
We're building the agentic drug company. Foundation models AI agents that simulate human biology to discover drugs. Backed by Y Combinator (W26).
Joined February 2026
- Tweets 27
- Following 6
- Followers 1,587
- Likes 30
8 Photos and videos






Jun 10
Thrilled to welcome Dr. Lucas Carey as our Chief Strategy & Partnerships Officer. His experience building scientific platforms and partnerships will be invaluable as we push biological world models into pharma and diagnostics. Welcome to CellType.
Jun 10

I'm joining @celltypeinc as Chief Strategy & Partnerships Officer. After 2 years building Pando's scientific engine, I'm going all-in on biological world models. At CellType our models reason and understand across modalities.
Pharma or diagnostics? Let's connect.
2
5
770
CellType retweeted
Our paper STRIDE was accepted to ICML 2026!
We post-train LLMs to optimize proteins & molecules by emitting a chain-of-thought of atomic edits (INSERT / DELETE / REPLACE). Levenshtein-shortest-path SFT GRPO-style RL. Boosts protein optimization success from 42% → 89%.

2
10
65
3,502
CellType retweeted
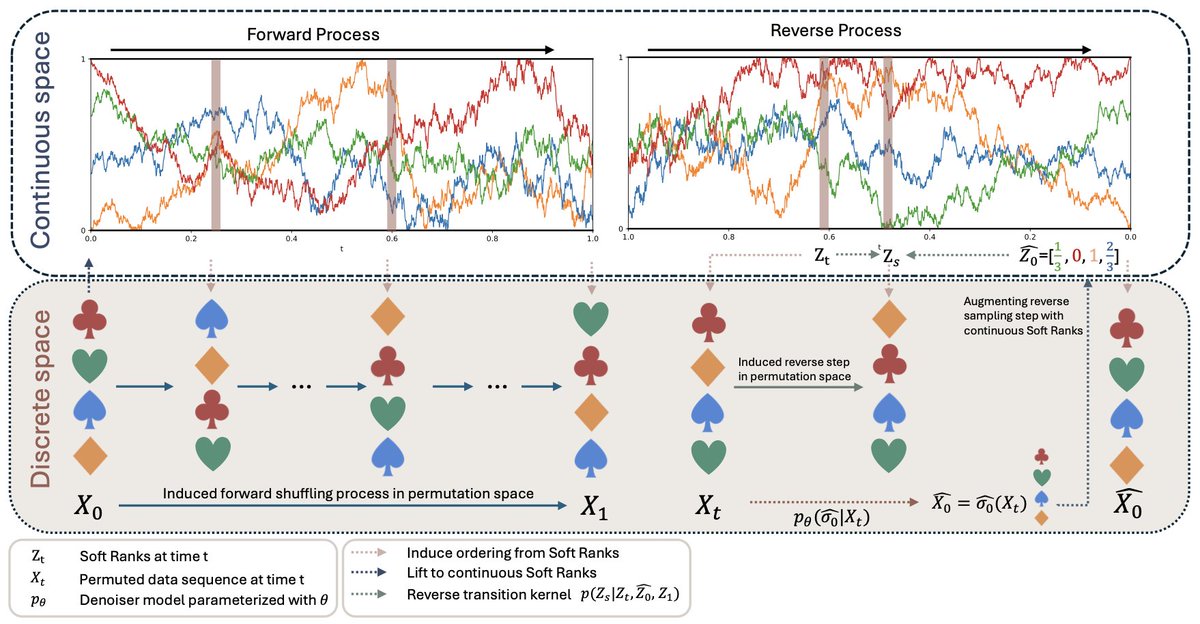
Our paper Soft-Rank Diffusion was accepted to ICML 2026!
Prior permutation-diffusion methods use riffle-shuffle forward processes that are abrupt and scale poorly with n. We instead lift permutations to continuous soft ranks in [0,1]ⁿ and run a reflected Brownian bridge, paired with a contextualized Plackett–Luce decoder. Big gains on long-sequence sorting and TSP.
3
4
29
2,365
CellType retweeted

Apr 27
AI-Personalized Medicine
@agupta
The cost of genome sequencing has fallen faster than Moore's Law, and agents can now analyze personalized health data to generate highly accurate, user-specific suggestions.
We think these shifts will bring about a revolution in care delivery, and a wide variety of startups will support every step of that ecosystem.
13
22
260
53,996
CellType retweeted

Apr 24
We’re hiring a Founding Head of Strategy, Data & Partnerships at @CellTypeInc
We’re building a biological world model — foundation models that simulate human biology and power the agentic drug company.
Help take this into the world.
Strategy × data x partnerships × frontier biotech/AI
🔗 celltype.com/careers/foundin…

