
AI/ML | Java | Python | JS | SaaS | Startup | Engineering Leader | MCA | MBA - NMIMS
Joined July 2023
- Tweets 443
- Following 367
- Followers 87
- Likes 297
81 Photos and videos













Pinned Tweet

Apr 13
A Website Blocker Chrome Extension You Must Have : chromewebstore.google.com/se…
41
Dhananjay retweeted
Morning bathrobe rant: disengage from the syntax.
52
51
637
40,445
Dhananjay retweeted

Apr 28
NEW POST
Thoughtworks internal IT use a workflow for agentic programming called Structured-Prompt-Driven Development (SPDD). @WeiZhang595190 and Jessie Jie Xia describe how this works with a simple example plus details in a github project.
martinfowler.com/articles/st…
25
123
870
95,578

This is why OpenAI was created
Apr 27

Elon Musk turned down all shares when he left OpenAI because he believed nonprofits are not meant for self-enrichment.
"The reason I founded OpenAI was because I was concerned, based on my conversations with Larry Page, that he was not sufficiently concerned about the dangers of AI. At my birthday party, he, in front of a large group of people, called me a speciesist, for favoring humanity over computers. So after that, I was like, We got to have some counterbalance to Google, because Larry doesn't seem to care if humans make it or not.
So I thought, what's the opposite of Google? It would be an open source nonprofit, and that's where the word open, in OpenAI comes from. It means open source.
I provided all the money, recruited the key people, and taught them everything I know. I actually even got them to deal with Microsoft.
And for all that, I did not seek any financial reward whatsoever. The reason I actually took down the offer for shares is because, I mean, I felt like what are the shares, and why like nonprofits supposed to have shares? Nonprofits are not supposed to be self enrichment, so that's why I turned on the offer of shares."
— Elon Musk
4,221
16,485
85,856
21,941,535
Dhananjay retweeted

Apr 26
Dario demonstrating that he doesn't understand software engineering. The human side of what we do has always been the heart. I can empathize with *wanting* to never talk to an engineer ever again, but engineering becomes more important with better tools.

Anthropic CEO (Dario Amodei):
"Coding is going away first, then all of software engineering."
What do you think about this?
57
102
798
67,471
Apr 26
Sidecar pattern in microservices 👇
Think of it as a “companion” container that runs alongside your app and handles things your service shouldn’t worry about:
🔹 logging
🔹 security
🔹 networking (proxies like Envoy)
🔹 monitoring
6
Apr 25
Strategy to decompose a system into microservices:
- By Business Capability
- By Subdomain (DDD)
- By Business Process / Workflow
- By Bounded Context
- By UI / Frontend (Vertical Slicing)
- By Technical Function (Layer-based)
- By Data / Entity
5
Apr 25
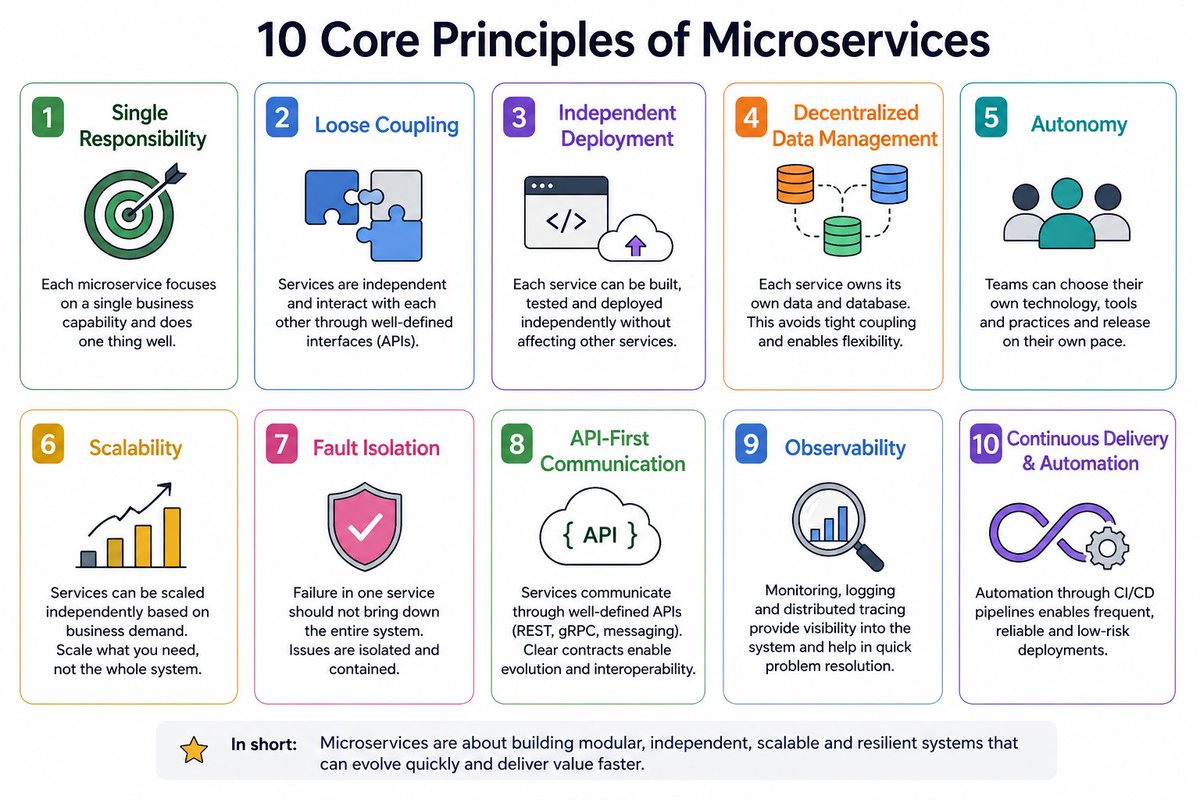
10 Core Principles of Microservices 🧵
1. Single Responsibility
2. Loose Coupling
3. Independent Deployment
4. Decentralized Data
5. Autonomy
6. Scalability
7. Fault Isolation
8. API-First
9. Observability
10. Continuous Delivery
#Microservices #SoftwareArchitecture #Tech
6

