
Ph.D. @UCSanDiego | Scaling RL and agents
Joined November 2021
- Tweets 429
- Following 707
- Followers 1,280
- Likes 1,822
Photos and videos
Pinned Tweet

Pretraining has scaling laws to guide compute allocation. But for RL on LLMs, we lack a practical guide on how to spend compute wisely.
We show the optimal compute allocation in LLM RL scales predictably.
↓ Key takeaways below
18
98
442
70,769
Very solid data work here on cua envs. Massive value in both the outcome and the execution!
May 26

RLVR has become the recipe for agentic post-training. But for Computer-Use Agents, the bottleneck is not the algorithm, it is the data. 🐌
🚀 We introduce CUA-Gym: a scalable, lightweight synthesis engine that turns arbitrary task queries into verifiable RLVR data for computer-use agents. The largest open CUA RLVR dataset to date:
🎯 32,122 verifiable RLVR tasks with programmatic setup scripts rewards
🌐 110 environments: 16 desktop apps 94 synthesized mock web apps
🏆 Qwen3.5-based CUA models trained with GSPO reach 72.6% on OSWorld-Verified and 56.6% on WebArena
📄 Paper: huggingface.co/papers/2605.2…
🏠 Homepage: cua-gym.xlang.ai
🤗 Dataset: huggingface.co/datasets/xlan…
💻 Codebase: github.com/xlang-ai/CUA-Gym
🧩 Environments: github.com/xlang-ai/CUA-Gym-…
🧵[1/6]
1
1
21
2,479
Zhoujun (Jorge) Cheng retweeted

May 22
🌀 Introducing 𝐄𝐪𝐮𝐢𝐥𝐢𝐛𝐫𝐢𝐮𝐦 𝐑𝐞𝐚𝐬𝐨𝐧𝐞𝐫𝐬 (𝐄𝐪𝐑) !
Feedforward models and weight-tied models behave very differently on hard reasoning generalization.
EqR pushes this difference to the extreme by learning 𝐭𝐚𝐬𝐤-𝐜𝐨𝐧𝐝𝐢𝐭𝐢𝐨𝐧𝐞𝐝 𝐧𝐞𝐮𝐫𝐚𝐥 𝐚𝐭𝐭𝐫𝐚𝐜𝐭𝐨𝐫𝐬 .
• Sudoku-Extreme: 99.8%
• Maze: 93%
#ICML2026
13
67
308
76,161

Excited to announce our tutorial: "Future of Work in the Age of LLMs" at #ACL2026 in San Diego, July 2! 🌴
There's a lot of speculation about AI and the future of human work. Our tutorial unpacks it from four angles:
→ The landscape of human work
→ How to build LLMs to augment real-world workflows
→ How to evaluate these LLMs
→ The future of work with LLMs/LLM-based agents

2
19
136
17,108
Thanks RadixArk for sharing our work NanoRollout!!

Slow, heavy environments have been the real bottleneck for agentic RL. NanoRollout tackles it head-on with a clean rollout-as-a-service design, integrated with miles for scalable agent RL.
Great work from the team!
1
17
2,195

Slow, heavy environments have been the real bottleneck for agentic RL. NanoRollout tackles it head-on with a clean rollout-as-a-service design, integrated with miles for scalable agent RL.
Great work from the team!
May 14

Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
1
8
69
14,917
Zhoujun (Jorge) Cheng retweeted

May 16
Thrilled to see those promising numbers! 🤯
Same finding on our end with NanoRollout: cross-scaffold generalization basically doesn't happen out of the box -- something the field should be talking about more.

