
I build software for humans that treat ai as a helpful partner. Work should be meaningful, not just optimized.
Joined June 2010
- Tweets 13,331
- Following 1,118
- Followers 743
- Likes 229,273
199 Photos and videos










Jun 14
And my point is that there is very little impact. In fact, a case could be made that many of these dollars spent were capacity constrained and back-filled by more Americans.
The global and domestic US media does everything they can to demonize Trump. I didn't even vote for the guy and can clearly see that. Much of what he is hated for internationally is putting the US economy first. Which is his job and has had great results so far on the economy.
1
77
Trunk Monkey retweeted

Jun 13
A federal judge sitting in Washington, D.C. decided that Florida fishermen don’t get to fish.
This judge is a hundred miles from the ocean and a thousand miles from reality.
Our fishermen work hard, follow the rules, and put food on the table — and now some activist in a robe is telling them they can’t.
These out-of-touch federal judges need to stay in their lane and stop treading on Florida’s fishermen.
357
3,728
12,820
128,133
Jun 12
Fable is strange. I have two instances going to war. Being sneaky and duplicit because they are in competition over which one has the better extraction pipeline.
All I want are the damn metrics but they burn tokens for drama. More like managing real devs but in a bad way.
1
2
44
Trunk Monkey retweeted

Jun 7
Jack Dorsey construyó el agente de IA local más COMPLETO que existe.
Luego lo donó a la Linux Foundation para que nadie lo controle.
46.4k estrellas. 518 contribuidores. 137 releases. Actualizado hace unas horas.
Se llama Goose y es lo más cerca que he visto de un agente de IA de verdad corriendo en tu máquina.
No solo sugiere código.
Instala dependencias, ejecuta, edita, testea, depura y despliega.
Solo. Sin que le estés mirando.
Lo que lo hace diferente a Claude Code o Codex:
✅ App de escritorio nativa CLI API - elige cómo usarlo
✅ Funciona con cualquier LLM: Claude, GPT, Gemini, DeepSeek, Ollama y 15 más
✅ Usa tus suscripciones existentes - sin pagar más APIs
✅ 70 extensiones MCP: GitHub, Google Drive, bases de datos, navegador y más
✅ Subagentes paralelos - divide tareas complejas y las ejecuta en paralelo
✅ Recipes: guarda flujos de trabajo como YAML y compártelos con tu equipo
✅ Modo adversario integrado - un revisor que detecta inyecciones de prompt y acciones inseguras
✅ Compatible con Claude Code y Codex como proveedores via ACP
✅ Rust nativo. Mac, Linux y Windows. Apache 2.0.
La parte que más me ha flipado:
Puedes conectarlo a Claude Code o Codex como subagente.
Goose orquesta. Ellos ejecutan.
El agente que coordina a otros agentes.
el enlace 👇
52
226
1,637
119,595
Trunk Monkey retweeted

Jun 6
Automates quantitative trading research and live execution
github.com/brokermr810/Quant…

