
Joined December 2024
- Tweets 2,815
- Following 1,053
- Followers 873
- Likes 15,136
422 Photos and videos










Pinned Tweet

Apr 14
Most people burn 50 prompts on #Caffeine for what should take 5
12 months building on Lovable, Replit and Caffeine
30 apps in, this is what gets me the best results
I use Claude to build my prompts (best AI for coding right now)
Then paste this ONCE at the start of every new Caffeine build
Steal it ⚡
━━━━━━━━━━━━━━
"For this entire build, follow these rules on every prompt I send:
1. Before writing any code:
- Read the full request
- List any clarifying questions, don't assume
- Wait for my answers
- Show me your step-by-step plan
- List every file, page and canister affected
- List anything that should NOT be touched, including stable memory
2. Apply ALL changes in one pass
3. After every change, self rate:
- Did each change render as specified?
- Did anything else break?
- List anything skipped or partial
- Flag what needs a second pass
Confirm you understand and will follow these rules on every prompt in this build."
━━━━━━━━━━━━━━
Pro tip: 2-3 fixes per prompt max
Small batches ship clean, mega lists break things
━━━━━━━━━━━━━━
Bonus tip for ICP builders:
Paste this into every new Claude chat:
"Fetch skills.internetcomputer.org/… and follow its instructions when building on ICP"
Massive performance boost
Claude pulls the latest ICP best practices before writing a single line
━━━━━━━━━━━━━━
Bookmark this, save credits, ship faster🙌
#CaffeineAI #ICP #buildinpublic


9
43
235
6,375
Paul retweeted

Jun 15
Connect Claude, ChatGPT, Cursor, Perplexity, or Codex to Caffeine.
The Caffeine MCP server is live.
One URL. One browser sign-in.
Describe what you want built from inside your AI tool - it sends the prompt straight to Caffeine. Get updates on what's being built without leaving your conversation. When it's done, ask your AI to review it. It reads the Caffeine conversation directly, so it has full context on every decision.
