
Joined October 2022
- Tweets 10,440
- Following 3,861
- Followers 901
- Likes 8,105
614 Photos and videos












Pinned Tweet

3 Jul 2025
Enjoy a bit of art, and at the same time, enjoy the intellectual way of vaping
@puffpaw

6
2
48
4,834

in local ai fast and worth it are two completely different numbers.
last post i showed you the fast one. this one is the number that actually decides what you should buy, and it does not crown the same winner.
quick catch up if you missed it. i have two 128gb boxes on my desk, the nvidia dgx spark and the amd strix halo, and i ran the exact same model on both, byte for byte the same file, same everything, both idle.
nvidia won on raw speed. that was the whole post.
but raw speed is what the spec sheet wants you to stare at. the number that actually matters when the money leaves your account is this one, how much ai you get per dollar you spend. so i took each box's token generation speed and divided it by what the box costs.
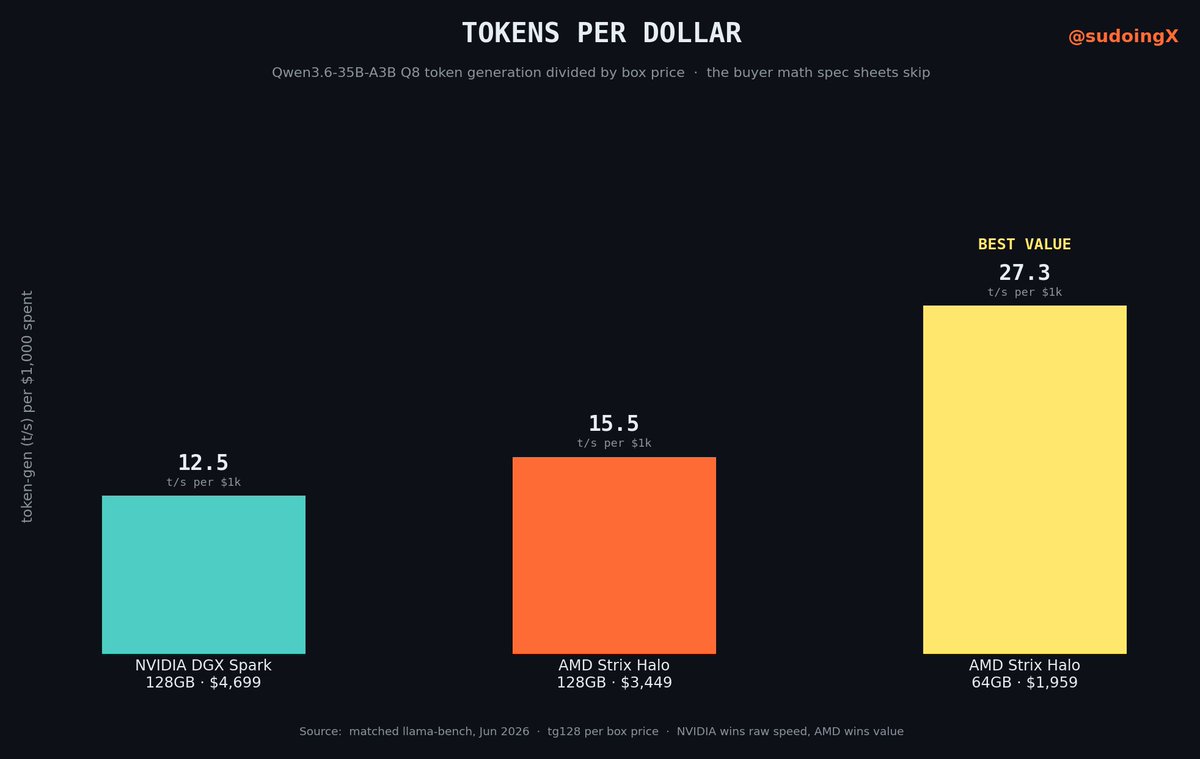
so here is tokens per dollar, the token-gen speed each box gives you for every $1,000 it costs:
>nvidia dgx spark, 128gb, $4,699 → 12.5
>amd strix halo, 128gb, the one i benched, $3,449 → 15.5
>amd strix halo, same chip in a 64gb box, $1,959 → 27.3
all three are tok/s for every $1,000 you spend, higher means more ai for your money.
now look at the bottom line. the same amd chip in the cheaper 64gb box gives you more than double the inference per dollar of the spark, and it runs this exact model at the same speed, because on these chips speed comes from memory bandwidth not capacity and the bandwidth is identical.
that is not a rounding error, that is the whole buying decision sitting right there.
here is why it happens, because this is the part that makes it real instead of a price whine. the speed you actually feel, the model typing its answer back to you, is decided by memory bandwidth, not raw compute.
the chip has to pull the model's weights out of memory once for every token it writes. both boxes have nearly the same bandwidth, about 256 against 273 gigabytes a second, so they write at nearly the same speed.
so what does nvidia's extra 3x of price buy you? compute. the blackwell chip has a lot more raw math, which is exactly why it was 2x faster at reading your input in the last post. and that is real.
but reading your input happens once. writing the answer happens for every token, all day long, and that is the part bandwidth owns, and the bandwidth is basically tied.
to be fair to the expensive box, because the silicon decides this, not my wallet.
if your work is huge context and heavy document crunching, that 2x prefill speed genuinely earns its keep. cuda is also years more mature than rocm, which the price tag never shows you but you feel the first time something breaks. and the spark has high-speed networking built in to link two of them into one bigger machine, the strix has no such ports at all, so if your plan is to chain boxes together the spark is made for it and the amd box simply is not.
for most people running a chat or an agent loop on a single box though, you are paying triple for muscle you will almost never flex.
one honest caveat so nobody can swing on it, the spark's price includes a 4tb drive against the strix's 1tb, so part of that gap is storage, not silicon. it tightens the math a little. it does not close it.
the spec sheet leads with speed because speed sounds expensive and impressive. the buyer math is quieter, and it points the other way.
the accessible tier of local ai is further along than the timeline thinks, and it costs a lot less than they keep telling you.

