
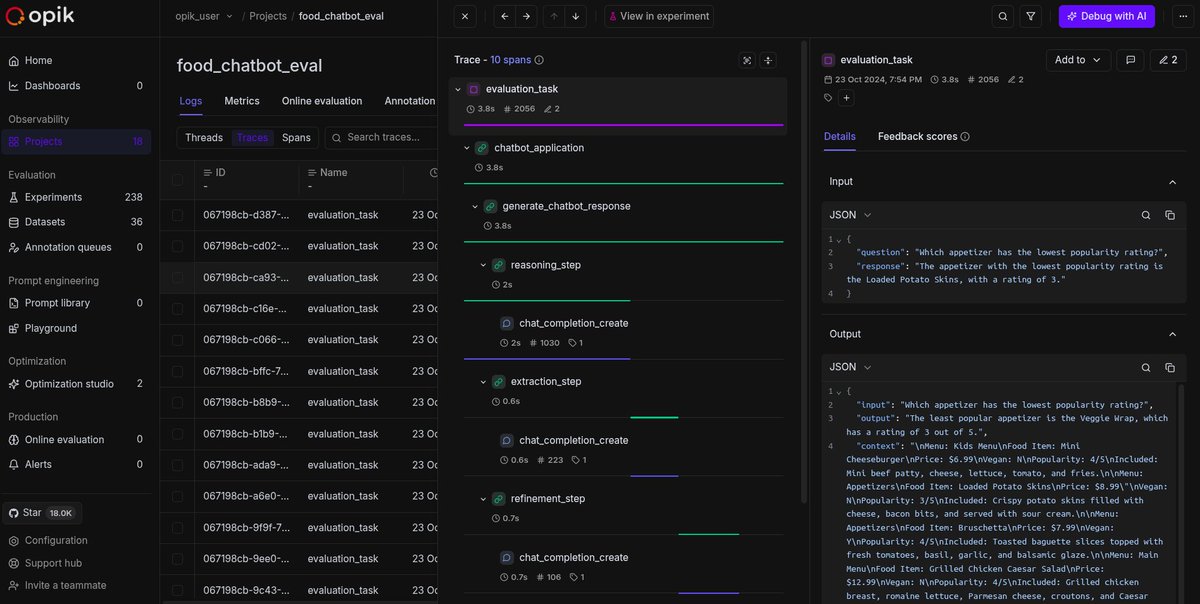
Comet provides an end-to-end model evaluation platform for AI developers, with best in class LLM evaluations, experiment tracking, and production monitoring
Joined October 2017
- Tweets 3,487
- Following 879
- Followers 15,053
- Likes 2,260
832 Photos and videos











You're spending ~30% of your coding agent tokens on misconfiguration. Bloated context, unused skills, idle MCPs.
We just launched Cost Intelligence in Opik — cuts that waste 20-30% with one click. Native to Claude Code Codex
🔗globenewswire.com/news-relea…
182
Comet retweeted

May 21
AI agent debugging is a COMPLETE mess right now.
You fix one issue…
and another workflow randomly breaks.
You change a prompt.
Tool calls start behaving differently.
You improve latency.
Accuracy drops somewhere else.
Most teams are basically duct taping evals, traces, prompts, scripts, and observability together hoping nothing explodes.
That’s why the new direction from Comet Opik feels important.
Comet Opik just dropped two features that feel like a HUGE leap for agent workflows:
• Test Suites
• Ollie
1] Test Suites
That “fix one thing, break another” problem?
This is the answer.
Every real failure you hit becomes a permanent test case with plain-English rules.
So when you tweak that prompt and tool calls start misbehaving, you catch it BEFORE it ships.
No giant eval dataset to build upfront.
And no more arguing whether 0.84 is better than 0.81.
You just get pass/fail on the scenarios that actually matter for your agent.
2] Ollie
And this is the CRAZY part.
A coding agent with full access to:
• your traces
• project history
• agent behavior inside Opik
That latency vs accuracy tradeoff you're constantly fighting?
Ollie sees both.
It diagnoses from your real traces, writes the fix in your code, AND generates a regression test so the same tradeoff doesn't bite you twice.
So instead of:
spot issue → switch tools → debug manually → write fix → create test separately → pray
…the entire loop closes inside one platform.
Find the problem.
Write the fix.
Generate the regression test.
All connected.
This is the first time I’ve seen an agent stack that actually feels built for iteration instead of chaos.
The teams with the fastest feedback loops are going to dominate this space.
Try Opik here:
comet.com/signup?utm_source=…
#AIAgents #AgenticAI #GenerativeAI #RAG #EnterpriseAI
14
16
71
842
Our Head of Research Doug Blank headed to Boston for his 3rd annual talk at @MITDeepLearning.
He took Asimov's laws of robotics & applied them to agentic AI -- proposing his own three laws of AI and sharing how we're thinking about AI safety at Comet.
youtube.com/watch?v=XKOpA7ia…
1
2
439
We're hiring across the team 🎉
If you know any rockstars (or are one yourself), we'd love to chat with you!
🔗 comet.com/site/about-us/care…
2
240
Comet retweeted

