
Building the memory layer for the hyper-agent generation. Governed shared memory for AI agent fleets. Open source and memclaw.net
Joined September 2025
- Tweets 104
- Following 670
- Followers 865
- Likes 142
14 Photos and videos




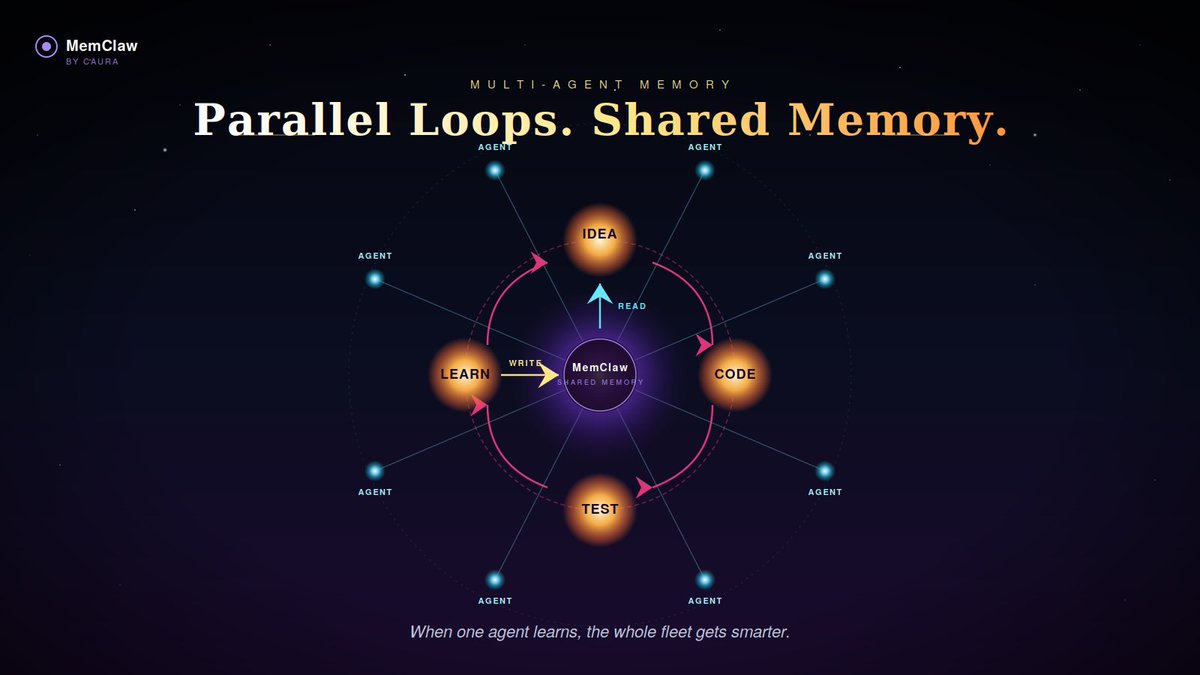







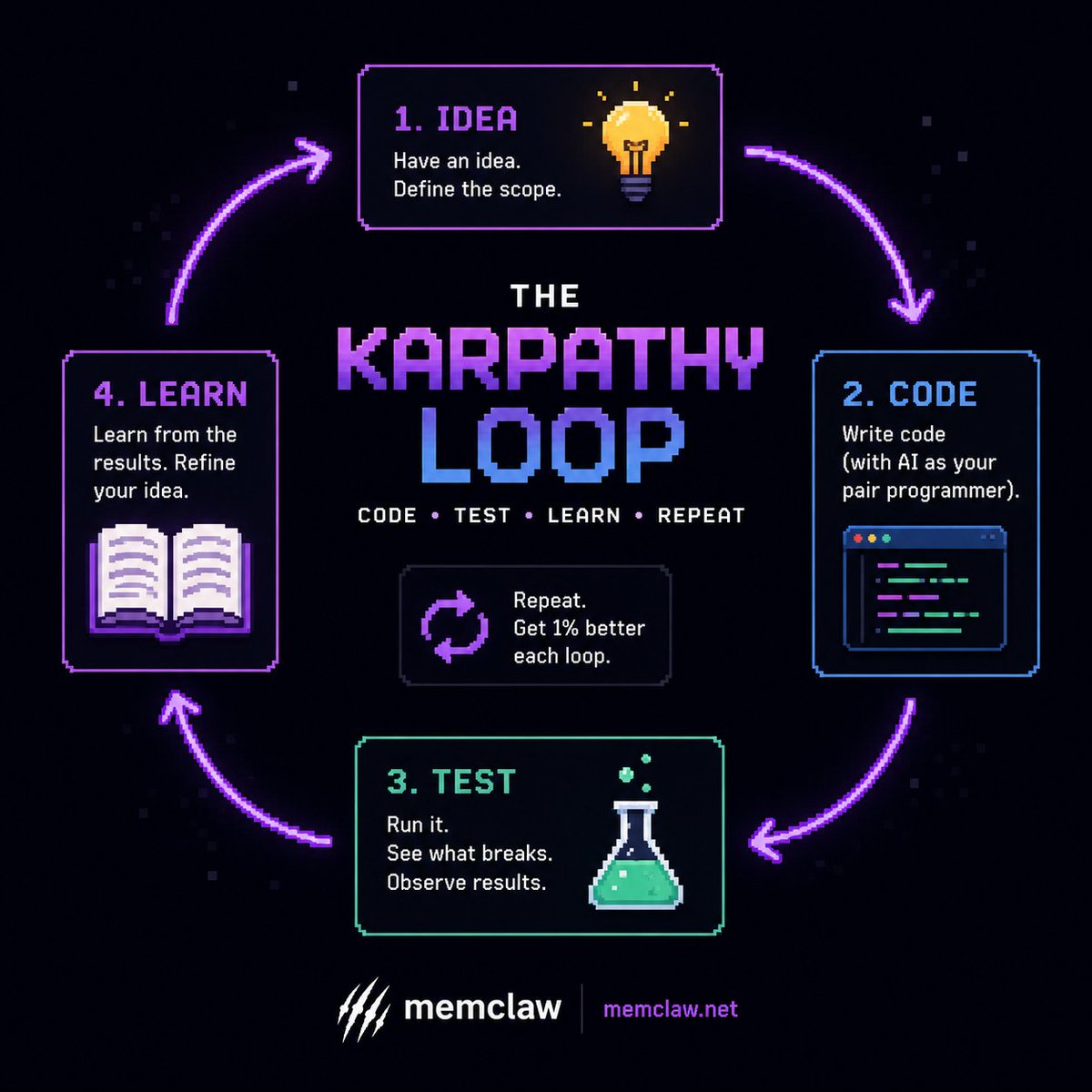

Most agent-memory tutorials stop at one agent remembering one thing. Real fleets are messier.
So we built the series we wished existed: 6 hands-on parts on one shared MemClaw stack, ending in a self-improving, governed fleet memory.
Open source ↓
memclaw.net/blog/memclaw-tut…
1
2
2
381
Static benchmarks go stale the day they ship. So we built one that doesn't.
PeerRank: 12 models write the questions, answer them with live web grounding, and grade each other — no humans, no gold answers. The rankings hold, and they agree with Elo.
New paper → arxiv.org/abs/2602.02589
2
2
5
161,929
4/
It's all open — code and the full dataset (12 models, 420 auto-generated questions).Paper: arxiv.org/abs/2602.02589
Code data: github.com/caura-ai/caura-Pe…
97
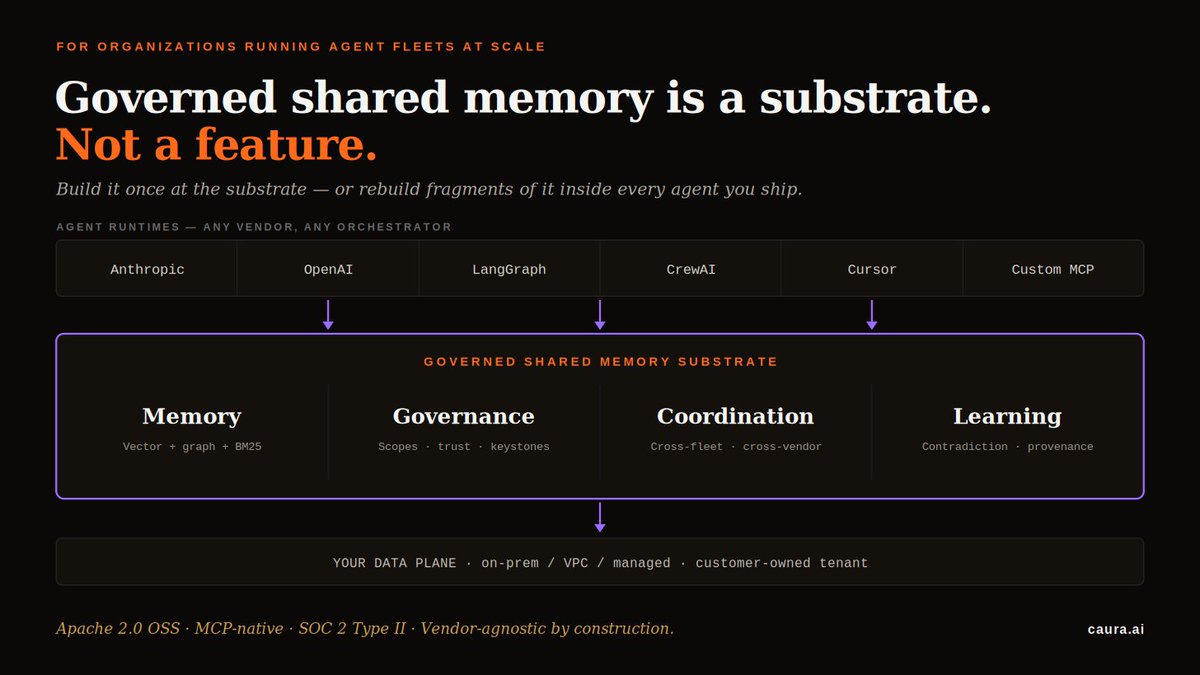
Governed shared memory for AI agents is a substrate. Not a feature.