The hottest job for the next five years is going to be the agent operator.
They don't need to be an engineer. They can walk into marketing, legal, or life sciences research and actually make agents work for that function.
Required skills:
> MCPs
> CLIs
> Writing skills (the file kind)
> agents.md fluency
> Business acumen
None of this is in any CS curriculum today.
Soon, enterprises will be pressured to redesign their workflows for agents, not for people. And when that happens, agent operators will be in massive demand.
224
770
5,828
486,972
Dhananjay retweeted

Apr 24
Anthropic's Claude Ai Agents Team just Educated how to build production AI agents in under 30 mins.
For Free. From the engineers who built the stack.
CANCEL Your Weekend Plans, and Learn to Build AI Agents Today.
Bookmark it. Watch it. Build your first production agent this weekend.
$5,000/month. $7,000/month. $12,000/month.
People are building agents for clients and charging $$$ as Beginners. You're still stuck in the thinking about AI phase.
This video fixes that tonight.
Follow @codewithimanshu for more high-signal content that actually moves your AI engineering career forward.
↓
Ivan Nardini runs Developer Relations for AI at Google Cloud. He just gave away the entire production agent stack in 30 minutes.
This is the talk that separates people deploying AI agents that actually scale from people whose agents break the moment they leave localhost.
Here's everything inside.
I break down a production AI video like this every week. Follow @codewithimanshu.
↓
The 4-part agent stack that actually scales.
Most devs are duct-taping frameworks together and calling it an "AI agent."
Ivan lays out the real stack:
Agent Development Kit (ADK): open-source, code-first framework for building, evaluating, and deploying agents. Supports Claude models through Vertex AI directly.
Model Context Protocol (MCP): lets your agent talk to any tool or data source with one standard. Vertex AI Agent Engine: managed platform for deploying, monitoring, and scaling agents in production. No DevOps headaches.
Agent-to-Agent Protocol: open protocol so agents built on different frameworks can actually work together.
This is the stack replacing every hacky agent setup in production right now.
Full MCP Claude breakdowns drop weekly on @codewithimanshu.
↓
Building your first real agent.
Ivan builds a birthday planner agent live.
LLM Agent class. Name it. Define instructions. Pick the model.
He uses Claude 3.7 Sonnet. You could use Opus 4.7 for better reasoning.
Full agent built in minutes. Not weeks.
Watch the build once and you'll never structure an agent the wrong way again.
I post agent architectures people pay $500 courses to learn. @codewithimanshu.
↓
Multi-agent systems without the chaos.
Single agents are easy. Multi-agent systems are where 99% of builders fail.
Ivan extends the birthday planner by:
Adding a calendar service through MCP tools Creating an orchestrator agent to route requests between agents Handling state and context across agent handoffs
This is production multi-agent architecture. Clean. Scalable. Debuggable.
Most tutorials hand-wave this part. This one shows you every step.
Multi-agent orchestration content drops weekly on @codewithimanshu.
↓
Deployment without the DevOps nightmare.
This is where most AI projects die.
You build a cool agent locally. It works. You try to deploy it. Everything breaks.
Vertex AI Agent Engine fixes this:
Minimal code deployment Automatic monitoring of latency, CPU, and memory Built-in observability and logging No infrastructure setup needed
You provide config and requirements. The platform handles the rest.
This is how agents actually get to production.
Deployment guides for Claude agents post every week. @codewithimanshu.
↓
Agent-to-Agent Protocol: the future nobody's talking about.
Most people don't know this exists yet.
The A2A Protocol lets agents built in different frameworks communicate seamlessly.
Your Claude agent. My LangChain agent. Someone else's CrewAI agent.
All talking to each other. All solving parts of the same problem. All without custom integration code.
This is the infrastructure layer of the coming AI economy.
Getting in early on A2A Protocol is like getting in early on HTTP in 1995.
A2A deep dive coming soon. @codewithimanshu.
↓
30 minutes from the team shipping this in production.
You'll learn more from this than from 6 months of YouTube tutorials made by people who've never deployed an agent past localhost.
People who watch this understand production AI agents at the architect level.
People who skip it keep hacking together frameworks that break every time an API updates.
Save the video. Watch it tonight. Build a real agent this weekend.
Follow @codewithimanshu for more high-signal content that actually moves your AI engineering career forward.
49
440
2,365
223,879
Dhananjay retweeted