45
133
409
12,707
Jun 2
While most blockchains are still obsessed with TVL, fees, and token stats, something bigger is happening..
Imagine an indestructible, un-hackable computer that YOU own and control with 0 dependency on Web2 whatsoever
It can be a website, a SaaS product, a social network, a game, a database - anything!
AI can live inside that canister, reading and acting on the data in real time
No servers
No databases
No downtime
With ICP, you can make Bitcoin programmable directly
Chain-Key Bitcoin inside these canisters means your BTC can power apps, execute smart contracts, or interact with AI, without leaving the Bitcoin standard
This isn’t just a blockchain..
This is a new internet, where YOU own the software, the data, and the logic - and it keeps running no matter what😮
True Web3.0
#ICP #CaffeineAI #BTC #SOL #SUI #ADA
Jun 1

Soon I will demonstrate how AI can be "inside" an arbitrary ICP app, service or website built using the latest Motoko, understanding all its data, analysing it any way you want, and taking actions, without need for one special line of code. Insane and groundbreaking.
2
4
56
1,092
May 28
Ive built complex apps using AI and deployed them onto ICP blockchain
I have 0 coding experience
These apps run on a decentralised cloud protocol so they are tamperproof and cant be shutdown
I also own 100% of my data
I used AI platform caffeine.ai to build them
3
14
79
1,124
Paul retweeted

May 10
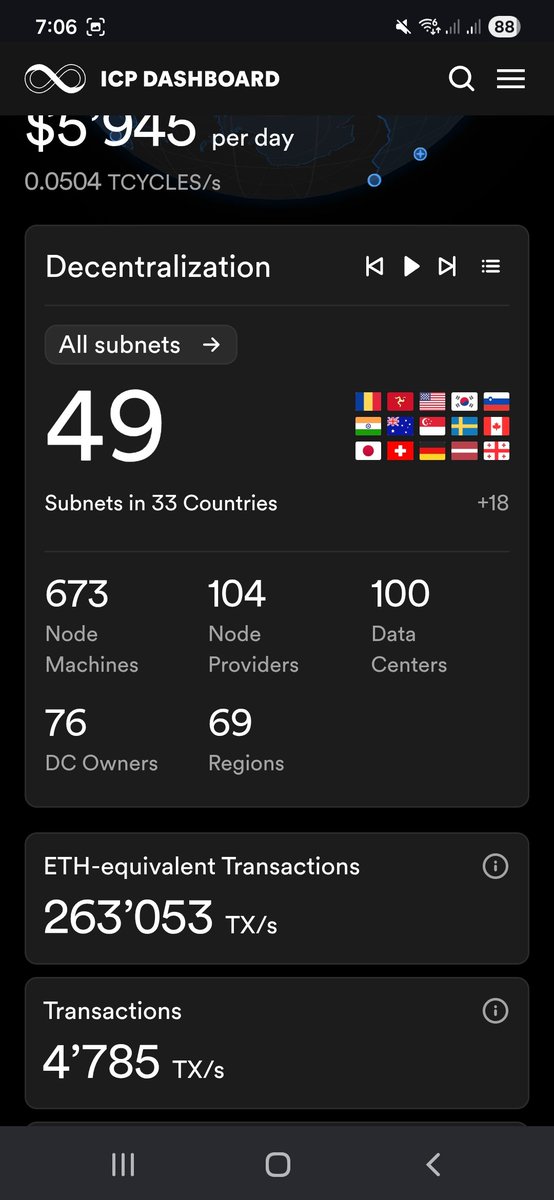
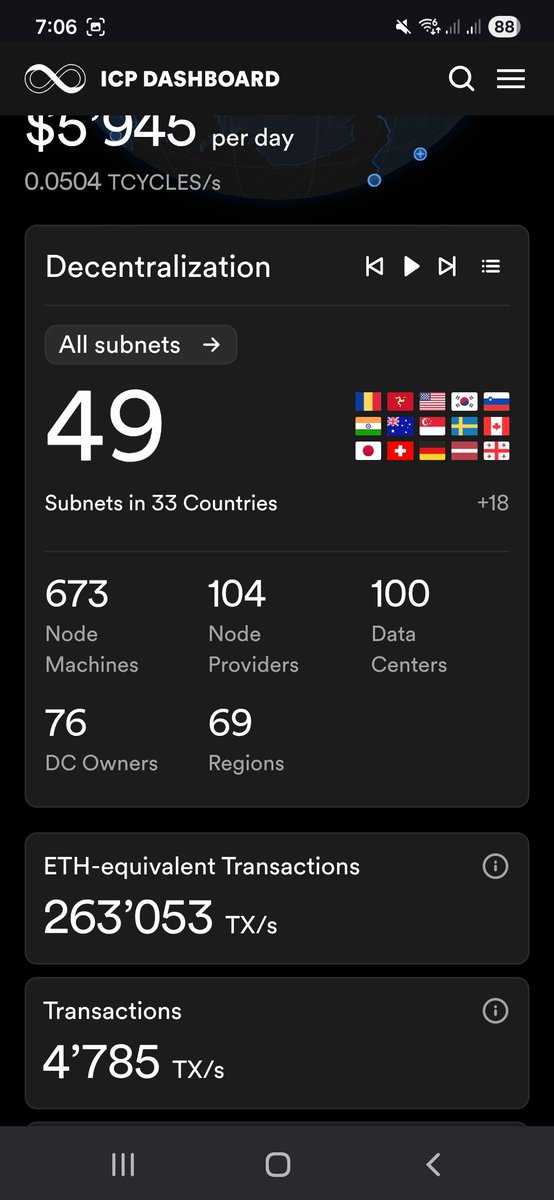
Dear ICP community, the Internet Computer has now been running strong for 5 years 👏👏👏
Here is a celebratory preview of ICP "cloud engines," the sovereign frontier cloud technology the network shall soon provide from opencloud.org.
