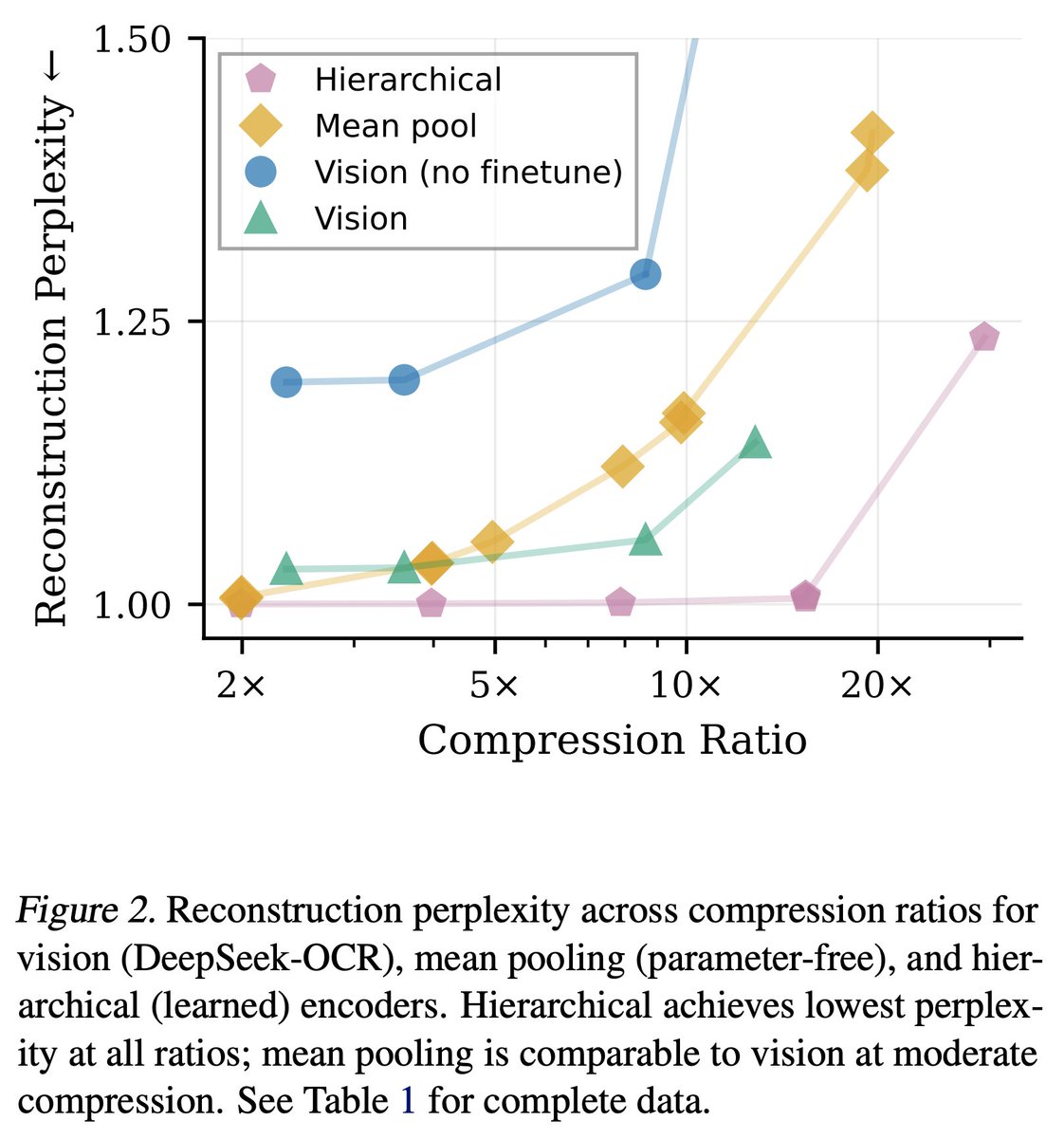

1
4
363
Taylor Berg-Kirkpatrick retweeted
23 Oct 2025
Excited to introduce our SoTA coding models, FrogBoss (32B) and FrogMini (14B), on SWE-Bench-Verified! (FrogBoss eats bugs… like a boss) 🐸🪲
These models were trained with bugs from a mix of existing and our new synthetic bug generation approach, called BugPilot.
(1/n)
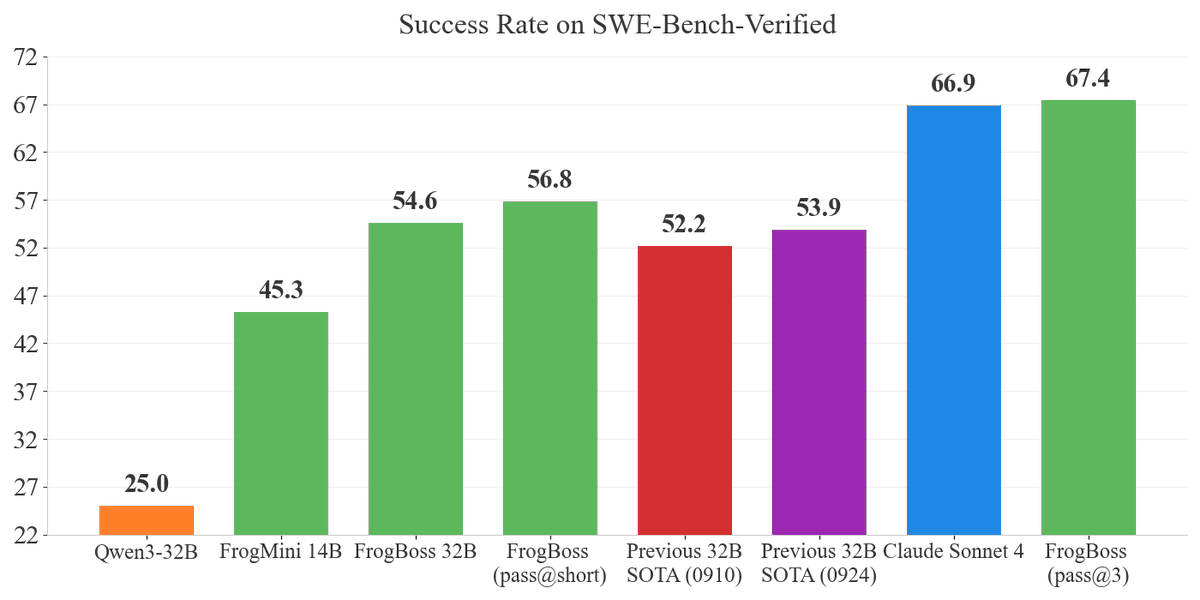

3
15
45
15,579
Taylor Berg-Kirkpatrick retweeted

23 Oct 2025
We hope to extend this framework in the future to real-time models like MagentaRT. And we hope you will play with our code as well to make your own cool music creations! Huge thanks to the team @zacknovack @dbeagleholeCS @BergKirkpatrick !
arxiv.org/abs/2510.19127
(5/5)
1
7
390
14 May 2025
So excited for Niloofar!!! she’s truly a force of nature — honored to have been along for part of the ride!!
6 May 2025

📣Thrilled to announce I’ll join Carnegie Mellon University (@CMU_EPP & @LTIatCMU) as an Assistant Professor starting Fall 2026!
Until then, I’ll be a Research Scientist at @AIatMeta FAIR in SF, working with @kamalikac’s amazing team on privacy, security, and reasoning in LLMs!



7
1,031