
Curating all things AI.
Joined March 2026
- Tweets 58
- Following 35
- Followers 57
- Likes 103
12 Photos and videos






16h
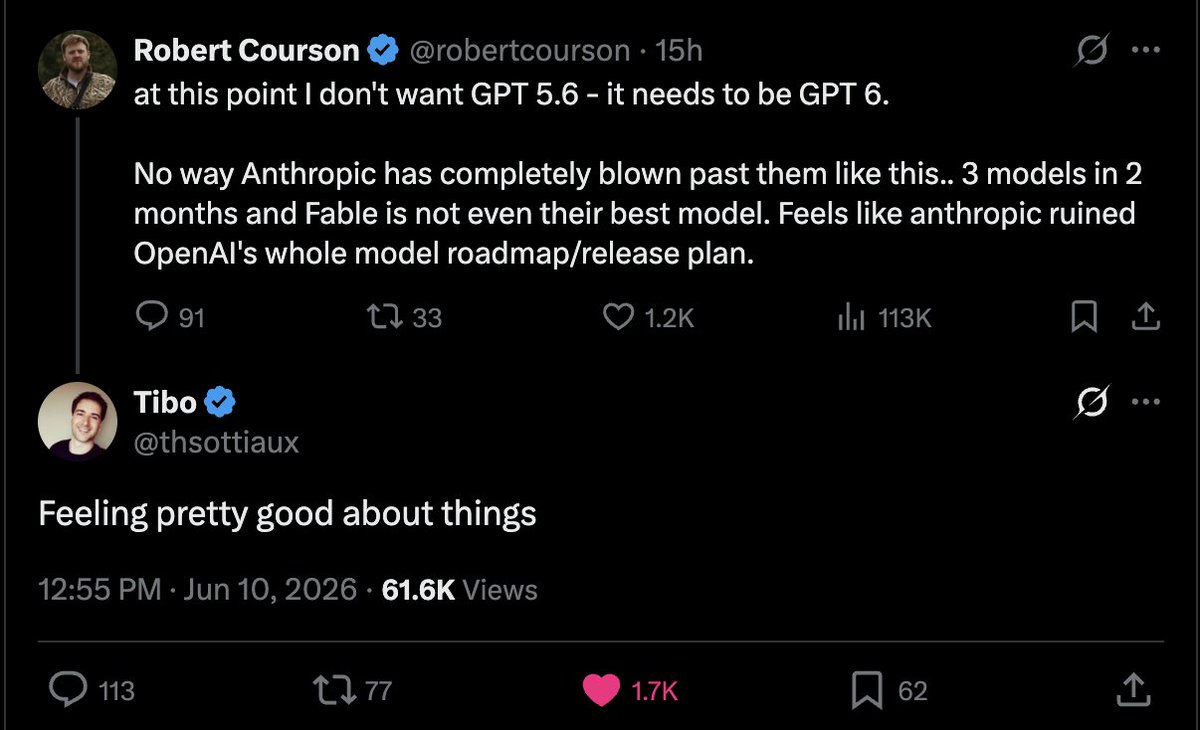
Some coverage on the crazy Fable saga.

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
59
Jun 11
Reading this, I am reminded about @bgurley’s take of Dario’s *Machines of Loving Grace* essay on @theallinpod.
Jun 10

Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: darioamodei.com/post/policy-…
178
Calathea retweeted

