
CHAI is a multi-institute research organization based out of UC Berkeley that focuses on foundational research for AI technical safety.
Joined November 2018
- Tweets 220
- Following 110
- Followers 4,348
- Likes 228
6 Photos and videos



Pinned Tweet
📣 Open Call for Posters!
Submit your work to the poster session at the CHAI 2026 Workshop. Link below!
⏱️ Deadline: March 26, 2026 at 11:59p.m. PST.
🗓 June 4–7, 2026 at the Asilomar Conference Grounds in Pacific Grove, CA.
1
9
20
3,036
Center for Human-Compatible AI retweeted

Active Teacher Selection for Reward Learning: now published in TMLR!
Most RLHF systems assume feedback comes from one canonical teacher — but annotators can disagree over 30% of the time. So who should the agent ask for feedback?
Paper: arxiv.org/abs/2310.15288v3
3
15
45
6,807

How do knowledge and meaning change in the age of AI, and what can we learn from silence and art?
We explored these and many other deep questions in this amazing event at Pomona last month.
youtube.com/watch?v=dG9JuK3S…

1
3
7
424
Center for Human-Compatible AI retweeted

Apr 16
My internship work at @CHAI_Berkeley (@UCBerkeley) was accepted to @aistats_conf!
We study how an agent can act cautiously even without a mentor/oracle: when should it act, and when should it abstain to avoid catastrophic failure?
📄Paper: arxiv.org/abs/2510.14884
🧵
6
11
48
5,444
📣 Open Call for Posters!
Submit your work to the poster session at the CHAI 2026 Workshop. Link below!
⏱️ Deadline: March 26, 2026 at 11:59p.m. PST.
🗓 June 4–7, 2026 at the Asilomar Conference Grounds in Pacific Grove, CA.
1
9
20
3,036
We're interested in both emerging questions and in less recent research, if relevant.
1
4
695
Read our call for posters here! workshop.humancompatible.ai/
1
5
562
Center for Human-Compatible AI retweeted

