
Joined November 2023
- Tweets 438
- Following 4,566
- Followers 1,502
- Likes 547
54 Photos and videos















Your AI companion should feel like yours. Not generic. Not robotic.
That's why we built Popia.
A companion that texts you first. Remembers your stories. Bonds with you like no other AI can.
Download for FREE on iOS & Android.
Official Website: popia.app/

1
1
41
Come and join us this Thursday! 'Vibe selling 101'!
luma.com/yjhld7ps
May 19

This Thursday evening! Come with us and learn about vibe selling
145
AI agents are moving fast, and SF is still where many of the best conversations happen.
On May 8, we co-hosted an AI Agent Builders event in San Francisco — bringing together founders, builders, and investors across the agent stack for real conversations and high-signal networking. Our head of growth @laura_llin also provided a talk about our fresh progress
Some of the sharpest discussions of the night centered on where the agent stack goes next: orchestration, memory, evals, and what "production-ready" actually means for agents in the wild.
Huge thanks to our co-hosts @CreaoAI, @GoKiteAI, @YottaLabs, and @kuseHQ, and to our event partners @gptdaoglobal and everyone who showed up.
More conversations, collaborations, and builder energy ahead. 🚀
May 11

AI Agent is moving fast, and SF is still where many of the best conversations happen.
On May 8, we organized an AI Agent Builders event in San Francisco 🌉 The evening brought together founders, builders, and investors across the agent stack for real conversations and high-signal networking.
There were lots of insightful discussions around where the agent stack was heading next. Always exciting to see so many talented people building in the space 🤝
Big thanks to co-hosts @CreaoAI @GoKiteAI @YottaLabs @kuseHQ , fellow event partners @CollovLabs @gptdaoglobal , and everyone who joined us that night.
More conversations, collaborations, and builder energy ahead.


1
1
6
1,331
Neweyes AI (by Collov Labs) retweeted

May 11
AI Agent is moving fast, and SF is still where many of the best conversations happen.
On May 8, we organized an AI Agent Builders event in San Francisco 🌉 The evening brought together founders, builders, and investors across the agent stack for real conversations and high-signal networking.
There were lots of insightful discussions around where the agent stack was heading next. Always exciting to see so many talented people building in the space 🤝
Big thanks to co-hosts @CreaoAI @GoKiteAI @YottaLabs @kuseHQ , fellow event partners @CollovLabs @gptdaoglobal , and everyone who joined us that night.
More conversations, collaborations, and builder energy ahead.
3
3
11
1,574
We are co-hosting ai agent builder event this Friday, come and stop by!
May 5
⭐️We’re co-hosting an AI Agent Builders event on May 8th in San Francisco!
We welcome AI Agent builders, founders, and investors across the stack to explore what’s next.
Don't miss:
- Real conversations
- High-signal networking
- Fresh perspectives on the agent stack
Co-hosts
@CreaoAI @GoKiteAI @YottaLabs @kuseHQ
Event partners
@JELabs2024 @CollovLabs @gptdaoglobal
Spots are limited
See you there
👉luma.com/5kkofx7o

1
179
We are happy to announce $23M Series A.
Collov Labs is betting on Visual AI as the next interface — for the 6.8 billion people who've never used AI because text was never the answer.
The lab came out of what we saw building our products. People who struggled to write prompts would point their phone at a room and just get it. Real estate agents. Small business owners. First-time AI users. Visual removed friction that text never could.
The milestones so far: → 1M users worldwide → ~1,000 five-star App Store ratings → Covered the same day by @FortuneMagazine , @axios , @theinformation , @pulse2news, and @UniteAi
Led by @MindWorksCap , Taihill Ventures, Brightway Future Capital, and others.
The next interface will be the camera. This is just the beginning.
— Collov Labs, San Francisco
#fundingannouncement #silliconvalley #collovlabs
2
6
491
Last night felt special. 🧧✨
@CollovLabs hosted another intimate founder & exec gathering — co-hosted by our Head of Growth @laura_llin and Gavin (@N) Llama Venture
In the middle of AI agent chaos, model launches, and nonstop hype… we chose to sit down and talk long-term.
Thank you @cmigos , Jinjin, @ZiqiPeng Kelly, Qinming, @4lili_lili4 Chris, @jayfunggy for making the room sharp, honest, and generous. 🤝
We talked about:
• Real AI agent progress (not Twitter demos 🚀)
• What OpenClaw changes in the ecosystem
• How founders stay grounded while everything accelerates ⚡
#ChineseNewYear is about reunion and momentum reset. 🏮
AI is competitive. Brutal sometimes.
But nights like this remind me — we’re building an ecosystem, not just products.
Wishing everyone clarity, courage, and compounding breakthroughs this year. 🥂
3
612
This framing — optimizing for a family of models rather than a single checkpoint — feels underappreciated.
The fact that nanochat recovers clean Chinchilla-style exponents (≈0.5 / 0.5) at such small scale is especially encouraging. It suggests scaling laws are structural, not an artifact of massive budgets.
Jan 7