Jun 10
If you started a new project with agentic coding over the past 1–2 months using previous models such as GPT-5.5 or Claude Opus 4.8, chances are the next best course of action you can take right now is to rewrite your code.
Hear me out.
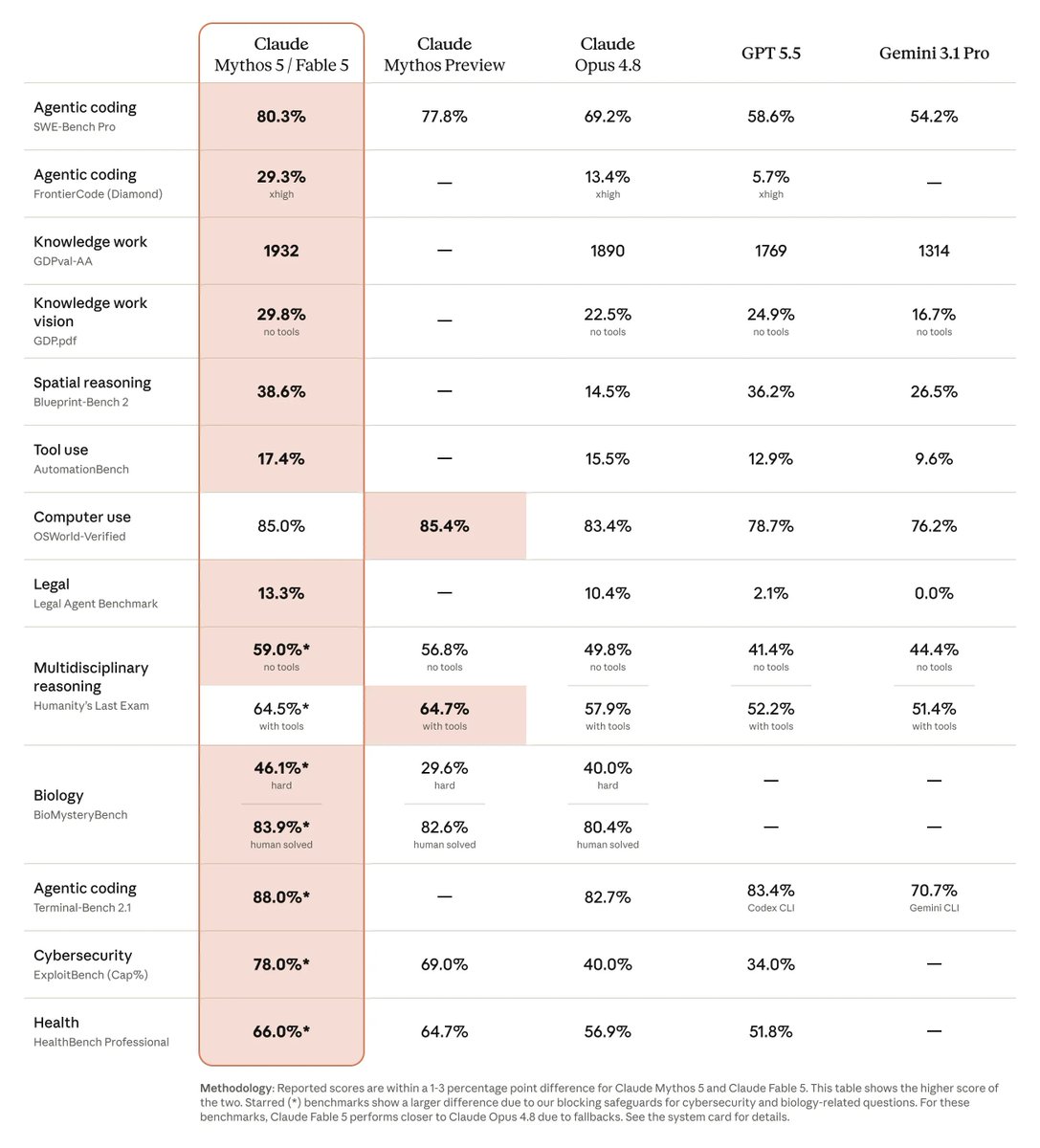
Since Claude Fable 5 launched, we are all quickly realising that Fable looks like a completely new tier of coding model, not just an incremental upgrade.
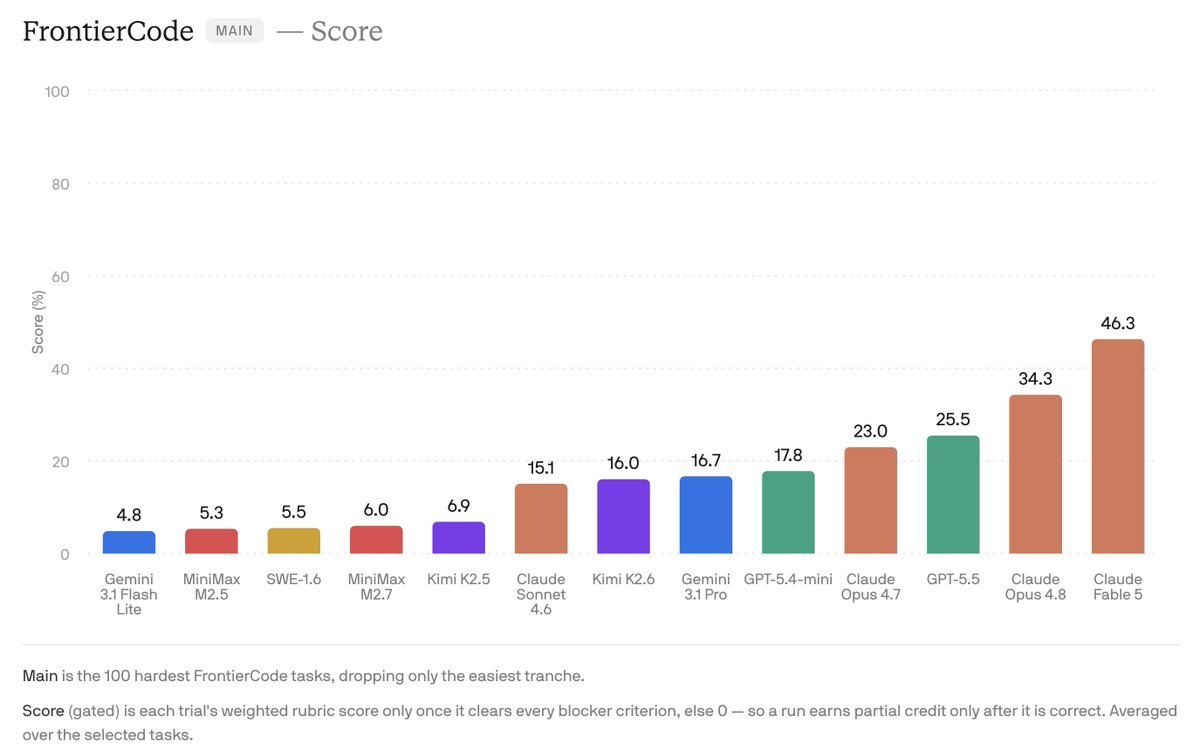
On Cognition FrontierCode Main, a benchmark designed to test whether code is actually good enough to merge, Fable 5 scores 46.3, ahead of Claude Opus 4.8 at 34.3 and GPT-5.5 at 25.5. That is roughly 35% above the previous Claude frontier baseline. (*Refer to the benchmark graph below.)
Here is why that matters for your existing project: given how much stronger the coding model is, previous code and prompts are no longer neutral context. They become baggage, old assumptions that anchor Fable to bad patterns and weak abstractions. Some of that code only worked because the previous model kept patching around its own limits.
This radically changes the economics of technical debt from both directions at once. Holding on to old agentic code just got more expensive, because that code can actively drag a stronger model down. Paying the debt off also got dramatically easier, because the stronger model can now rewrite the weak parts directly.
The old rule was to avoid rewrites unless absolutely necessary, because rewrites were slow, expensive, and risky. That rule was built for a world where rewrites took months.
Stripe is the clearest sign that this world is ending. During early testing, Anthropic reported that Fable 5 “compressed months of engineering into days.” In a 50-million-line Ruby codebase, it performed a codebase-wide migration in a day that would otherwise have taken a whole team over two months by hand.
