
Bookoora is an AI-focused entertainment & education platform focusing on personalized audience experiences in LEARN. GAMES. VOICE. STORY. bookoora.com
Joined December 2023
- Tweets 260
- Following 358
- Followers 34
- Likes 58
106 Photos and videos












Pinned Tweet

Jun 9
4
35
May 31
Hey @imagine @xai I was testing your new grok 1.5 preview and generated a 15-s clip in your console.x.ai/team and spent US2 . However after generation, I cannot access any generation library to download the asset?
150



Apr 18
youtube.com/watch?v=d7QBMNU4…
How @watchonwonder, @LumaLabsAI and @awscloud collaborated to produce The Old Stories: Moses, the next big-scale #AI production after House of David, starring Sir Ben Kingsley.
54
Bookoora.com retweeted

Apr 14
Dreamina Seedance 2.0 is now live via BytePlus ModelArk API.
Turn text, images, and clips into cohesive videos — with consistent characters, controlled motion, and enterprise-ready quality, all in one workflow.
Go make it move: tinyurl.com/mszv5b3a
Learn more: tinyurl.com/ypvd2h5t
#DreaminaSeedance #BytePlus #ByteDance #ModelArk #AIVideo #GenerativeAI
78
67
393
414,803
Apr 12
Hey @topazlabs
Please include targeted file size indicators for your upscales. Most AI generations now have a file size limit.
Quite a pain and waste of time to keep toggling upscale parameters just to meet these size limitations...
The problem however stems from some model providers.
We need better leeways with image file size limits (10MB only for @BytePlusGlobal) and prompt text character limits (eg. 2000 char limit on @Hailuo_AI and 3500 on @BytePlusGlobal @ByteplusAIDevs ).
1
34
Apr 12
We've lost countless credits on Veo 3.1 Fast/Lite due to these issues despite repeatedly force-prompting targeted restrictions. Anyone else face the same issues?
1) Wrong speaker talks in multi-speaker environment or worse, everyone moves their mouths as if they're ventriloquists
2) Character stubbornly turns around and AI renders a totally different face, clothing, hand, rings, etc.
3) Camera stubbornly turns around and we see new and unnecessary structures, backgrounds, characters previously blocked by foreground characters
4) No minors in the scene (so we have to age our child characters)
5) Still only 8 seconds when the norm now is 12-15 seconds
Prompting helps but on average, each prompt generation will use up between 3-5 generations.
Weigh these against the now-possible one-shot generations from say, Seedance 1.5 Pro or Seedance 2.0 (which now costs between USD1.5-USD3 per 15s gen output) and you'll see the real economics.
The expected Google Veo 4 needs to be multimodal, supports at least 15 seconds output and AI-gen human character uploads, to remain justifiably and economically viable.
43
Mar 25
So we finally got access to Seedance 2.0 on Dreamina Capcut to continue our work on Allastria Chapter 4. All four of these shots (where the woman's face is tilted sideways with varying gaze at different angles) were all rejected.
In the end, we had to change our story/camera angle.
@BytePlusGlobal #Seedance2 #Dreamina #Capcut @capcutapp



113
Mar 20
If you're wondering what ByteDance (makers of TikTok) is doing with Seedance 2.0 (instead of its global launch)...
pandaily.com/byte-dance-laun…
1
137
Mar 20
Let the family decide. When the film comes out, let the audience decide. In between, yes, we should just leave matters be.
Mar 18

People are going to disagree, but as long as he himself wanted it and his own family gave the greenlight, everyone else should shut up.
32
Mar 16
This is not generative AI.
Mar 15

🎾Introducing LATENT: Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data
Dynamic movements, agile whole-body coordination, and rapid reactions. A step toward athletic humanoid sports skills.
Project: zzk273.github.io/LATENT/
Code: github.com/GalaxyGeneralRobo…
17
Mar 15
Australian tech entrepreneur used ChatGPT and AlphaFold to find a cancer cure for his dog. @GoogleDeepMind @OpenAI
theaustralian.com.au/news/te…
1
24
Mar 6
We enjoyed this AI-generated track so much, we decided to make Joe pretend-play it at a wine cellar. :) Enjoy the track.
#aimusic
1
137
Mar 4
Seedance 2.0 API pricing info. Take it what you will. :)
Mar 4

