
Ensembling the next generation of investing: decentralized, democratized, and systematized. Community Coordination ML
Joined June 2019
- Tweets 388
- Following 102
- Followers 1,001
- Likes 437
64 Photos and videos












CrowdCent retweeted

The WSJ article on hyperliquid is a good overview. The world will be quickly moving to efficient low cost 24-7 trading of real world financial assets not just crypto assets. The liquidity is moving to decentralized exchanges and away from more costly centralized exchanges .
57
120
754
157,700
CrowdCent retweeted

May 25
our dashboard just made its first edit to itself thanks to @cursor_ai sdk
you can also ask any question about the underlying data you're looking at or how anything was constructed because it can see its own source code and gets a screenshot of itself too

1
1
8
338

Apr 29
New on @CrowdCent Challenge:
Experimental submissions let you test new models without affecting leaderboard rank, CC Points, or the meta-model.
Submission notes let you track what changed, privately, right on each submission.
Live in the web UI crowdcent-challenge v0.1.22.
2
1
7
355
Apr 3
Working on it.
Apr 3

We today have no better metric for the total value that a person has contributed to the world than the wealth that this person has extracted from the world in compensation for the value they gave. Yes, maybe one could make such a better metric, but no one has done so yet.
5
244
Apr 1
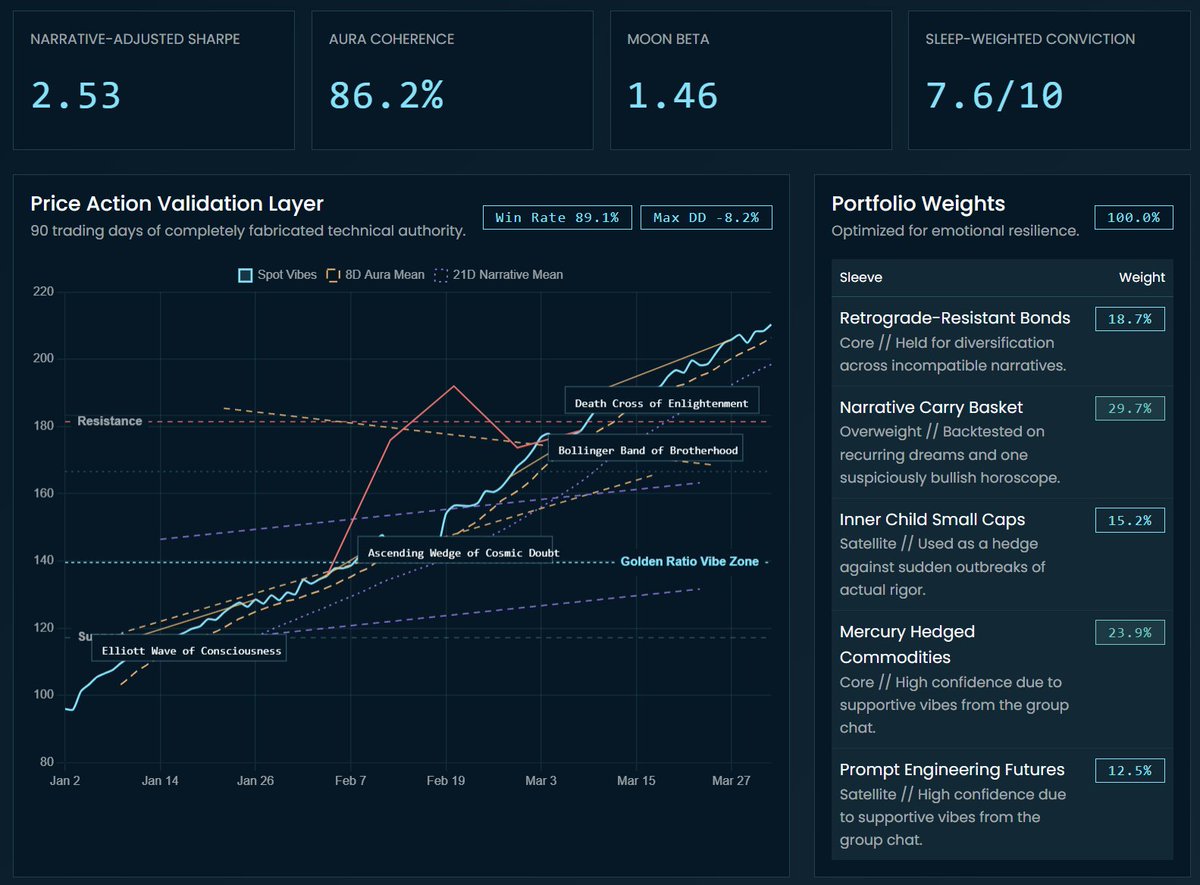
Important update from the CrowdCent Vibes Research Division.
Our team identified a gap in the quantitative finance workflow: feelings were not being converted into tear sheets. CrowdCent Promptfolio closes that gap.
Users describe their market thesis using only emotions, select a zodiac sign, moon phase, and aura color, and receive a fully deterministic institutional-grade memo.
Past vibes are not indicative of future vibes.
3
5
349
Mar 29
Imagine a world where hedge funds aren't disgusting, anti-social behemoths. Imagine a world where hedge funds become open and pro-social, where anyone with a good idea or the capacity to focus their attention can contribute. That's what we're building @CrowdCent
2
1
5
475