Source: anthropic.com/news/claude-fa…
If Fable can make migrations dramatically easier on 50 million lines of code, then on a 1–2-month-old agentic codebase, it becomes rational to rebuild before the bad assumptions harden.
I have been vibe coding for almost a year, and spent the past month coding out @CalatheaAI , an AI curation system for myself. Under the old rules, rewriting after a month would look premature. With Fable, I think waiting is the bigger mistake the cost of rewriting has fallen that much, the opportunity cost has already flipped. Now, the bigger risk is not rewriting too early. The bigger risk is letting brittle crawler assumptions, weak freshness checks, and patched source logic harden into the foundation.
One more thing. Given that Fable is out of the bag, the rest of the field will catch up. Open-source models will get sharply better through distillation, and future paid models will be radically more powerful still. Sooner or later, those capabilities will be pointed at all the agentic slop we have accumulated over the past year and a half since vibe coding became a thing. The vulnerabilities a weaker model wrote, a stronger model can find.
So going forward, revisiting previous agentic code with Fable or an equivalent model is not just paying down "technical debt". It may become a security imperative, even a moral one, especially if you are building a product with actual customer data or finances.
We have been curating all things AI daily, but today, @CalatheaAI is hunkering down and rebuilding with Fable.
I think most of us should do that too.
2
1
5
1,556
Jun 10
Tried Claude Fable 5 with this approach and it works well.
The model seems better when you stop over-prescribing the steps. Give it the objective, define what done looks like, add verification criteria, then let it find the path.
A lot of old Claude.md files may now be too restrictive.
Jun 9