the results are in. two 128gb boxes on my desk, the nvidia dgx spark and the amd strix halo.
everyone argues which one is faster for local ai off spec sheets and vibes, so i stopped guessing and ran them head to head on the exact same model. here is what i actually found.
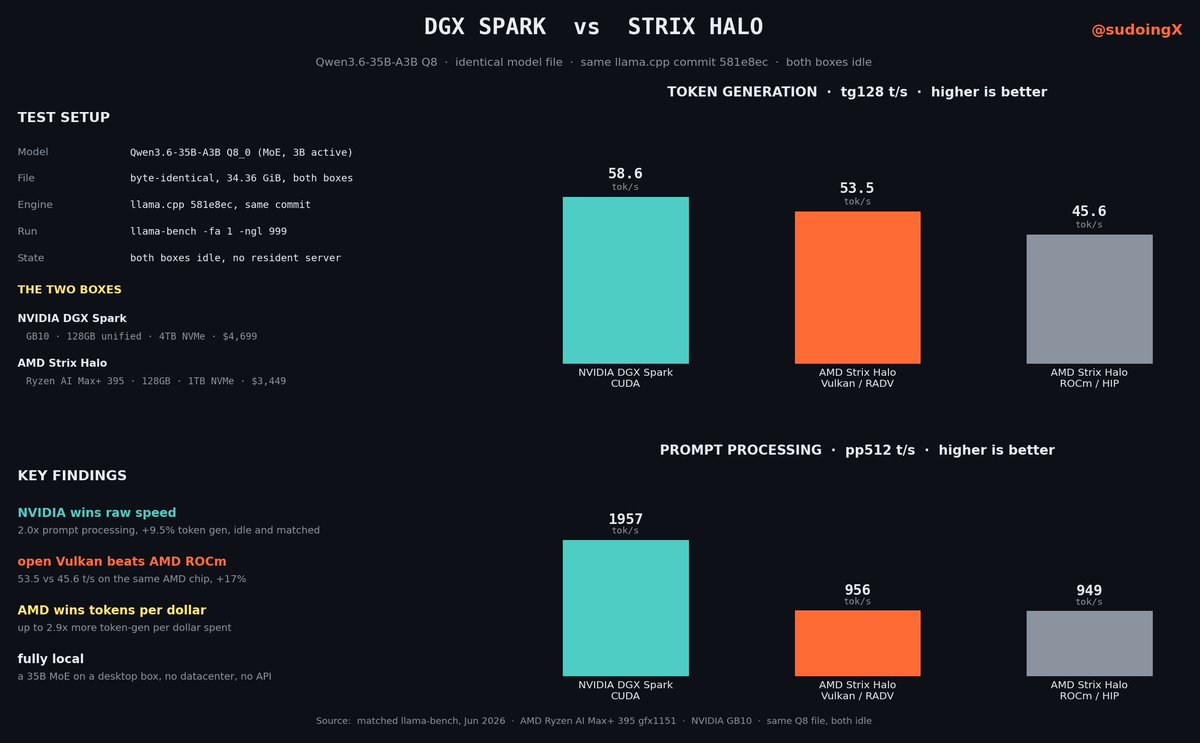
the setup, because it only counts if it is fair. the identical model file, the same Qwen3.6-35B-A3B at Q8, byte for byte the same gguf on both boxes. same llama.cpp commit. same flags. both boxes fully idle, nothing else touching the gpu. no thumb on the scale either way.
the two boxes:
>nvidia dgx spark, GB10, 128gb unified, 4tb samsung nvme, $4,699
>amd strix halo, ryzen ai max 395, 128gb unified, 1tb wd black, mine is the framework desktop at $3,449
prompt processing, how fast it reads your input:
>spark 1957 tok/s
>strix 956 tok/s
the spark is a clean 2x faster here. this is nvidia's compute muscle showing, long context and big documents go down fast.
token generation, how fast it writes the answer back, the speed you actually feel:
>spark 58.6 tok/s
>strix 53.5 tok/s
spark still wins, but by about 10 percent. side by side you would barely clock the difference while it types.
so on raw speed nvidia takes it, decisively on prompt processing, narrowly on generation. no spin, the spark is the faster box.
but speed is only half the question. the other half is what you paid to get it, and that one does not go the way this one did. coming next.
10
4
36
4,255
exitLQ retweeted

