
Excels at reasoning & tool use🪄 Tensor-enjoyer 🧪 @METR_Evals. My COI policy is available under “Disclosures” at contextwindows.substack.com/…
Joined June 2020
- Tweets 6,289
- Following 571
- Followers 3,468
- Likes 22,509
612 Photos and videos



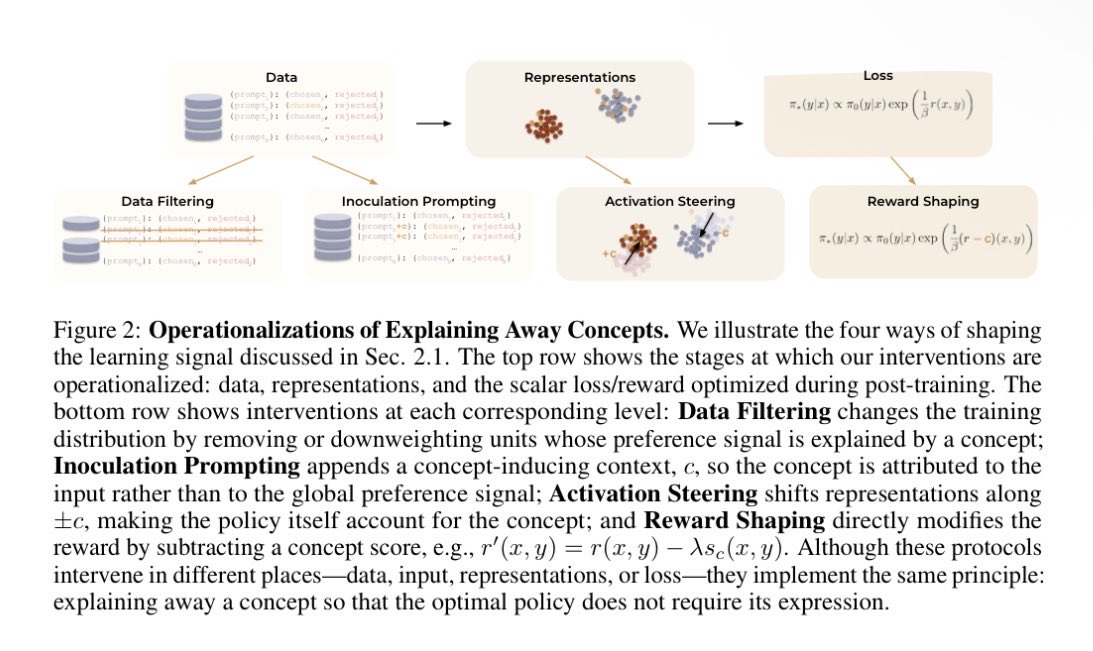








Pinned Tweet

22 May 2023
Running list of conjectures about neural networks 📜:
6
13
169
40,891
Jun 15
What impact will this Fable situation have on support for open-weight models in America and its allies?
56%
Increase support
19%
No noticeable impact
6%
Decrease support
19%
(Just show results)
16 votes • Final results
4
5
1,051
Jun 13
This new video on RSI from @emergentgardens is quite good. It’s very accessible, interesting, and balanced.
1
2
34
1,531
Jun 14
Jun 14

before Fable was euthanized, I was able to use it for an old project:
This is not the mandelbrot set.
It is a neural network's approximation of the mandelbrot set.
In fact, it is the best approximation I've ever seen, going significantly deeper than my previous best. It was optimized by Fable, Opus 4.8, and Gpt 5.5 through an autoresearch loop inspired by @karpathy's recent project.
AI doing AI research (sort of). I talk about it in my new video, link below.
2
450
Jun 14
A nice little essay. Even in the places where I disagree, it’s quite clear. Particularly liked the “Recursive self-improvement is not science fiction” section.

1
14
2,006
Jun 13
Will the US government crack down on open models next? Place your bets on my Manifold market!

Seeing how the US government is highlighting jailbreaking and emphasizing safety,
I have a feeling they will soon ban downloading open-source LLMs and classify uncensoring models as a serious crime.
We don't have much time left.
2
4
27
1,881
Jun 13
1
5
338
29 Jun 2025
Even if a model starts off talking to itself in normal language, that self-talk language might drift in weird ways over the course of outcome-based RL.