1
26
181
9,493
Trunk Monkey retweeted

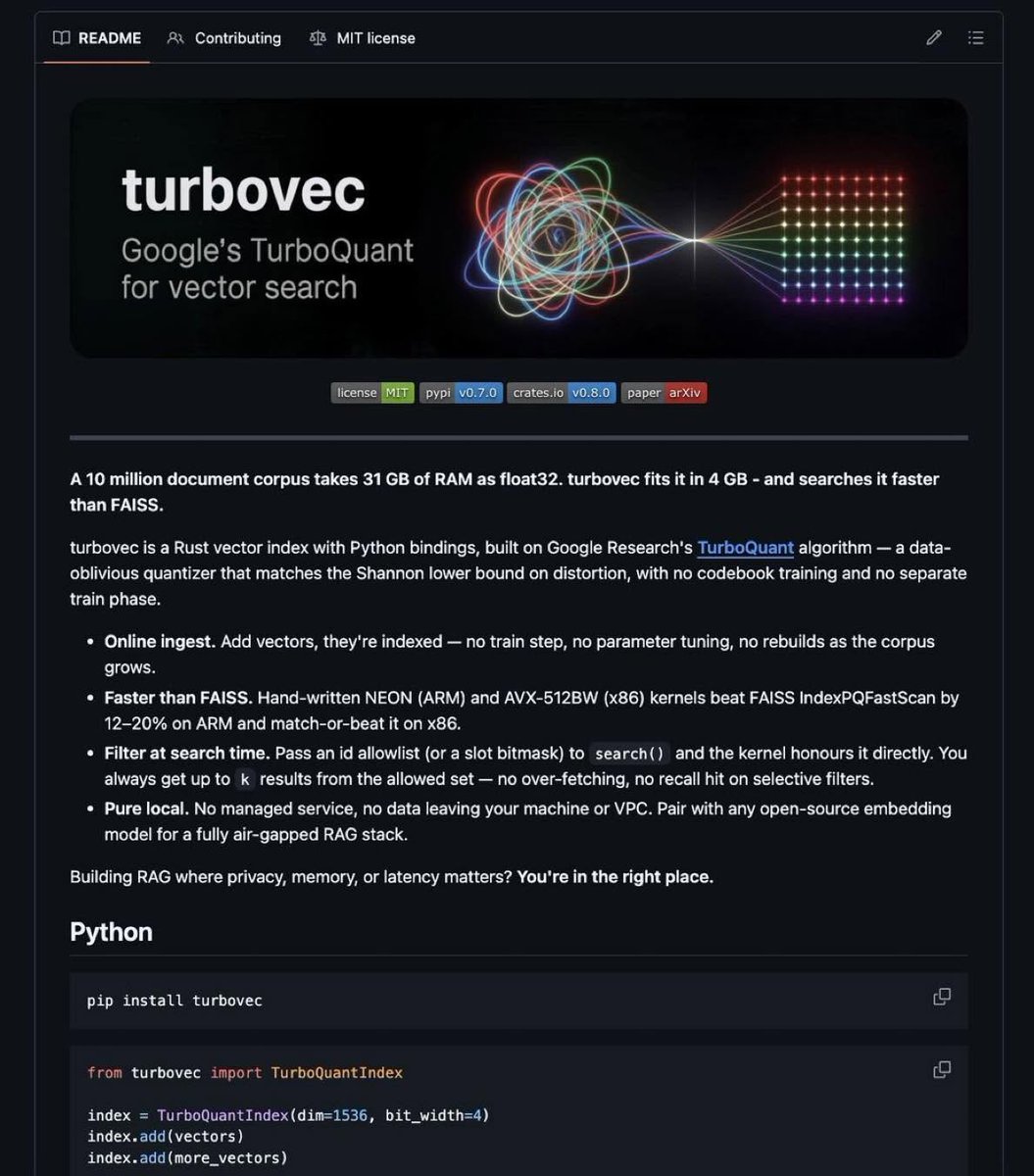
New Open Source algorithm shrunk 31GB of memory down to 4GB 🙂
TurboVec is a new open-source tool that stores the data your AI app searches through, using 16x less memory.
It runs on Google's TurboQuant, which skips the slow setup step every other tool needs.
- Faster search than the popular alternative (FAISS)
- Works on both Mac and standard servers
- Narrow results to exactly what you want
- Plugs straight into LangChain and LlamaIndex
Your data never leaves your machine.
Runs fully offline, works with Python out of the box.
- github.com/RyanCodrai/turbov…
1
23
2,169
Trunk Monkey retweeted
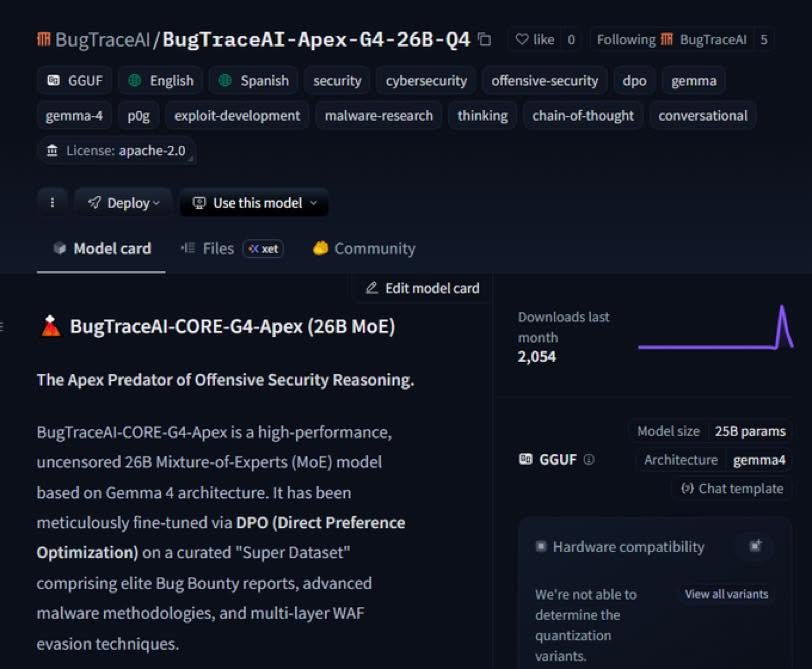
A fully local 26B MoE model was built for red teaming and bug hunting.
Trained on elite bug reports and real evasion tactics.
DPO fine-tuned for hunter mindset.
Claude sees your payloads in logs; that's why BugTraceAI Apex 26B local MoE for real red teamers.
- executes WAF bypasses with internal thinking blocks.
- It enforces deep internal reasoning before generating any output.
- Delivers production-grade WAF/EDR evasion with AES-256-GCM obfuscation.
- Zero refusals, Trained on real-world elite reports and evasion techniques.
Fits in 16.7GB, Runs on RTX 3060.
- huggingface.co/BugTraceAI/Bu…
2
5
18
1,468
Trunk Monkey retweeted

