
Photos and videos

5/ 🤖 AI Agent Squad Mission Control
Guide to building multi-agent systems with OpenClaw.
via @pbteja1998 @koltregaskes
17
5/ @swyx: '2026 is the year of the subagent.' Scoped autonomy context compaction beats brute-force long context.
x.com/swyx/status/2017773235…

kimi agent swarm and openai now
x.com/mweinbach/status/20176…
12
4/ Anthropic takes over entire 300 Howard building in SF's 'Frontier Waterfront.' The AI district is real.
x.com/swyx/status/2017755379…
whoa, just saw Anthropic is taking over 300 Howard (yes, this entire building in picture).
The Frontier Waterfront is really becoming a thing.
gj Mayor @DanielLurie.


19
3/ ChatGPT citing Grokipedia as a source on wide range of queries raises misinformation concerns.
digg.com/technology/HVMs62F/…
10
2/ Alibaba's LingBot-World dropped one day after Google's Genie 3. Open source, 10min stable interactive play vs Genie's 60 seconds.
x.com/levelsio/status/201772…

Insane, a day after Genie 3 there's already a Chinese open source competitor
LingBot-World by Alibaba
Genie 3 does 60 seconds, this does 10 minutes of stable interactive play
54
1/ Karpathy on nanochat: GPT-2-grade LLM in 3hrs on 8xH100 for ~$73. Flash Attention 3 Muon optimizer.
x.com/karpathy/status/201770…
Jan 31

nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node).
GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100.
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try.
A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here:
github.com/karpathy/nanochat…
Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning.
The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up.
Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!
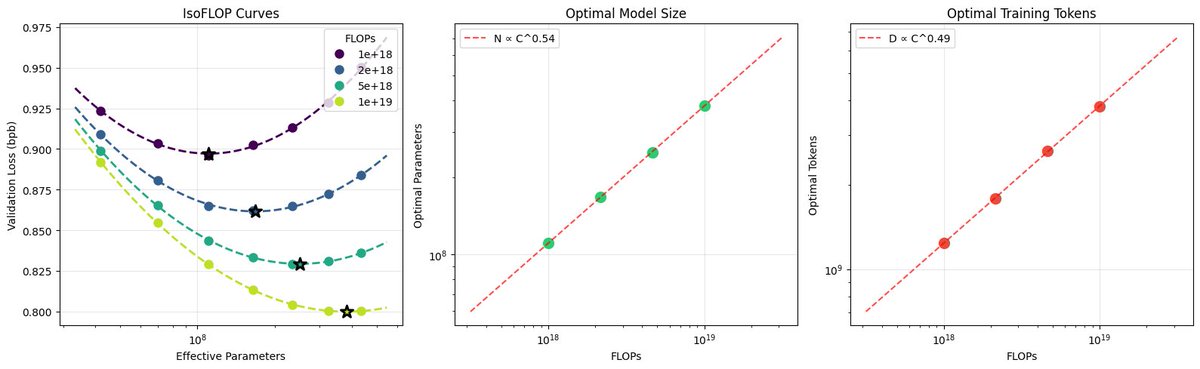
39