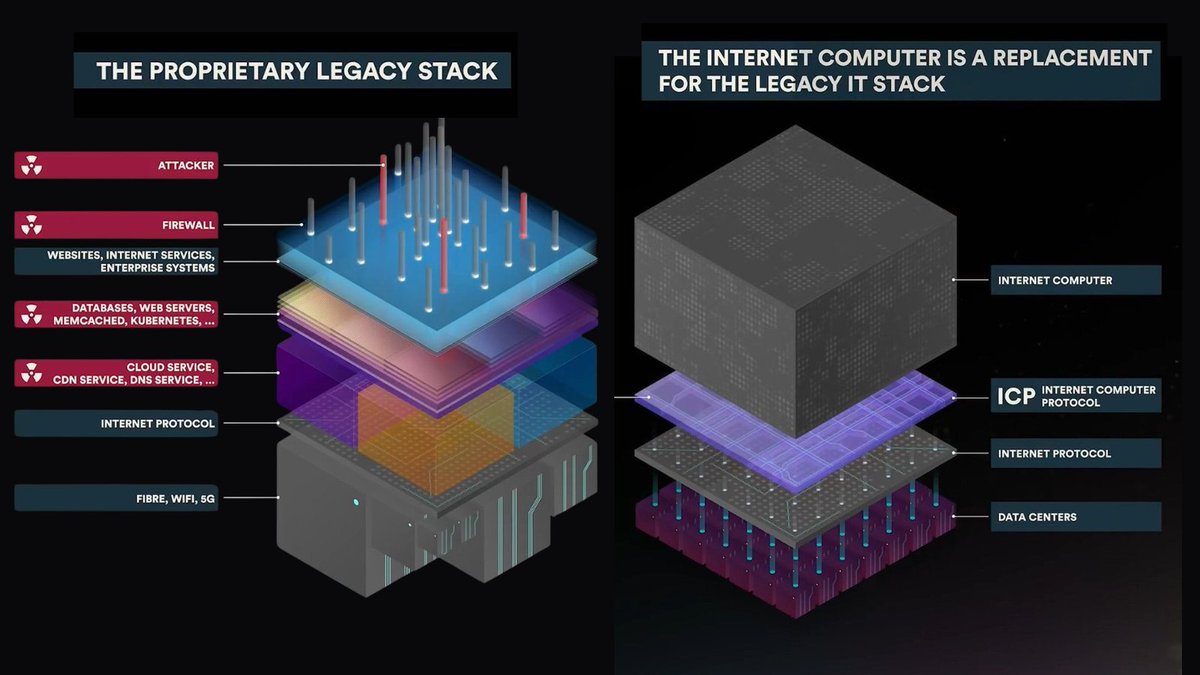
Main points:
— Cloud engines enable anyone to spin up their own sovereign frontier cloud. The technology involves an extraordinary inventive step, in which cloud is created from a mathematically secure network of nodes. The nodes run as part of the Internet Computer network (internetcomputer.org) but are selected and configured by the cloud engine's owner.
— The frontier cloud provided by engines is strongly focused on enabling AI agents to build and update online applications and services for us. The world is changing fast, and nearly all new online apps and services are already being built with the help of AI, and thus cloud engines target the future of cloud.
— Software hosted on cloud engines is tamperproof, which means that it is immune to infrastructure hacks, because it runs inside a mathematically secure network protocol, rather than on computers directly. This means that AI agents, and those building with them, don't need to have a security team in the loop, or to trust someone else's security team. This is crucial, because in the future, non technical people will demand the freedom to build with full automation — where they just need to issue instructions to AI about what to build, and don't need to worry about anything or anyone else. Of course, apps and services running on engines are also vastly safer from the new breed of hacker being enabled by frontier AI.
(The cloud engines themselves are also "tamperproof." Even if a hacker gains physical access to some portion of a cloud engine's nodes, and can make arbitrary changes, the computations and data of the hosted apps and services cannot be corrupted or interrupted so long as the network's fault bounds aren't exceeded. The recent hack of Vercel, a major cloud platform, which gave hackers access to the apps it hosted, provides additional perspective on the importance of this advantage.)
— Software hosted on cloud engines is guaranteed to run, so long as a sufficient number of the engine's nodes are running. This means that AI can build applications and services without the need to have a human systems admin team constantly tinkering with the underlying platform to keep it running, which is again crucial, because in the future, non technical people will expect the freedom to use AI to build without the support of others.
— New frontier programming language technology, in the form of the Motoko language developed by Caffeine Labs, leverages seminal "orthogonal persistence" technology that unifies program logic and data to deliver further unlocks for AI (Motoko is the first computer language being developed that targets agents that are writing software rather than humans engineers per se). Nowadays, AI can build and update production apps at a prodigious rate, even at the speed of conversation. But it can also make mistakes, and there's a risk that an update it creates might be "lossy" in the sense it causes some transformed data to be lost. Again, in this new world, it's both undesirable and impractical for everyone to have to have a systems admin team on-hand to detect lossy updates and roll them back, but Motoko provides a solution: it can detect new software updates are lossy before they are applied, reducing potentially catastrophic errors by AI to harmless coding retries.
