
Joined November 2024
- Tweets 222
- Following 81
- Followers 78
- Likes 1,082
169 Photos and videos

















I have met with many companies that heavily benefit from my work to discuss the possibility of them supporting me. They frequently commit to do so, but they almost never do. When most companies "support open source", what they mean is they like profiting off it for free.
10
9
226
8,867
Clumsy_Trainer retweeted

Apr 8
ACE-Step-1.5-xl is out now.
We scaled the DiT decoder to 4B. And it shows better audio quality, better prompt following, and better musicality. It still fast -- 8 steps with turbo distillation.
What didn't change:
- Same generation API, same LoRA training code, same everything
- All LM models (0.6B / 1.7B / 4B) fully compatible with all 3 variants
- Your existing projects work with XL — no changes needed
Try it for free at acemusic.ai
Weithgts and code:
GitHub: github.com/ace-step/ACE-Step…
Hugging Face: huggingface.co/ACE-Step/Ace-… (3 variants: xl-base, xl-sft, xl-turbo)
XL demos: ace-step.github.io/ace-step-…
15
80
385
35,592
I trained an ACEStep 1.5 XL LoRA on "some obscure 60s English rock band". Then I wrote a song about LoRA training and had them play it. Absolutely wonderful experience. I still have some UI work before I can make training public in AI Toolkit, but working on it as fast as I can.
54
59
525
36,775

Clumsy_Trainer retweeted

Feb 17
There are many ways to support this project: Open issues, submit PRs, build the ecosystem. The real contribution is making it popular and accessible. Share your music, make tutorials, spread the word. Let’s build something amazing together. 🚀
github.com/ace-step/ACE-Step…
1
5
16
622
Clumsy_Trainer retweeted
Feb 14
LEGO models are supported; we just need to test and fix bugs today
Currently, it’s only lacking testing, and tutorials, and only the base model is supported.
2
2
10
2,713
I always felt CFG was a patch to fix a training problem we didn't yet understand.
Training with only normal distributed noise teaches the model that each step will have a perfectly normalized error from the previous step, which is not the case. Therefore, it is incapable of correcting the errors it created from the previous steps during generation, which leads to distorted generations as these uncorrected errors compound with each step.
We currently correct this by applying 2 pass CFG to amplify the model's correction predictions from a base, which helps correct these errors at each step, but this leads to the model over correcting leading to over corrected images that look oversaturated. That classic AI look.
I tested fine-tuning Z-Image while providing a balanced random augmentation of the noise and it appears to have taught the model to overcome these errors which led to the model no longer needing CFG and also producing better quality images in the process.
These samples are from training a LoRA on Z-Image with a batch size of 2 for 3,000 steps. I am going to do a significantly longer fine-tune using the same process this weekend.

23
28
411
25,913
Clumsy_Trainer retweeted
Feb 3
We're releasing ACE-Step-v1.5(2B), a fast, high-quality open-source music model.
It runs locally on a consumer-grade GPU, generates a full song in under 2 seconds(on an A100), supports LoRA fine-tuning, and beats SUNO on common eval metrics.
GitHub: github.com/ace-step/ACE-Step…
Key traits:
Quality: beats Suno on common eval scores
Speed: full song under 2s on A100
Local: ~4GB VRAM, under 10s on RTX 3090
LoRA: train your own style with a few songs
License: MIT, free for commercial use
Data: fully authorized plus synthetic
The music AI space lacks commercial-grade open models. Many creators are forced to rely on closed-source services, and can’t fully own, run locally, or fine-tune their own models. We want to help change that.
144
458
2,547
1,052,270
Support for training LoRAs for @Ali_TongyiLab Z-Image has been added to AI Toolkit. No code changes were necessary, but I did add a template to the UI so you can quickly get started.
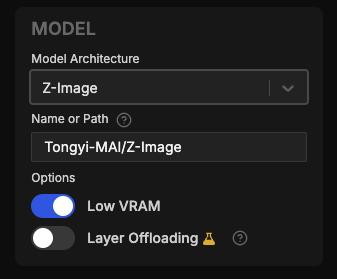
15
30
288
29,545

Tutorial: How to Train a @Lightricks LTX-2 character LoRA with AI Toolkit
In this video, I train a character LoRA on the late great Carl Sagan.
Links in 🧵

6
39
287
16,379
AI Toolkit now officially supports training @Lightricks LTX-2 LoRAs.
24
17
257
18,660
The most difficult hurdle with implementing LTX-2 into AI Toolkit was handling the data loader. Stretching video with audio to desired frame rate and count while maintaining audio synchronization and preserving the pitch was very difficult. But it is done! Won't be long now.
14
10
171
8,065
LTX-2 in AI Toolkit progress:
I have model loading, quantizing, ramtorch offloading, and training on images / videos without sound working. Need to finish up sound and add i2v support, but it is coming along. Tested a 2 character LoRAs. <24GB of vram for image only. This is not pushed yet.
20
10
170
20,257
If you appreciate my contributions to open source software and models, please consider becoming a sponsor. Supporting open source projects and their creators is vital for open innovation, and financial support from people like you makes my work possible.

7
14
144
46,619

My latest LoRa CHIAROSCURO is avaiable in early acces @HelloCivitai
civitai.com/models/2276358?m…
Trained for @Ali_TongyiLab Z-Image Turbo on @ostrisai AI-Toolkit
#AIart #lora #zimage #ai
2
29
31 Dec 2025


10