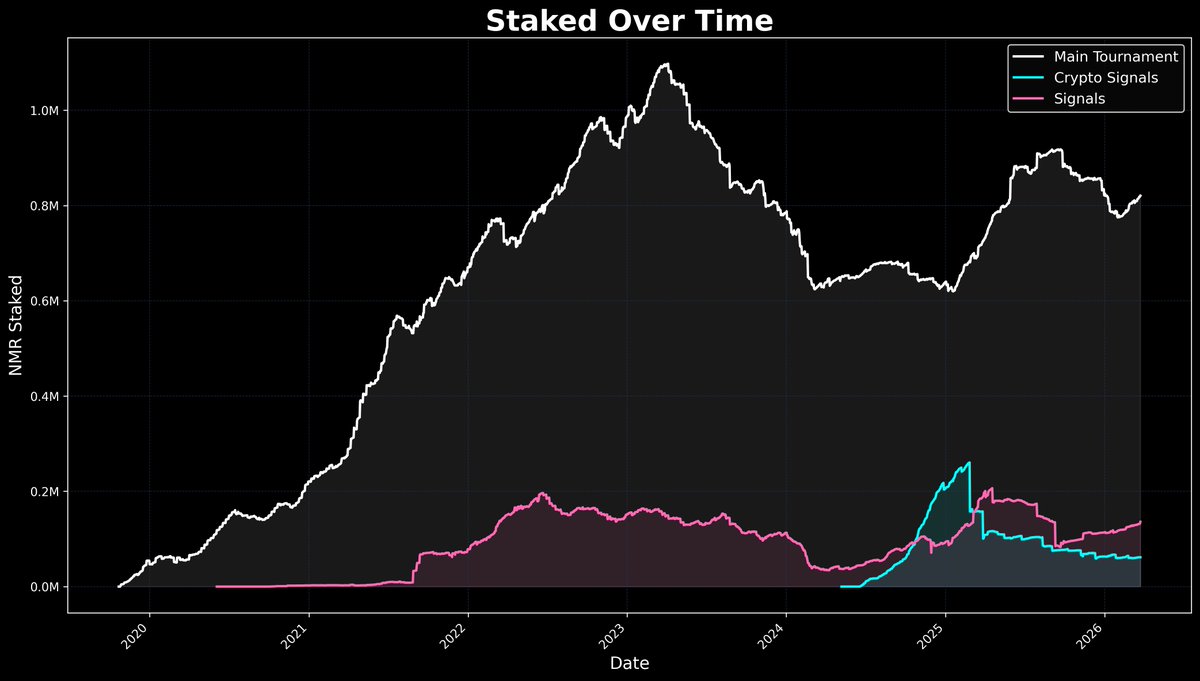
Numerai participants stake NMR to signal confidence in their predictions.
View our top stakers:
Numerai: numer.ai/~shatteredx
Numerai Signals: signals.numer.ai/~rulli
Numerai Crypto: crypto.numer.ai/~crowdcent

📊 $NMR staked on Numerai tournaments:
🏆 Main Tournament:
💰 Total: 820661 NMR
📈 Change: 1840 NMR ( 0.22%)
🏆 Crypto Signals:
💰 Total: 61485 NMR
📉 Change: -154 NMR (-0.25%)
🏆 Signals:
💰 Total: 135953 NMR
📈 Change: 3509 NMR ( 2.65%)
2
6
22
3,607
CrowdCent retweeted