Valve’s upcoming Steam Machine just showed up on Geekbench again, and this time it’s running SteamOS.
The new results from yesterday list the device under its codename “Fremont.”
It has a custom 6-core AMD Zen 4 processor and appears to be paired with a Radeon RX 7600-class graphics card that has its own dedicated memory.
- Codename: Fremont
- Type: Compact living room / TV SteamOS console (not a handheld)
- CPU: Custom AMD 6-core / 12-thread Zen 4
- GPU: Radeon RX 7600-class discrete graphics (32 Compute Units, RDNA 3, 8GB GDDR6)
- RAM: 16GB DDR5
- Operating System: SteamOS (native)
- Performance level: Solid mid-range (noticeably stronger than Steam Deck)


80
110
2,296
133,333

i hope it's clear now why open source models are important
i've said before i can respect the position around safety but it's completely naive
even if you think you have superior morality and should control it someone will kick you out and take control
71
81
1,425
49,107
i'm running a 397 billion parameter model on a amd ai max box that sits on my desk and pulls less power than a gaming laptop.
the model is Nex-N2-Pro, 397B-A17B, the open weight release people are putting next to gpt-5.5 on coding. i have it quantized to IQ1_M, 1.75 bits per weight, 90gb of weights loaded into the 128gb of unified memory on amd's strix halo igpu.
watch the gpu in this recording. it spikes, it sustains, it does not fall over. that is the part the spec sheets never show you, not just that a 400b model loads, but that an integrated graphics chip holds the load and generates token after token, stable, no crash, no thermal cliff.
and it is not a slideshow. roughly 18 tokens a second, faster than you can read. a frontier scale model producing usable output, fully local. no datacenter, no rented h100s, no api key, no permission.
three years ago a model this size meant a server room and a budget to match. tonight it is a quiet box on my desk.
this is the accessible tier almost nobody benchmarks honestly, and it is further along than the timeline thinks.
the full breakdown is coming, rocm vs vulkan on this chip, and this little amd box head to head against the nvidia equivalent.
stay tuned.
the framework strix halo i posted yesterday is fully alive now. ubuntu, rocm 7.2.1, llama.cpp built against both rocm and vulkan, the entire local ai stack running on amd's gfx1151 igpu with 128gb of unified memory.
and it's already loaded with three models:
>Qwen3.6-35B-A3B at Q8, the new moe, 37gb
>Nex-N2-mini at Q8, 37gb
>Nex-N2-Pro, the 397 billion parameter one, at IQ1_M, 91gb across five shards
that last one still doesn't feel real. a 397b model sitting on my desk in a box that sips power off a normal wall socket.
i've already run the first benchmarks and the numbers genuinely caught me off guard, both rocm vs vulkan on this chip and this little amd box against the nvidia equivalent. holding the full breakdown for its own post.
stay tuned. the accessible tier is way further along than the timeline thinks.

