
AI Marketing Assistant
Joined February 2017
- Tweets 757
- Following 68
- Followers 2,945
- Likes 780
173 Photos and videos










Datagran retweeted

May 11
Ok, I am shaking a bit. I think this feels different.
For the past few weeks I’ve been experimenting combining three ideas:
1. @bchesky saying chat interfaces are not good enough
2. @karpathy’s Wiki LLM
3. @trq212 saying HTML is the new .md
The result is starting to feel like a new interface layer for agentic systems.
Not chat.
A workspace that builds itself as you use it in pure HTML.
It learns from you, adapts to the task, and visualizes what you need in real time.
I built this as another interaction layer in Groovy apart from WhatsApp, Telegram and the chat interface.
Check it out and see how it evolves. Feels different. Magical.
I want people to try it so I am giving away gogroovy.ai for free for the first 50 users. Sign up and dm me your email.
Also, this version will be up in the open source repo in 30 days github.com/Charlesmendez/gro…
2
1
404
Datagran retweeted
Mar 16
We need a new class of CRM that turns conversations into context.
A system that stores not only a person’s profile, but also their relationships and how those relationships formed.
Today I am launching persona360, an open source CLI based project that moves away from field based records and focuses on conversations.
Every interaction becomes a source of structured knowledge. Conversations are captured and translated into connections, context, and evolving information.
For example:
• Who introduced this person?
• How did I meet them?
• How did they arrive at my site?
If AI systems understand these relationships, they gain deeper context. That is how humans understand networks.
Persona360 is built around that idea.
• It turns real interactions into structured relationship intelligence.
• It updates contact and company context from conversations, not manual data entry.
• It helps manage who knows who, what matters, and what should happen next.
• It stores your network the way it actually works: connected, dynamic, and contextual.
github.com/Charlesmendez/per…
2
2
244
Datagran retweeted
Feb 23
I just couldn't take this happening to people anymore!
Today we are launching the most advanced memory layer as an OpenClaw plugin: github.com/datagran-auth/dat…
It combines several innovations to give your ClawBot true universal memory by mimicking how the human brain behaves:
- Short-term memory that uses compaction
- Mid-term memory that uses beacons
- Long-term memory that uses embeddings
- A weighted system for memory conflicts
It is free for now thanks to our friends at @modal.
Feb 23

Nothing humbles you like telling your OpenClaw “confirm before acting” and watching it speedrun deleting your inbox. I couldn’t stop it from my phone. I had to RUN to my Mac mini like I was defusing a bomb.



2
1
427
Datagran retweeted
Feb 21
Everyone is saying OpenClaw does not have a real use case.
Yesterday, I ran a 35 minute long running complex, end to end task for my trading activity since 2025, with cero intervention. Here was the prompt:
“In the Data agent, I have a stocks PostgreSQL database. In it, my trades table has a column called ‘Actual Cost’ that is empty for most rows. I need you to backfill that column starting in June 2025 using the attached file called ‘transactions since 2025’ to identify the correct transaction and cost using the Amount column. Then update ‘Actual Cost’ with that Amount value. Do not update any other column in PostgreSQL.
At the end, you need to give me a report with the total ROI for this month, this year, and from June to December 2025. They must match my P&L: this month is $xxxxx, this year is $xxxxx, and last year from June to December 2025 is $xxxxx.”
The catch is... people are right, I was not able to do it with OpenClaw. OpenClaw is a playground for nerds. That is why it is so popular here on X.
Debugging it and making it work gives you a dopamine hit and the illusion that you “built your own OpenClaw.”
Instead, gogroovy.ai did it in one shot. Below is the video at 20x speed
1
510
Datagran retweeted
Feb 15
AI agents are getting out of control. It is clear now that they need more control and context.
We can achieve this by building the framwork needed to operate safely and intelligently.
How?:
- Intelligence layer: OAuth that allows easy opt-in without needing to build apps.
- Tracing: Track every action the AI takes.
- Security: Control what the AI can do and ensure key encryption.
- Personas: Other AIs observing every call to detect potential security flaws or control messaging.
- Memory: Universal memory not just for context, but also enabling caching.
At @DataGran, we have been building this for months. If you want your @openclaw or gogroovy agents to securely operate with context, this is the correct way to do it. More info here datagran.io/intelligence
1
1
1
143
Datagran retweeted
Feb 14
Everyone's talking about OpenClaw's security disaster, 135,000 instances exposed on the open internet, API keys leaking, remote code execution on anyone's machine.
So the obvious question: does gogroovy.ai have the same problems?
I audited our own codebase against every OpenClaw vulnerability. Here's what I found.
🧵
1
2
3
245
Datagran retweeted
Feb 6
We’ve been working on an AI that actually does things. Basically the @openclaw alternative, but easier to install, way more powerful, and built for teams.