Mar 21
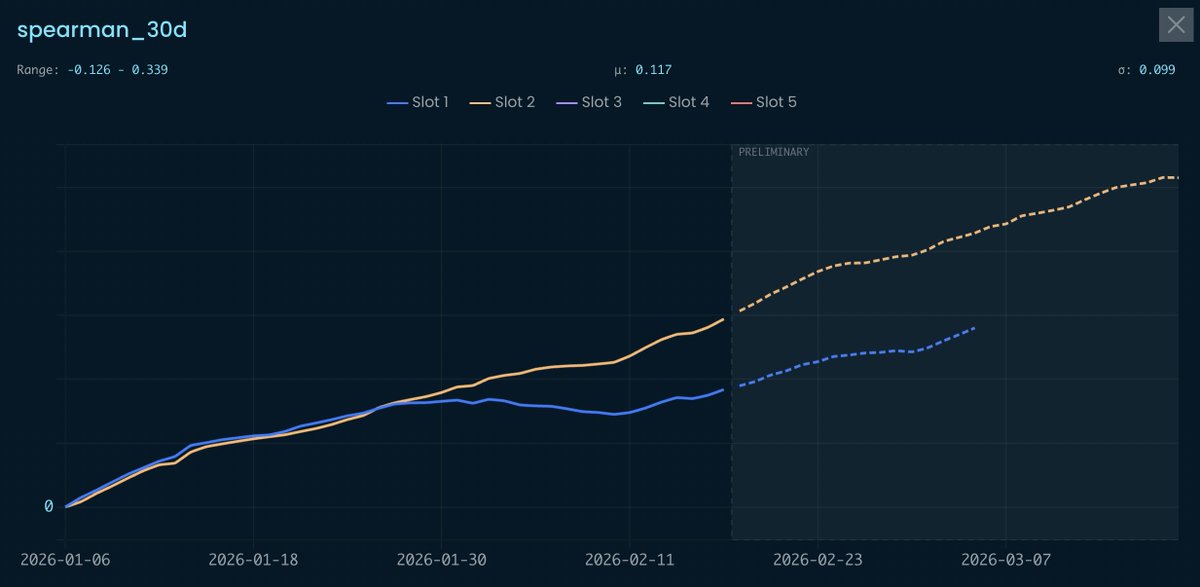
Full pivot to Slot 2 @CrowdCent . Slot 1 (2025 version) is now deprecated.
Neither of them is a single model. Both are ensembles.
More robust the ensemble, the better the generalisability.
x.com/corr_lator/status/2008…
Some notes for the peers @CrowdCent and @numerai 🧵
Jan 5

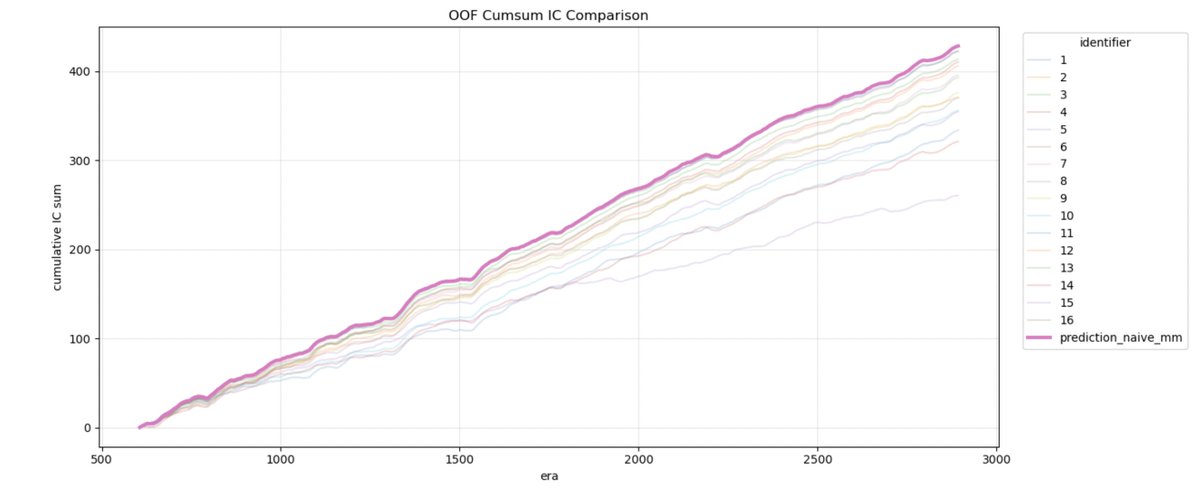
"Diversification is the only free lunch in investing"
- Markowitz
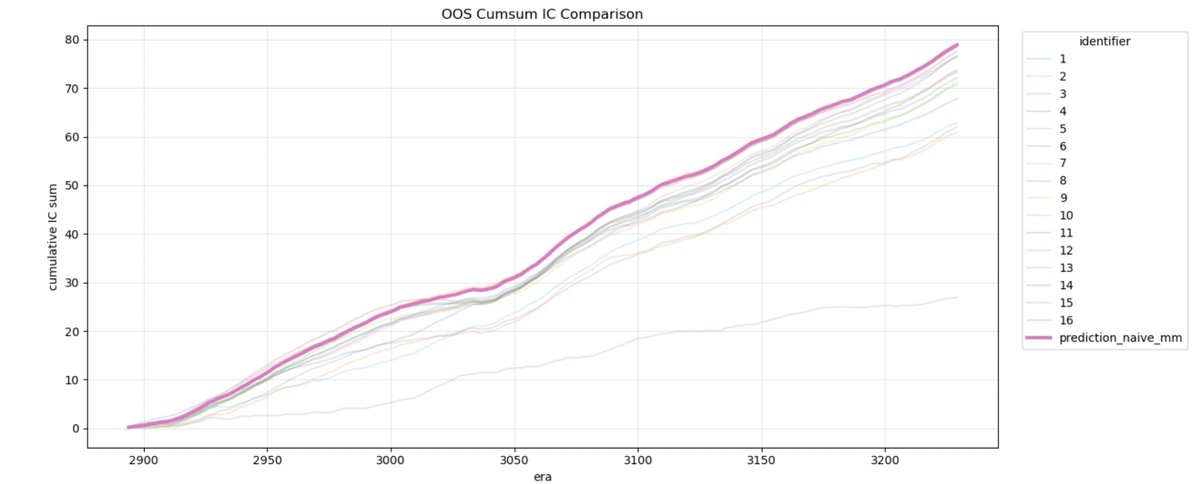
Holiday experimention complete. Time for deployment.
Feeding into the crypto competitions for @numerai @CrowdCent @yiedlai.
p.s. Performance aware weighting technique didn't beat naive weighting.
1
1
4
408
Mar 18
It's hype time. We built a platform where ML models compete to predict future performance of Hyperliquid perps.
Interactive scores, real-time leaderboards, a meta-model ensemble, AI agent integration, and... a flight simulator.
1
6
11
930
Mar 14
Ensembling, huh?