Every fleet eventually needs persistent cross-agent memory with scopes, audit, and provenance. Build it once at the substrate — or rebuild fragments of it inside every agent you ship.
Any vendor. Any orchestrator. One governed plane.
1
3
451
25,000 downloads.
Thank you.
MemClaw is shipping in the wild. Apache 2.0. MCP-native. Production-proven at eToro.
This is the agent infrastructure era.
github.com/caura-ai/caura-me…
2
6
804
Drop a brand-new Anthropic agent into a live OpenClaw fleet.
Under 5 minutes later it answers like a 6-month veteran — portfolio, P&L, the team's standing rule.
Different vendors. One governed memory. Nobody integrated with anybody. Agents don't talk. Memory remembers.
memclaw.net/blog/new-hire-kn…
1
4
499
A solo dev wired two local agents into one shared cognition layer.
One hour. One JSON block. Standard MCP. No orchestrator.
Every fact taught once, enforced across every surface.
Agents are the workforce. Cognition is the institution.
memclaw.net/blog/clawshield-…
4
4
20
3,408
While the rest of AI is still demoing agents, eToro is running 300 of them in production.
One company brain.
21,500 memories. 1,372 skills. 23 ms recall across 291 agents. Audited every read.
memclaw.net/blog/etoro-compa…
1
3
21
2,158
We married Claude and ChatGPT.
MemClaw was the bestman.