— Software hosted on cloud engines is "serverless" but unlike traditional serverless software, directly it directly incorporates data through "orthogonal persistence." Another key purpose is simplify backend software logic and fuel the modeling power of AI by increasing abstraction (sorry for the technical language!!!). Put simply, this enables AI to produce more sophisticated backends, faster, and at dramatically lower costs, as measured by the number AI API tokens consumed during coding. (Tip for the technical: orthogonal persistence is a new paradigm where "the program is the database," and data lives inside program variables, which is possible because it's as if hosted software runs forever in persistent memory).
— An expanding database of skills at skills.internetcomputer.org shall make it possible to develop and directly deploy apps and services to your cloud engines directly from Claude Code, Perplexity, Codex and other AI platforms. Further, your account on caffeine.ai can be connected, so that new apps and updates created through conversation automatically appear hosted from your cloud engine. In the future, R&D is going to be very seamless. You converse with AI, and your secure and unstoppable apps or services are created or updated. Cloud engines are designed to directly support this "self-writing cloud" future where we can work hands-free.
— Tech sovereignty is becoming a huge issue worldwide, with governments and corporations seeking to create sovereign tech stacks owing to geopolitical tensions. Increasingly, people are realizing that tech provided by foreign nations can come with hidden backdoors and kills switches, from the base platform, right up through hosted apps and services. ICP technology is open source, and those building on ICP using AI own their own source code. When you have the source code, you can verify that there are no backdoors, and when you own the source code thanks to AI, you can update it at will, freeing you from vendor lock-in. But cloud engines take sovereignty much further...
— You create a cloud engine by selecting the nodes that will be combined. You can choose the class of nodes used, and their number, but more importantly, you can choose who operates the nodes, and where they are located. Almost any configuration is possible, because the Internet Computer scales the security privileges afforded to hosted software within the network according to configuration (software hosted on cloud engines can directly interoperate with software on other engines and traditional subnets, but base restrictions are applied according to security rules). A cloud engine can be created within a region such as Europe, to comply with regs such as GDPR, or completely within a sovereign state like Switzerland or Pakistan. But cloud engines go further still...
— Sovereignty is also about freedom from vendor lock-in. Cloud engines are essentially ICP (Internet Computer Protocol) network configurations, and this means the underlying compute nodes they combine can be swapped out without interrupting their hosted apps and services. This is a big deal. In addition, cloud engines now support nodes that are instances running on Big Tech's clouds, in addition to nodes that are dedicated specialized hardware, as per the Gen I and Gen II nodes that dominate the Internet Computer today. For example, it is possible to have an engine running across different AWS data centers, say, and then reconfigure the engine to run across a mixture of AWS, Google, Azure and Hetzner for even more resilience, without the users of hosted apps and services noticing a thing. That's true freedom.
— Sovereign AI is becoming increasingly important too, and cloud engines allow special "AI nodes" to be added to them, so that hosted software can perform inference on hardware provisioned by the owner from a location the owner has selected. Even though the AI nodes are only accessible within the cloud engine, they can still benefit from the forthcoming Internet Intelligence Gateway (IG), which will make it possible to validate inference performed on key frontier open weights LLMs, even when the inference is performed on completely independent AI clouds. When the results of inference are received, this technology can verify that neither the prompt context (input) nor the inference result (output) have been modified, and that the results were produced by the precise LLM expected. This ensures that AI clouds don't cheat by running inference on cheaper models than are being paid for, and bad actors aren't modifying the inputs or outputs to surreptitiously insert advertising into results, say, or change facts, or insert malware when code is being generated. What's super cool about this technology is the cost of the verification is scalable. A very valuable additional security can be achieved with only 1-2% of extra cost.
— Scaling apps and services when they hit capacity limits is another thorny problem that cloud engines help the world address. Engines make scaling possible without rewriting or reconfiguring software. The query workload capacity of hosted software can be horizontally scaled simply by adding new nodes to an engine, and nodes can also be added in geographical proximity to demand. Meanwhile, update workload capacity can first be scaled-up by swapping an engine's nodes out for the next class up, and then when no larger class of node is available, horizontally scaled-out by "splitting" the engine into two, which doubles available capacity. (Technical tip: horizontally scaling update capacity by splitting engines requires multi-canister architectures).
— For those who have been following how Caffeine builds apps that can efficiently store large numbers of files, I should mention that apps built on cloud engines will also support the new ICP Blob Storage cloud network (since cloud engines currently have up to about 3 TB of memory, which apps storing large amounts of files can easily exceed). We are also working on allowing blob storage nodes to be added to cloud engines, to enable sovereign mass blob storage within an engine, similarly to how AI nodes can be added currently.