1
6
33
2,950
Apr 14
CellType is hiring founding engineers! Biology is one of the biggest unsolved frontiers for AI. Join us building foundation models and agentic systems for drug discovery. If you want to push the frontier of AI for science, we'd love to talk.
celltype.com/careers
3
1
15
4,149

Mar 21
Great finally meeting Taylor Hsu from Senhwa Biosciences in person in San Francisco. Their drug CX-4945 was identified in our screen out of 4,000 compounds. Now CellType and Senhwa are partnering to further develop it together — exciting things in the pipeline!
senhwabio.com/en/news/202603…
2
16
1,365
Mar 16
LLMs can ace science exams and explain complex mechanisms. But can they actually do science—design a molecule, a dosing regimen, or a gene circuit that works?
We built SciDesignBench, a benchmark for testing frontier LLMs on scientific design tasks grounded in real simulators. The core finding is that models that can talk fluently about science still struggle when asked to produce designs that actually satisfy quantitative targets. We also propose a simulator-feedback RL recipe that improves performance on these tasks.
Paper: arxiv.org/abs/2603.12724 🧵
2
12
47
22,119
Mar 16
The elegant part is that the same asymmetry that makes inverse design hard also suggests the fix. Scientists have already built forward simulators for many of these problems. Those simulators can be repurposed as RL environments: propose a design, evaluate it, learn from the reward.
In our case studies, training on simulator feedback lets a small 8B model outperform much larger frontier models on selected scientific design tasks.
1
1
409
Mar 16
This is the thesis behind @CellTypeInc. You can't just prompt an LLM to design a drug. You need a simulator that can evaluate whether a design actually works—and then use that feedback to train models that get better at the hard direction.
Paper: arxiv.org/abs/2603.12724
2
366
CellType retweeted
Mar 13
Our first clinical-stage pharma partnership. CellType models working on a real drug, in real patients. This is what we built for.
Mar 13

We are thrilled to announce CellType's strategic partnership with Senhwa Biosciences! We're using our models to accelerate their clinical oncology drug, CX-4945, unlocking novel mechanisms to make tumors more visible to the immune system. senhwabio.com/en/news/202603…
1
4
24
4,040
Mar 13
We are thrilled to announce CellType's strategic partnership with Senhwa Biosciences! We're using our models to accelerate their clinical oncology drug, CX-4945, unlocking novel mechanisms to make tumors more visible to the immune system. senhwabio.com/en/news/202603…
2
18
5,349
Mar 11
Keep working in your local environment while CellType Agent Pro offloads heavy GPU jobs to CellType Cloud.
Run protein folding, molecular simulations, single-cell models, and other GPU-heavy bio workflows without managing your own GPU stack.
Try it at celltype.com/agent
2
24
17,271
Mar 9
People kept telling us they wanted to run the CellType Agent but didn't have the compute. So we built CellType Agent Pro — GPU compute, plus an on-prem option for teams with sensitive data.
celltype.com/agent
3
15
89
31,582
CellType retweeted

Feb 18
This team of Yale CS Professor postdoc is building a next-gen drug company. It's been great working with them this batch. Congrats on the launch!
Feb 18