New post: nanochat miniseries v1
The correct way to think about LLMs is that you are not optimizing for a single specific model but for a family models controlled by a single dial (the compute you wish to spend) to achieve monotonically better results. This allows you to do careful science of scaling laws and ultimately this is what gives you the confidence that when you pay for "the big run", the extrapolation will work and your money will be well spent. For the first public release of nanochat my focus was on end-to-end pipeline that runs the whole LLM pipeline with all of its stages. Now after YOLOing a few runs earlier, I'm coming back around to flesh out some of the parts that I sped through, starting of course with pretraining, which is both computationally heavy and critical as the foundation of intelligence and knowledge in these models.
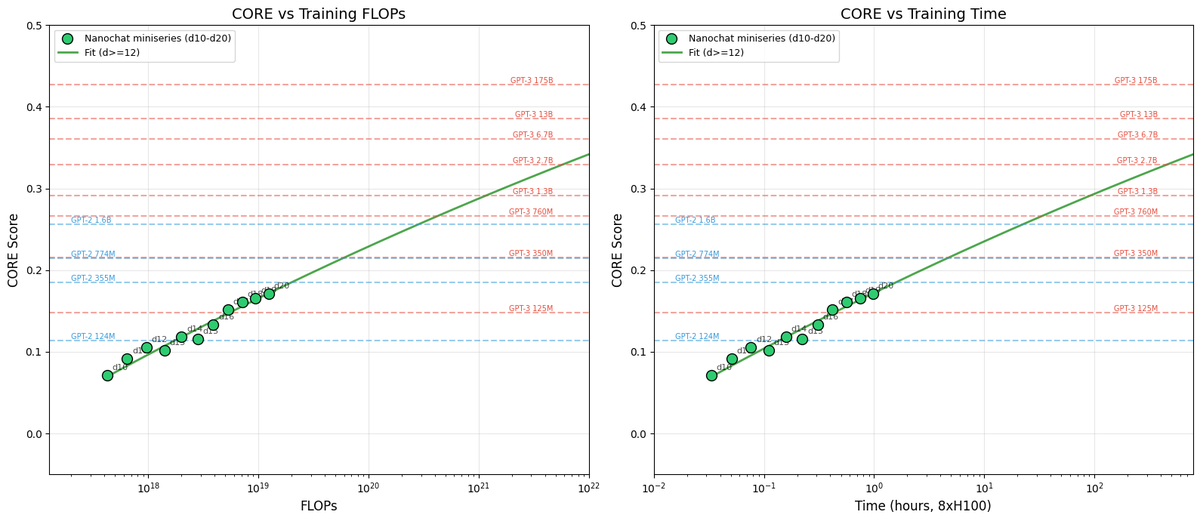
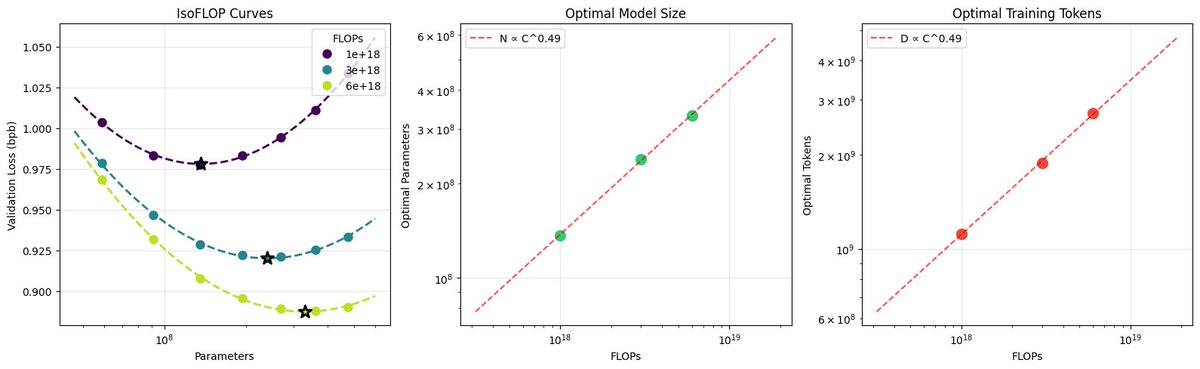
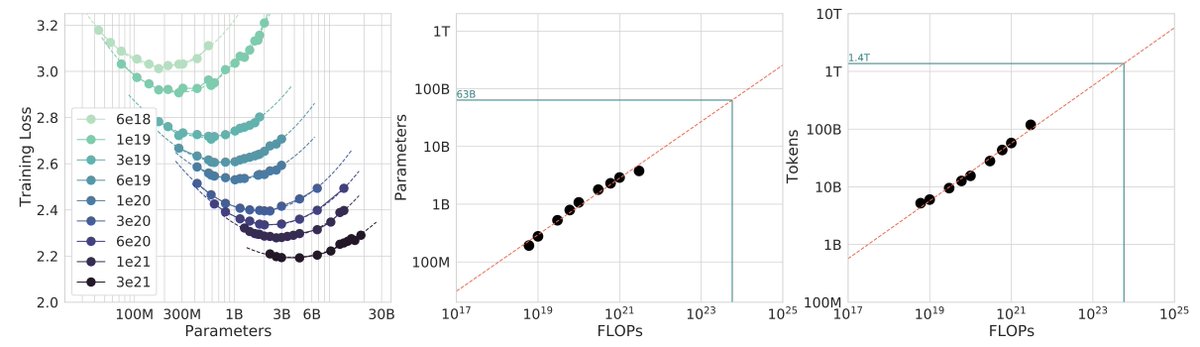
After locally tuning some of the hyperparameters, I swept out a number of models fixing the FLOPs budget. (For every FLOPs target you can train a small model a long time, or a big model for a short time.) It turns out that nanochat obeys very nice scaling laws, basically reproducing the Chinchilla paper plots:
Which is just a baby version of this plot from Chinchilla:
Very importantly and encouragingly, the exponent on N (parameters) and D (tokens) is equal at ~=0.5, so just like Chinchilla we get a single (compute-independent) constant that relates the model size to token training horizons. In Chinchilla, this was measured to be 20. In nanochat it seems to be 8!
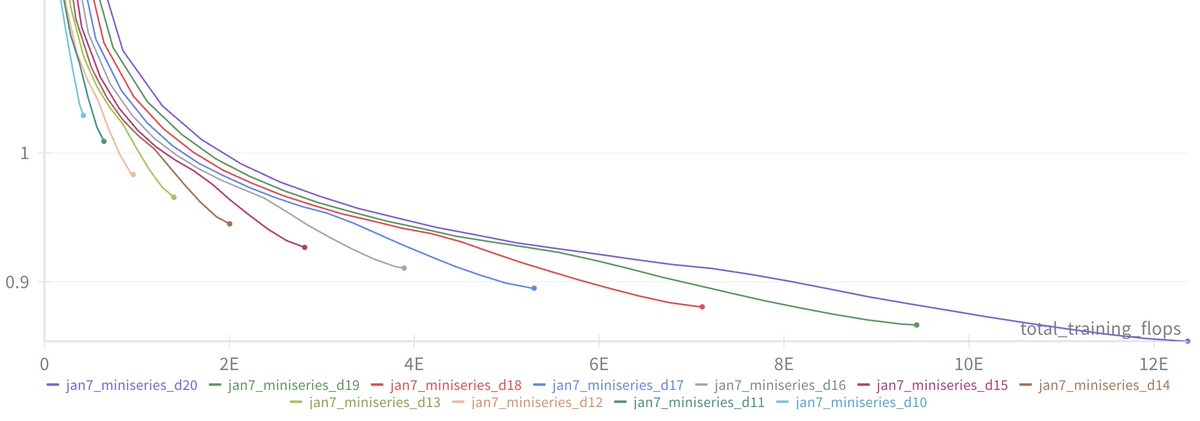
Once we can train compute optimal models, I swept out a miniseries from d10 to d20, which are nanochat sizes that can do 2**19 ~= 0.5M batch sizes on 8XH100 node without gradient accumulation. We get pretty, non-itersecting training plots for each model size.
Then the fun part is relating this miniseries v1 to the GPT-2 and GPT-3 miniseries so that we know we're on the right track. Validation loss has many issues and is not comparable, so instead I use the CORE score (from DCLM paper). I calculated it for GPT-2 and estimated it for GPT-3, which allows us to finally put nanochat nicely and on the same scale:
The total cost of this miniseries is only ~$100 (~4 hours on 8XH100). These experiments give us confidence that everything is working fairly nicely and that if we pay more (turn the dial), we get increasingly better models.
TLDR: we can train compute optimal miniseries and relate them to GPT-2/3 via objective CORE scores, but further improvements are desirable and needed. E.g., matching GPT-2 currently needs ~$500, but imo should be possible to do <$100 with more work.
Full post with a lot more detail is here:
github.com/karpathy/nanochat…
And all of the tuning and code is pushed to master and people can reproduce these with scaling_laws .sh and miniseries .sh bash scripts.
1
492
Neweyes AI (by Collov Labs) retweeted

