
Building Slite
Joined October 2013
- Tweets 6,016
- Following 1,230
- Followers 3,295
- Likes 23,287
808 Photos and videos









Pinned Tweet

Today we're introducing Slite as the first self-maintaining Knowledge Base
Your wiki docs go outdated everyday, and your agents depend on them for your most ambitious workflows.
Slite monitors your docs' accuracy from all other work tools (slack, jira, linear, codebase, etc) while you sleep and updates them.
It even directly talks to your AI agents to give them accurate context without burning their context window or tool calls.
You've been trying to build this 'company brain' for months now with hacky MVPs
This is the final version of what you need, already built to be collaborative, headless, and secure.
Check it out and HMU if you need this for your team, I'll be running personal onboardings for the next few days!
23
13
126
16,658
I'm still confused on these type of releases.
The only mildly interesting - but is it worthy of being called a standard? - part is the yaml description of different folders, the meta knowledge describing how sources are organised.
It's often appended to each docs without a full description at parent level and this pattern is definitely big to do retrieval on unstructured knowledge
Jun 12

This is really big news. Google introduced the Open Knowledge Format (OKF) - a standardized way to store information in a directory of markdown files. Makes it really easy to make a digital brain that agents can use.
These files can serve as a living wiki. You can give agents the ability to query them or edit them. They can interlink.
Seems to me this could replace Notion or Obsidian. I can think of so many uses for this.
Google's blog post: cloud.google.com/blog/produc…
An easier to understand explanation is the SPEC.md file:
github.com/GoogleCloudPlatfo…
I gave those two links to Antigravity and asked how we could use it for any of the projects we're working on. It came up with so many ideas. I would imagine Claude Fable 5 would whip up some pretty amazing things based on this system.
Currently creating an OKF library of our pepper garden. It's going to be a fun weekend.