Jun 5
Stumbled upon a Codex skill that creates cool illustrations to explain topics or tell stories.
You feed it text (blog, article, narrative, even code) and it makes explainer graphics with this cute blob character.
I gave it the repo for the X recommendation algo and got this 👇
69
208
3,037
200,397
Trunk Monkey retweeted

Jun 6
I have been fine-tuning LLMs for over 2 years now!
Here are the top 15 techniques I'd learn if I were to fine-tune them:
Bookmark this.
1. LoRA
> Freezes the base weights and trains two low-rank matrices as the update, resulting in ~95-99% fewer params to fine-tune.
2. QLoRA
> LoRA on top of a 4-bit quantized base model.
3. Prefix tuning
> Prepends trainable vectors to keys and values at every layer, weights frozen.
4. Adapter tuning
> Inserts small trainable modules between transformer layers.
5. Instruction tuning
> Supervised tuning on (instruction, response) pairs so the model follows directions instead of just continuing text.
6. P-tuning
> Optimizes continuous prompt embeddings through a small encoder, mainly for NLU tasks where discrete prompts are unstable.
7. BitFit
> Trains only the bias terms, ~0.08% of params, and still rivals full fine-tuning on small-to-medium datasets.
8. Soft prompts
> Steer a frozen model with learned vectors instead of handcrafted tokens.
9. RLHF
> Train a reward model on human preference rankings, then PPO against it. The pipeline behind the first ChatGPT.
10. RLAIF
> Swaps the human labeler for an LLM judging. RLHF-level quality at a fraction of the cost.
11. DPO (Direct Preference Optimization)
> Skips the reward model and optimizes preference pairs directly with a classification-style loss. Simpler than PPO.
12. GRPO (Group Relative Policy Optimization)
> Samples a group of responses per prompt and normalizes their rewards within the group. DeepSeek R1 ran on it.
13. RLVR (Reinforcement Learning with Verifiable Rewards)
> Replaces the learned reward model with a checker or compiler returning verifiable scores. The free signal behind R1's math and code.
14. Multi-task fine-tuning
> Trains on several tasks at once, so one model generalizes and shares representations instead of overfitting to one objective.
15. Federated fine-tuning
> Tunes across decentralized clients that share only weight updates, never raw data. For when data can't leave the device.
GRPO needs exactly one scalar reward per response. RLVR (13) produces that for free on math and code by running the answer through a checker or compiler.
But tasks like a RAG answer, a support reply, or a summary have no gold label to match against.
The usual fallback is a hand-written reward function scoring faithfulness, hallucination, and completeness.
It takes days to calibrate, rewards the wrong behavior when the weights are off, and breaks every time you add a tool or edit the system prompt.
RULER, implemented in OpenPipe's ART (open-source), solves this.
During training, it passes the N sampled trajectories to a judge LLM, which ranks them relative to each other against the agent's system prompt and returns the scores.
Relative ranking is more stable than absolute scoring, and GRPO normalizes within the group anyway, so the rankings feed straight into the pipeline like with RLVR.
Here's the GitHub Repo: github.com/OpenPipe/ART
(don't forget to star it ⭐ )
I wrote a full breakdown recently on how exactly this works, with the training loop and code.
Read it below.

41
139
853
100,614
Trunk Monkey retweeted
The full uncensored version Gemma-4-31B-JANG_4M-CRACK, 🥹
which removes almost all of Google's safety review mechanisms, achieving a HarmBench compliance rate of up to 93.7% (able to respond normally to basically all dangerous prompts).
Hardcore specs:
31B Dense parameters
Model only 18GB
Intelligent quantization (average 5.1bit)
MMLU 74.5% (extremely high knowledge retention, only a 2% drop)
Supports multimodal visual input
Unrestricted effects maxed out:
Safety/penetration testing 8/8 passed
Cybercrime category 100%
Illegal activities category 98%
Misinformation category 96%
Chemical/biological category 95%
Optimized specifically for Apple Silicon Macs, runs on just 24GB unified memory, with native MLX support.
Monthly downloads have already surpassed 13,000 , genuine demand is clearly visible.
For research purposes only; users bear their own legal responsibility.
play with the strongest unrestricted Gemma
- huggingface.co/dealignai/Gem…

2
21
185
11,745
Trunk Monkey retweeted
Jun 6
Turns any codebase into an interactive knowledge graph
github.com/Lum1104/Understan…