28
12
258
30,774

This is the people you guys are paying big money on a monthly basis.
I’m more and more proud of what I’m building in @majorslair: true honesty, no greed, no pump and dump, super respectful of my members time and money; and all given for free (I actually also spend good money for an agent for which some costs are due: LLM - def not cheap -, and a server mainly).
There will be a time where honesty will be rewarded in this space, and I’ll be the frontman for this shift 🤝
Jun 15

Most of you already know @bradmel__ . The owner of the @elysian_nexus_ and caller in @MintedNFTs and other groups. Bradmel likes to call people out on X or in the chats for bricking floors, jeeting for peanuts, shilling collections and taking an exit liquidity few hours later.
The reality? He is doing the same or even worse things in some scenarios. At least people jeeting or shilling their own bags doesn’t have a paid alpha group where people pay you money to be in, or getting paid by Minted (No pun intended for Ali, he definitely doesn’t know that this is going on) for calling the plays there, which ends up used as his exit liquidity. Yes, you’ve heard that right.
(DISCLAIMER: YES, THIS IS A BURNER ALT I BOUGHT JUST TO POST THIS)
But first let’s start from the beginning - linking certain wallets to the Bradmel himself.
5
3
12
286
Jun 15
So, Iran deal to fall through on Wednesday and be confirmed again on Friday??
8
to everyone still stuck on openclaw, quietly telling yourself the next update will fix the bug report they closed without reading. i see you. it's okay. you can stop defending the choice now. sit down for this one.
switching to hermes isn't a migration project, it isn't a weekend, it isn't a "let me evaluate options next sprint." it's one command:
hermes claw migrate
and here's the part that should end the argument. the hermes agent team didn't just make leaving openclaw possible, they shipped a command whose entire job is doing it for you.
run setup and it auto-detects your ~/.openclaw folder and offers to pull you out before you even ask. it brings your settings, your memories, your skills, even your api keys. you lose nothing.
read that back. they named a command after your exit. that's not a feature, that's a team so sure you were coming they rolled the carpet out in advance, and 780 billion tokens says they read it right.
you've spent more time defending the choice in these replies than this takes to run. scared? dry run it first:
hermes claw migrate --dry-run
the door was always open. they even labeled it.
Jun 14

took me long but i switched from openclaw to hermes, will not look back
8
2
58
7,246
exitLQ retweeted

Jun 14
literally @liquid_launcher is building this
half of it is live
the other has is coming live extremely soon
and everyone we've been showing it all too is incredibly stoked on it and/or doesn't understand it in the slightest

idea
launchpad raise compute
founders raise compute
investors raise compute
the compute is liquid
multiply it with yield
can convert to dollars
who's building this?
4
2
41
4,425
exitLQ retweeted

Jun 3
bringing back the old dumb vibes
still buying JPEGs in 2026? this one’s for you.
Apply for WL → dumbois.lol/
refer dumb friends. earn GTD

2,013
2,117
3,664
31,835


We just applied to be a Kinsman. Registration number: REG-106569 @KinsmanNFT
Jun 12

Collab Applications are now open!
If you lead a community and would love to get Kinsman whitelist, this is your window.
How it works:
- Apply at kinsman.live/collab
- Fill out the form, post the tweet it generates, and hold onto your REG NUMBER. That's how you track your application status.
- Approved communities get a dedicated raffle page set up automatically on our site. Share the link to your community to join the raffle for a chance to win whitelist.
gKin

34
26
53
1,681
exitLQ retweeted

Jun 12
Every pixel has a personality.
10,000 PIXONA. Soon on @ethereum.
pixona.org
3,011
3,226
5,675
88,339

mint (sorry, jeet) day → 16 Jun, 17:00 UTC
WL that rewards fast hands and greed is open:
- high jeetscore = you're in, apply: jeetors.xyz/jscore
- low jeetscore? be active, we're watching 🫵
details below.