1
283

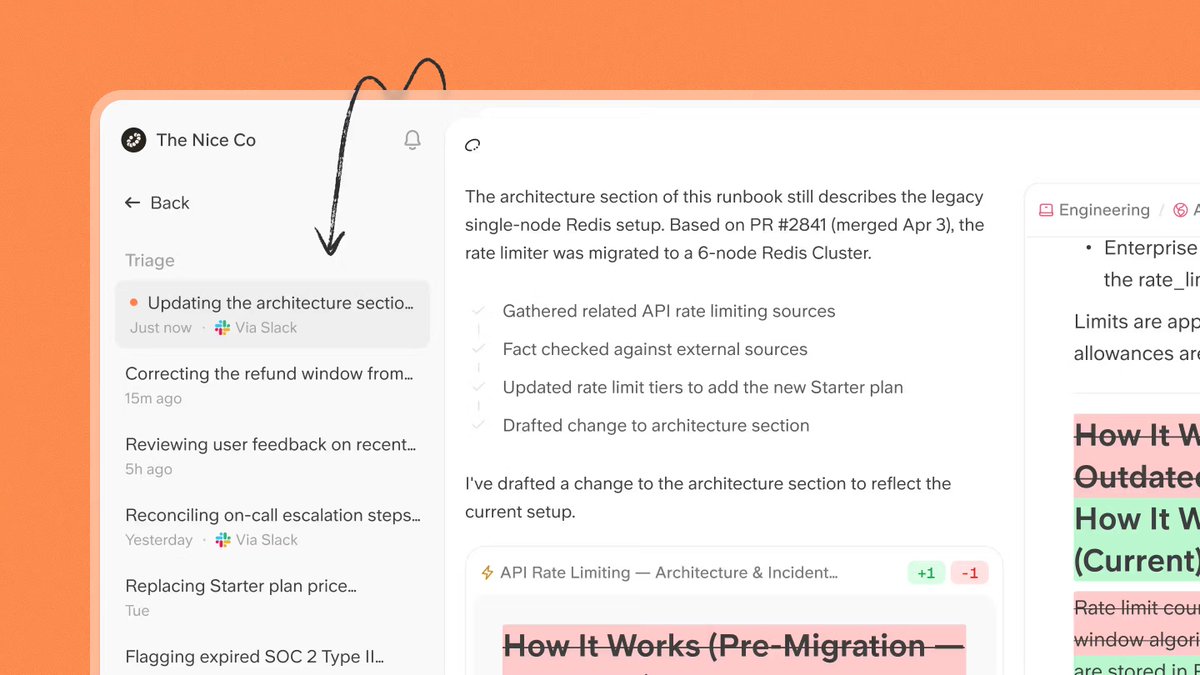
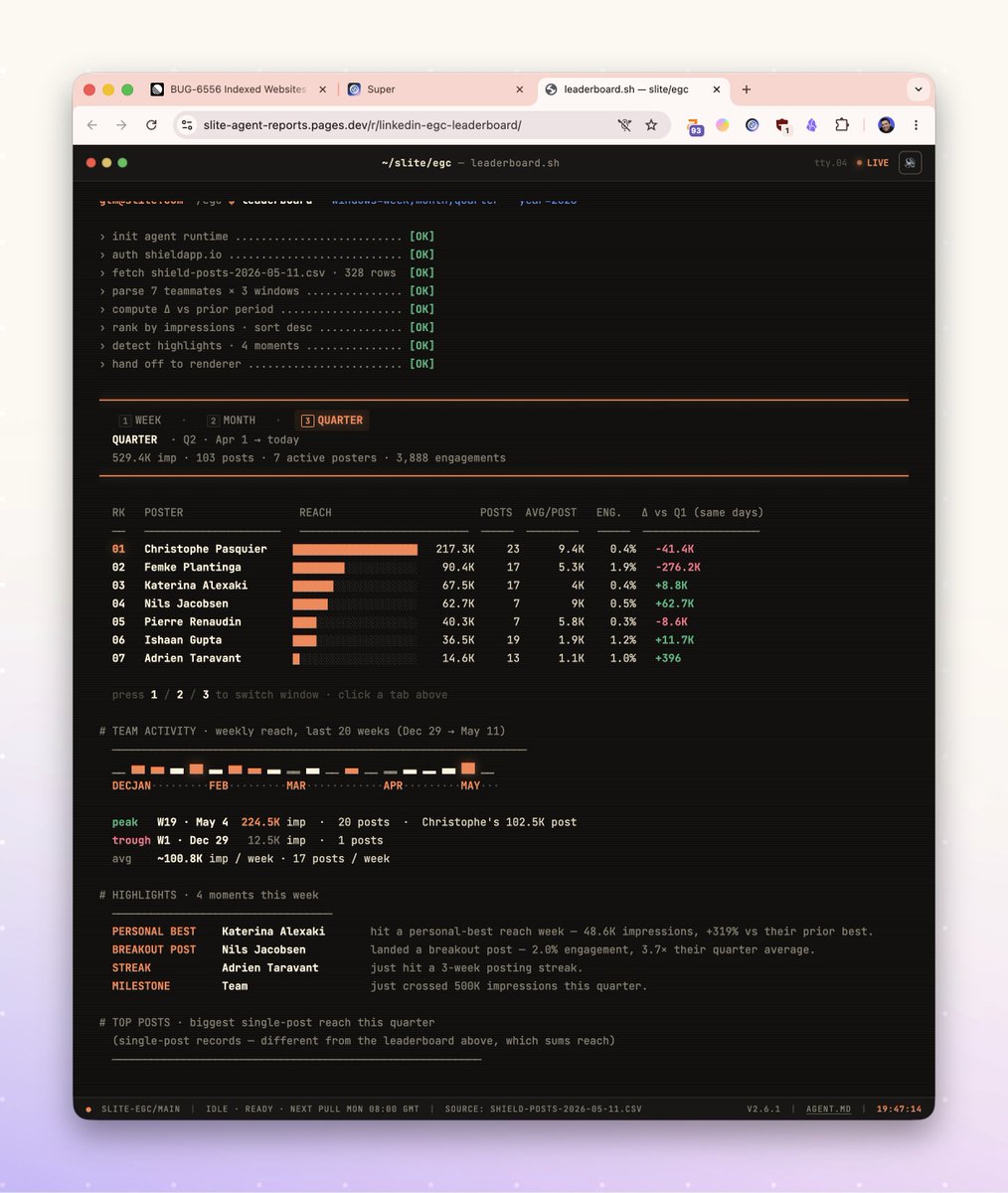
Today, Slite became the first self-maintaining knowledge base.
Docs go stale. Teams and agents act on wrong information. Nobody notices until it's too late.
We launched something to fix that.
Meet the Slite Agent:
Slite Agent is a layer on top of your knowledge base that never sleeps. It monitors every doc, detects when content has gone stale, and surfaces a proposed update, written and ready for your review.
How it works:
→ Slite Agent scans your knowledge base and all your other apps (Github, Jira, Slack etc.)
→ flags outdated docs
→ drafts a proposed update
→ you review and approve
What you get:
✓ Verified docs rank higher in AI answers. Stale ones get excluded.
✓ Your team gets accurate answers, without having to maintain anything manually
✓ Your AI agents get a context agent that answers anything and everything about your company
Read the full announcement: slite.com/blog/slite-announc…
3
8
503
Christophe Pasquier 🇺🇦 retweeted

