
Research Scientist @ Jasper Research | Ph.D in Applied Maths (Generative Models) @Inria. I also maintain python packages democratizing Deep Generative Models.
Joined April 2021
- Tweets 184
- Following 118
- Followers 967
- Likes 363
50 Photos and videos














Pinned Tweet

17 Jun 2022
After 8 months of long coding nights ☕️ we finally officially release Pythae 🥳, a python library unifying generative autoencoder implementations including vaegan🥗, vqvae or RAEs.
🖥️ github repo: github.com/clementchadebec/b…
👉paper: arxiv.org/abs/2206.08309
12
141
897
Clément Chadebec retweeted

Jun 1
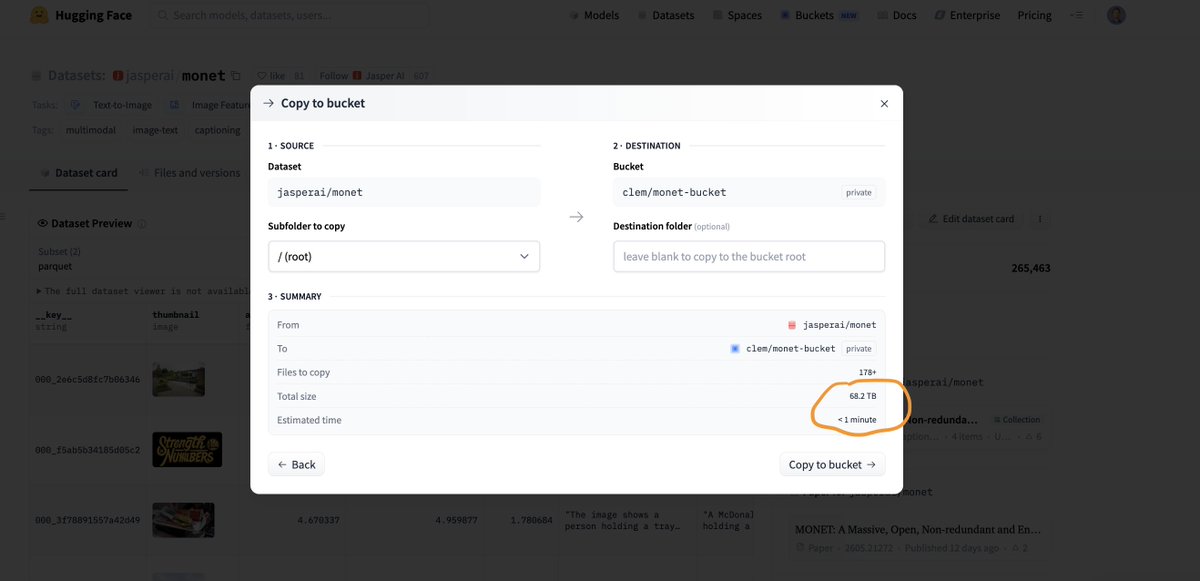
Feels quite magical to be able to clone a 68 TB dataset to my private HF training bucket while I only have a 4TB local disk, all of that in less than a minute thanks to HF infra optimizations & xet dedup!
14
9
136
14,322
Clément Chadebec retweeted

May 29
very nice dataset drop from the clipdrop team 🙌
May 28

📢 New @heyjasper release ! 📢
MONET 🌸 : An Apache2.0 deduped and recaptioned dataset of 105M samples unlocking reproducible text-to-image research.
Nano T2I 🖌️ : A codebase to train your own T2I model
🤗 @huggingface: huggingface.co/datasets/jasp…
💻: github.com/gojasper/nano-t2i
Very excited about this new release, pushing the boundaries of open and reproducible T2I research.
Congrats to the team!
Benjamin Aubin Gonzalo Quintana @onurxtasar @UlaLaParis @_jeev2 @dh7net @clipdropapp @heyjasperai
1
1
9
735
Clément Chadebec retweeted