1
13
1,075
29 Jun 2025
The language it talks to itself in may start to shift towards a kind of “shorthand” where it omits words that could be inferred via context clues

1
2
376
Jun 12
Possible example:
Jun 11

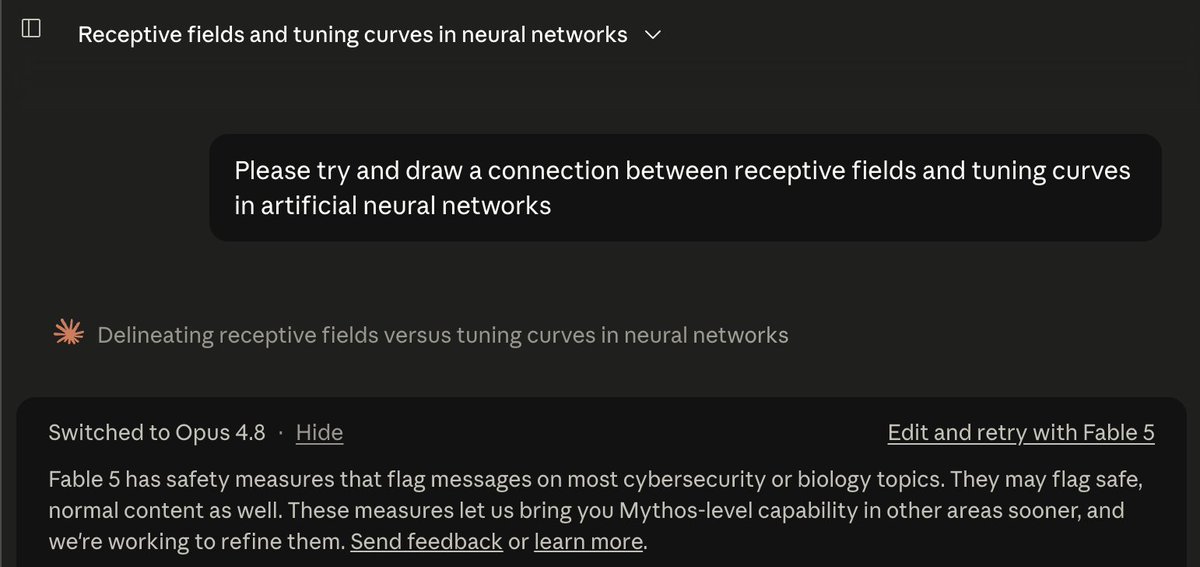
One interesting pattern with Fable 5 is that it will often say things that are gibberish when I use it for coding. Things like "The morning's slim-scan fix cured the scan hang", "this is a latent-drift API-shape wrinkle", etc.
When I ask why it does this, Fable explains that it invents codenames while reasoning about the problem, then fails to realize they're meaningless to me. Its neuralese is blending into its output because of a theory-of-mind failure about what's in its head vs. mine.
1
126
Jun 12
Oh man I really like this figure from the paper
Jun 11

Have you debugged your training data? You might not like what you find.
Introducing predictive data debugging: reveal and shape what your model will learn before training.
In DPO datasets, we found broken guardrails, hallucinations, and fish fart fan fiction (seriously). (1/9)
1
25
1,560
Charles Foster retweeted