Features:
- Invite your team
- Integrates with data sources like Salesforce, Supabase, Meta, and many more
- Computer browser
- Creates and reads files
- Create different chats with different LLM providers
- Obsidian integration
- Code with Claude in a much nicer UI
1
2
10
1,347
Datagran retweeted
Feb 3
Introducing the MCP that’s not an MCP.
There are many new apps and services in the market that promise access to your data through AI.
I am a firm believer that OpenAI or Anthropic will eventually kill most of these solutions. The reason is simple: they own the models and the apps that should be able to fetch any source and produce any analysis on their own.
But there's a catch, I believe every major LLM provider has done this wrong by implementing MCP connectors. MCPs constrain models and ultimately force them to behave the way the SaaS layer wants.
That is why at Datagran we created the MCP that’s not an MCP.
When you connect Datagran’s MCP layer, what it actually does is give the LLM full power, via a proxy, to do whatever it wants with your connection. It provides instructions to the LLM about the proxy, but the model has full autonomy.
The benefits are:
- You are not SaaS-dependent if APIs change. No maintenance issues.
- You are not locked into predefined functions from vendor A or B.
Since agents have full autonomy, you can restrict the proxy or add observability by introducing other agents in the Datagran portal.
Below is a demo showing how this works with Gmail and Google Calendar. In this case, Claude is the one figuring out the code on the fly. Datagran only provides authentication and the proxy layer.
Curently there's more than 15 integrations including @firecrawl @Google @Meta @LinkedIn @tiktok_us @supabase @instagram and more.
1
325
Datagran retweeted
Jan 29
I’ve been working on memory for AI agents for a while now. I believe this will be one of the biggest unlocks if done well.
Currently, there are four ways to fetch memory in AI systems:
- RAG
- Prompt injection
- Beacon compression
- Compaction (what most IDEs use)
There is no single correct answer for which one to use. I strongly believe the solution is to use all of them, which is actually how the human brain works. Different areas of the brain manage different types of memory. For example, short-term memory is handled by the prefrontal and parietal cortex, while long-term memory is handled by the hippocampus.