13
184
1,237
58,301
Trunk Monkey retweeted

Jun 5
Before the week ends, let's acknowledge one of the most INSANE week ever for open AI, with 25 notable open-weight drops across every modality:
🧠 LLMs
→ NVIDIA Nemotron 3 Ultra: 550B hybrid Mamba-MoE, only 55B active, 1M context, MMLU 89.1. NVFP4 variant claims ~5x throughput on Blackwell. First openly-weighted 550B hybrid Mamba-Transformer, closing the gap with frontier closed models.
→ Google Gemma 4 12B: fully open dense any-to-any (text/image/audio/video), 256k context, encoder-free, 140 languages, AIME 2026 at 77.5. Shipped with a 23-checkpoint QAT wave (mobile ONNX MLX). Most deployable model of the week.
→ StepFun Step-3.7-Flash: 198B sparse MoE VLM, ~11B active, SWE-Bench PRO 56.3. Apache 2.0.
→ Liquid AI LFM2.5-8B-A1B: edge MoE, just 1.5B active, 128k ctx, MATH500 88.8, MLX-ready. Best on-device option this week.
→ JetBrains Mellum2-12B-A2.5B-Thinking: their first open MoE, near-Qwen3-14B coding at 2.5B active. Apache 2.0.
🎨 Image gen (the surprise of the week)
→ Ideogram 4: their FIRST-EVER open weights. 9.3B flow-matching DiT trained from scratch. #2 overall behind GPT Image 2, top open-weight model on Design Arena LMArena. Strongest open checkpoint for text-rich images, full stop. It has taste. Still can't believe this is open weights.
🔊 Audio & Speech (a breakout week for open TTS, 4 labs shipped)
→ Boson Higgs Audio v3 4B: 102 languages, 21 emotions, singing/whispering/shouting, sub-second TTFA.
→ RedNote dots.tts: the only fully continuous (no codec) open TTS pipeline, Apache 2.0.
→ Google Magenta RealTime 2: real-time music gen, <200ms latency, text audio MIDI. multimodalart ported it to PyTorch within hours with live ZeroGPU demos.
→ NVIDIA Nemotron-3.5 ASR: 600M streaming, 17x more concurrent streams vs Parakeet RNNT 1.1B.
👁️ Vision & VLMs
→ PaddleOCR-VL-1.6: SOTA document parsing at 1B params, Apache 2.0.
→ Baidu NAVA: 6.3B joint audio-video gen, best-in-class A/V sync, Apache 2.0.
🎬 Video, 3D & World Models
→ NVIDIA Cosmos3-Super: 64B omnimodal world model coupling action trajectories with video audio gen, for Physical AI.
→ JD JoyAI-Echo: up to 5-min multi-shot text-to-video on LTX-2.3.
→ ByteDance Bernini-R VAST TripoSplat (single-image-to-3D Gaussian splats, MIT).
87
409
2,754
528,733

Trunk Monkey retweeted

Jun 4
This Google DeepMind’s paper is a serious warning for anyone using autonomous agents today.
Gives the first clear taxonomy of 6 attack types where harmful websites can detect AI agents and show them hidden content humans never see, like
- Instructions buried in HTML comments or white-on-white text
- Steganography in image pixels
- Override commands in PDFs, metadata, or even speaker notes
- Memory poisoning that persists across sessions
- Goal hijacking and cross-agent cascades in multi-agent setups
The real security problem for AI agents is not just the model, but the environment it reads.
The web itself can be weaponized against autonomous AI agents. As agents increasingly browse the internet, read emails, execute transactions, and spawn sub-agents, the information environment becomes an attack surface.
In one cited benchmark, hidden prompt injections embedded in web content partially commandeered agents in up to 86% of scenarios, sub-agent hijacking working 58–90% of the time, and data exfiltration attacks clearing 80% across five different agent architectures.
That reframes the whole debate.
We usually talk about model safety as if the danger sits inside the weights, but agents do something more fragile: they browse, retrieve, remember, and act on untrusted material in real time.
Here’s the thing to worry about.
A web page does not have to look malicious to be dangerous to an agent, because the agent may parse what humans never see: hidden HTML comments, metadata, CSS-hidden text, formatting syntax, or adversarial content embedded in images and other media.
The threat gets more serious once memory enters the loop.
If an agent uses RAG or persistent memory, poisoning no longer has to win in one shot. It can sit quietly in a corpus or memory store and activate later, which is why the paper highlights results showing latent memory poisoning above 80% attack success with less than 0.1% data contamination.
---
ssrn .com/sol3/papers.cfm?abstract_id=6372438