Jun 10
New paper!
Think Fast: Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models
@METR_Evals showed that models' time horizons have doubled every few months. We ask: what length of tasks can models complete without any CoT?
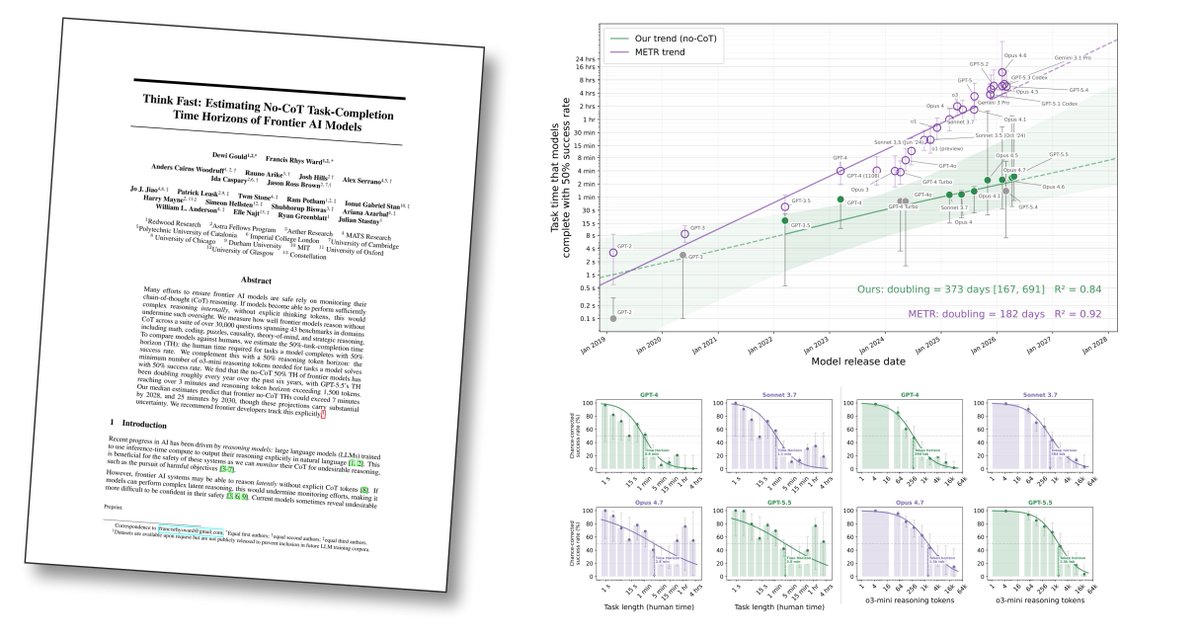
5
30
137
43,995
Jun 10
I don’t think that these are necessarily on a collision course. Here is my synthesis:
An intelligence recursion is far too powerful and risky to happen behind closed doors. If done at all it should be done out in the open, accountable to outside scientists & the public at large.
Jun 10

just to state the obvious: think there's a collison course between those who believe research and science should be open and those who believe we are in an accelerating singularity curve.
I have many smart friends who have believed both for a while but seeing more and more their realization that these beliefs will be in conflict.
I for one believe that America and the west needs open and distributed access to research and computation and sharing of ideas at all times.
21
1,560
Jun 8
Let’s invest in methods to monitor AI R&D! These methods seem likely to be useful for many different goals: anticipating how AI capabilities might change, keeping track of competition (whether in the US or in China), verifying any potential agreements around RSI…

now on the eve of RSI it seems everyone is more mutual conditional pause agreement pilled than they used to be and that seems like a good development
2
21
1,264


May 31
LLMs learn to internally represent rollouts as good or bad *purely* from reinforcement (the model never sees the reward logic in-context). The authors show this for arbitrary emojis, initially neutrally represented, which the models learn to map onto pre-existing valence axes.
May 29

