
构建 AI 的知识协议层,让你的知识数据变成你的资产 @codatta_io
Joined July 2013
- Tweets 409
- Following 8
- Followers 738
- Likes 109
91 Photos and videos














Jun 12
两真一假——AI数据版。
其中一条是假的。是哪一条?
1. 一张错误标注的图片可能悄悄拖垮整个模型。
2. 大多数公开的AI数据集会标注谁做了标注。
3. Codatta 验证者在贡献生效前会重新检查。
猜猜看👇
8
Jun 10
发现AI出错了?那就是前沿贡献。
Codatta的“纠正LLM错误”任务:找到有缺陷的模型回答,截图并提交正确答案。每个经审核通过的贡献最高可获100积分。
教程如下👇
1
32
Jun 8
AI训练依赖于人类数据。贡献者们很少能证明或拥有他们所提供的内容。
Codatta正在构建缺失的环节:基于链上的贡献证明。
- 每一次提交都有数字指纹并可追溯
- 每位贡献者持有所有权代币
- 每次使用都会向源头触发版税支付
15
Jun 4
你有没有问过两个AI模型同一个问题,得到不同答案?
这正是这个任务的核心。
找一个客观问题,让两个AI模型给出不同答案。提交两份回答及截图,并附上你认为正确的答案。
每个有效提交都有助于找出当今顶级模型中的真实知识盲点——同时还能让你获得100积分。
观看教程👇
1
50
Jun 3
大多数数据管道让你做出选择:精确度还是规模。
高质量标签?慢且昂贵。
快速、可扩展的收集?噪声大、不可靠。
Codatta 的混合验证不会让你二选一。
每次贡献都经过透明流程——贡献者提交,验证者确认,结果记录并附上风险评级。每一步都可追溯。
精确度和规模。两者兼得。
18
Jun 1
标注加密货币地址并赚取奖励。
东南亚CEX热钱包收集 — 印度尼西亚·泰国·柬埔寨。
在本地CEX交易?这为你而来。提交交易所热钱包地址 — 每个50积分。
👉 app.codatta.io/app/frontier/…
24
May 26
加密地址元数据支离破碎。
团队重复做相同的研究。中心化提供者限制访问。市场变动最快时,数据恰恰过时。
合规、市场分析、交易——全都在不完整的地图上运行。
Codatta 正在构建加密地址注释——一个社区驱动的数据库,贡献者跨链丰富、验证和更新地址数据。
为整个加密生态系统打造共享智能层。开放、实时、社区共建。
1
27
May 22
注释加密地址,赚取奖励。
您在这些OTC平台交易吗?
InnovestX / Bitazza / EasyEquities / Interactive Brokers / MultiBank / Alpaca Trading
提交场外交易地址,进行注释,赚取奖励。
👉 app.codatta.io/frontier/proj…
39
May 21
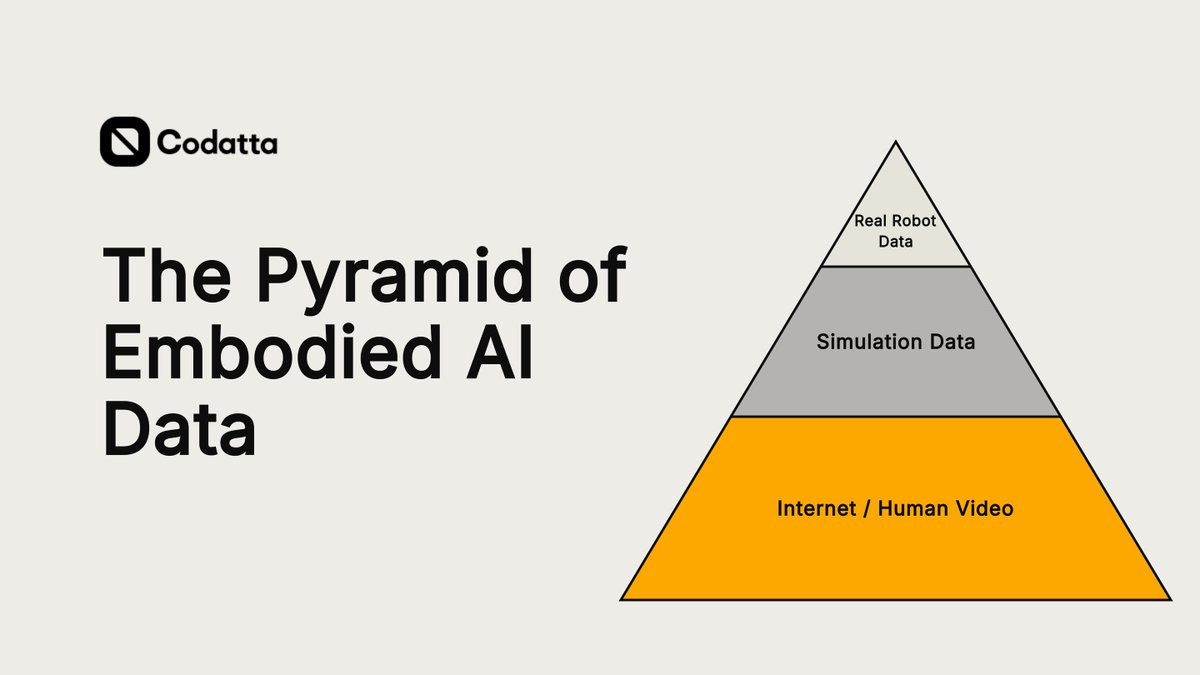
具身AI领域急需数据。获取高质量机器人数据极其困难。要理解行业如何解决这一问题,我们需要看看数据金字塔,它由三个主要层次组成:真实机器人数据、仿真数据以及互联网/人类视频。
1
24
May 21
3️⃣ 互联网 / 人类视频
互联网和以人为核心的视频是最丰富且成本最低的可用原材料。
优点:规模化。它帮助基础模型建立基本的物理认知——理解世界如何运作、空间推理和人类意图。
缺点:缺乏力、扭矩和触觉反馈。视频展示了行动的结果,但不能精确显示执行所需的电机信号。AI知道“做什么”,但不知道“如何”移动关节来完成。
趋势:硅谷先驱如Physical Intelligence、Figure AI和Sunday Robotics正积极转向此方向。通过将强化学习与去中心化、以自我为中心(第一人称)视频收集相结合,它们旨在绕过繁重的远程操作。像苹果的EgoDex和NVIDIA的EgoScale等项目正是为此:从海量、低成本的人类视频中提取高信号、可用的行动数据。
1
15
May 21
没有哪个成功模型会只依赖单一层。但只有底层能转动数据飞轮——它是唯一成本足够低、能从部署循环中学习的一层。谁能破解消费级结构化人类视频的难题,谁就能悄然为所有上层的类人机器人提供动力。
13
May 20
AI训练数据没有版税制度。
这对实验室来说是个特色,对其他人来说是个缺陷。
一条关于Codatta为何构建版税引擎——以及它带来什么改变的帖子。🧵
1
30
May 20
给建造者的福利:先训练后付款。
现在就用数据集。从未来收入中支付。版税引擎自动累积债务并在资金到账时结算——双方都能核对的收据。
零前期摩擦。没有“先信我们,分成以后再说”。
1
18
May 20
对于贡献者:每一美元都溯本求源。
数据集版本 → 资产 → 贡献指纹 → 你。没有追溯修改,没有不透明的算法。如果争议改变了输入,变更会被记录,并且报酬会重新计算。
这才是AI的版税系统应该有的样子。
docs.codatta.io/en/core-syst…
30