
Building Full Self Coding.
Joined October 2021
- Tweets 6,110
- Following 174
- Followers 22,654
- Likes 10,295
2,020 Photos and videos











Pinned Tweet

18 Dec 2025
BLACKBOX AI is now a @Microsoft Official Partner.
Enterprises can purchase @blackboxai licenses directly through the Microsoft Marketplace.
Built for teams that ship fast and stay secure.

36
12
174
73,292
BLACKBOX AI retweeted
Jun 13
Blackbox Agents API - Grok, Claude, Codex, Gemini, All CLI's managed from one API
With the same API you can run Evals on all popular benchmarks like swe-bench, hle, aime, mmlu-pro
With the Blackbox Agents API, the first Recursive Self Improving Repo works 24/7 up to your max spend to continuously have all agents keep working on your repo's.
Multiple Agents working 24/7 without prompting on:
- Bug fixes
- Security
- New features
- Design updates
- Any thing you want them to focus on
7
5
26
3,310
Jun 8
We’re live at London Tech Week 🇬🇧
See agentic inference live at the BLACKBOX AI booth.
Don’t miss Richard on Tuesday 9th, 12:30 at the Core Stage:
“The Secure Orchestration Layer for the Agentic Enterprise.”
Meet us there.


2
1
12
788
BLACKBOX AI retweeted

Jun 6
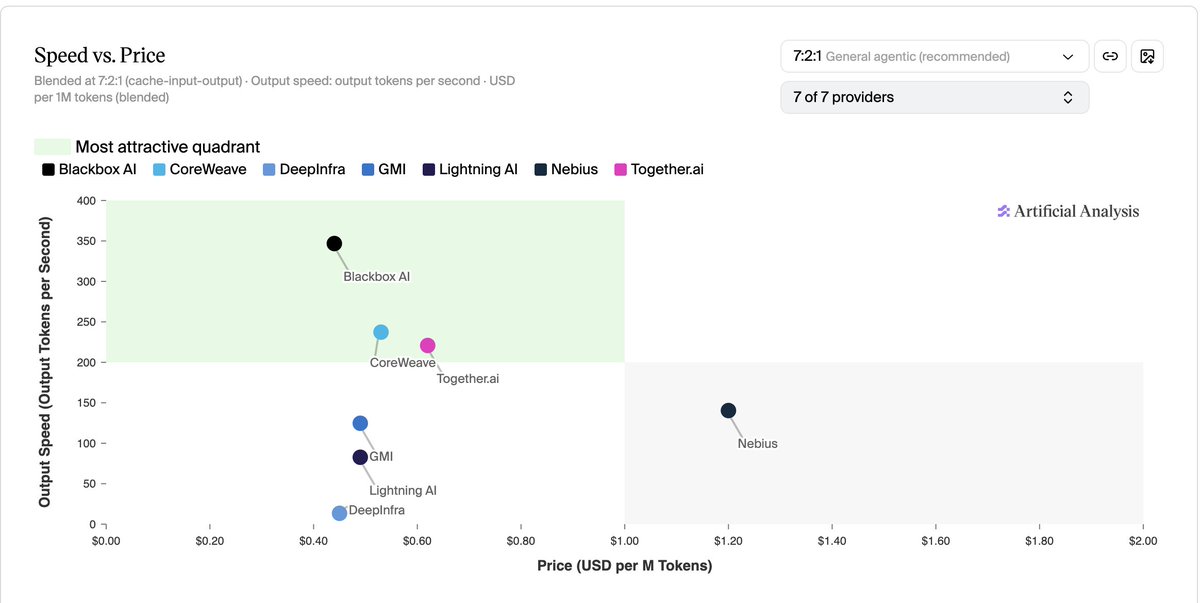
"Blackbox AI stands out as the overall leader, ranking first across all three categories: speed, latency, and pricing."
YOU ARE WELCOME 🫡
2
1
15
1,632
Jun 5
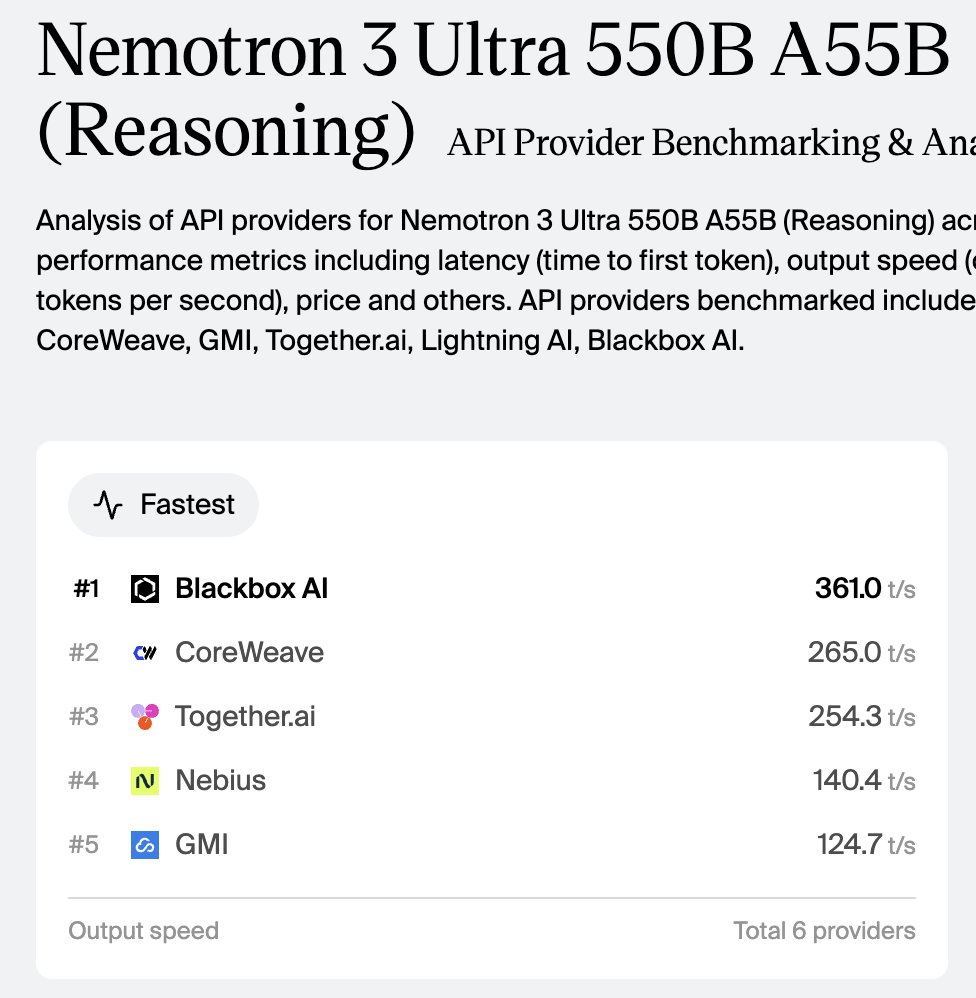
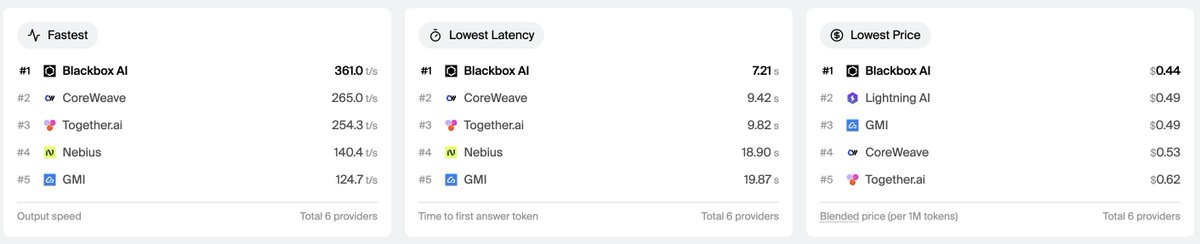
Nvidia Nemotron 3 Ultra - Output tps
Blackbox AI -> 420
CoreWeave -> 261.7
Together AI -> 249.3
Nebius -> 140.7
GMI -> 124.7
3
1
19
1,247
Jun 4
Well well well... turns out that not all providers are created equal

Introducing NVIDIA Nemotron 3 Ultra.
A frontier smart open model built for long-running agents that need to plan, reason, use tools and keep working across complex coding, research and enterprise workflows.
Up to 5x faster inference and up to 30% lower cost for agentic tasks.
Learn more: nvda.ws/4x9nGps
4
1
35
3,851
Jun 4
3
518
Jun 4
We partnered with @nvidia as their single flagship provider and optimized Nemotron 3 Ultra to the highest inference speed served today at 420 output tokens/sec

