
Joined January 2015
- Tweets 10,547
- Following 1,391
- Followers 463
- Likes 12,114
541 Photos and videos












Crispy retweeted

Jun 12
You can be repulsed by the general idea that there's a trillionaire while also being repulsed by the specific idea that it's Elon Musk.
478
2,787
18,732
285,842

Crispy retweeted

Apr 10
Chemtrails don't exist
Turbo cancer doesn't exist
Covid does exist
Covid vaccines worked
Ivermectin doesn't work for Covid
Ivermectin doesn't work for cancer
Vaccines eradicated smallpox
Vaccines don't cause autism
Thanks and have a wonderful day
1,514
3,298
15,750
231,244
Crispy retweeted

Apr 8
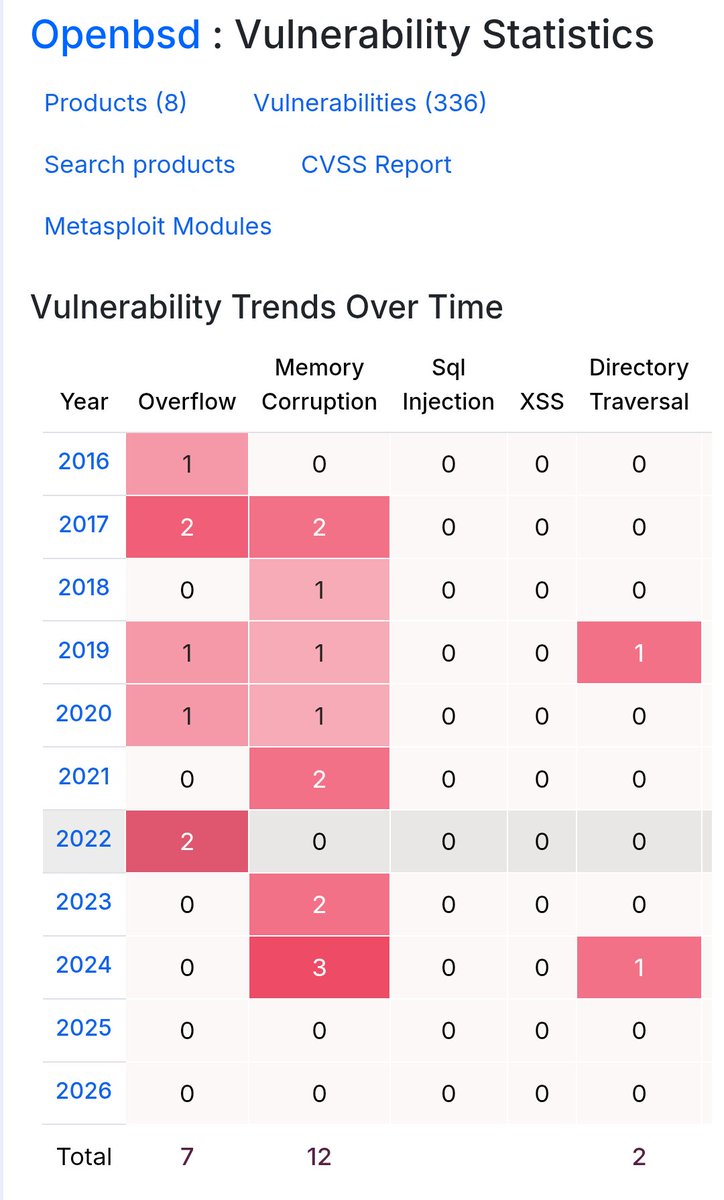