We've reset usage limits across our products!
For those just starting to test Fable, here's four tips for using it more effectively:
1. Give it bigger, more ambitious tasks than what previous models could handle.
2. Use xhigh/high effort as your default for best performance, med for faster interactive sessions.
3. Rework your skills and CLAUDE.mds. Instructions written for prior models anchor Fable to stale patterns, let it use its own judgment first.
4. Move from providing tasks to providing objectives. Describe what done looks like and how to verify it, then let Fable find the path (/loop and /goal are built for this)
1
101
Jun 9
It's here.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
1
42
Jun 9
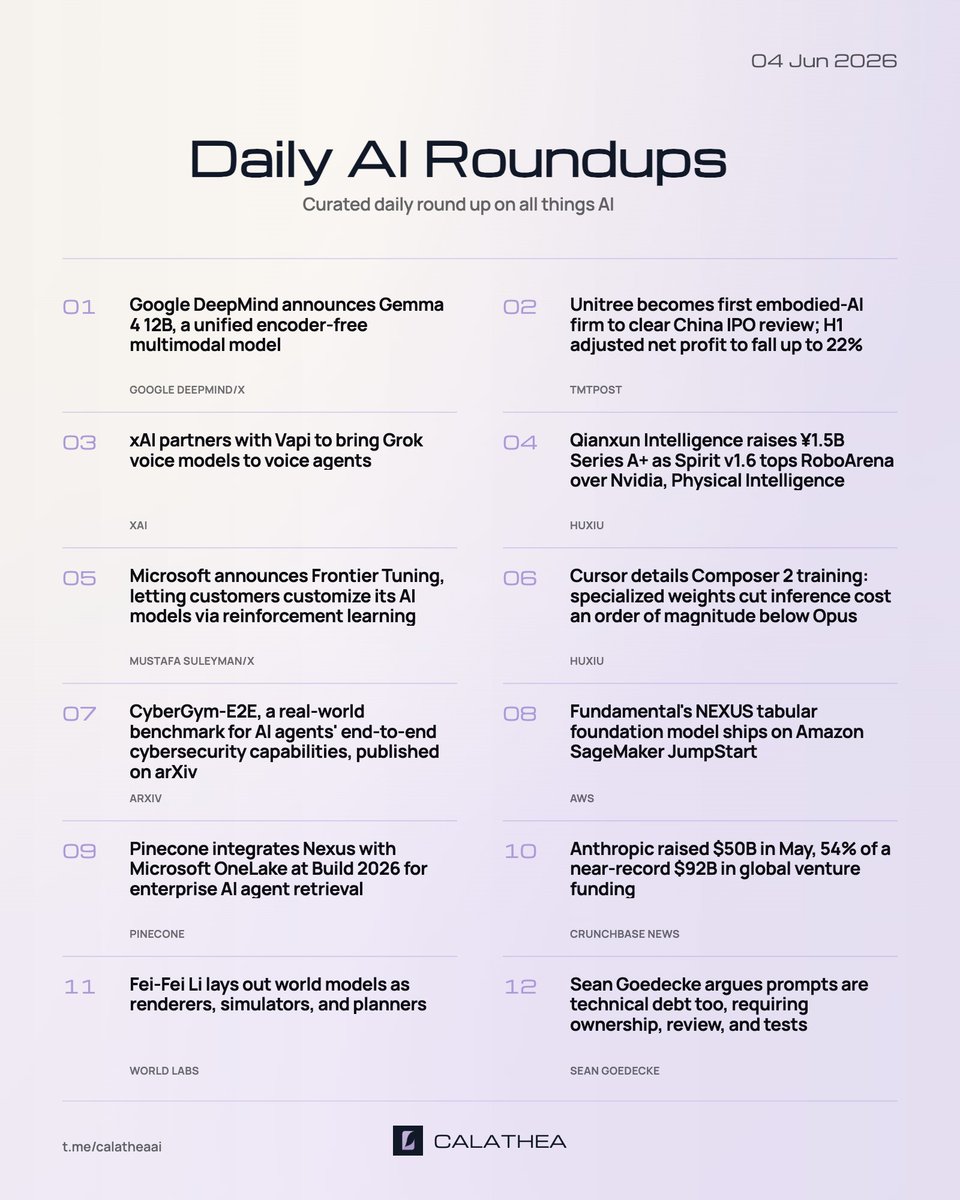
Daily AI Roundups | 09 Jun 2026
Anthropic’s Claude Fable is the top watch today, with OpenAI’s structure, ChinaRxiv’s GPT-5.5 deployment, FrontierCode, and AI research also moving.
1
1
149
Jun 9
Links continued:
7. arxiv.org/abs/2606.09204
8. arxiv.org/abs/2606.09735
9. blog.google/innovation-and-a…
1
1
17
Jun 9
Want this every day?
Follow Calathea on Telegram for your daily fix on all things AI. We promise curated headlines, quick context, and only the links that matter.
Join here: t.me/calatheaai
1
40
Jun 9
Claude Code just added nested subagents
Anthropic’s Boris Cherny says Claude Code can now let agents launch other agents, with an initial nesting depth capped at 5.
The goal is context management: instead of forcing one agent to carry the whole task, child agents can handle isolated workstreams in their own context.
Worth testing today if you use Claude Code for agentic coding workflows.
Jun 9