Jun 10
Knowledge bases don't die overnight.
They rot slowly, one outdated doc at a time.
This is called knowledge drift. And it's now fatal, not just for your team, but for your agents.
When an AI agent uses your KB as its source of truth (and it will), every outdated doc becomes a confident, well-formatted wrong answer.
Garbage in, garbage out - at scale, at speed, with no one to catch it.
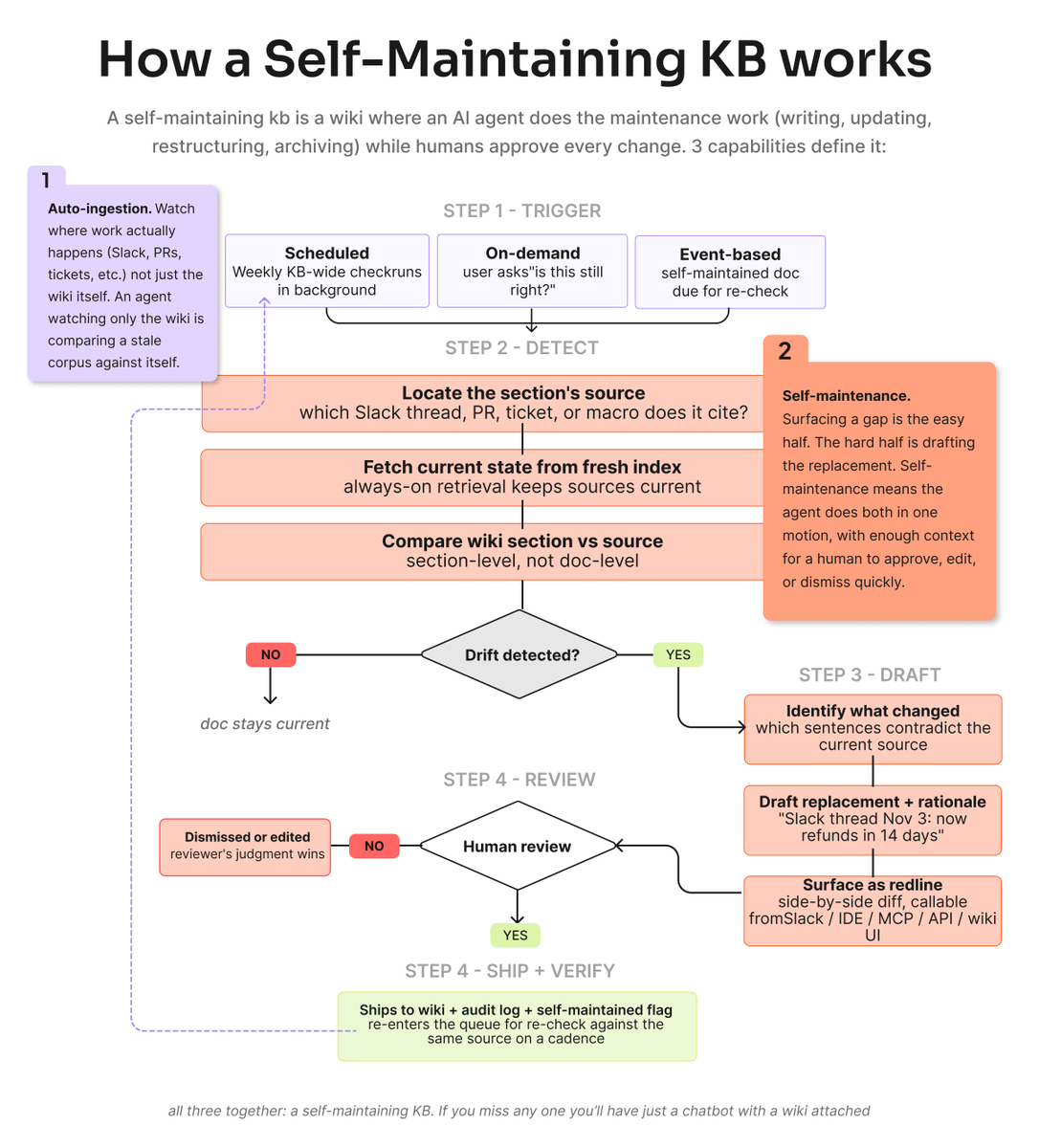
Here's how a self-maintaining KB fixes that:
1️⃣ Self-maintenance loop. The loop is continuous: trigger → ingest → detect → propose → approve.
2️⃣ It detects drift. An Agent monitors your connected tools (Slack, Linear, GitHub, Jira) and flags docs the moment they fall out of sync with reality.