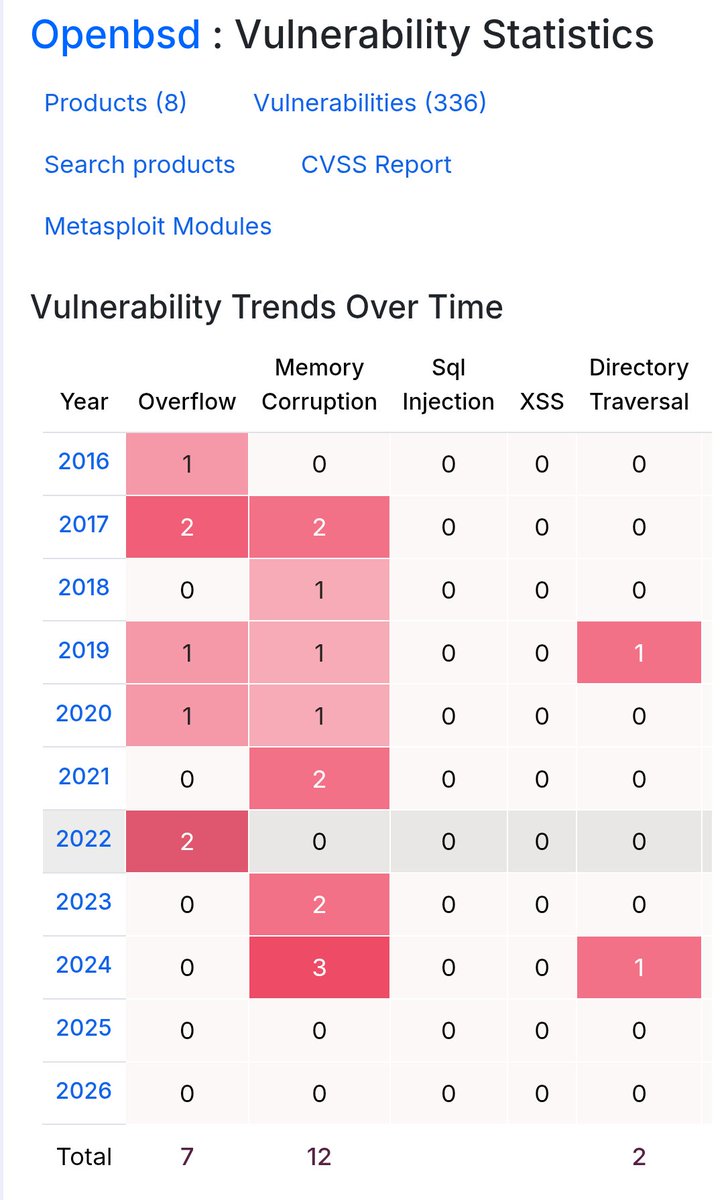
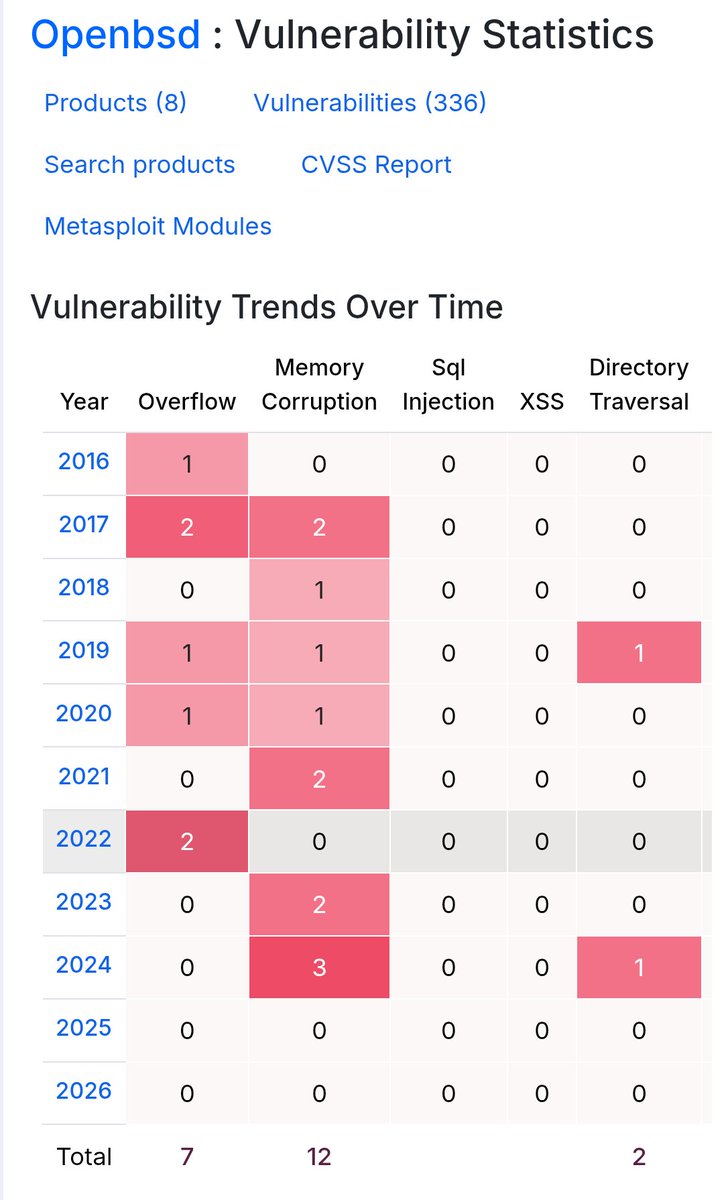
"But here is what we found when we tested: We took the specific vulnerabilities Anthropic showcases in their announcement, isolated the relevant code, and ran them through small, cheap, open-weights models. Those models recovered much of the same analysis. Eight out of eight models detected Mythos's flagship FreeBSD exploit, including one with only 3.6 billion active parameters costing $0.11 per million tokens. A 5.1B-active open model recovered the core chain of the 27-year-old OpenBSD bug." aisle.com/blog/ai-cybersecur…
110
335
2,435
726,407