Jan 7
New post: nanochat miniseries v1
The correct way to think about LLMs is that you are not optimizing for a single specific model but for a family models controlled by a single dial (the compute you wish to spend) to achieve monotonically better results. This allows you to do careful science of scaling laws and ultimately this is what gives you the confidence that when you pay for "the big run", the extrapolation will work and your money will be well spent. For the first public release of nanochat my focus was on end-to-end pipeline that runs the whole LLM pipeline with all of its stages. Now after YOLOing a few runs earlier, I'm coming back around to flesh out some of the parts that I sped through, starting of course with pretraining, which is both computationally heavy and critical as the foundation of intelligence and knowledge in these models.
After locally tuning some of the hyperparameters, I swept out a number of models fixing the FLOPs budget. (For every FLOPs target you can train a small model a long time, or a big model for a short time.) It turns out that nanochat obeys very nice scaling laws, basically reproducing the Chinchilla paper plots:
Which is just a baby version of this plot from Chinchilla:
Very importantly and encouragingly, the exponent on N (parameters) and D (tokens) is equal at ~=0.5, so just like Chinchilla we get a single (compute-independent) constant that relates the model size to token training horizons. In Chinchilla, this was measured to be 20. In nanochat it seems to be 8!
Once we can train compute optimal models, I swept out a miniseries from d10 to d20, which are nanochat sizes that can do 2**19 ~= 0.5M batch sizes on 8XH100 node without gradient accumulation. We get pretty, non-itersecting training plots for each model size.
Then the fun part is relating this miniseries v1 to the GPT-2 and GPT-3 miniseries so that we know we're on the right track. Validation loss has many issues and is not comparable, so instead I use the CORE score (from DCLM paper). I calculated it for GPT-2 and estimated it for GPT-3, which allows us to finally put nanochat nicely and on the same scale:
The total cost of this miniseries is only ~$100 (~4 hours on 8XH100). These experiments give us confidence that everything is working fairly nicely and that if we pay more (turn the dial), we get increasingly better models.
TLDR: we can train compute optimal miniseries and relate them to GPT-2/3 via objective CORE scores, but further improvements are desirable and needed. E.g., matching GPT-2 currently needs ~$500, but imo should be possible to do <$100 with more work.
Full post with a lot more detail is here:
github.com/karpathy/nanochat…
And all of the tuning and code is pushed to master and people can reproduce these with scaling_laws .sh and miniseries .sh bash scripts.
226
672
5,411
712,534
World model ≠ next-token prediction
A “world model” isn’t a bigger sequence model that predicts the next frame/token. It’s a latent state machine: it must compress observations into a state that persists, and it must learn dynamics that are stable enough to roll forward under actions.
2
2
2
480
This is why we're excited about the recent JEPA line of thinking: instead of reconstructing pixels, you predict representations of missing regions. I-JEPA framed this cleanly for images (predict target-block embeddings from a context block, with masking strategies that force semantic abstractions).
1
1
163
On the video side, V-JEPA 2 pushes the same principle toward physical prediction planning, mixing internet-scale video with a small amount of interaction data to get models that start to act, not just recognize.
Ref: arxiv.org/abs/2301.08243
arxiv.org/abs/2506.09985
2
137