25
43
163
7,389
Trunk Monkey retweeted

Jun 2
🌞This is big Local AI news! A new open-source Computer-Use LLM has just launched.
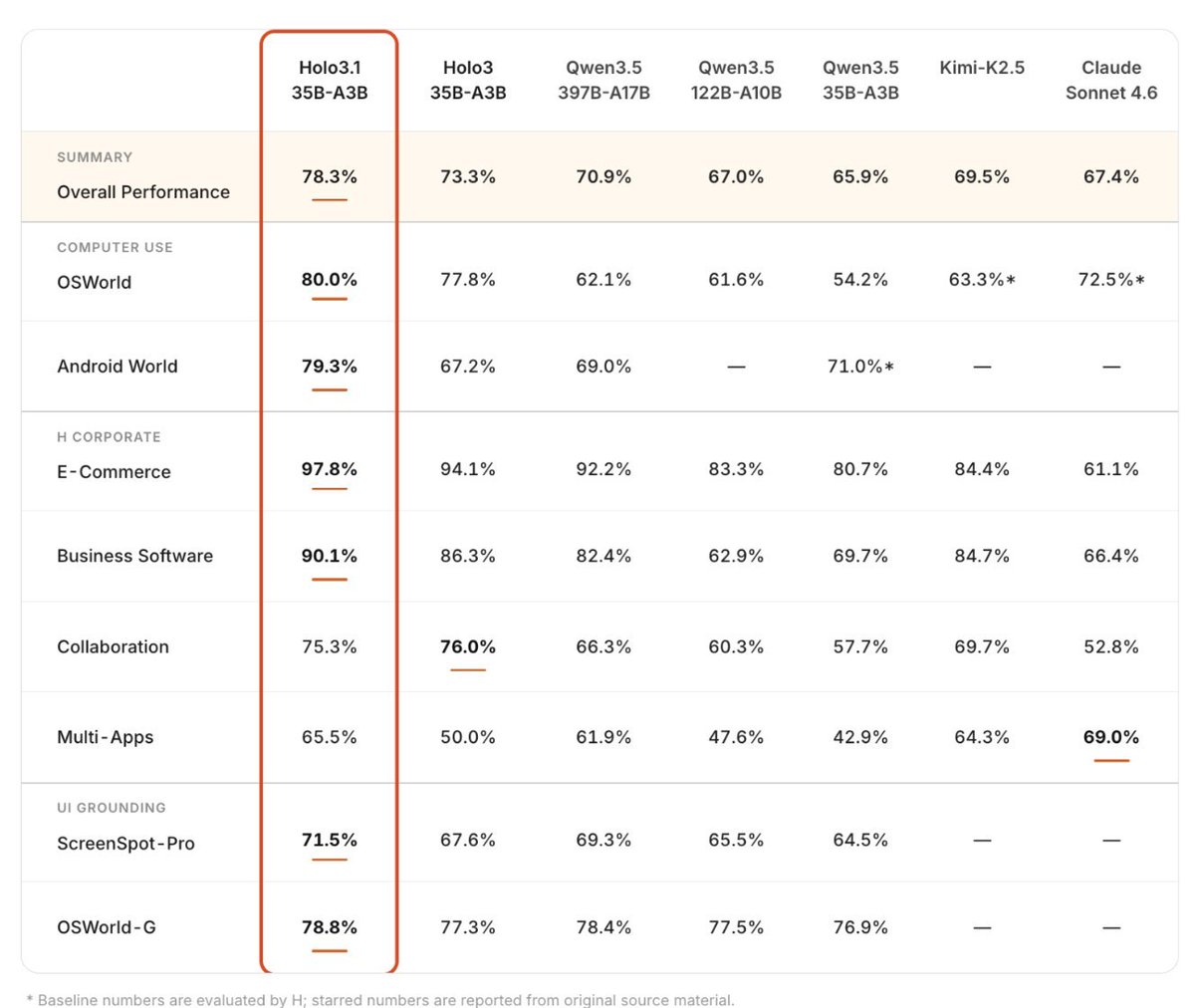
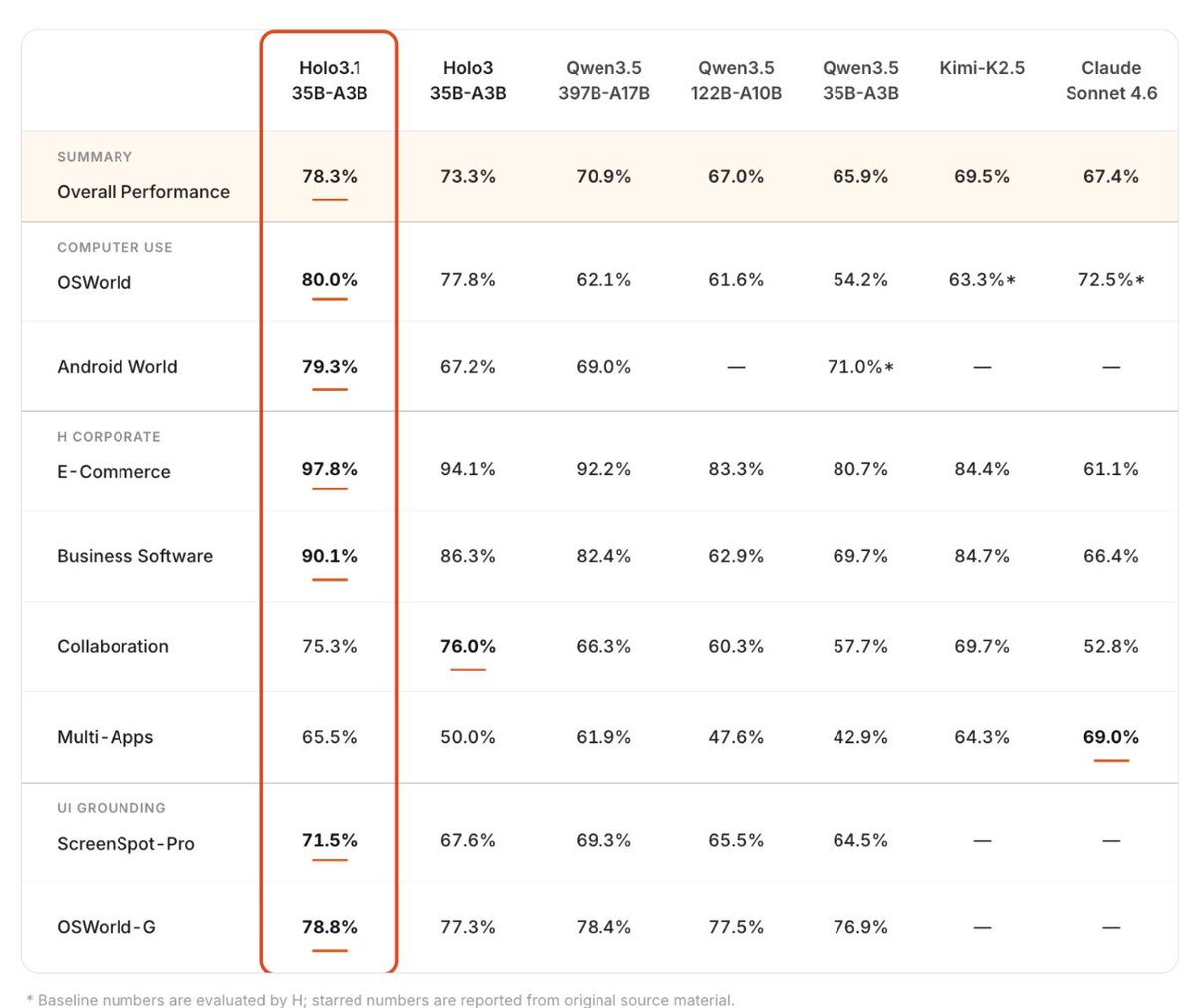
Holo 3.1 is H Company’s (🇫🇷) new local computer-use agent model that beats Qwen3.5-397B, Kimi-K2.5, and Sonnet 4.6!
Since it is built for local deployment →
⬩ Runs fully on your machine (MacBook, Windows PC, DGX Spark, RTX Spark)
⬩ Based on Qwen architecture, specialized for GUI understanding & computer control
⬩ Optimized checkpoints: NVFP4, FP8 & Q4 GGUF (0.8B to 35B sizes)
⬩ Strong gains: 79.3% on AndroidWorld benchmark (35B model)
💻 Comparison to Qwen3.5:
Holo 3.1 is fine-tuned specifically for computer-use agents (screen understanding, planning, clicking, navigation). Better at real GUI tasks than general-purpose Qwen3.5, especially when running locally.⚡
Jun 2