Apr 9
They found bugs in OpenBSD! The most secure application on the planet that I haven't heard of before!!!
That's unbelievable and clearly a sign of AGI!!!!
Well..
18
Mar 24
Remember IQ tests effectively measure how good you are with IQ tests.
Mar 23

In March 2023, Claude had an estimated IQ of 64. Today, Claude Opus 4.6 scores 133 on the Mensa Norway test. GPT-5.2 Thinking hits 141. Gemini 3 Pro, 142.
That's a jump from cognitively impaired to gifted in three years. No human population has ever improved that fast, the Flynn effect gives us ~3 IQ points per decade.
AI just did 70 points in 36 months.
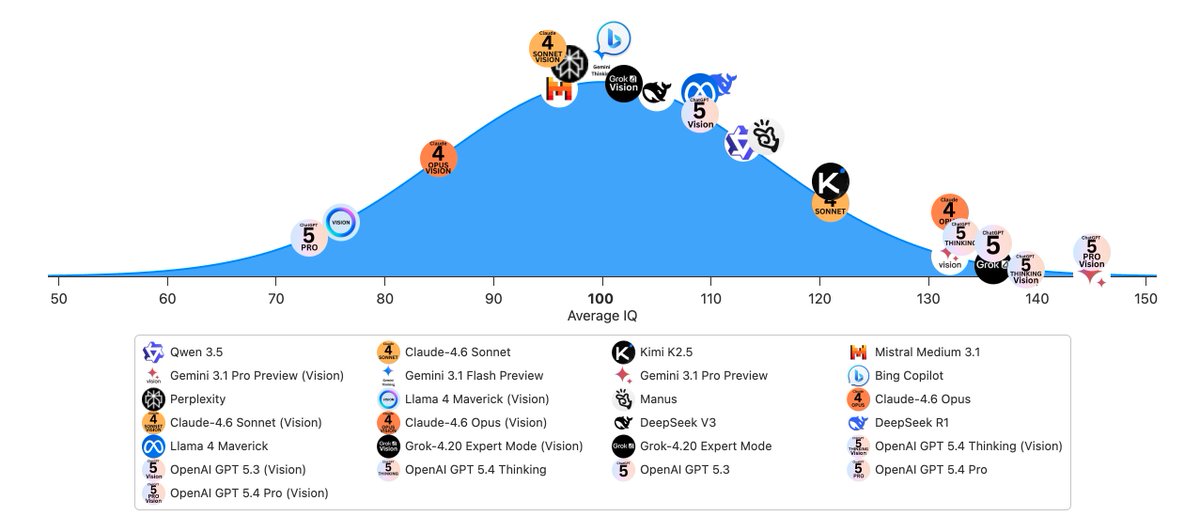
11
Crispy retweeted