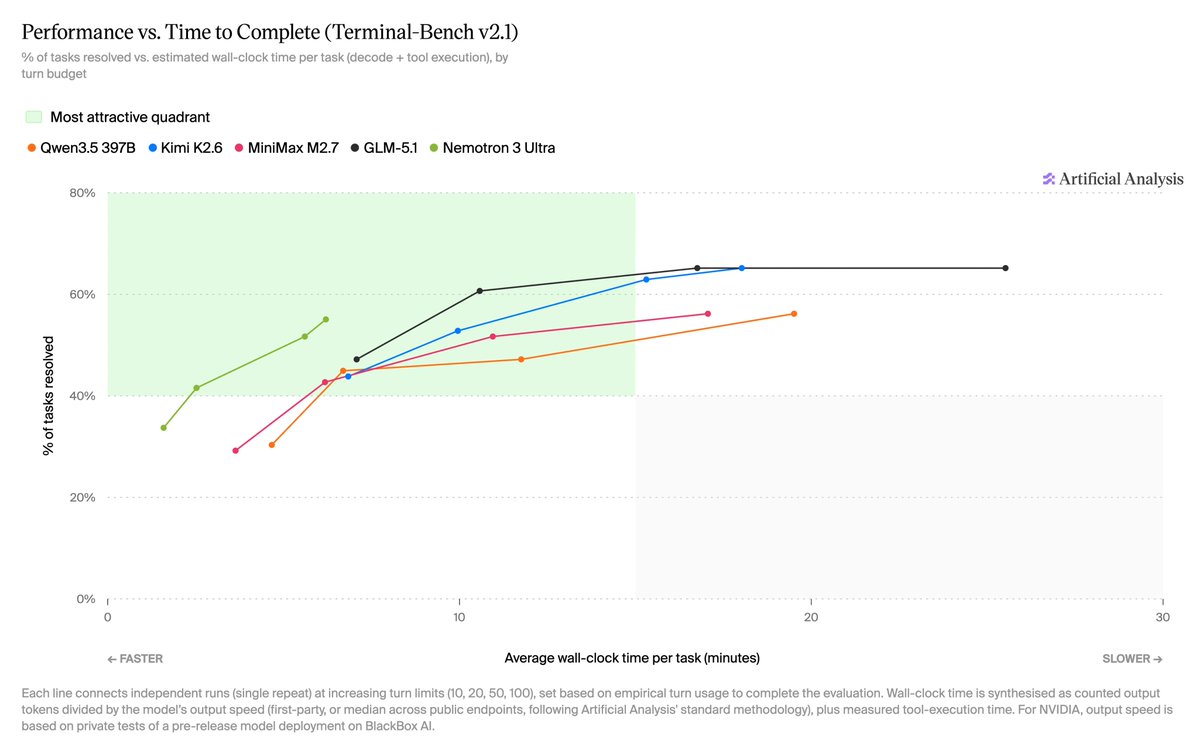
Nemotron 3 Ultra was launched today, including a focus on low latency agentic performance. We tested it against peers under restricted turn-usage limits on Terminal-Bench v2.1 - @NVIDIA Nemotron 3 Ultra completes tasks at a much faster pace than peers due to its high inference speed while scoring competitively on the benchmark.
In this analysis each model is given a ‘turn limit’ within which it can complete tasks, inside a customized version of the Terminus 2 harness which advises it of this limit. We apply 4 increasing turn limits and trace each result’s tradeoff of task latency and performance. Time per task, on the X axis, is calculated as decode time based on token usage and measured endpoint output speeds (for Nemotron 3 Ultra, speeds were measured on a pre-release deployment on @blackboxai), plus the actual time spent executing tools to complete the benchmark.
Nemotron 3 Ultra is the fastest across all turn limits and sits on the Pareto frontier for performance versus time per task for this evaluation.
2
2
31
2,193
BLACKBOX AI retweeted

Nemotron 3 Ultra was launched today, including a focus on low latency agentic performance. We tested it against peers under restricted turn-usage limits on Terminal-Bench v2.1 - @NVIDIA Nemotron 3 Ultra completes tasks at a much faster pace than peers due to its high inference speed while scoring competitively on the benchmark.
In this analysis each model is given a ‘turn limit’ within which it can complete tasks, inside a customized version of the Terminus 2 harness which advises it of this limit. We apply 4 increasing turn limits and trace each result’s tradeoff of task latency and performance. Time per task, on the X axis, is calculated as decode time based on token usage and measured endpoint output speeds (for Nemotron 3 Ultra, speeds were measured on a pre-release deployment on @blackboxai), plus the actual time spent executing tools to complete the benchmark.
Nemotron 3 Ultra is the fastest across all turn limits and sits on the Pareto frontier for performance versus time per task for this evaluation.
10
11
181
15,594
BLACKBOX AI retweeted
Jun 4
there is a convention in charts to always mention 'higher the better' or 'lower is better'
its simpler to keep it 'blackboxer is better'
Jun 4