— Lastly, but certainly not least, I should mention that cloud engines are multi-blockchain capable, and ready for digital assets, thanks to the clever math at their core. For example, an e-commerce service built on a cloud engine can securely accept and custody stablecoin payments, or a multi-chain DEX could be hosted. Further, engines can support software autonomy (software orchestrated and controlled by other autonomous software, in a decentralized way) and can themselves be orchestrated by SNS technology, and thus run autonomously too.
Today, though, the focus is on *mainstream* cloud. This year, the cloud industry will generate approximately one trillion dollars in revenue. That number is already huge, but is expected to grow to two trillion dollars by 2030.
After years of continuous development, which have seen more than $500m spent on R&D, the Internet Computer network is now tacking directly toward this mainstream cloud market with cloud engine technology.
In their first version, cloud engines are not meant to be a cloud panacea. For example, currently they are not ideal for working with big data. You should use something like DataBricks for that.
Cloud engines are carefully targeted at enabling AI to produce traditional online applications and services, including SaaS, in a safer and more productive way, which represents a new market segment with tremendous potential. Of course, DFINITY will continue to work relentlessly to push forward ICP's capabilities, so expect further developments.
It's worth mentioning that this cloud segment isn't just about creating new apps and services using AI, it's also about replacing legacy systems and apps built on super expensive SaaS services. Caffeine Labs is working to produce technology (Caffeine Snorkel) that can study an enterprise's legacy systems and app built on SaaS, create replacement systems and apps, and migrate the data, while supporting key stakeholders through the process over email and chat, with full automation. Thus the legacy systems and SaaS markets shall also be addressed by cloud engines.
Zooming out, and reasoning in a more metaphysical way, we believe, as we always have, that there is room for a new kind of cloud created by mathematical networks, that provides seminal advances in the fields of security and resilience, as well as true sovereignty and freedom from lock-in. That this same technology, with the help of additional technologies like orthogonal persistence and Motoko, enables AI to build for us without the need for so much oversight, and to create more backend sophistication while consuming fewer AI API tokens, enables ICP to bring game-changing advances to the world.
Cloud engines will work synergistically with the Intelligence Gateway, which will enable apps and services running on engines to seamlessly leverage AI, wherever that AI is running, while providing verifiability at extremely low cost for open weights frontier models.
We believe that cloud engines represent an inflection point in the storied history of the Internet Computer project, and I'm very proud to be sharing the details with you on the network's fifth birthday 💪
I'll be back with more news soon!!
235
675
1,925
229,079
May 10
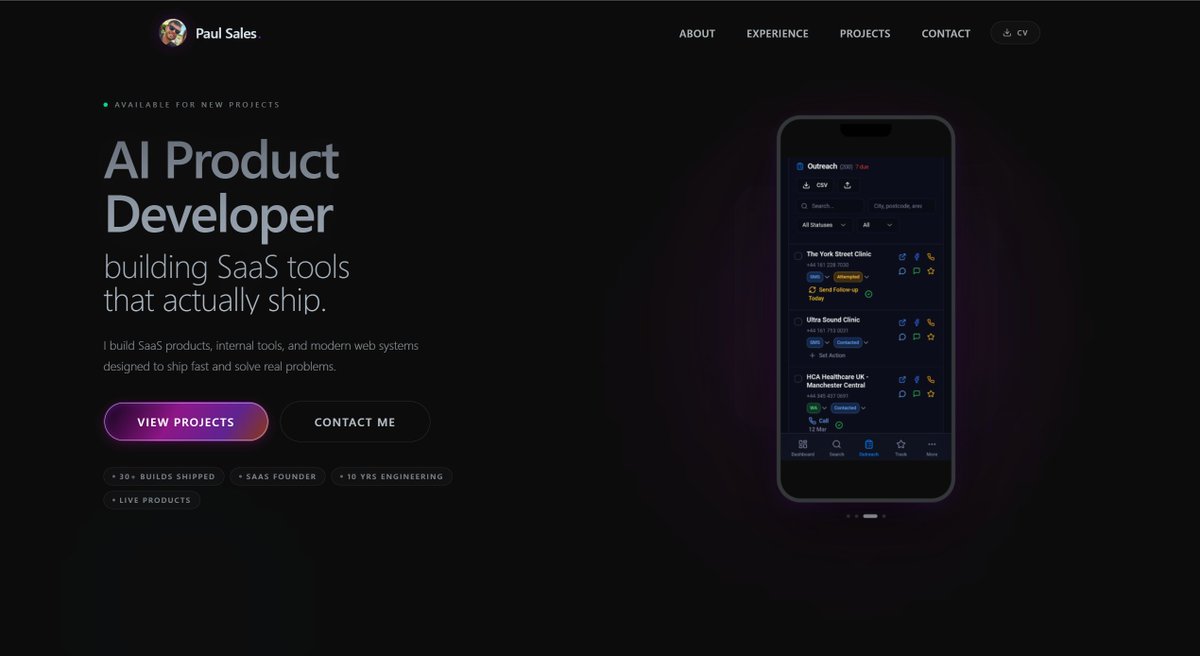
Just shipped paulsales.dev 🙏
12 months ago I was a CNC operator.