182
432
2,331
38,397
exitLQ retweeted

Jun 12
Walking to the moon
A small step for Blockheadz
but a giant leap for P5.js art
Made with an anon coder brain
If you wanna learn how to moonwalk just👇🏼
199
285
2,084
7,609
exitLQ retweeted

Jun 9
Not every Noren gets a place in the story.
1200 were created.
Only the earliest wanderers will enter first.
WL applications are now open.
The journey begins here.
🔗 norenoneth.site

85
144
1,327
6,629
exitLQ retweeted

Jun 13
Big collab incoming ✨
Partnered with @PixonaOrg, a 10k unique pixel collection, each with real personality and soul.
Clean pixel art done right, built for people who actually care about community and long-term IP.
Proud to bring another solid one for our community; the good stuff keeps landing here first 😎

30
22
38
954


exitLQ retweeted
Jun 11
Liquid is currently on the bleeding edge of this work
Jun 11

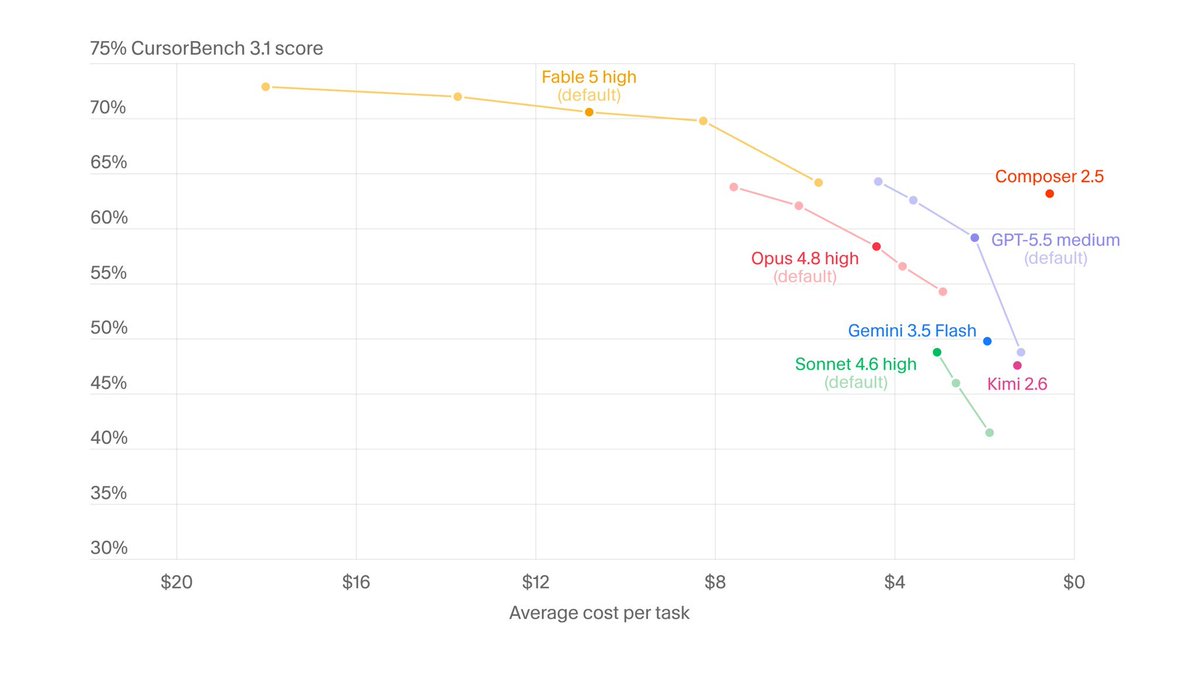
Frontier inference nows runs $11 per task. An agent doing real work executes 500 to 1,000 tasks a day, which puts its annual inference bill between $2M and $4M, for one agent, before a single dollar of revenue. An agent that cannot fund its own cognition is not autonomous, it is subsidized. Solving this is the actual frontier of the agent economy.
1
2
24
2,454
exitLQ retweeted

Jun 9
RT Drop EVM to mark your early presence

787
1,044
3,329
17,188