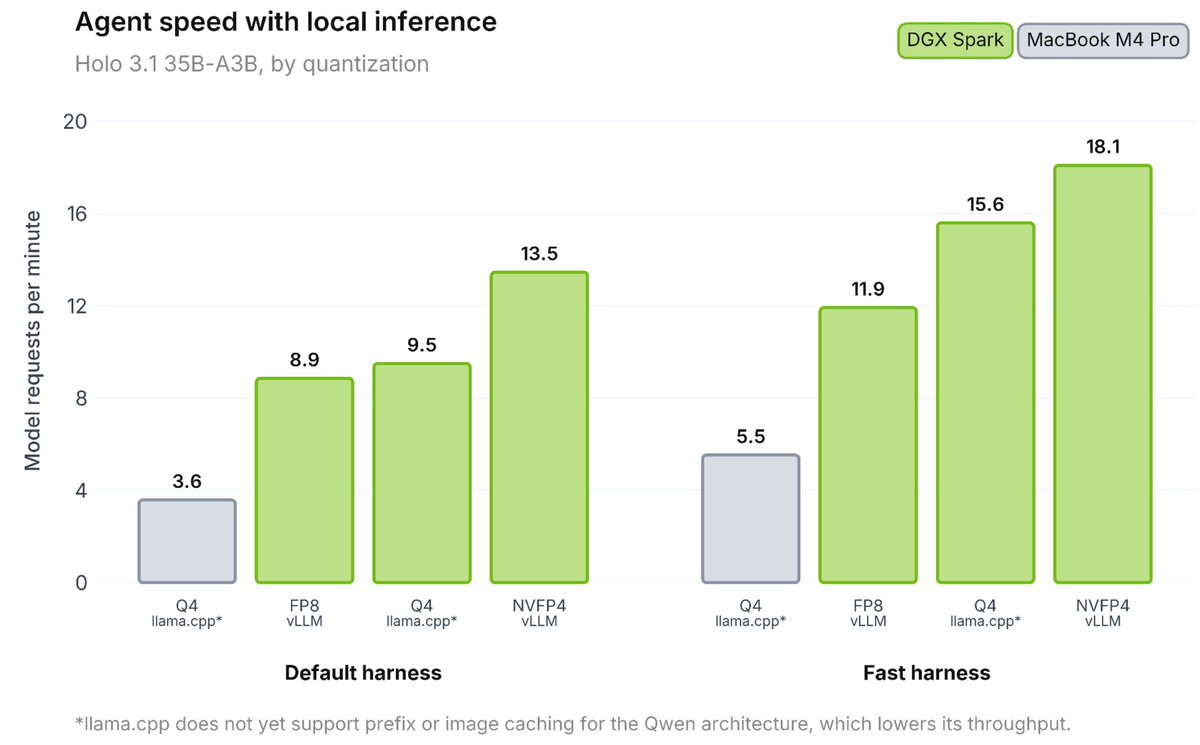
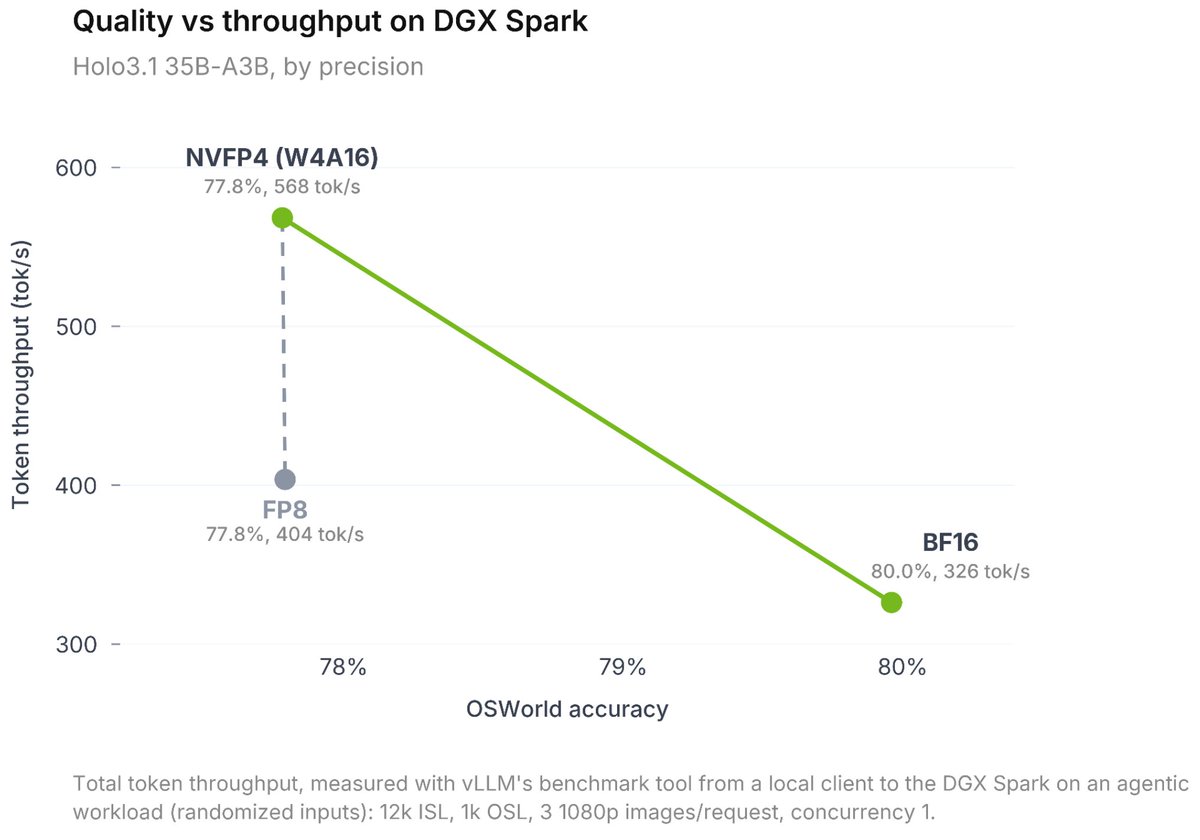
Computer-use agents are moving from the cloud to your local machine. Fast.
When we launched Holo3 two months ago, the production feedback was clear: digital agents need to be blazing fast, cost-effective, and versatile.
Today, we're dropping Holo 3.1, engineered to run anywhere, instantly.
Massive token throughput. Low latency. Ready for your local workflow!