Seedance 2.0 update: The API pricing was just dropped.
Video input included: ¥46/M tokens (~$6.67/M)
Video input excluded: ¥28/M tokens (~$4.06/M)
A 15-second video costs ~¥15($2.17). That's literally ¥1 ($0.14) per second.
Do you think that's expensive? 🤔
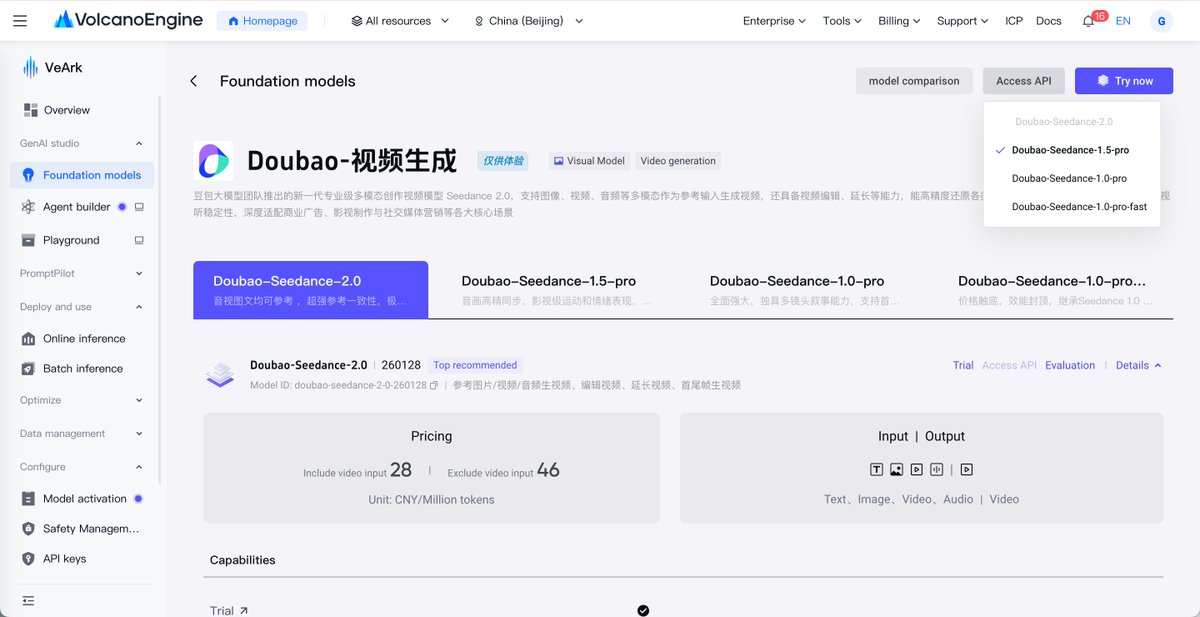
155
Feb 24
We tested this prompt on five music-generating platforms in this order (first 3 lets you download MVs for free):
- Google Lyria 3 via Gemini (30 seconds)
- Sonauto V3
- ProducerAI (now using Google Lyria v3) and
- Suno v4.5 (MV is not free)
- Udio (no downloads)
While most follow the prompted sequences accurately, Sonauto goes a different route with a recurring overarching tune.
Prompt: "An epic orchestral fantasy film score with a dynamic arc. Start: Eerie, minimalist opening with low-register double bass and haunting solo violin "teasing" a dark melody. Transition: Rapid crescendo into a high-energy battle anthem. Core: Driving taiko drum percussion, rhythmic string ostinatos, and soaring, emotionally-charged legato violin melodies. Crescendo: Grand cinematic finale featuring a powerful SATB choir (non-verbal chants) and full brass section. Ending: Sudden decrescendo into a "soft ripple" effect of delicate pizzicato strings and a faint, ethereal vocal hum. No synthesizers, no electronic processing, no lyrics."
Suno v4.5 version: suno.com/s/zRTl4VAbFmjTdNOO
Udio version:
udio.com/songs/rdfetWEz4wuH9…
#producerAI #sonauto #udio #suno #lyria #gemini #lyria3
175