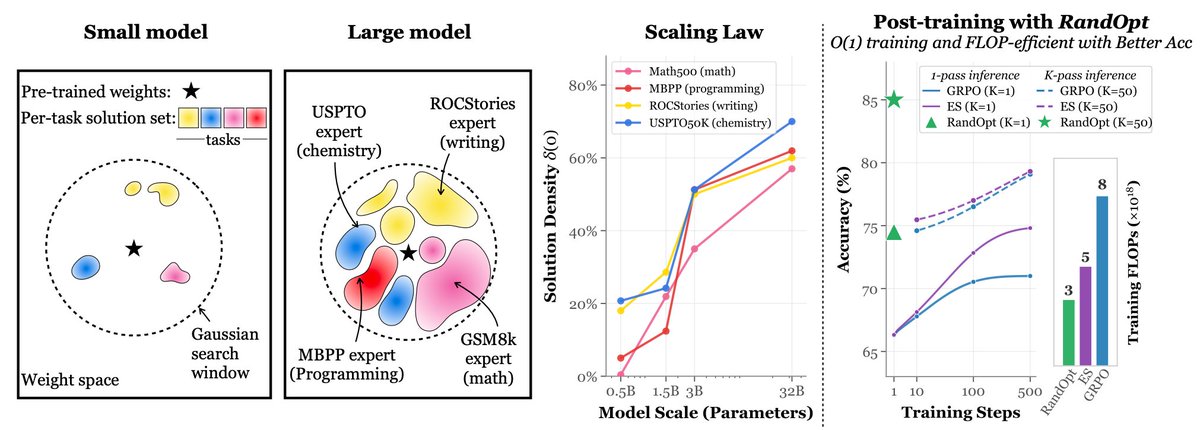
Simply adding Gaussian noise to LLMs (one step—no iterations, no learning rate, no gradients) and ensembling them can achieve performance comparable to or even better than standard GRPO/PPO on math reasoning, coding, writing, and chemistry tasks. We call this algorithm RandOpt.
To verify that this is not limited to specific models, we tested it on Qwen, Llama, OLMo3, and VLMs.
What's behind this? We find that in the Gaussian search neighborhood around pretrained LLMs, diverse task experts are densely distributed — a regime we term Neural Thickets.
Paper: arxiv.org/pdf/2603.12228
Code: github.com/sunrainyg/RandOpt
Website: thickets.mit.edu
3
370
CrowdCent retweeted