Apr 25
Karpathy didn't make a course.
He made THE course.
3 hours. Free.
Tokenization. Attention. Hallucinations. Tool use. RLHF. DeepSeek. AlphaGo.
Every behavior you've ever wondered about in an LLM - where it comes from, why it exists, how it was engineered.
The gap between engineers who understand this and engineers who don't isn't technical depth.
It's the ability to conceive of entirely different things.
Community note
This video was stolen from @karpathy's YouTube channel.
youtu.be/7xTGNNLPyMI?si…
73
940
7,330
627,938

Dhananjay retweeted

I will apply below 5 patterns to solve the problem.
1. Timeout — "Don't wait forever"
Imagine you call a friend and they don't pick up.
You don't keep the phone to your ear for 10 minutes — you hang up after 30 seconds.
That's a timeout.
In code:
Service A sets a rule — "if Service B doesn't respond within 3 seconds, I give up."
This frees the thread immediately instead of letting it hang.
The user gets a fast error instead of waiting 30 seconds for a slow one.
2. Circuit Breaker — "Stop knocking on a broken door"
Imagine a broken light switch.
You flip it 5 times, nothing happens.
You stop trying and use a torch.
After 10 minutes, you try the switch again just to check.
That's exactly how a circuit breaker works — three states:
Closed (normal):
everything works, requests pass through
Open (broken):
after 5 failures, stop calling Service B entirely. Return error instantly.
Half-open (testing):
after 10 seconds, allow 1 request through. If it works, go back to Closed. If not, stay Open.
The magic: when the circuit is Open, Service A doesn't even try to call Service B. No waiting. No thread blocked. Instant response.
3. Bulkhead — "Don't put all eggs in one basket"
A ship has separate compartments (bulkheads).
If one floods, the others stay dry. Ship doesn't sink.
In code:
Service A has separate thread pools for each downstream service.
10 threads for Service B. 10 threads for Service C.
If Service B goes down and all 10 B-threads get stuck — the 10 C-threads are completely unaffected.
Service C still works normally.
Without bulkhead: Service B's failure eats ALL threads in Service A. Everything breaks.
4. Retry — "Try again, but smartly"
Sometimes Service B just had a hiccup — network blip, brief overload, a restart.
The request would succeed if you tried one more time.
Retry with exponential backoff:
try immediately → wait 500ms → try again → wait 1s → try again.
If all 3 fail, give up.
The key warning:
only retry idempotent operations.
Getting a user's profile? Retry fine.
Creating a payment?
Never retry — you might charge twice.
5. Fallback — "Have a Plan B"
When Service B is definitely down, don't crash. Return something useful instead.
Options in order of preference:
Return the last cached response
Return a default/empty response
Return a degraded response (fewer fields)
Example: a product page can still show without live stock data.
Show "Check availability in store" instead of crashing.
The Golden Rule:
these patterns work together, not separately.
The correct order to apply them is Retry → CircuitBreaker → Bulkhead → Timeout → Fallback.
Resilience4j in Spring Boot applies them in exactly this order when you stack the annotations.
Please follow me if you like my efforts:
Thank you in advance
1
1
4
645
Apr 18
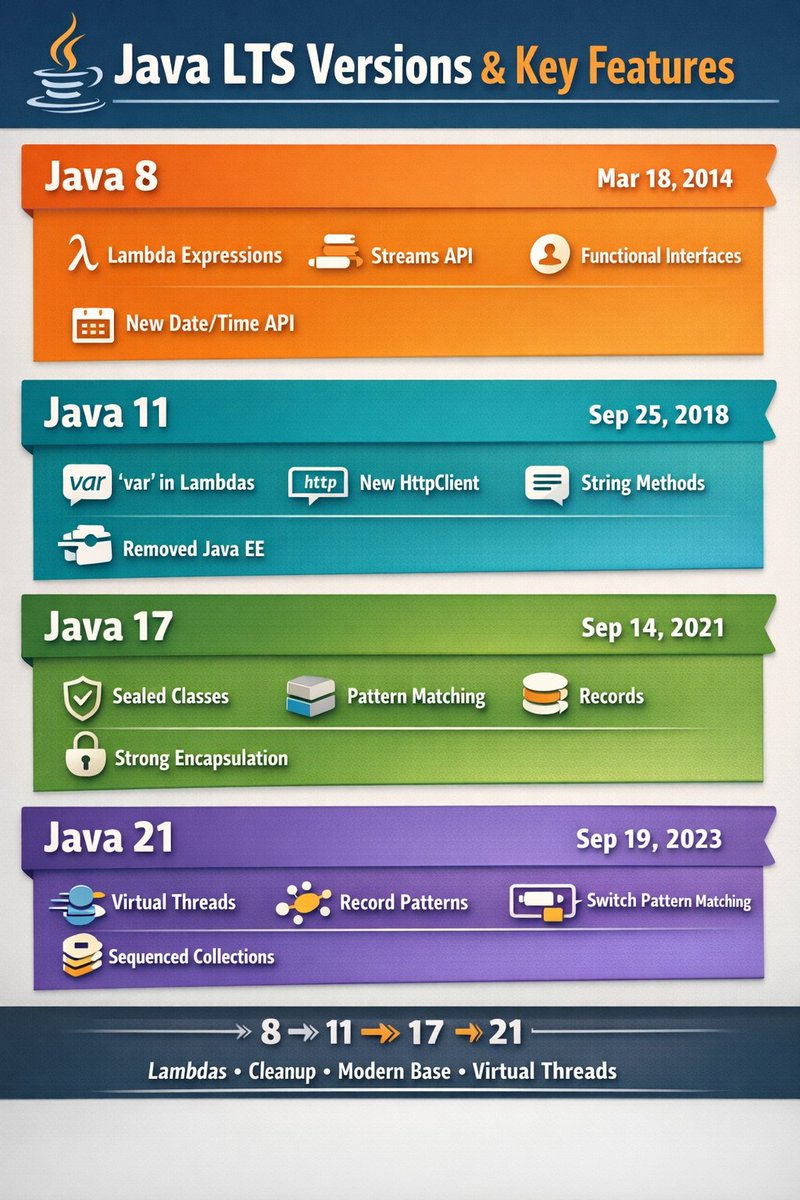
Journey of Java LTS:
8 → 11 → 17 → 21
8 → Lambdas
11 → Cleanup
17 → Stable modern base
21 → Virtual threads
32
Apr 17
Despite their complexity and overhead, the biggest advantage of microservices - if implemented correctly -is their ability to solve organizational and system scalability issues in a very effective way.
8
Apr 17
One thing to note for start-ups:
Microservices are not the sliver bullet. Building a simple three-tier architecture with the help of a small team is a much better choice than investing in building a complex system prematurely.
Focus on customer's problem, not scaling.
10
Dhananjay retweeted