May 28
We are starting to be quite bullish about getting in the data infrastructure business.
I just cloned 68 TB (while I only have a 4TB local disk) to my @huggingface training bucket in 1 minute 55 seconds, thanks to Xet deduplication and all our infra optimizations.
You can host your data processing pipelines on HF and leverage those insane optimizations 🔥
16
33
178
22,015
Clément Chadebec retweeted

May 28
wow 🤯
68 TB, high-quality, high-resolution, Apache 2.
Thank you! 🙌🫡
May 28
📢 New @heyjasper release ! 📢
MONET 🌸 : An Apache2.0 deduped and recaptioned dataset of 105M samples unlocking reproducible text-to-image research.
Nano T2I 🖌️ : A codebase to train your own T2I model
🤗 @huggingface: huggingface.co/datasets/jasp…
💻: github.com/gojasper/nano-t2i
Very excited about this new release, pushing the boundaries of open and reproducible T2I research.
Congrats to the team!
Benjamin Aubin Gonzalo Quintana @onurxtasar @UlaLaParis @_jeev2 @dh7net @clipdropapp @heyjasperai
2
3
54
7,746
Clément Chadebec retweeted

May 28
Ah! this is insane, I've been complaining for weeks about the lack of open text-to-image data! Congrats on the release @heyjasperai
May 28
📢 New @heyjasper release ! 📢
MONET 🌸 : An Apache2.0 deduped and recaptioned dataset of 105M samples unlocking reproducible text-to-image research.
Nano T2I 🖌️ : A codebase to train your own T2I model
🤗 @huggingface: huggingface.co/datasets/jasp…
💻: github.com/gojasper/nano-t2i
Very excited about this new release, pushing the boundaries of open and reproducible T2I research.
Congrats to the team!
Benjamin Aubin Gonzalo Quintana @onurxtasar @UlaLaParis @_jeev2 @dh7net @clipdropapp @heyjasperai
2
2
11
614