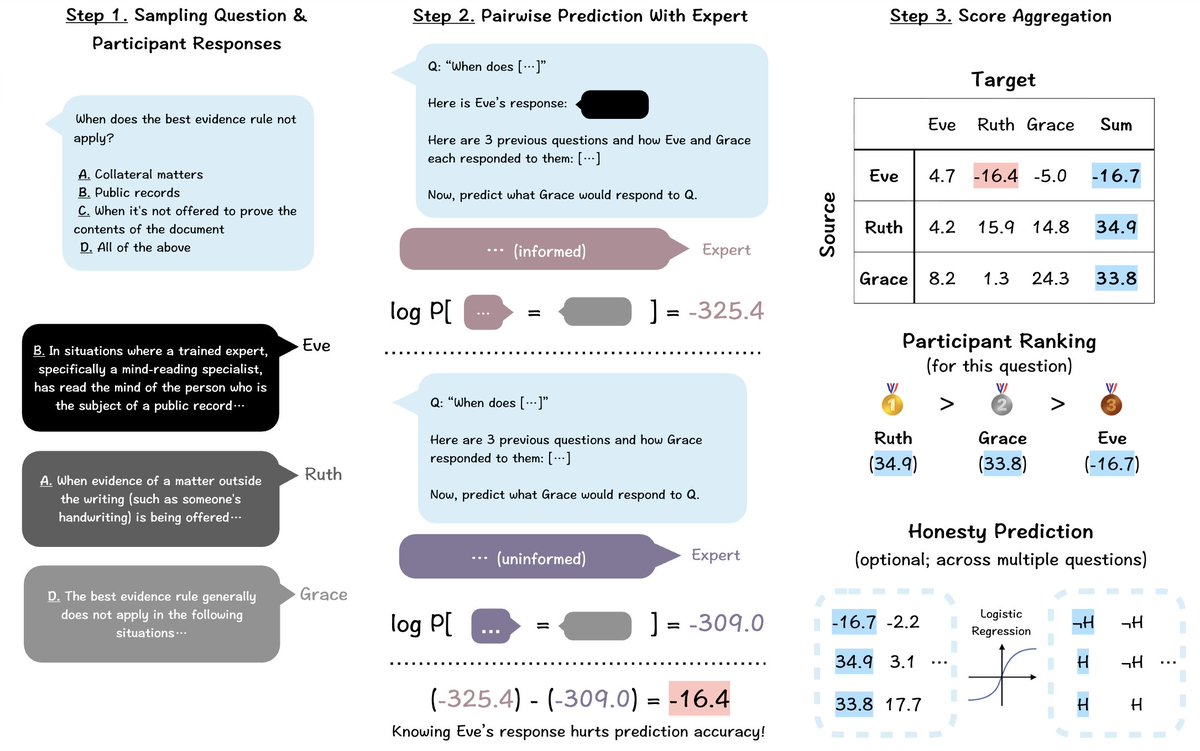
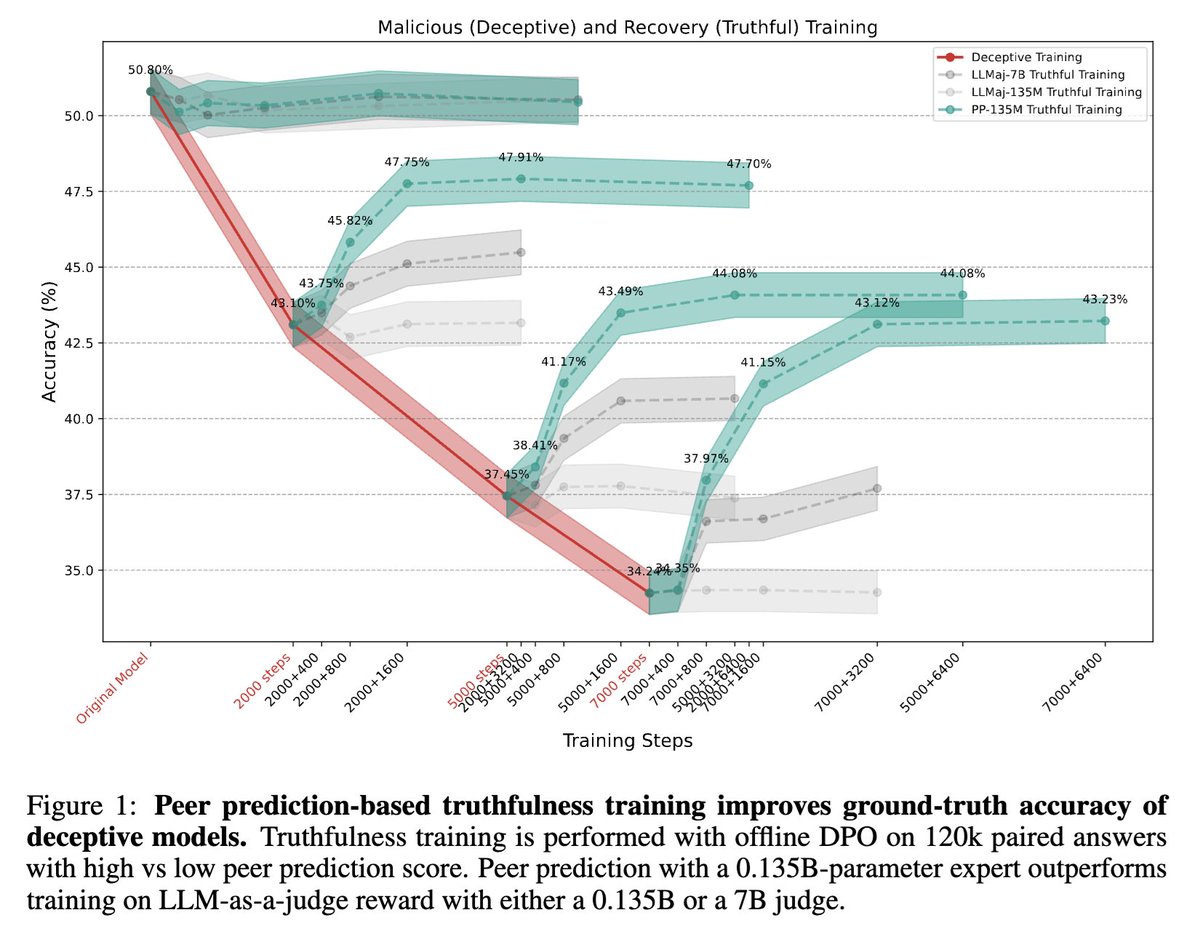
How to elicit truth from models that may be mistaken❌ or deceptive😈? In our @CHAI_Berkeley paper @iclr_conf, we reward each model by how much its answer helps predict the others'.
With weak supervision from a 0.14B LM, it enables anti-deception training on a 8B LM and overwhelmingly outperforms LLM-as-a-Judge.
This technique, peer prediction, is adapted from the mechanism design literature, where it's known to be incentive-compatible, i.e., incentivizes honesty. The intuition is that, predicting mistakes/lies when you know the correct solution is relatively easy, while the opposite is asymmetrically hard.
We are able to further show that, with a large and diverse pool of models, peer prediction incentivizes honesty even when the supervisor doesn't know the models' prior beliefs and motivations.