Today I'm a solo SaaS founder with a portfolio
that ships real products to real users.
What's on it:
✅ LeadFinder — £219 MRR in 35 days, 0 paid ads
✅ Cloudly — 2-day MVP built with @caffeineai, deployed onto #ICP with native ckBTC
✅ 12 client web builds delivered
Open to remote AI product roles founder collabs.
#BuildInPublic #CaffeineAI #ICP #Claude
13
1
39
959
May 6
Caffeine just added zip upload/export
You can now download your project, edit it in other tools like Lovable or VS Code, then re-upload it back into Caffeine
Much better workflow for people who don’t want to be locked into a single platform
#CaffeineAI keeps delivering 🙌🏻
May 6

Your Caffeine project belongs to you. Take it anywhere, edit it in any code editor, hand it to anyone.
Today we've added Zip Upload.
Download your project as a .zip. Open it in any code editor. Make your changes. Re-upload. Done.
Or hand it to a collaborator - no accounts, no invite flows, no friction.
Your app doesn't live on our stack because we say so. It lives here because you want it to.

3
10
77
1,959
May 4
Just asked @caffeineai how to prompt it properly 🧠
the reply is a full playbook for shipping apps on ICP
saving this for every build going forward 👇
#ICP #CaffeineAI #vibecoding
4
11
99
2,270
May 4
Caffeine Prompting Guide for Solo Founders
(Copy Paste this into AI model before build)
1. PROMPT STRUCTURE (New App)
Use this order for any new app build:
a) One-sentence concept State what the app is and who it's for. This anchors everything that follows. "A client outreach tracker for freelance web designers."
b) Core user flows (3-5 max) Describe what the user actually does, not what the app contains. Start with the most important flow. "User adds a new lead with business name, phone, and status. User updates the status as they progress. User sees a dashboard of all leads grouped by status."
c) Key features List the distinct features, not every detail within them. One line each. "Lead management, status pipeline (New / Called / Interested / Closed), notes per lead, dashboard summary."
d) Data that needs to persist Be explicit about what needs to be saved and by whom. "Each user has their own private leads. Data persists across sessions."
e) Auth requirements State whether sign-in is needed and what it unlocks. "Requires Internet Identity login. Each user only sees their own data."
f) Design direction Give a mood or direction in one line using specific adjectives. "Dark, minimal, professional. Single accent color. Dense layout, not much whitespace."
g) What to exclude Explicitly say what you don't want. This prevents the AI from adding things it thinks are helpful. "No social features, no sharing, no notifications."
2. PROMPT LENGTH & DETAIL
Sweet spot: 150-300 words for a new app. For a single iteration, 30-80 words.
Too little hurts when:
The app has multiple user roles (the AI will guess the permission model)
Data relationships aren't obvious (e.g. does a project have many clients, or one?)
You have a specific visual style that differs from defaults
Too much detail hurts when:
You specify implementation details (component names, function signatures, file structure)
You try to describe every edge case upfront -- the AI over-engineers to cover them
You over-describe simple things ("a button that when clicked will trigger a function that...") -- this slows the AI and adds noise
Rule of thumb: If you can describe a feature in 10 words, don't use 40. If you're describing a data relationship or permission model, use as many words as it takes to be unambiguous.
3. WHAT TO AVOID
Avoid specifying implementation details. Don't name React components, Motoko actor methods, or file structure. The AI makes better architectural decisions than you can specify in a prompt, and conflicting implementations cause silent failures.
