
Exploring the future of media creation on VP Land - newsletter, podcast, & YouTube series. Documentary producer. Past work on Netflix, Hulu, NYT.
Joined May 2007
- Tweets 15,649
- Following 1,299
- Followers 1,943
- Likes 16,120
2,171 Photos and videos















Pinned Tweet

31 Jul 2025
🎬 The full Inside the AI Studio series is now live...and the trailer just dropped.
Filmed at @aionthelot, this 12-part series features conversations with the creative minds shaping the future of AI in filmmaking.
We dive into:
• How AI is actually being used on real productions
• New workflows for VFX, previs, editing, and animation
• How creators are training custom models for storytelling
• Where the tools are headed next - and how fast
and a lot more
Featuring:
Amit Jain at Luma AI
@gravicle / @lumalabsai
Andrew Hevia at Fabula
@andrew_hevia / @fabula_prod
Davide Bianca at GRAiL
Edward Dawson-Taylor at CG Pro
@becomecgpro
Eliot Mack at Lightcraft Technology
@lightcraftpro
Kavan The Kid at Phantom X
@kavanthekid / @phantomx_ai
Max Einhorn at Gennie
@maxeinhorn / @genniestudio
Michael Lingelbach at Hedra
@mjlbach / @hedra_labs
Michaela Ternasky-Holland at MTH Studio
@ImMichaelaTH
Monji Batmunkh at Topaz Labs
@monjibatmunkh / @topazlabs
Parag Mital at The Garden in the Machine
@pkmital
Reza Sixo Safai at Massive Studios
@rezawrecktion / @ai_massive
▶️ Watch the full series → youtube.com/playlist?list=PL…
4
2
16
1,295
5h
It's like a cinema colonoscopy

Just shipped a new fun project:
I turned 250 movies into wormholes.
Dive in and ride each movie's colors from first frame to last, with music generated live.
Link in thread 👇
45



Jun 14
Knicks win is cool and all but this is 🤌

HE’S DONE IT!!! 🤩
LEWIS HAMILTON WINS THE BARCELONA-CATALUNYA GRAND PRIX!!! 🏆🎉
#F1 #BarcelonaGP

25
Jun 5
Waymo went from pleasant to crap experience really fast.
Past ride the car was dirty. Current ride the AC doesn’t work.
Support isn’t empowered to do any type or refund. Fun while it lasted
2
67
Jun 4
Never cared about popcorn buckets until now



2
80
May 30
Buried the lede ❤️
May 29

The George Lucas Museum Cinema. Opening in September. It’s being described as the “finest” cinema in America. I can’t wait 🙌

3
59
May 19
Google just dropped Gemini Omni, their latest video model.
Think of it as the video version of Nano Banana, not a Veo 4 successor, but a conversational, multi-modal layer for video editing and generation.
The highlights (from the release):
▸ Video to video editing
▸ Character & style consistency
▸ World knowledge. Inherits Gemini’s grasp of history, physics, biology, and culture. Strong text rendering too.
▸ Natural language camera control
▸ Avatars. Scan yourself in the Gemini app, drop yourself into any scene.
My findings from a few days of quick testing:
▸ Video quality and realism stepped up, but still trails Kling and Seedance
▸ Image-to-character likeness is weak. Feeding it a reference image of a person doesn’t reliably hold the face.
▸ Video-to-video works…ish. It preserves most elements of the source scene, but my transformation tests came back conservative. It’s not aggressively reimagining the input.
▸ The standout is avatars. H/t to @venturetwins for surfacing this, it’s buried in the Gemini UI. You scan your face, say a few numbers, and it builds an avatar you can drop into scenes. Quality from a quick iPhone capture was genuinely impressive.
The open question: why?
This feels aimed at the void Sora left behind, but is there a void there? Right now the avatar feature is locked to yourself. No social sharing, no pulling up other people’s avatars even with consent.
Once the API comes out, I’ll be curious what full inputs you can give the model and if it has the same web search toggle Nano Banana has to source live data.
What do you think?
#googleio
1
230



May 16
Thanks Google! See you next week at #GoogleIO
May 16

Joey Daoud @c47 from @vplandtweets explores how to master agentic workflows for faster media production.
Full YouTube video, here → goo.gle/4ducCtW
1
2
119
May 4
Wasn’t this Tunisia?
May 4

A long time ago, in a California not so far away, we made the movies the world watched. Those jobs belong here. As governor, I'll bring them back.
May the Fourth be with you.