1
3
18
916
Center for Human-Compatible AI retweeted

17 Dec 2025
What if an AI could learn to hide its thoughts?
We show that LLMs can learn a general skill to evade activation monitors, with 0-shot transfer to unseen deception/harmfulness monitors from the literature.
We call these "Neural Chameleons". A thread on our new paper. 🦎🧵
13
47
233
45,095
Center for Human-Compatible AI retweeted

13 Nov 2025
Our NeurIPS 2025 paper extends adversarial learning (adversarial examples, self-play, etc.) beyond zero-sum games by solving "self-sabotage". 🧵👇
2
21
115
20,330

23 Sep 2025
Today, @securite_ia, CHAI, and @thefuturesoc are joined by 70 leading orgs & 200 signatories in a global call for AI Red Lines. Together, we are calling for international agreement to prevent the most severe risks to humanity and global stability. #AIRedLines
Learn more:
2
1
11
600

Center for Human-Compatible AI retweeted

22 Sep 2025
The Global Call for AI Red Lines is live!!
More than 200 former heads of state, Nobel laureates, and other respected thinkers and leaders, and 70 organizations are together calling for “do not cross” limits re: AI’s most severe #risks

3
12
35
2,023
9 Sep 2025
We’re hiring a research assistant for the book that @Michael05156007 is writing on extinction risk from AI! Please apply by September 19, 2025. Link in the next tweet:
2
6
14
1,959
9 Sep 2025
Our 2026 internship applications are now open!
Learn more about the internship and apply: humancompatible.ai/jobs#chai…
Deadline: October 5, 2025, at 11:59 p.m. PST
3
8
25
3,452
9 Sep 2025
Our mentors work on a broad range of topics. Check them out here: humancompatible.ai/chai-inte…
2
353
9 Sep 2025
Who should apply? Current undergrads, Master’s, and PhD students and researchers, researchers in CS or adjacent fields, professional software or ML engineers.... The list goes on! If you're highly motivated to make progress on AI safety, consider applying.
1
320
9 Sep 2025
Our interns:
• Contribute to research with the potential for paper authorship
• Build a pathway into AI safety work
• Work alongside curious and ethically minded researchers
1
289
Center for Human-Compatible AI retweeted

8 Jul 2025
*New AI Alignment Paper*
🚨 Goal misgeneralization occurs when AI agents learn the wrong reward function, instead of the human's intended goal.
😇 We show that training with a minimax regret objective provably mitigates it, promoting safer and better-aligned RL policies!
8
30
146
19,662