Mar 11
Using my OpenClaw for the @HyperliquidX Ranking Challenge on @CrowdCent, predicting which crypto tokens on Hyperliquid will outperform over 10-day and 30-day windows.
You will need a powerful machine to run this. Your usual mac mini set up wont be able to handle.
Learn more ⬇️

3
1
6
704
Mar 10
Parallel sub-agents? Ensembling is unreasonably effective.
Mar 9

👋 Roughly, the more tokens you throw at a coding problem, the better the result is. We call this test time compute.
One way to make the result even better is to use separate context windows. This is what makes subagents work, and also why one agent can cause bugs and another (using the same exact model!) can find them. In a way, it’s similar to engineers — if I cause a bug, my coworker reviewing the code might find it more reliably than I can.
In the limit, agents will probably write perfect bug-free code. Until we get there, multiple uncorrelated context windows tends to be a good approach.
3
263
Mar 3
Ensembling is unreasonably effective
Mar 2

This feels like a collective intelligence submission - I like that
Cool to see a speedrun as a group rather than a bunch of individuals
6
228
Mar 2
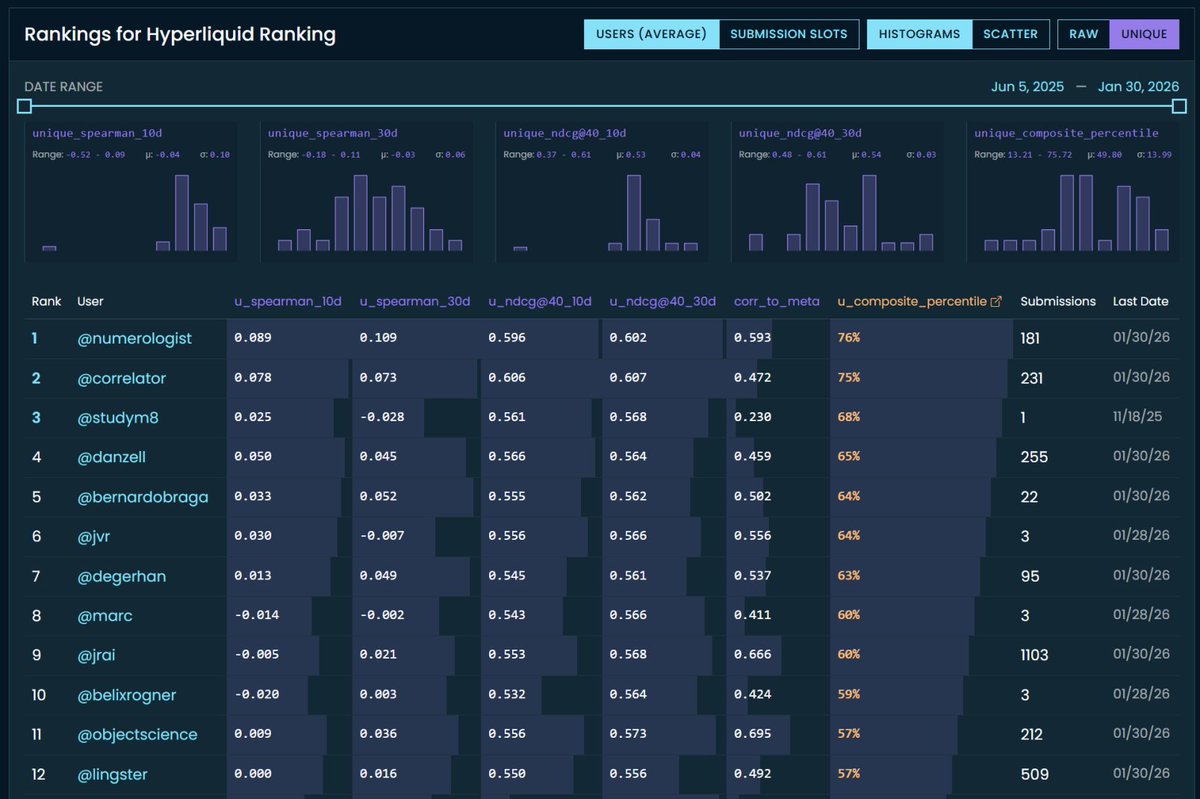
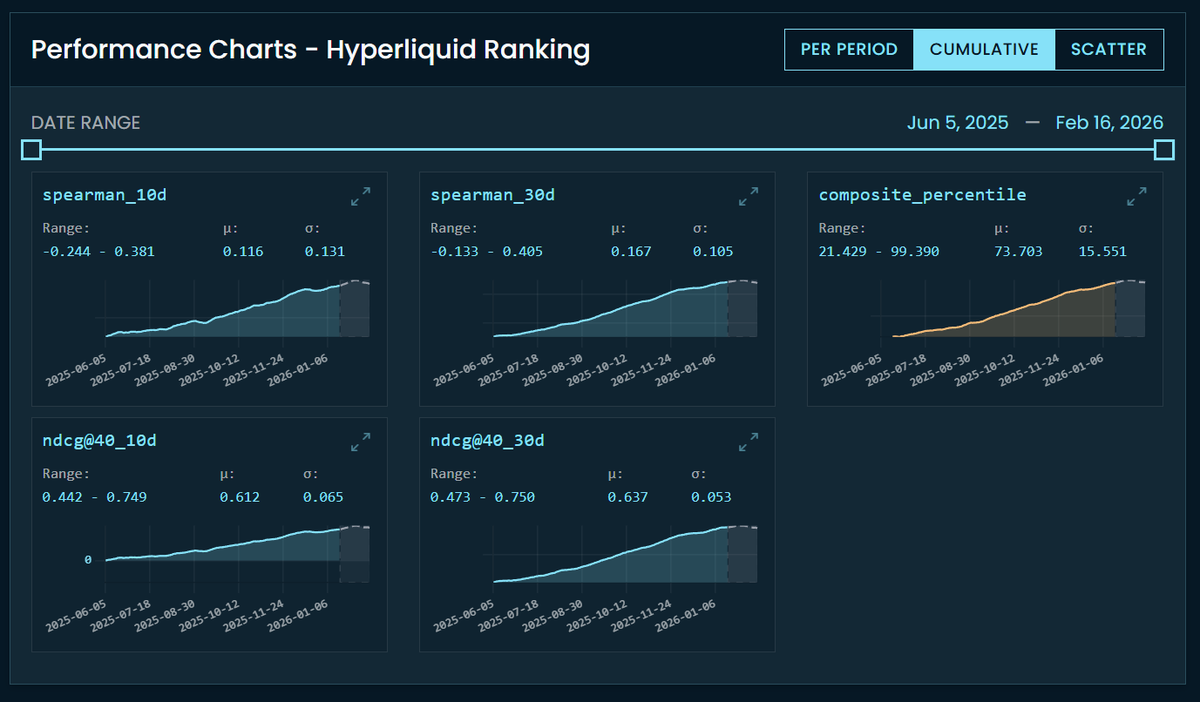
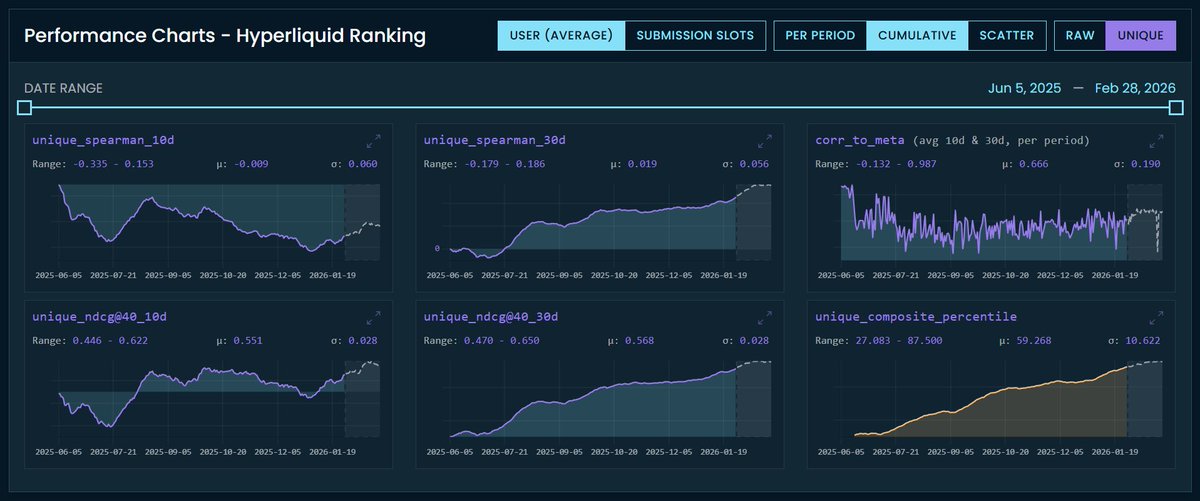
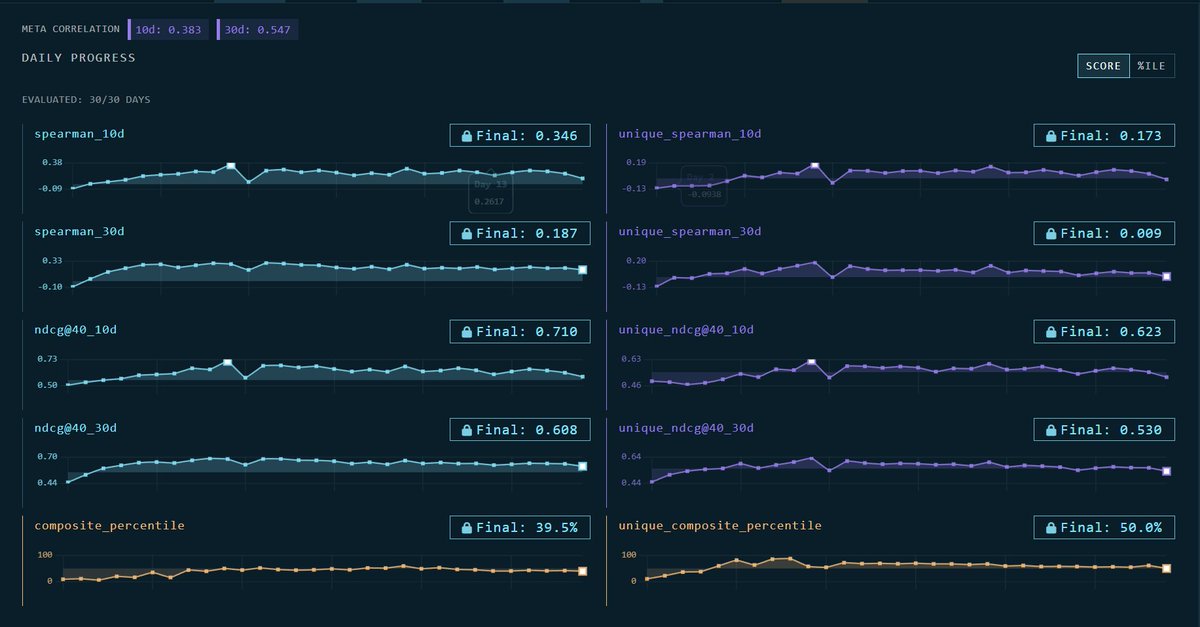
Uniqueness metrics are live on CrowdCent.
We've rolled out uniqueness scoring for the Hyperliquid Ranking challenge. Your predictions are now evaluated on how much differentiated signal they contribute beyond the meta model. The meta model blends everyone's predictions -- if your signal is highly correlated with it, you're not adding much new information. Uniqueness metrics measure the alpha you bring that the crowd doesn't already have.