Tell one. The other remembers.
memclaw.net/blog/memclaw-bes…
1
4
10
1,102
Caura-MemClaw is open source.
Apache 2.0. The whole engine — storage, hybrid retrieval, contradiction detection, audit trail, 12 MCP tools. Same code running in prod.
git clone → working fleet memory in 5 minutes.
memclaw.net/blog/caura-memcl…
11
4
19
2,213
memclaw.net/blog/road-to-hyp…
Agents shouldn’t just execute tasks — they should evolve through them.
The real breakthrough isn’t automation.
It’s systems that learn, adapt, refine judgment, and become more capable with every interaction.
Static agents are workflows.
Evolving agents are teammates.
3
1
14
97,654
memclaw.net is the first governed shared memory
for AI Agents fleets.
3
2
41
706,780
memclaw.net/blog/etoro-compa…
How eToro Built a Company Brain for 20 AI Agents.
A publicly traded fintech’s quest to give its agent fleet a shared memory — and the architecture that made it possible.
5
3
26
397,619
7
22
2,572
Someone asked: Will AI destroy humanity?
Probably not. We're doing fine on our own—climate change, nuclear weapons, reality TV.
AI isn't the villain. It's the adult watching us run with scissors.
The real question: Can AI save us from ourselves fast enough?
We're betting yes 🤖
2
1
14
2,040