Huge open release from @heyjasperai : MONET
105M curated image-text pairs, Apache 2.0, with embeddings, VAE latents, multi-VLM captions, and a companion training repo (nano-t2i) to train a T2I model end-to-end on one H200 for <$300.
Congrats @CChadebec & co 👏
May 28
📢 New @heyjasper release ! 📢
MONET 🌸 : An Apache2.0 deduped and recaptioned dataset of 105M samples unlocking reproducible text-to-image research.
Nano T2I 🖌️ : A codebase to train your own T2I model
🤗 @huggingface: huggingface.co/datasets/jasp…
💻: github.com/gojasper/nano-t2i
Very excited about this new release, pushing the boundaries of open and reproducible T2I research.
Congrats to the team!
Benjamin Aubin Gonzalo Quintana @onurxtasar @UlaLaParis @_jeev2 @dh7net @clipdropapp @heyjasperai
1
2
4
590
Clément Chadebec retweeted
May 28
With 104M of image-text pairs, this is one of the largest, if not the largest, openly-licensed image dataset
And it's on @huggingface!!
Kudos @heyjasperai
May 28
📢 New @heyjasper release ! 📢
MONET 🌸 : An Apache2.0 deduped and recaptioned dataset of 105M samples unlocking reproducible text-to-image research.
Nano T2I 🖌️ : A codebase to train your own T2I model
🤗 @huggingface: huggingface.co/datasets/jasp…
💻: github.com/gojasper/nano-t2i
Very excited about this new release, pushing the boundaries of open and reproducible T2I research.
Congrats to the team!
Benjamin Aubin Gonzalo Quintana @onurxtasar @UlaLaParis @_jeev2 @dh7net @clipdropapp @heyjasperai
4
11
81
20,095
May 28
📢 New @heyjasper release ! 📢
MONET 🌸 : An Apache2.0 deduped and recaptioned dataset of 105M samples unlocking reproducible text-to-image research.
Nano T2I 🖌️ : A codebase to train your own T2I model
🤗 @huggingface: huggingface.co/datasets/jasp…
💻: github.com/gojasper/nano-t2i
Very excited about this new release, pushing the boundaries of open and reproducible T2I research.
Congrats to the team!
Benjamin Aubin Gonzalo Quintana @onurxtasar @UlaLaParis @_jeev2 @dh7net @clipdropapp @heyjasperai
9
33
116
45,179
May 28
Using the MONET dataset exclusively, we trained a 4B T2I model from scratch. Built on an MMDiT-inspired architecture and trained via latent flow matching with a deep compression VAE, the model can generate images up to 2048x2048 resolution.
📜 : arxiv.org/abs/2605.21272
💻: github.com/gojasper/nano-t2i
1
3
9
415
May 28
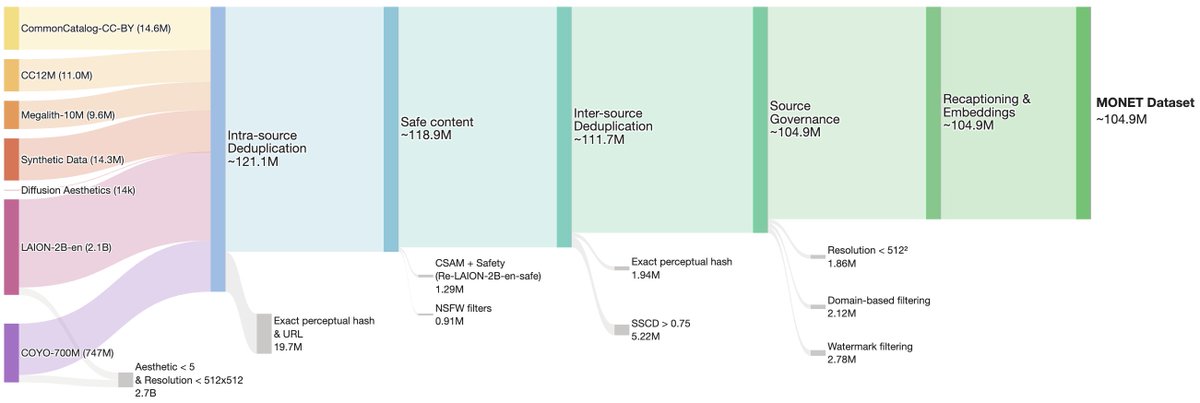
We put in place a rigorous and meticulous filtering, deduplicating, and re-captioning pipeline to create MONET:
⛽ Sourced from 2.9B images from open datasets (LAION, COYO, etc.)
✅ Filtered for high-res, aesthetics & strict safety/NSFW standards
👬 Deduplicated & stripped of stock/watermarked images
💬 Re-captioned using 4 top VLMs for rich, diverse text descriptions
🕹️ Augmented with safe, permissive synthetic data
1
2
10
293
Clément Chadebec retweeted

19 Aug 2025
Flash Diffusion is a breakthrough in accelerating conditional diffusion models for image generation. Think fewer steps, faster results, and state-of-the-art quality. Here's what you need to know:

1
1
3
652
Clément Chadebec retweeted
1 Jul 2025
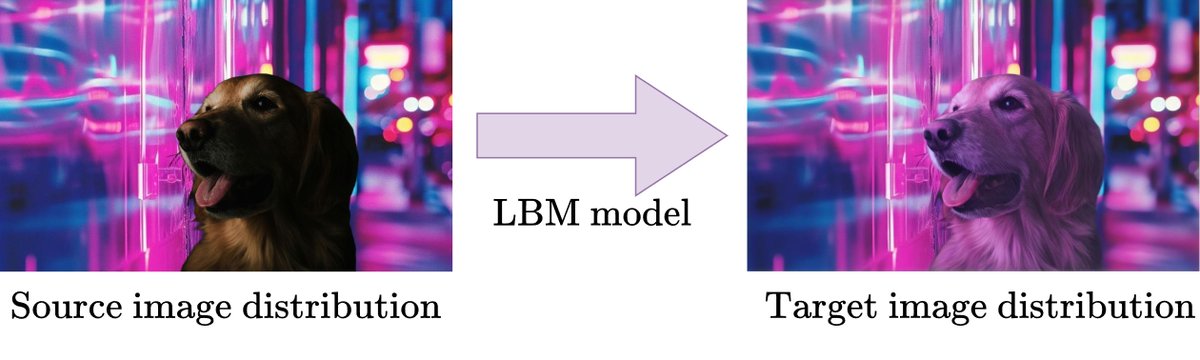
We’re thrilled to announce that the Jasper Research team’s latest paper on Latent Bridge Matching (LBM) was accepted to the prestigious IEEE/CVF International Conference on Computer Vision! Thank you @ICCVConference for the recognition, and congratulations to the team: @onurxtasar, Sanjeev Sreetharan, Benjamin Aubin, Gonzalo Quintana, @dh7net, and @CChadebec.
LBM is a technique for rapid, high-fidelity image-to-image translation. Learn more about how LBM is changing visual marketing for retailers. bit.ly/3ZWMEcI

3
5
1,295
Clément Chadebec retweeted

13 May 2025
Object Relighting with Latent Bridge Matching
Link to Hugging Face space below Link to Kijai's ComfyUI wrapper in first comment 👇
6
20
157
17,934
Clément Chadebec retweeted
13 May 2025
Proud to share the latest breakthrough from Jasper Research: Latent Bridge Matching (LBM) just got a major update!
Our team has released three new open-source models on Hugging Face—supporting depth, normals, and relighting—along with training code and a Gradio demo for object relighting.
This work continues our mission to advance controllable, high-quality AI image generation for enterprise marketing teams.
🔗 Explore the research, models, and demo: linkedin.com/feed/update/urn…
👏 Congrats to @CChadebec, Benjamin Aubin, @OnurXTasar, and @dh7net for pushing the field forward.
13 May 2025
📢 Latent Bridge Matching update! 📢
New @heyjasperai release 🚀
- 3 LBM models on @huggingface (relighting, depth, normals)
- LBM training code
Also see our @Gradio space for object relighting!
🤗 huggingface.co/jasperai/LBM_…
💻 github.com/gojasper/LBM
📗 arxiv.org/abs/2503.07535
2
5
14
1,865
Clément Chadebec retweeted

13 May 2025
Very proud of the team!
13 May 2025
📢 Latent Bridge Matching update! 📢
New @heyjasperai release 🚀
- 3 LBM models on @huggingface (relighting, depth, normals)
- LBM training code
Also see our @Gradio space for object relighting!
🤗 huggingface.co/jasperai/LBM_…
💻 github.com/gojasper/LBM
📗 arxiv.org/abs/2503.07535
1
3
371
13 May 2025
📢 Latent Bridge Matching update! 📢
New @heyjasperai release 🚀
- 3 LBM models on @huggingface (relighting, depth, normals)
- LBM training code
Also see our @Gradio space for object relighting!
🤗 huggingface.co/jasperai/LBM_…
💻 github.com/gojasper/LBM
📗 arxiv.org/abs/2503.07535
4
25
85
8,210
13 May 2025
Today, we release on @huggingface, the model for object relighting where the model should relight a foreground object so that it blends perfectly with a target background.
🤗Ckpt: huggingface.co/jasperai/LBM_…
🤗Demo: huggingface.co/spaces/jasper…
1
3
165
13 May 2025
We also release checkpoints for normal and depth estimation where the model should translate an input image into a normal or depth map.
🤗 Ckpt: huggingface.co/jasperai/LBM_…
🤗 Ckpt: huggingface.co/jasperai/LBM_…
1
4
173