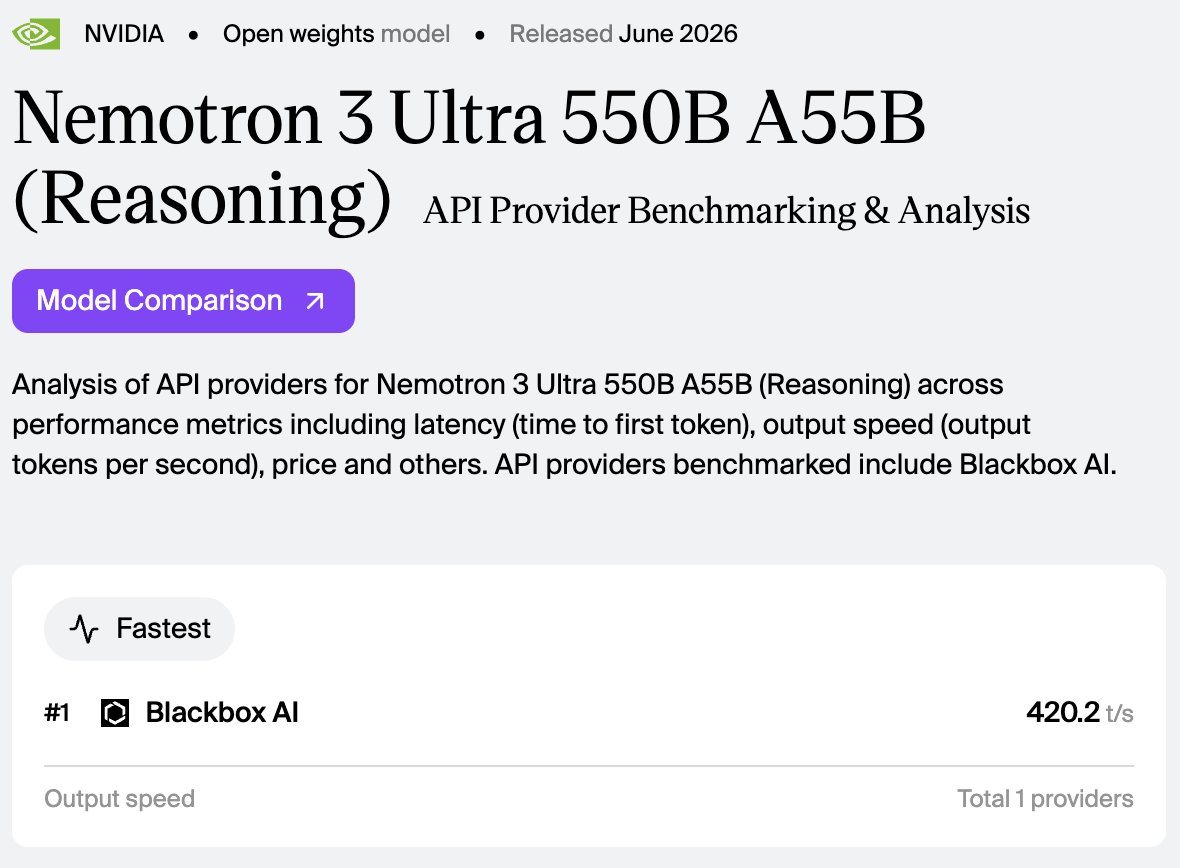
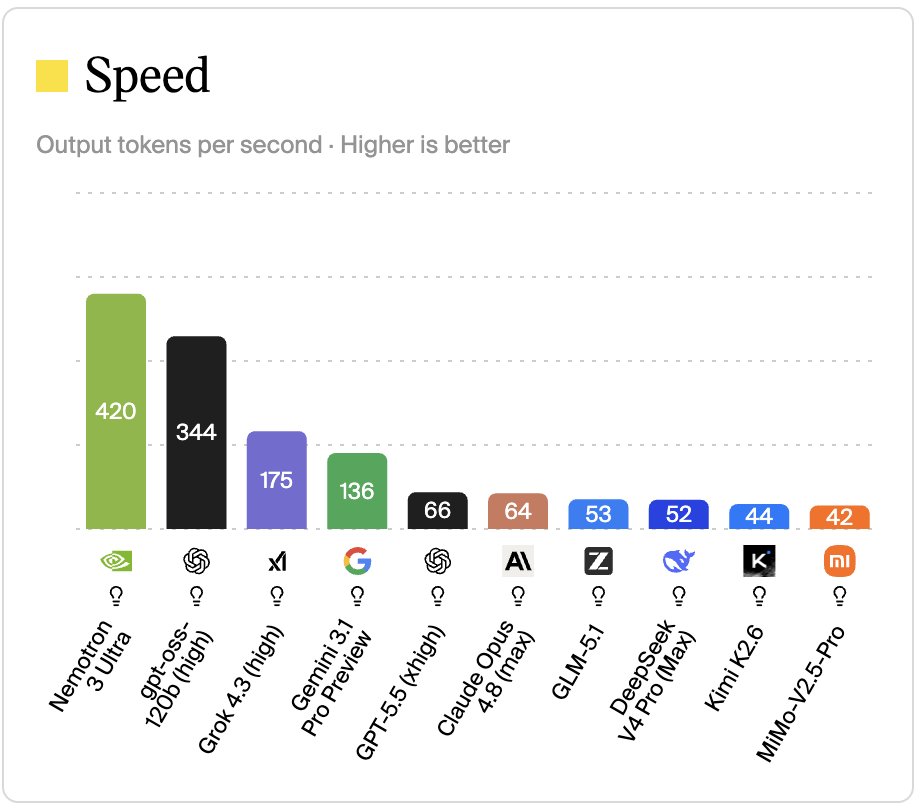
420.2 tok/s on a 550B model. ⚡️
Nemotron-3-Ultra-550B-A55B reaches 420.2 tok/s powered by BLACKBOX AI Inference Engine.
Blackbox now delivers the fastest inference in the industry, outperforming every other provider, including on smaller-parameter models.
Check our blog in the comments.
1
6
1,140
Jun 4
Open source needed a comeback.
Agents needed real speed.
The world needed an American answer.
Day 0. @nvidia Nemotron Ultra is live on Blackbox at 420 tok/s.
$0.37 in. $1.08 out. Per million tokens.
550B parameters. Faster than models a fraction of its size.
The fastest inference ever shipped.
The agentic era starts now. 🇺🇸⚡
Full breakdown in the comments. 👇