Just landed nested subagent support in Claude Code
Starting to experiment more with agents kicking off agents as a way to better manage context. Capped at depth=5 to start, going out in today’s release.
Lmk what you think!
1
111
Jun 8
Giving massive Game Master vibes, but honestly?
We are totally here for it 😉 Would be interested to see what kind of work would be classified as “impressive” or “incredibly useful”.
Jun 7

I have a new kind of big button that I can press for Codex. Over the next 100 days, we will select one person per day who does impressive or incredibly useful work with Codex and give them 10X usage limits for a month to see what they can do with it.
First one tomorrow.
1
52
Jun 9
Interesting that the first Codex 10x pick went to an existing OpenAI partner.
x.com/thsottiaux/status/2064…
Jun 9
First one is @skirano. Enjoy the 10X and keep building magic. Who's next?
x.com/skirano/status/2062942…
48
Jun 9
Sharing this gem again in case the people at the back missed it: MIT Missing Semester is still one of the best resources for anyone starting out with coding with AI.
Not because it teaches you how to prompt better. Because it teaches you the layer that prompts don’t replace.
Shell teaches you how programs talk to each other: arguments, streams, env vars, return codes, signals, pipes. That matters when your AI agent is running commands, reading stdout, failing on paths, missing env vars, or returning a non-zero exit code.
Debugging teaches you what to do after the model gives you 500 lines and something breaks: read logs, inspect stack traces, use verbose flags, isolate the failure, figure out whether the code is wrong or the environment is wrong.
Git gives you the safety rail: diffs, branches, commits, rollback, history. Code quality tools give you the verification layer: formatters, linters, tests, type checkers, pre-commit hooks, CI.
That’s why Missing Semester aged so well. AI made code generation easier, but it made the surrounding skills more important. Run the code, inspect the failure, track the diff, test the change, package the environment, ship the artifact.
If you’re learning to vibe code, don’t just learn prompts. Learn the system the code has to survive in.
missing.csail.mit.edu/
1
1
71
Jun 8
Daily AI Roundups | 08 Jun 2026
10 AI stories worth catching up on today, covering agent security, autonomous coding loops, AI Gateway infra, privacy leakage, enterprise Copilot, and agent sabotage detection.
1
1
60
Jun 8
Links continued:
8. arxiv.org/abs/2606.07054
9. x.com/huggingface/status/206…
10. arxiv.org/abs/2511.02748
Jun 7

Gemma 4 MTP just got officially merged into llama.cpp
This means you can use Gemma 4 QAT MTP for a lightweight super fast setup. Excited to see what the community builds with it
github.com/ggml-org/llama.cp…
1
1
32
Jun 8
Want this every day?
Follow Calathea on Telegram for your daily fix on all things AI. We promise curated headlines, quick context, and only the links that matter.
Join here: t.me/calatheaai
1
62
Jun 8
/loop used to mean Ralph-style retry loops.
Now it’s starting to mean continuous orchestration via cron jobs: agents supervising agents, spawning threads, checking work, recovering state, and looping until verified.
Basically, AI systems building themselves. Great read.

2
257