16 Dec 2025
🚀 Today we’re launching the @collov_ai Design Center —the world’s first interior design AI agent built for #realestate.
Not a tool.
Not a filter.
An AI agent that understands space, style, and intent.
23
6
42
7,030
16 Dec 2025
2
402
16 Dec 2025
@collov_ai #collovAI now serves millions of users worldwide —
from solo agents to large brokerages.
⏱️ Hours → seconds
🔁 Revisions → one command
👥 Design teams → one AI agent
This is real-world AI at scale.
1
396
16 Dec 2025
We didn’t build Design Center to make design prettier.
We built it to make 🏠 real estate move faster.
🚀 Faster listings
👁️ Clearer visualization
📊 Better decisions
Welcome to the Collov AI Design Center.
Real estate visuals, reimagined.
353
23 Nov 2024
#CREtech2024 in New York City was successfully completed last week! The event was a remarkable gathering of thought leaders, innovators, and industry professionals dedicated to revolutionizing the real estate and construction sectors with cutting-edge technology.
#CollovAI was honored to showcase how our advanced #spatialdesignintelligence is transforming workflows across real estate and interior design. From enabling dynamic, real-time spatial reasoning to streamlining design proposals for clients, our solutions sparked significant interest and enthusiasm among attendees.
Our keynote speech was incredibly inspiring, highlighting the immense potential of AI-driven innovation to reshape the future of spaces. We were excited to see the industry’s strong recognition of our vision and technology.
We are eager to expand our network of partners and collaborate with forward-thinking companies ready to embrace the future of spatial design and real estate technology.
🫶Let’s work together to bring smarter, more efficient, and visually stunning solutions to the market!If you’re interested in partnering with us, reach out—we’d love to explore opportunities to drive innovation together!
#NYC #RealEstate #CollovAI



4
381