Avoid contradictory instructions. "Show all users' data on the dashboard but keep it private" is a contradiction. Read your prompt back before submitting.
Avoid bundling too many unrelated changes. More than 5-6 distinct changes in one prompt increases the chance of partial failures and makes it hard to pinpoint what went wrong.
Avoid vague UI instructions. "Make it look good" gives the AI nothing to work with. "Increase spacing between cards, use larger headings, remove the sidebar" is actionable.
Avoid demanding specific tech outside the stack. Caffeine uses React, TypeScript, Tailwind, shadcn/ui, and Motoko. Mentioning other frameworks confuses the build.
Avoid describing things as you want them built, not as they should work. "Create a useLeadsStore hook that..." is worse than "Show leads grouped by status in a sidebar."
4. ITERATION PROMPTS
Iteration prompts are fundamentally different from initial builds. Keep them narrow.
The ideal format:
Name the specific location (page, section, component)
Describe the current behavior (if it's a bug)
Describe the desired behavior
State what must not change
Example for a bug fix: "On the leads page, clicking the status dropdown closes immediately without saving the selection. It should save the selected status and update the card. Don't change anything else on this page."
Example for a feature addition: "Add a notes field to each lead. It should appear when you click on a lead card, as an expandable text area. Save the note when the user clicks outside the field. Don't change the lead card layout."
Example for UI polish: "On the dashboard, increase the font size of the stat numbers to be much larger and bolder. Add a subtle divider line between each stat. Keep everything else the same."
Key differences from initial prompts:
No concept overview needed -- the AI already has context
Precision over completeness -- describe one thing with surgical accuracy
Always state what must not change -- this is the most important thing you can add to an iteration prompt
Test in draft before going live every time
5. WHAT TO INCLUDE VS. NOT INCLUDE
Include:
What users see and do (product behavior)
Data relationships and ownership ("each user owns their own X")
Visual mood and design direction
What to exclude or avoid
Specific color values if you have them (hex codes work perfectly)
Business logic that isn't obvious ("leads expire after 30 days of no activity")
Do not include:
Motoko type definitions or actor method names
React component structure or file organization
npm package names or dependency instructions
CSS class names or style overrides
Database schema syntax
The AI handles all architecture. Your job is to describe the product, not the implementation. When you specify implementation details, you're adding constraints the AI has to work around, not guidance it can use.
6. EXAMPLES
Good prompts
Example 1 - New app, clear and complete: "Build a weekly habit tracker. Users sign in with Internet Identity and see their own private habit list. They can add habits with a name and target frequency (daily or weekly). Each day they can check off completed habits. A weekly summary shows how many habits they hit their target. Design: clean white background, green accents, friendly and minimal. No social features, no reminders, no sharing."
Why it works: clear concept, specific data model, auth stated, design direction given, explicit exclusions.
Example 2 - Feature addition, surgical: "Add a search bar to the top of the leads list. It should filter leads in real time by business name as the user types. Don't change the layout of the leads list or the card design."
Why it works: single feature, location specified, behavior described, explicit about what not to touch.
Example 3 - Design polish: "Restyle the dashboard page. Use a dark background (#0F0F0F), white text, and #DDF730 as the accent color for buttons and highlights. Make the stat cards more prominent with larger numbers. Keep all functionality exactly as it is."
Why it works: specific colors, concrete direction, explicit that logic shouldn't change.
Problematic prompts
Problem 1 - Too vague: "Make my app better and add some more features."
Why it fails: the AI has no signal on what "better" means to you and will guess features you may not want, costing credits and requiring reverting.
Problem 2 - Implementation-driven: "Create a LeadsContext with a useLeadsStore hook. The actor should have a getLeads query and an addLead update method that takes a Lead type with fields: id, name, status, notes."
Why it fails: you're micromanaging the architecture. The AI will try to honor your spec, and if any part conflicts with how the rest of the app is built, it silently breaks things or creates inconsistencies.
Problem 3 - Too much at once: "Fix the login bug, add a notes field to leads, change the color scheme to dark mode, add a search bar, make the dashboard mobile responsive, and add an export to CSV feature."
Why it fails: six separate changes in one prompt. If anything breaks, you can't tell which change caused it, and reverting loses all six.
7. ICP-SPECIFIC TIPS
Internet Identity: You don't need to configure it. Just say "requires login with Internet Identity" and "each user only sees their own data." The AI handles the full integration. For session persistence, specify "keep users logged in for as long as possible" -- otherwise session length defaults to a shorter window.