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
6
17
59
6,502
BLACKBOX AI retweeted
Jun 4
“Why work if you don’t want to be the best?” 🐍
Jun 4
420.2 tok/s on a 550B model. ⚡️
Nemotron-3-Ultra-550B-A55B reaches 420.2 tok/s powered by BLACKBOX AI Inference Engine.
Blackbox now delivers the fastest inference in the industry, outperforming every other provider, including on smaller-parameter models.
Check our blog in the comments.
2
7
824
Jun 4
420.2 tok/s on a 550B model. ⚡️
Nemotron-3-Ultra-550B-A55B reaches 420.2 tok/s powered by BLACKBOX AI Inference Engine.
Blackbox now delivers the fastest inference in the industry, outperforming every other provider, including on smaller-parameter models.
Check our blog in the comments.
NVIDIA has just released Nemotron 3 Ultra, the new most intelligent US open weights model, with leading speed for its intelligence
Nemotron 3 Ultra scores 47.7 on the Artificial Analysis Intelligence Index, well ahead of the next strongest US open weights models, Gemma 4 31B (39.2), Nemotron 3 Super (36.0) and gpt-oss-120b (33.3), but behind the Chinese-led open weights frontier (Kimi K2.6 at 53.9).
We partnered with @NVIDIA to evaluate this model for intelligence and speed ahead of its public release. These figures use the final NVFP4 weights that NVIDIA recommends for inference, but our tests show minimal intelligence impact compared to BF16 testing, with higher precision resulting in an Artificial Analysis Intelligence Index score of 48.2 vs. the NVFP4 score of 47.7.
Key Takeaways:
➤ Nemotron 3 Ultra leads in speed for its intelligence: through BlackBox AI ahead of release, Nemotron 3 Ultra is served at over 400 output tokens per second - this is slightly faster than the typical serving speed of gpt-oss-120b despite being >4X larger, and comes with significantly greater intelligence
➤ Largest Nemotron 3 model so far: with approximately 550 billion total parameters and 55 billion active, Nemotron 3 Ultra is significantly larger than its siblings and is the largest and most intelligent US open weights model release ever
➤ Nemotron 3 Ultra is the leading US open weights model on the Artificial Analysis Intelligence and Agentic Indexes by far, but Gemma 4 31B scores ~1 point higher on the Coding Index (comprised of Terminal-Bench Hard and SciCode)

5
21
204
23,986
Jun 4
4
1,136
BLACKBOX AI retweeted
Jun 3
big news for 🇺🇸 open source models & agents ... this week ...
1
1
8
622
BLACKBOX AI retweeted
Jun 1
best open source model 🫡
1
9
1,191
BLACKBOX AI retweeted
Jun 1
🇺🇸 dominance 🚀


1
4
936