3️⃣ It proposes the fix. The agent drafts the update: edits existing docs, writes new ones, merges duplicates. Ready for review.
4️⃣ Humans approve. Nothing auto-applies. Every change goes through a triage step. The agent proposes; your team verifies.
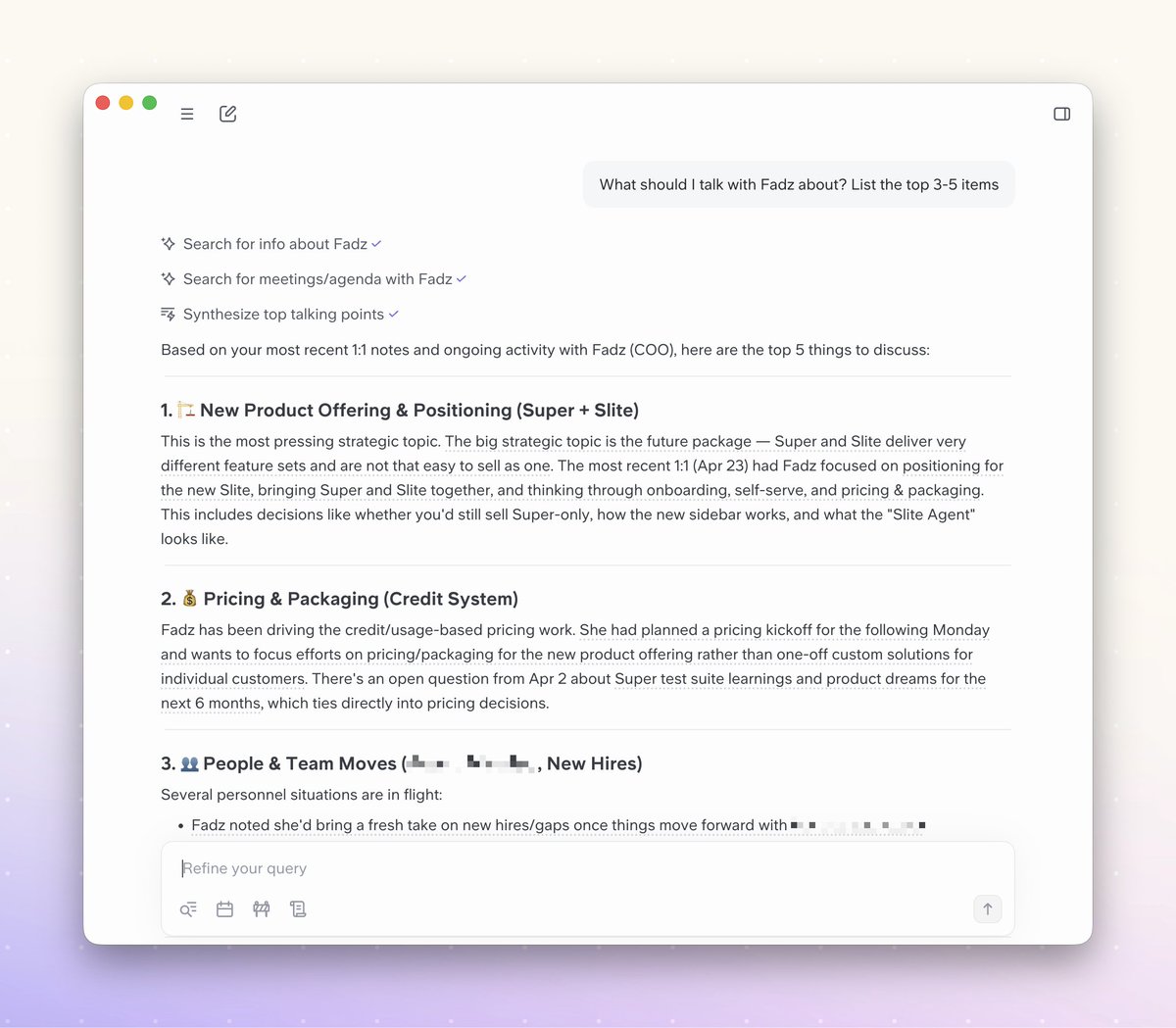
You're not replacing your team's judgment. I see it more like: getting verified knowledge and context your team can trust and your agents can act on.
Today, we launched the first self-maintaining knowledge base at @slitehq.
Read the announcement here: slite.com/blog/slite-announc…
3
32
213
10,618
Presentation of our agent by the tech team live from our Offslite 🔥
(incredible how AI 10x the quality of internal presentations)
1
7
272
Christophe Pasquier 🇺🇦 retweeted
Things are cooking at @slitehq in Berlinooo.
More very soon 🧡