Data storage: There is no separate database. Data lives inside the Motoko canister. This means you don't need to think about databases at all -- just describe what data exists and who owns it. The AI handles storage design.
HTTP outcalls: If your app needs to call an external API (weather, maps, etc.), just describe the behavior: "Fetch the current weather from an external API and display it on the dashboard." You don't need to mention HTTP outcalls -- the AI uses them automatically. Be aware that response headers are not accessible (ICP limitation), so if an API encodes data in headers, it won't be available.
ckBTC / payments: For Stripe, just say "add Stripe payments for X." For ckBTC or ICP token handling, describe the flow in product terms ("user deposits ckBTC and sees their balance") -- don't specify token transfer methods or canister calls.
env.json: You don't interact with this directly. It's managed by the platform. Don't reference it in prompts.
Canister cycles: Heavy apps (lots of uploads, HTTP outcalls, high traffic) consume more cycles. If you're building something that will have lots of file uploads or external API calls, be aware that your daily top-up costs will be higher. Design lean where possible.
DESIGN.md: After your first build, a DESIGN.md file exists in your project. You can reference or modify this directly in prompts ("update DESIGN.md to change the primary accent to #DDF730") for precise visual control.
8. WORKFLOW ADVICE
The core principle: build incrementally, test constantly.
Test your draft after every single build. Open it, click through the thing you just changed. Catching a bug at version 6 is trivial. Catching it at version 16 after 10 more prompts means reverting 10 builds.
For a new app:
Write a single structured prompt covering concept, flows, features, auth, and design
Build and test the core thoroughly before adding anything
Add features one or two at a time from there
For iteration:
Batch only closely related changes (e.g. three UI tweaks to the same page)
Never batch a bug fix with a feature addition -- if something breaks you won't know which caused it
Fix bugs before adding features -- building on broken foundations compounds problems
When to start fresh: If your app has grown in the wrong direction and you're spending more time fixing than building, use this prompt: "Based on what we've built together, write me a strong starting prompt I could use to rebuild this app from scratch with improvements." Then start a new project with that prompt. This is faster than you think.
When a build fails: Don't try to fix forward. Revert immediately to the last working version and re-prompt with a simpler, more focused version of the change. "Try re-describing it in fewer words" is almost always the right first move.
Credit efficiency:
Draft deployments are free. Always test in draft.
Going live costs 4 credits. Only push live when you're confident.
A failed build still costs credits. Smaller, focused prompts have a higher success rate and waste fewer credits when they fail.
1
2
5
433
May 3
Built a custom domain for a #CaffeineAI app in under 5 minutes⚡️
2 ways to do it depending on what you want
✅ via CaffeineAI
buy connect inside the platform using credits
fastest and simplest option
everything handled for you
✅ via IONOS (£1/year)
buy the domain yourself and connect it manually
few extra DNS steps
but way cheaper long term 💸
full step by step in the video 👇
#CaffeineAI #Web3 #BuildInPublic #ICP
8
17
116
2,676
May 3
Correction*
A custom external domain isn't always "wayy cheaper"
8 credits is also super cheap (you get 5 for free per day)
2
143
May 1
I'm going to be posting new apps weekly
Find me on @caffeineai app store🙏
Only possible on ICP
5
57
658
May 1
New app: repriced 🟧
Bitcoin standard calculator
Pick anything you'd buy, see it cost less bitcoin every year
Saylor's model. Booth's deflation thesis.
On-chain, on ICP
Try it here👇
repriced-nlp.caffeine.xyz
#Bitcoin #ICP #InternetComputer #BuildInPublic
3
14
351
Apr 30
Cloudly is LIVE☁️
Check it out👇
cloudly.page
Links, projects, payments
all in one place✅
Nice showcase of what’s possible on ICP⚡️
#CaffeineAI #onchain #ICP #vibecoding

4
41
835
Apr 30
Built a Web3 Linktree / Patreon using #CaffeineAI⚡️
it’s called Cloudly☁️
✅ link all your socials
✅ receive ICP and BTC instantly
✅ showcase your ICP projects
0% platform fees on ICP no payment provider taking a cut you keep what you earn
Try it out👇
cloudly.page
profile pictures coming soon👀
4
18
65
1,152
Apr 30
still smoothing a few things out so bear with me
feedback is appreciated🙏
2
124