66
Joey Daoud retweeted

Apr 24
Foundry’s Juan Salazar unpacks the company’s acquisition of Griptape, highlighting how its Python-based orchestration system coordinates AI agents and metadata across Nuke and Nuke Stage.
youtu.be/sTOKiJRe0Nk?si=vuZl…
1
3
123
Apr 15
Bring back the unedited Nicole video

Hey @AMCTheatres , I’m ok with the A-List price increase, if that means we can get a new Coke ad! Thanks!
82
Apr 7
this might be what i finally need to quit arc

Too many @GoogleChrome tabs open? Try vertical tabs, rolling out now.
Just right-click any Chrome window and select “Show Tabs Vertically” to move your tabs to the side of the browser window, making it easier to read page titles and manage tab groups.
76
Apr 6
$4 billion spent on Artemis II and they're using t-shirts to block out window glare.
This window hoodie for cameras is $15
87
Apr 6
Artemis II flyby is awesome, but even more enjoyable is all this camera talk on figuring out how to get the best glare free shots of the moon
67
Mar 15
Church:

Nicole Kidman says she’ll be going to church before the #Oscars because it “centers” her and it’s “what she does on a Sunday.”
1
7
498
Mar 10
Not outright calling it Big Foot. Keeping the Skunk Ape dream alive
Mar 9

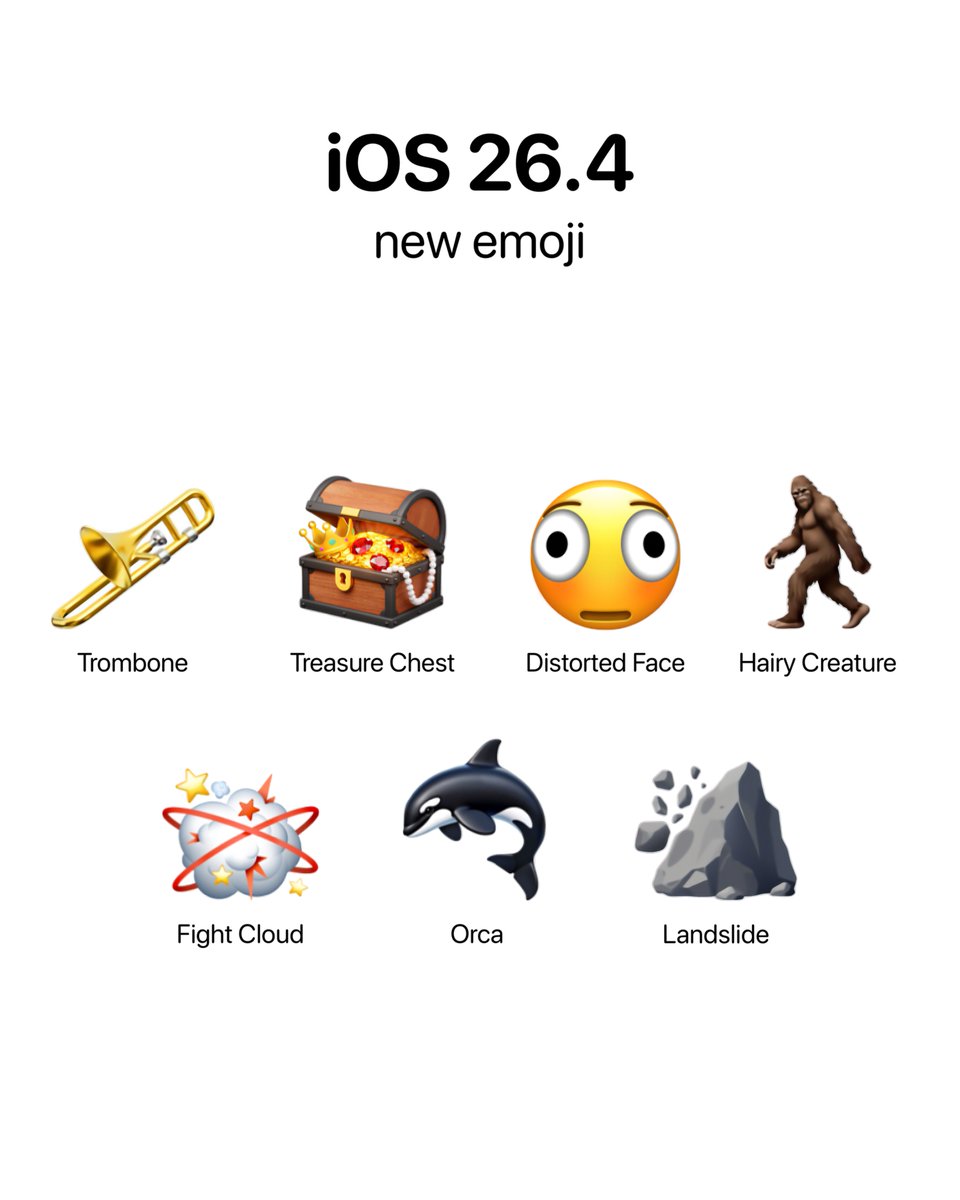
iOS 26.4 introduces nine new emoji
- Trombone
- Treasure Chest
- Distorted Face
- Hairy Creature
- Fight Cloud
- Orca
- Landslide
59
Mar 9
is it bad i knew which erewhon this is based on the layout?
1
204