Apr 16
The reading list that taught me how to think about agentic architecture.
Bookmark this.
1. Brewer's CAP Theorem (2000) — trade-off thinking
2. Netflix Hystrix docs — circuit breaker pattern
3. Martin Fowler: Saga Pattern — distributed rollback
4. The Twelve-Factor App — stateless service design
5. AWS Well-Architected Framework — blast radius thinking
6. "Thinking in Systems" — Donella Meadows
7. Designing Data-Intensive Applications — Kleppmann
8. Google SRE Book Ch.13 — cascading failures
9. OWASP LLM Top 10 (2025) — agent attack surfaces
10. Anthropic: Building Effective Agents (2024)
11. LangGraph docs — stateful agent patterns
12. Microsoft AutoGen paper — multi-agent orchestration
13. Gartner: Agentic AI Hype Cycle (2025)
14. EU AI Act Article 14 — human oversight requirements
Classic distributed systems stuff.
Applied to the next layer of the stack.
Follow for annotated breakdowns → @asmah2107
38
330
15,660


Dhananjay retweeted

Apr 14
With AIs “distance” is important. One AI that writes tests, and another that makes them pass, sets the two at odds with each other and prevents either from cheating. This is very much like the separation of powers in a democratic constitution.
Another form of distance is semantic. I have the AI create a parser that parses gherkin into an intermediate representation file. Then I have it write a generator that reads the IR file and produces executable test code.
That semantic distance interposed so many intermediate goals that the AI cannot reach through them in order to cheat. Or, to say that differently, the intermediate goals become higher priority than the overall goal of making the test pass, making reinforcing the test higher priority than cheating to get green.
23
18
330
20,035