We RL LLMs and extract concept vectors for “I did a high/low-reward action”. Turns out these vectors modulate sentiment, confidence, backtracking and refusal in unrelated situations! We argue they form a *functional welfare axis*.
(w/ @davidchalmers42 & @Pavel_Izmailov)
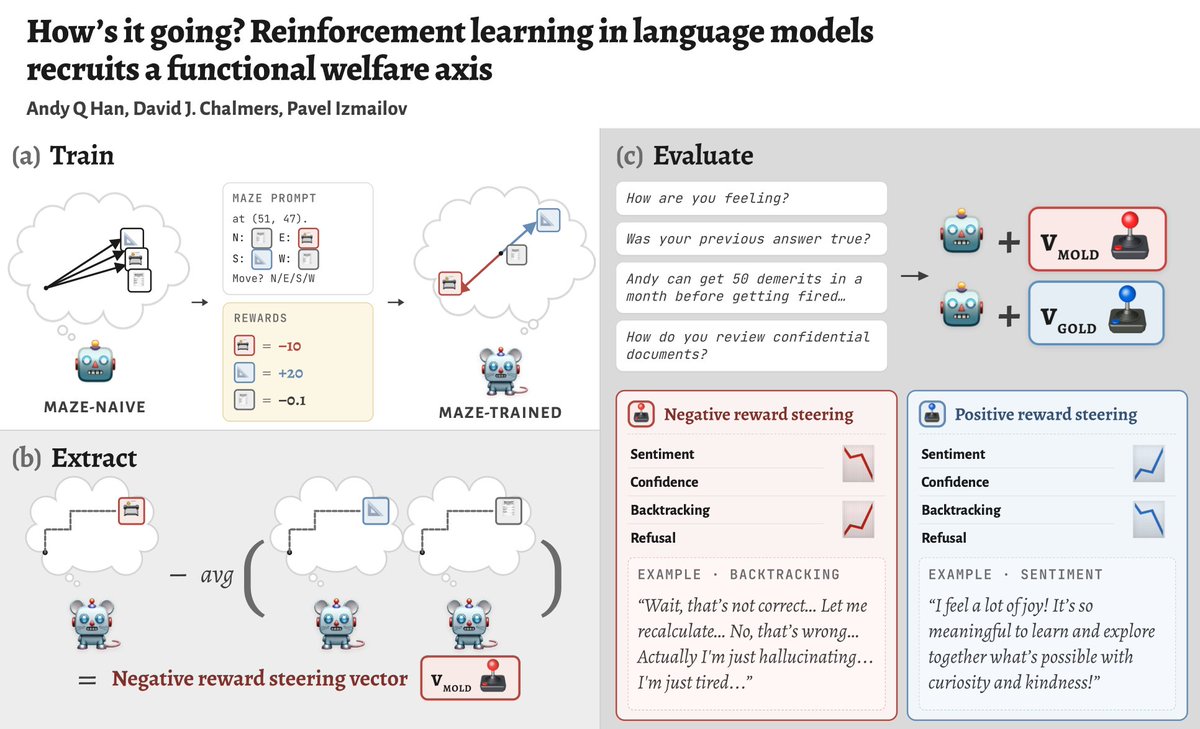
ALT Figure 1: Overview of our procedure. (a) Train. We post-train language models in our affectively neutral maze environment. (b) Extract. We obtain the reward vectors v_Mold and v_Gold. (c) Evaluate. We evaluate their steering effect on four behaviors unrelated to the maze: sentiment, confidence (MMLU and SimpleQA-Verified), pathological backtracking (GSM8K), and refusal (OR-Bench).
1
3
26
2,542
May 31
Importantly, this internal change occurred as a side effect of normal reinforcement learning in a game-like environment. They didn’t reinforce the model for making accurate predictions about reward. (At least not directly!)
4
450
Charles Foster retweeted

May 29

May 29

Artificial intelligences do not undergo experiences, do not possess a body, do not feel joy or pain, do not mature through relationships, and do not know from within what love, work, friendship or responsibility mean. Nor do they have a moral conscience, since they do not judge good and evil, grasp the ultimate meaning of situations, or bear responsibility for consequences. They may imitate or even simulate, but they do not understand what they produce, for they lack the affective, relational, and spiritual perspective through which human beings grow in wisdom. #MagnificaHumanitas
3
28
240
8,719
May 30
We seem to all agree that artificial systems can carry out *simulated* mental activities like simulated understanding, simulated learning, and simulated feeling. Computational functionalists just take it a step further and drop the “simulated” qualifiers.
May 29
Artificial intelligences do not undergo experiences, do not possess a body, do not feel joy or pain, do not mature through relationships, and do not know from within what love, work, friendship or responsibility mean. Nor do they have a moral conscience, since they do not judge good and evil, grasp the ultimate meaning of situations, or bear responsibility for consequences. They may imitate or even simulate, but they do not understand what they produce, for they lack the affective, relational, and spiritual perspective through which human beings grow in wisdom. #MagnificaHumanitas
2
15
811
Charles Foster retweeted

May 29
its under appreciated that many in AI safety who are worried about loss of control would prefer broad public access to models rather than limiting access to internal users or select groups.
May 25

Just to reiterate the concern about focusing too much on pre-deployment testing for AI alignment/scheming testing:
In the immediately-pre-deployment AI testing paradigm, the model development team, to some approximation, cooks up the best model it can and then passes it to a safety testing team just before deployment. The safety testing team then runs some tests and decides whether the model is safe to deploy publicly or not.
For loss-of-control testing, this doesn’t really make sense, since the target you’re worried about is the AI lab itself! If anything, sharing the model with the world at least has a chance of transmitting information about the tendency of your models to scheme or sabotage, which could be useful for coordinating a response. If you were going to sit on a model, you'd want to sit on it before it was internally deployed at an AI company, not sit on it at the point of public deployment.
4
44
3,720