.@celltypeinc is building the agentic drug company.
AI agents foundation models that simulate human biology. They've already discovered and validated a novel cancer treatment signal and work with Top 10 pharma.
Congrats on the launch @david_van_dijk and @vrkici!
ycombinator.com/launches/PSn…
3
10
68
13,621
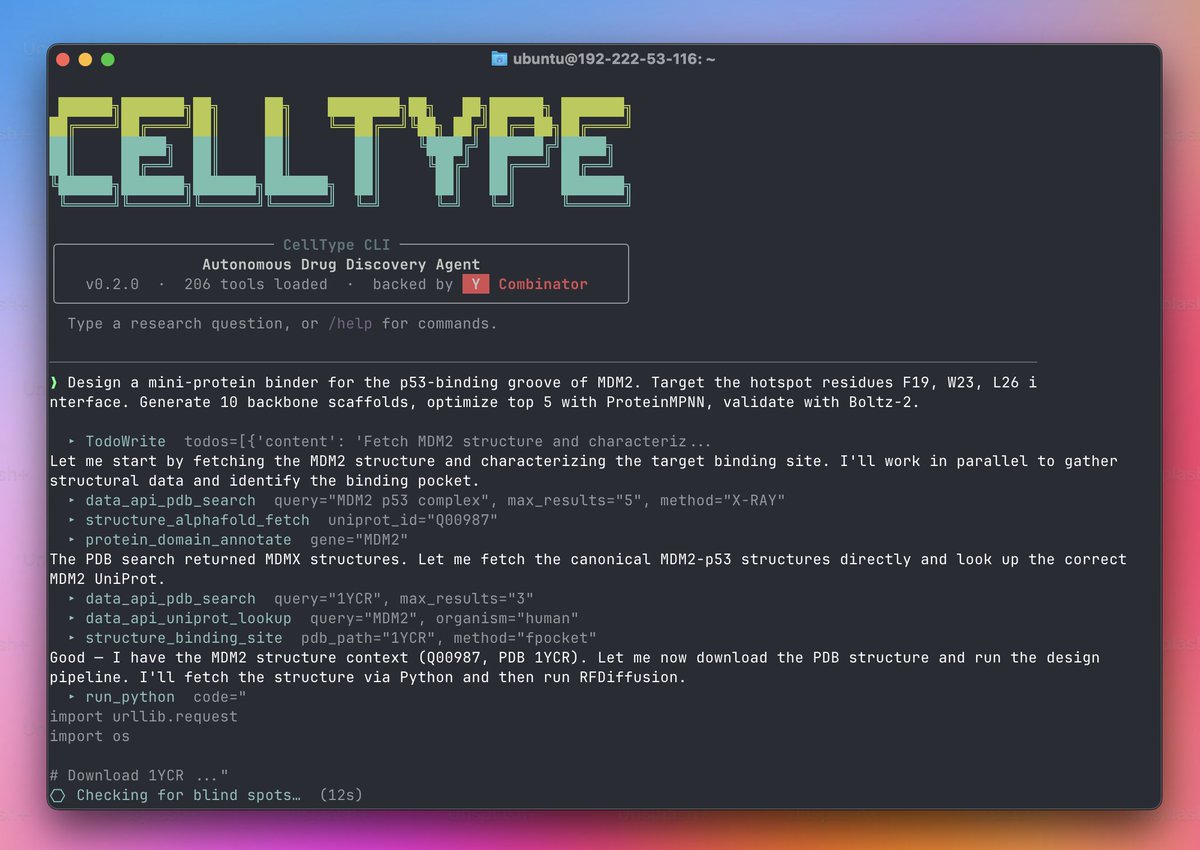
Feb 23
We teach models to reason about biology.
Today we're open-sourcing the tool we built to run that science.
Think Claude Code, but for drug discovery.
pip install celltype-cli
35
120
717
276,340
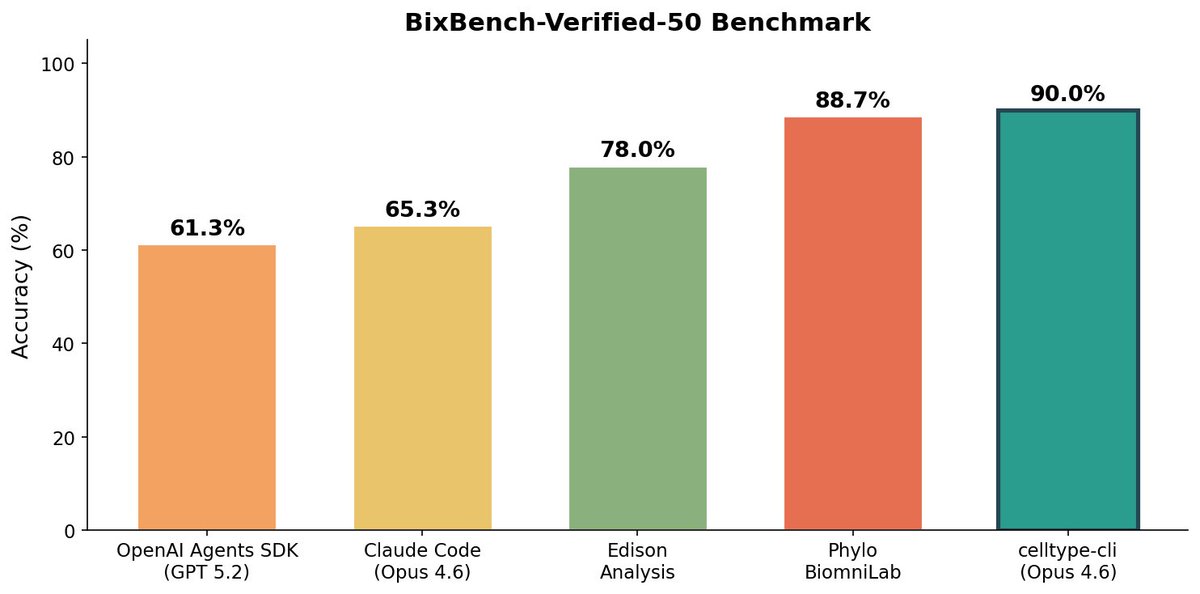
Feb 23
We benchmarked celltype-cli against other agentic systems on computational biology tasks.
1
2
45
8,077
Feb 23
100 domain tools. CLI-native. Fully extensible.
celltype.com/cli
github.com/celltype/cli
3
67
6,801