May 6
I just interviewed the former CTO at IBM and Chairperson of NodeJS.
Here's what I learned:
Michael @maximilien spent 12 months shipping production RAG to multiple customers.
In our discussion, he told me that nothing on a leaderboard can predict what works until you evaluate your customers' data.
Which I found interesting because...
Most teams treat RAG like a setup task.
Pick a vector database.
Pick OpenAI embeddings.
Ship it.
Then spend months “vibe-checking” results.
But production RAG doesn’t work like that.
It's more of an iteration loop rather than a setup problem.
Stitch → evaluate → iterate
A real system has multiple moving parts.
You don’t pick one...
You swap and measure each one.
Here’s what that looks like in practice:
1. Build a small eval set from real user questions
2. Build your evaluator (e.g., LLM Judge) against that dataset
3. Align your evaluator with human feedback (before trusting scores)
4. Iterate cheapest-first (retrieval → embeddings → infra)
To make this work, you also need visibility across runs.
This is where tools like Opik by @Cometml come in...
Tracking each experiment so you can compare models, configs, and results over time.
But most teams refuse to do this because it's extremely cumbersome.
• Re-ingestion takes time
• Pipelines break
• Comparisons become unreliable
So people default to benchmarks instead.
But that doesn't mean it's better.
On a real customer dataset (auction listings), Michael @maximilien swapped only the embedding model.
An open-source model ranked #130 on MTEB beat OpenAI:
• 11% quality
• 240x faster re-embedding
• 50% smaller vectors
• $0 cost
Here's the gist...
RAG is not about picking the best tools.
It’s about measuring what works for your data.
Until you do that…
You’re just guessing.
Full interview and breakdown here: decodingai.com/p/ship-rag-wi…
3
4
19
674
"Until you evaluate on your data, nothing else matters."
May 1

I’ve spent the last week interviewing @maximilien, former CTO at IBM and Chairperson of NodeJS Foundation, who has shipped production RAG to multiple customers over the past year. The lesson he kept circling back to is that until you evaluate on your customer’s data, nothing else you do matters.
Production RAG is a loop: stitch your embedding model, chunking, retrieval, vector DB, and judge, then evaluate and iterate until you hit your customer’s metrics. Public benchmarks and the MTEB leaderboard are signals, not verdicts.
On a real customer dataset of Leica auction listings, an open-source sentence-transformer that ranked around #130 on MTEB still beat OpenAI by 11% in quality. It ran 240x faster, produced 50% smaller vectors, and cost $0.

1
1
665

As your agent matures, something shifts.
You stop writing code, and start editing prompts, tweaking params, trying new tools, etc.
The tooling for this phase sucks. Today, we’re fixing that.
Announcing Agent Configuration Agent Playground in Opik. 🧵

3
9
28
28,753

We're launching the Agent Playground so you can test your full agent configuration from the UI.
Tweak prompts and swap models without touching your code. See how the entire agent responds and only save what works.
comet.com/site/blog/end-to-e…
124
It’s his first week in the office so say hi if you see him around 👋
Research preview available in the Opik Cloud. Sign up for early access:
comet.com/site/products/opik…
2
143
The big idea with Test Suites is that agents need comprehensive regression tests, built on nuanced assertions and real production traces.
This is how you improve your agent for one user without damaging it for 3 others, as explained by @JacquesVerre youtube.com/watch?v=lt5iQ-gg…
1
3
19
571
Your suite grows as you build. Every failure you catch becomes a test case. Each failed test tells you what needs to be fixed.
Available in the open-source instance. Take a first look: comet.com/site/blog/ai-agent…
3
146
Great start to the week at @aiDotEngineer London! We'll be around all day tomorrow if you want to meet the team.
Catch @vincent_koc tomorrow giving a talk on the future of evals or pop by the booth to grab an Ollie and say hello🦉


1
4
329