May 15

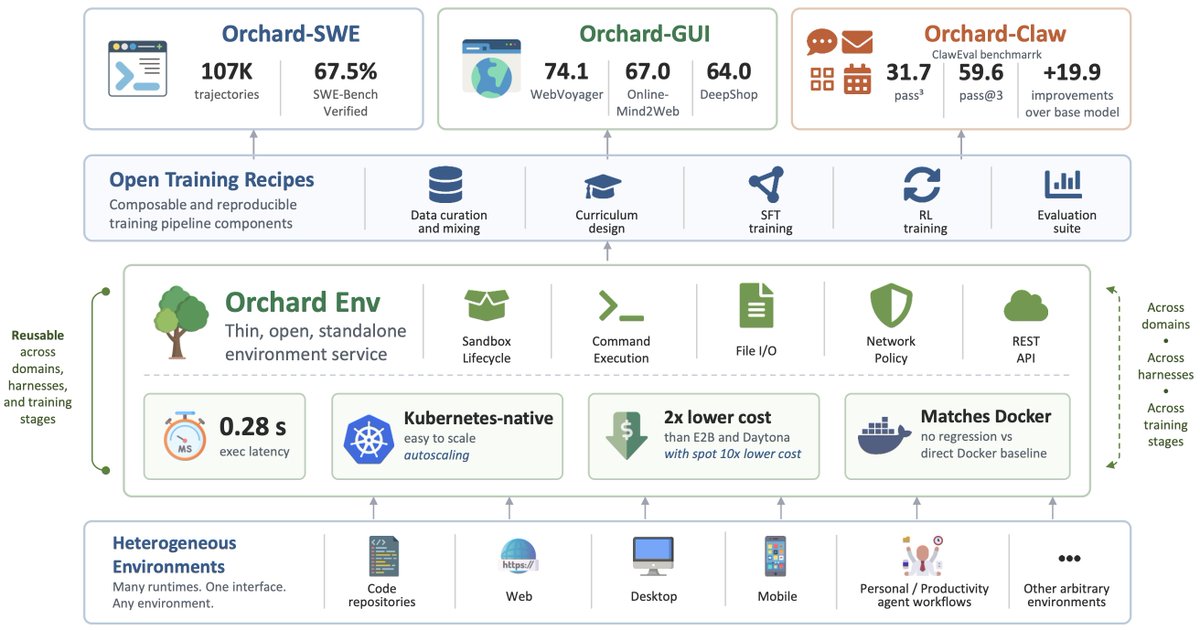
🌳 Introducing Orchard — an open-source agentic modeling framework! 🎉
One thin & cheap sandbox infra powers training recipes across SWE / GUI / personal-assistant agents:
⚙️ Orchard Env: 0.28s exec latency; 100% success @ 1,000 parallel sandboxes 💪
🛠️ Orchard-SWE: 67.5% on SWE-bench Verified (30B-A3B, ~3B active)
🖥️ Orchard-GUI: 68.4% avg on WebVoyager / Online-Mind2Web / DeepShop (4B!)
📬 Orchard-Claw: 73.9% pass@3 on Claw-Eval
🔗 arxiv.org/abs/2605.15040
📦 Code and data are coming soon!
Let's accelerate open agentic AI! 🚀


1
6
33
6,052
Zhoujun (Jorge) Cheng retweeted

May 15
Cool. I always enjoy playing with nano projects.
No matter who asks me how to learn LLM, my answer is always the same.
- Start with nanochat/nanogpt.
- Then pick one super niche direction.
- Deep dive into it. Build a nano project. Scale it gradually.
That's all.
May 14

check our new work nanorollout!!
7
36
4,092
Zhoujun (Jorge) Cheng retweeted

May 15
Been working on the coding model behind this for a while. Still needs huge improvement, but let's see!
An early beta of Grok Build, an agentic CLI for coding, building apps, and automating workflows is now available for SuperGrok Heavy subscribers.
Through this early beta, we will improve the model and product based on your feedback.
Try it at x.ai/cli

18
6
217
10,411
Zhoujun (Jorge) Cheng retweeted

The lack of light weight, open agent infra has been a massive pain point. This is a great starting point esp for large scale, thousands of parallel envs, battle tested coding / computer use agent training!
May 14
Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
2
19
2,946
Zhoujun (Jorge) Cheng retweeted

May 14
check our new work nanorollout!!
May 14
Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
5
29
8,271
Zhoujun (Jorge) Cheng retweeted

May 15
Check out this cool project led by @JunliWang2021 @ChengZhoujun ! Solid new agent infra and impressive results on open source RL/SFT recipes.
May 14
Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
2
4
11
1,236
Zhoujun (Jorge) Cheng retweeted

May 15
Very solid agentic infra work on accelerating agent rollout!
May 14
Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
1
2
10
2,845
Zhoujun (Jorge) Cheng retweeted

May 15
Nice work! Training digital agents isn't trivial, co-designing rollouts with targeted environments stands as the pain point once you dig into agentic RL. This is super clean and agentic RL folks should try this out.
May 14
Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
1
2
7
747
Zhoujun (Jorge) Cheng retweeted

May 15
We need more agent rollouts. Glad to see SETA is used in NanoRollout!
May 14
Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
1
3
20
3,309
Happy to release NanoRollout, our infra attempt to scale digital agent rollouts without pain. Setting up and scaling parallel digital agent envs is one of the biggest headaches in agent training / deployment. The open community hasn't handled it well.
Two appealing features from NanoRollout:
🔌 Non-intrusive RL integration with frameworks such as miles, verl, tunix; validated end-to-end, e.g. outperforms DeepSWE-32B at a large 4k batch size 🚀
🧩 Unified support across agent harnesses and envs — covering SWE-Bench, Terminal-Bench, OSWorld, CocoaBench — with fast parallel eval that reproduces published scores (e.g., full SWE-Bench Verified eval from 102 min → 18 min, 5.7x faster⚡)
And the core logic is just ~900 LOC.
Hope NanoRollout helps if you're also trying to scale agent rollouts. Check out the tech blog and github for more details!
Big thanks to the fantastic co-lead @JunliWang2021
May 14
Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
7
19
2,923
Zhoujun (Jorge) Cheng retweeted
May 14
Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌
🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads:
🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B
🧪 250k distilled coding trajectories -> SOTA ≤32B open coding agent
⚡ Fast evaluation on coding/cua/unified agent -> finish
Check our Blog: cocoa-org.notion.site/nanoro…
2
39
136
35,493
Zhoujun (Jorge) Cheng retweeted

May 13
Today, we’re excited to launch Recursive (@recursive_si): an exceptional team across London and San Francisco, building AI systems that can safely improve their own capabilities over time.