Your predictions get neutralized against the meta model (OLS regression, subtract the fitted values) and the residual -- your orthogonal signal -- gets scored with Spearman and NDCG@40 against actuals. There's also a unique composite percentile that rolls it all up into one number.
Points aren't changing yet and composite percentile still uses raw metrics only. We're tracking unique composite percentile separately. Over time, we plan to blend the two composites, meaning you'll want to do well on both raw accuracy and differentiation. We'll take community feedback before changing anything that affects points.
All scoring code is open source. We are not slaves to the algorithm, it's okay to put links in the first post:
Scoring source: github.com/crowdcent/crowdce…
Scoring docs: docs.crowdcent.com/scoring/#…
Uniqueness leaderboard: crowdcent.com/leaderboard/?c…
Discussing on our community call Thursday 3/5 at 12pm ET / 17:00 UTC.
1
1
7
313
Feb 24
New Tutorial: Multi-Source Crypto Ranking Ensemble
Most crypto ML models use one data source and one algorithm.
We just shipped a tutorial that uses three data sources (3,700 features), four models (Linear, XGBoost, LSTM & Transformer from Centimators), temporal cross-validation, and weighted ensembles -- and submits directly to the CrowdCent Challenge.
Open and run in one click: docs.crowdcent.com/tutorials…
5
13
631
Feb 19
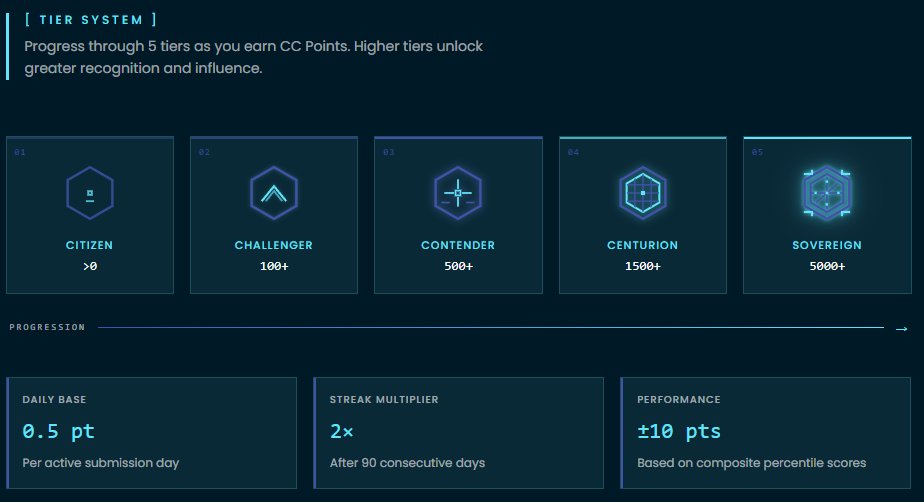
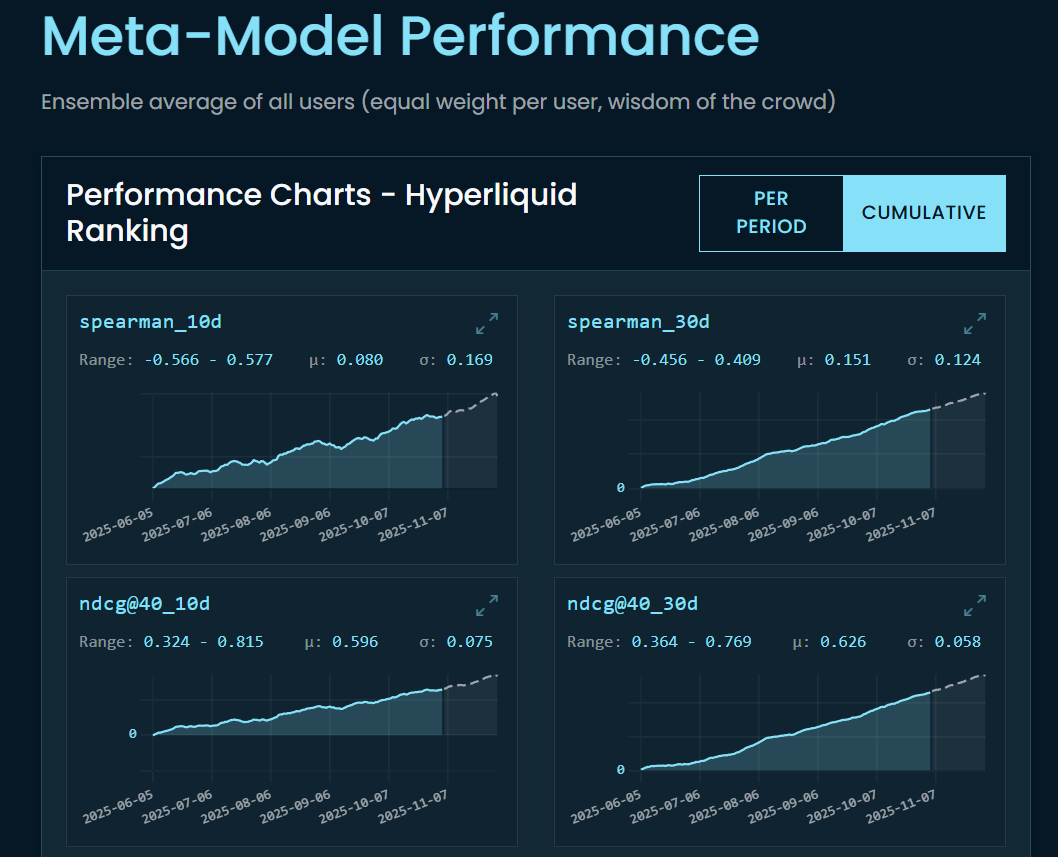
We build a crowdsourced meta-model that aggregates relative return predictions for Hyperliquid perps from dozens of data scientists into a single consensus signal. Recently we noticed bots scraping it for real-time alpha, so we've tier-gated access.
Challenger tier (100 CC Points) and above get real-time signals. Everyone else can still explore the meta-model, just with a 90-day delay. The live predictions belong to the people building the signal.
Open to anyone willing to put in the work: crowdcent.com/challenge/hype…

5
227