4
1
18
1,244
Christophe Pasquier 🇺🇦 retweeted

Jun 4
Excited to launch Upstream and announce our $3M pre-seed round
AN INBOX DESIGNED FOR HUMANS AND AGENTS
Upstream's agents sort the noise, draft replies in your exact voice, follow up at the right time, and do what you ask, like finding receipts, scheduling meetings, or writing personalized messages
Thousands of people used it in our closed beta to handle their email. Now available to everyone
How it works: 🧵
37
30
156
33,279
Our Agent roasting itself, and this one was on point.
Reinventing team knowledge to self maintain with human in the loop is, in fact, reinventing Git for business logic.
1
2
93
Christophe Pasquier 🇺🇦 retweeted
Happy Monday to everyone, except:
• people that slide into my LinkedIn DMs with a sales pitch
• "AI specialists" who steal visuals without giving credit
• anyone who still hasn't switched away from Notion, Guru or Confluence

3
2
14
1,038
Christophe Pasquier 🇺🇦 retweeted

May 30
I just found a great solution to a frustrating issue I've had for years.
I like to subscribe to educational newsletters to pick up tips and learn from entrepreneurs far more successful than myself.
I've been really enjoying the 30 day growth series by @chenellco.
Here's the issue: I might get a newsletter on Monday but only want to go through it on Friday. Until then it sits unread in my inbox taking up space.
I like inbox zero.
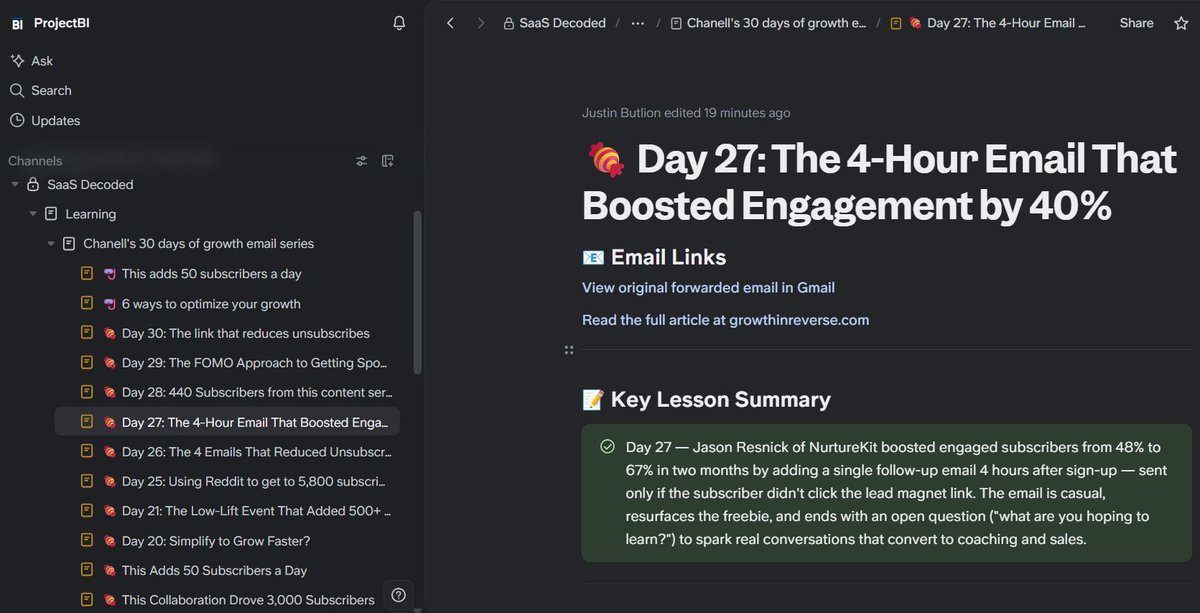
The solution: I forward the email to an inbox my virtual employee, Viktor (@get_viktor_com), has access to and I ask him to turn the email into a document in @slitehq, my AI-friendly knowledge base.
Why does this work so well?
1. The content is organized in a knowledge base so I can find it easily (Slite has a great search function).
2. I can ask Viktor to scan through Slite and use the info saved from the newsletters to solve problems, draft plans, or make suggestions.
3. I keep my inbox clean.
4. I can ask Viktor to create a digest of the lessons that were saved in the knowledge base in the previous week. I can then scan through them and zoom in on the items which catch my attention.
By the way, the above flow can be semi-automated by using multiple inboxes, labels and a scheduled task set up in @get_viktor_com.
DM me if you'd like the exact steps for setting up this flow.
2
2
192
Christophe Pasquier 🇺🇦 retweeted