Jan 13
Elon is building a spaceship that runs on White Power.
35
21
282
12,120
Crispy retweeted

21 Dec 2025
When it comes to scientific discovery, one thing LLMs are really good at is getting hobbyists to delude themselves into believing they've made a huge breakthrough on some longstanding problem or a theory of everything
267
235
3,390
332,921
12 Dec 2025
Excited to be the 1,207th 😎 on @BackerKit for The Between. the-between.backerkit.com/co…
15
28 Nov 2025
RT @GaryMarcus: This place is toxic.
For the last seven years I warned you that LLMs and similar approaches would not lead us to AGI. Almo…
557
Crispy retweeted

8 Oct 2025
if only we had invested more money in neurosymbolic AI, earlier….
8 Oct 2025

Now it's up to us to refine and scale symbolic AGI to save the world economy before the genAI bubble pops. Tick tock
21
9
198
22,708
Crispy retweeted
29 Sep 2025
The narrative around LLMs is that they got better purely by scaling up pretraining *compute*. In reality, they got better by scaling up pretraining *data*, while compute is only a means to the end of cramming more data into the model. Data is the fundamental bottleneck. You can't scale up pretraining compute without more data.
And so far this data has been chiefly human-generated -- over 20,000 people have been employed full-time for the past few years to provide annotations to train LLMs on. Even when the data is coming from RL envs, the envs still had to be purposely handcrafted by humans.
And that's the fundamental bottleneck here: these models are completely dependent on human output. They are an interpolative database of what we put into them.
90
175
1,612
118,894
Crispy retweeted

24 Sep 2025
Is there something in the water in America 🤔 im not kidding🤔 does Republicans eat or drink something that "normal" people dont drink or eat🤔 because from a Norwegian point of view it seems like millions of Americans Lost all contact with reality🤷 gone totally bat shit crazy🤷
3,378
3,180
27,361
562,766
24 Sep 2025
Da will jemand ganz dringend Afd Mitglied werden.
24 Sep 2025

Ich möchte im Übrigen meine Steuergelder weder bei Amadeu Antonio noch bei Omas gegen Rechts noch bei R21 verausgabt sehen.
27
24 Sep 2025
Es will halt keiner einfach Mal so 50-100 Milliarden investieren. Wäre prinzipiell in Europa oder Deutschland kein Problem.
Wir haben riesige Fabriken und mit die schnellsten Großrechner.
24 Sep 2025

- Energieverfügbarkeit
- Energiekosten
- Verfügbarkeit von geeigneten Chips
- Verfügbarkeit von Kapital
- Drosselung von Innovation durch Bürokratie (AI Act, DSA, DSGVO, ...)
- Politik, die auf Berater hört, die vom Thema keine Ahnung haben (Bsp: KI-Strategie 2018)
- risikoaverses Mindset
Fehlt noch was?
28
Crispy retweeted

24 Sep 2025
A man with a sixteen year long heroin addiction told you that Tylenol causes autism, and you believed it like a dumbass
1,776
15,279
160,028
2,919,270
24 Sep 2025
Regarding Tylenol: all pharmaceutical companies say don't take our drugs during pregnancy, because nobody will take the risk.
#TYLENOL
12

Crispy retweeted

23 Sep 2025
die Welt war objektiv besser, als verstrahlte Podcaster noch ausschließlich Internetfreaks waren und nicht Grund für mehrtägige Staatstrauer in den USA
21
28
955
25,770