15
17
124
17,240
A great piece on self-distillation using failures! Besides scaling up num of rollouts, actively scaling (extracting) signals from raw rollouts should be an important way to improve agents and save compute.
May 12

On-policy self-distillation is a promising direction for learning from rich textual feedback. But can it really learn from failed trajectories?
Our answer: not quite -- unless we let the model actively interpret them.
🧵1/N

1
2
18
3,775
Zhoujun (Jorge) Cheng retweeted

May 8
Sub-agents are a promising inference-time scaling primitive:
• Expand an agent's working memory
• Divide-and-conquer hard problems
• Solve problems faster with parallel execution
But how do we train a model to best take advantage of sub-agents and make sure we get these benefits?
Very excited to release RAO: Recursive Agent Optimization.
RAO is an end-to-end reinforcement learning approach for training LLM agents to spawn, delegate to, and coordinate with recursive copies of themselves (that can themselves spawn other agents) - turning recursive inference into a learned capability.
1/10
23
117
717
134,874
Zhoujun (Jorge) Cheng retweeted

May 4
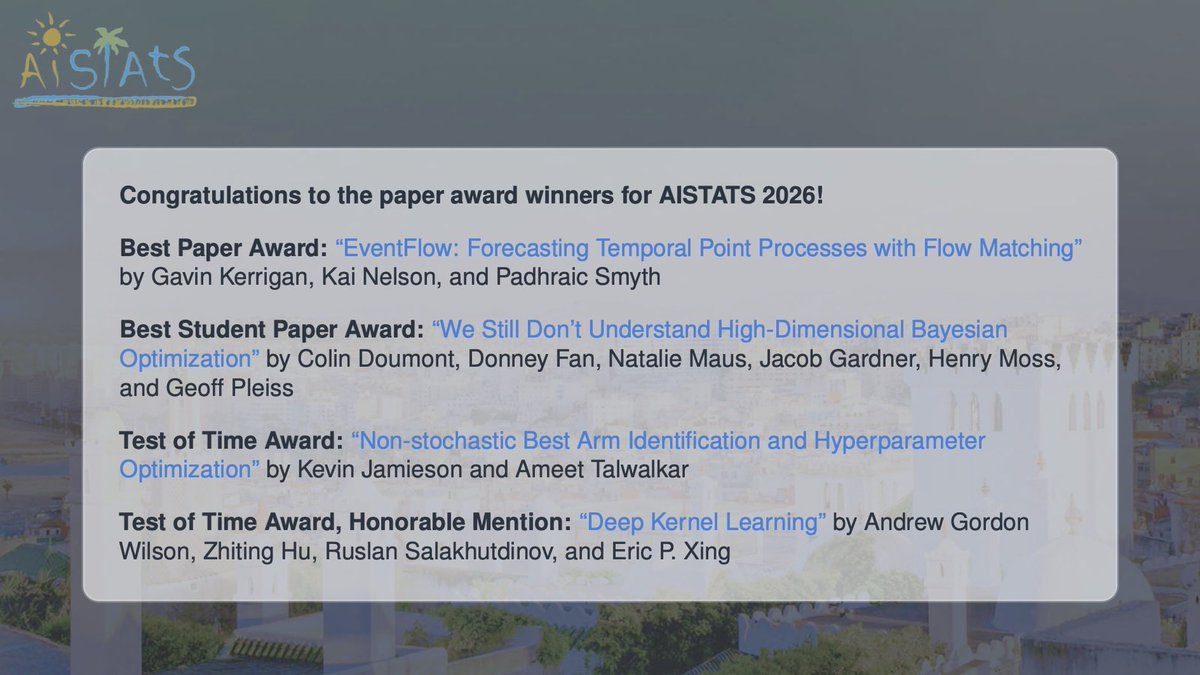
🏆Honored to receive the Test of Time Award Honorable Mention #AISTATS2026 for our 2016 work Deep Kernel Learning, with the amazing @andrewgwils @rsalakhu @ericxing
What a decade of AI progress! While GenAI is now driving massive real-world applications, the deepest underlying challenge remains: learning efficient representations of the world—for understanding, generation, predicting future worlds, and reasoning in the latent space.
So much fun to think about for the next decade!⏳
10
14
120
14,557