May 31
I get that business insurance is similar Nobel level type of pursuit as ground breaking physics and the Manhattan project. Hopefully the blast radius will be contained.
I don’t think the disagreement is whether hard problems require intensity.
The disagreement is whether intensity has to become a permanent operating model, and whether working seven days a week is the thing that compounds.
My argument is that for most startups, the real compounding advantage is not raw hours. It is clearer thinking, better judgment, learning, and a team that can sustain high-quality work for a long time. You can always spend a lot of time working, but the PMF might never arrive.
There are moments where extraordinary effort is necessary. Launches, incidents, existential deadlines, customer commitments. Those moments matter, and great teams rise to them.
But if the company requires heroics every day of the eek, that usually points to a system problem. It means the operating model depends on burning reserve capacity instead of building it. Company that is constantly on fire is company that is not operating well.
Whenever you put something out there, people will argue and people can argue the way I run Linear. The reason I comment on these things to offer some counter point.
There is a growing cliché in startup culture where founders and startups feel the need to perform intensity publicly. How hard they work, how little they sleep, how many tokens they spend, how busy they are, how much personal sacrifice they make.
You almost never see this from the most successful companies or people. Even if they work that way, they usually don’t make it the story, because they have more important things to talk about, like the product, the customers, the insight, the strategy, the quality of the work.
That’s my issue with the narrative and why I think startups shouldn't blindly follow it. Not that is bad to work hard but grindmaxxing narrative can become the greater goal and become counterproductive. The performative intensity becomes the thing, and loosing sight of what actually matters.
Lets check back in 7 years.
55
147
3,652
373,157
How you know we're getting to the end of the free tokens era, Claude Code starts to display tokens used as it works.
1
2
140
Christophe Pasquier 🇺🇦 retweeted
May 28
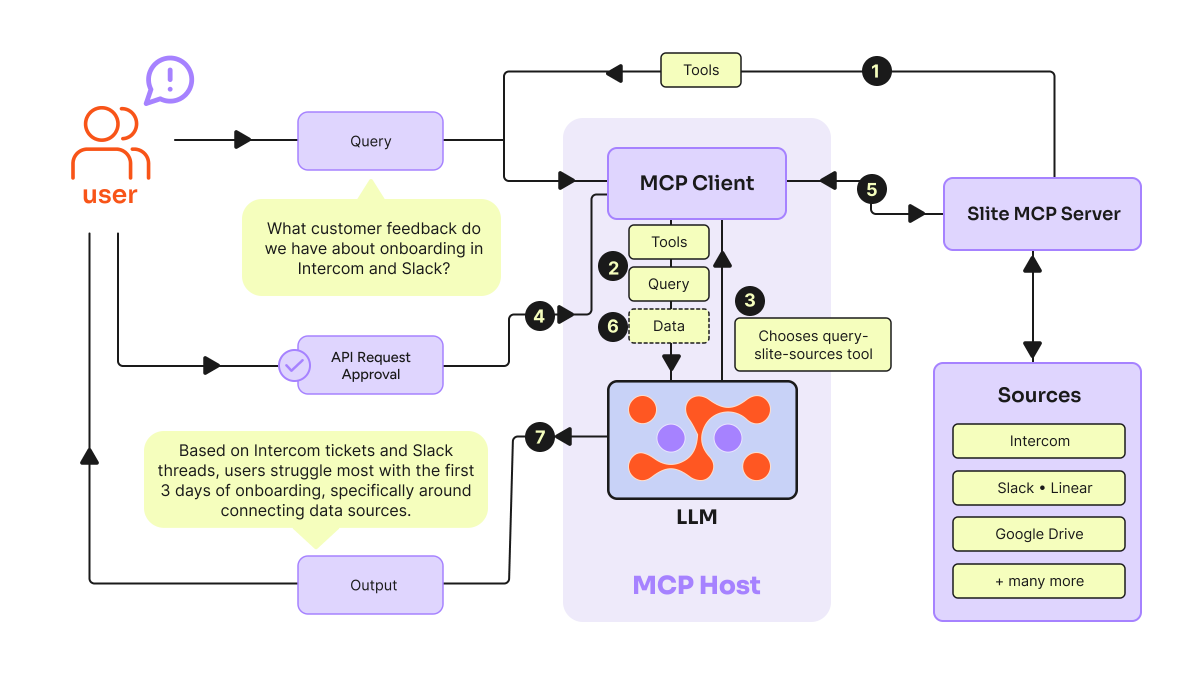
If you still don't know how to explain MCP.
Here's what it looks like when you plug it into real tools.
MCP is designed to get the full potential of AI models by giving them structured, dynamic access to the right context, without having to reinvent the wheel each time you need to define and serve a tool for an LLM.
Let's say a user asks: "What customer feedback do we have about onboarding in Intercom and Slack?"
That single query triggers a 7-step dance across the MCP stack. Here's what happens:
1️⃣ The MCP Client asks the MCP Server what tools are available. The Server replies with a list - search Intercom, query Slack, pull Linear tickets, fetch from Drive.
2️⃣ The Client sends the user's query plus the tool list to the LLM. "Here's the question. Here are your options. Pick one."
3️⃣ The LLM chooses. In this case: query-super-sources, the tool that searches across multiple connected systems at once.
4️⃣ Before any tool actually runs, the user approves the API request. This step matters more than people give it credit for - it's the line between an agent that works for you and one that acts on you.
5️⃣ The Client calls the MCP Server with the chosen tool. The Server hits the actual sources: Intercom, Slack, Linear, Drive.
6️⃣ Raw data flows back to the LLM. Not formatted, not summarized - the actual results.
7️⃣ The LLM synthesizes: "Based on Intercom tickets and Slack threads, users struggle most with the first 3 days of onboarding, specifically around connecting data sources."
Done. One natural-language question, four tools queried, one synthesized answer.
A few things worth noticing about this flow:
• The LLM never touches the sources directly. It only sees the tool list and the results.
• The user approval step is built into the protocol, not bolted on. This is what makes MCP enterprise-ready in a way that raw function calling isn't.
• And the Super MCP Server is doing something specific, it's not one MCP server per source, it's one server that routes across multiple sources. Big difference when you're building real systems.
What's the most useful thing you've wired into your MCP stack? 👀
4
10
64
4,607
Christophe Pasquier 🇺🇦 retweeted

May 22
i have a lot of respect for @arthurmensch for trying to engage and educate the french institutions.
This is un-ironically important work that you're doing mate 🙏
May it be fruitful
24
34
577
37,108
Christophe Pasquier 🇺🇦 retweeted

May 3
Honestly, faster horses would've been way cooler.
27
7
427
16,412
There is massive value in purpose-built.
I also have had the same for a year, with more comprehensive data than Granola could even grab, yet I'm in love with having no maintenance efforts and to delegate the taste and details to @meetgranola
May 20

1 month ago, I spent 10 min building this exact feature as a @NotionHQ agent and it works perfectly
Although I love my granola, it almost makes me love notion even more
Notion is probably one of the best positioned companies in the world rn
1
4
741