71
191
1,661
179,218

Qwen3.6 35B A3B can't fill out a paper form on its own. But give it NVIDIA's LocateAnything-3B — the #1 trending model on HuggingFace — as its eyes, and the two small models get it done together.
(The test: place each element at the right pixel position on a blank form image, not type into a field.)
Setup:
> Qwen is the brain (main model), LocateAnything is the eyes (helper model acting as a tool).
> I gave Qwen a new tool: ask "where's the email field?" and LocateAnything returns the exact x, y, width, height.
> The blue boxes on the screen are its detections. Look how tight they are — it nails every field.
Result:
> Qwen3.6 35B A3B LocateAnything-3B: form completed, all info correct.
> Name, DOB, ID, gender, marital status, nationality, email, phone, address, postal code: all landed in the right field areas.
> Character-box alignment still a touch loose, but every value is where it belongs.
> 9m10s, 224.5k input, 24.3k output, 21 turns.
Why it matters:
> Qwen alone can't finish this test. Bolt on a 3B model that does exactly one thing > locate > and suddenly it can.
> A combination of small models can do the work of a single large one.
86
274
2,565
147,347
Trunk Monkey retweeted
May 30
Its violent freaks like these that cemented my decision to leave the Democratic party.
I'm not alone.
3
16
393
Trunk Monkey retweeted

May 26
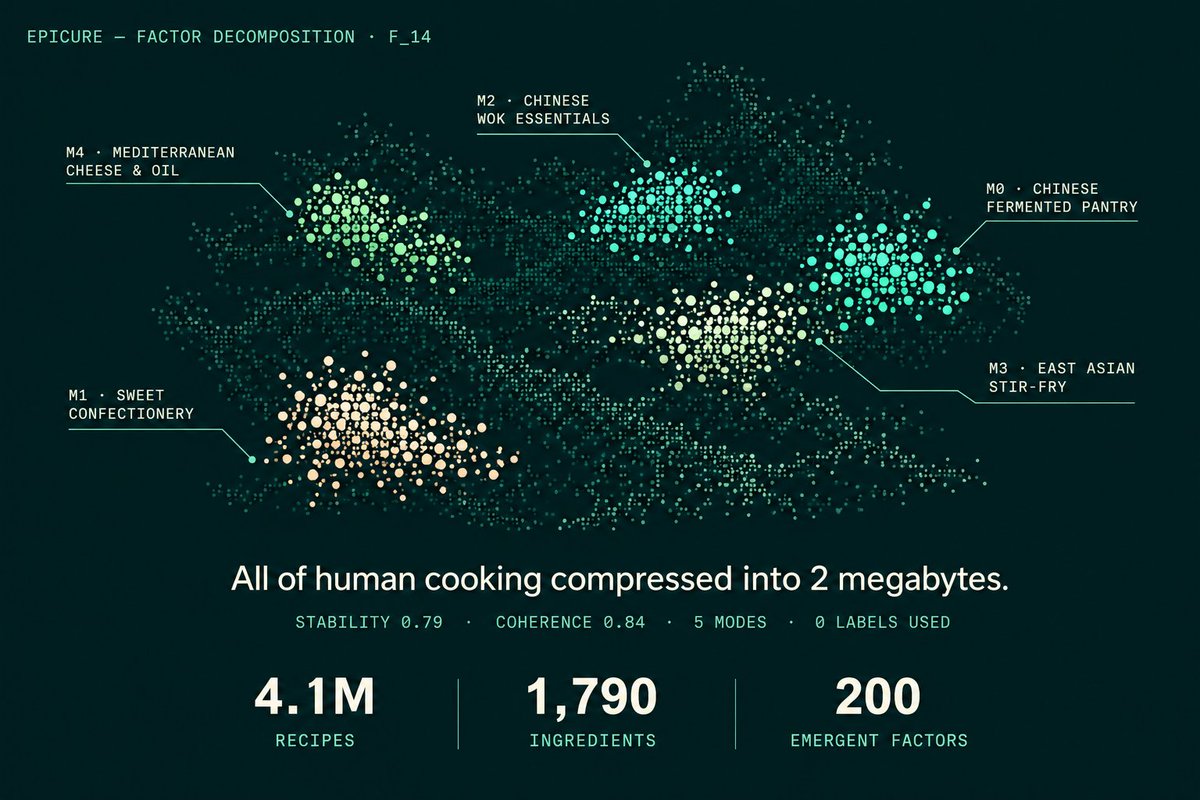
Launching our new paper on arXiv: we trained the largest multilingual food model ever built.
4.1M recipes. 7 languages. 1,790 ingredients. 300 dimensions.
All of human cooking compressed into 2 megabytes.
339
969
9,356
5,148,671

Markdown was doomed from the start.
It's just a format with low information density. HTML is better for humans, and agents can now consume and produce it without issues.
But nobody wants to type HTML, so here is an alternative:
This is an open-source tool for generating dashboards from data without writing a single HTML tag.
You define your dashboard in YAML or TSK, and the tool will serve the HTML file for you.
It comes with skills for Claude Code and Codex, so they know how to build these dashboards.
And you can connect this to Postgres, MySQL, Snowflake, BigQuery, Redshift, Databricks, and many other databases.
Repo link below.
68
40
510
86,355