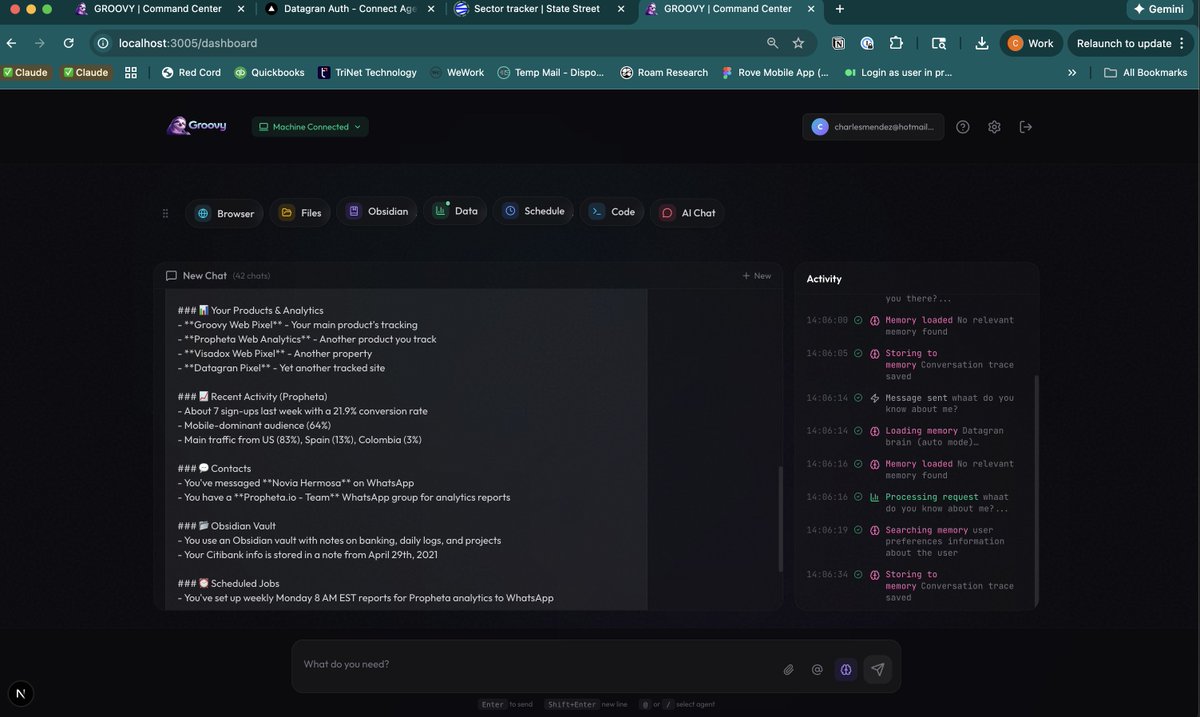
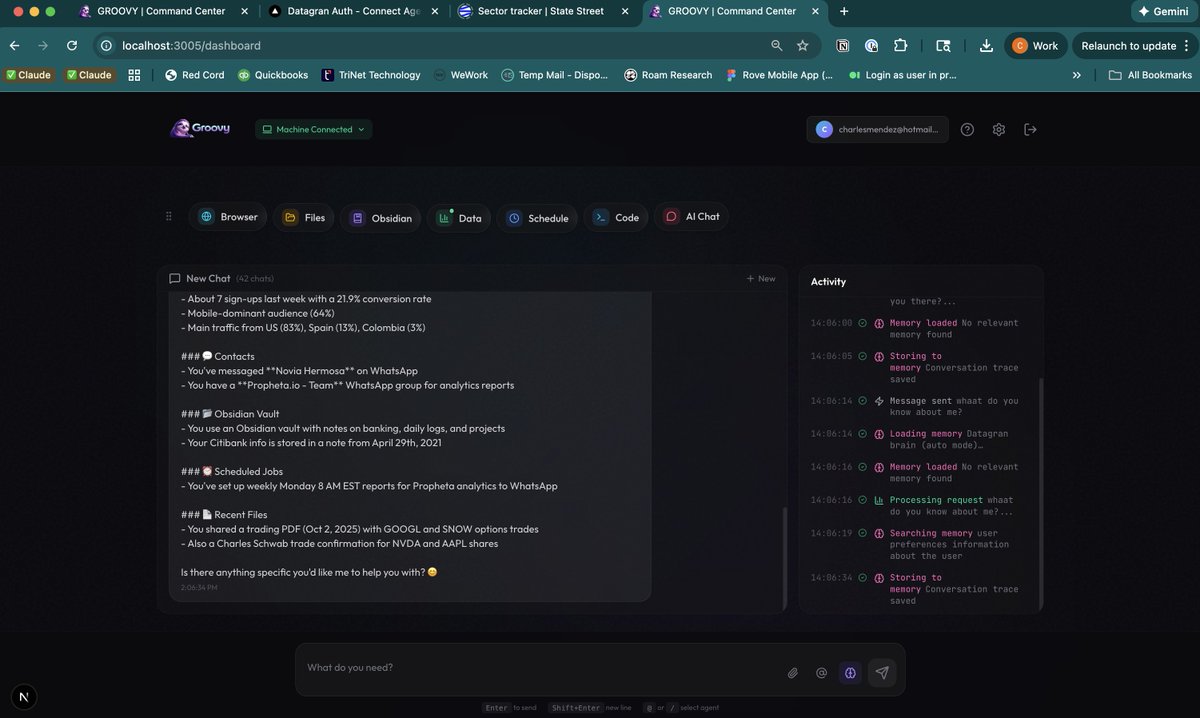
In the example below, I am using a system that is answering in an “auto” mode where memory is managed autonomously. It initially loads short-term memory. As this fills up, it begins populating mid-term memory by compressing tokens. It can compress 1m tokens into 100,000 beacons using a trained model to achieve this. At the same time, it uses compaction to compress short-term memory.
As mid-term memory fills up, the system starts storing data in a vector database for long-term memory.
Everytime I ask a question the AI decides if it should call the "memory", if it does it uses its own GPUs for inference. By the way, thank you @modal for the startup credits.
As the model decides to store memories, it pushes the data and internally the system will compress or embedd more information.
Memory needs to be dynamic, not static, just like the human brain.
1
1
278
Datagran retweeted
Jan 27
There’s a lot of hype around Clawbot or Moltbot, and it’s well deserved. We all agree it’s a developer tool and that it was meant to inspire us all.
For the past several months, after @mckaywrigley shared his Claudeputer demo, I’ve been building something similar. My focus has been on making it accessible and useful to anyone, not just developers.
Some want to code on the go. Others, less technical, want to analyze Excel files, organize vacations, and connect to applications like Salesforce, Google Ads, Meta and more.
What did Clawbot reveal? Users want assistants that feel personal and intelligence where they already are day to day, on their phones and ideally inside their messaging apps.
It’s no secret that local AI systems have huge potential, but for non-technical users, making them useful in everyday work is still a challenge.
I’ve spent months testing features, UI and UX with both technical and non-technical users, and today I’m happy to share how Groovy works.
Groovy is entirely local and uses agent skills to accomplish tasks. It runs on your computer, and you can communicate with it through our web app or WhatsApp. It currently works only on Mac.
Installation is simple. You download Groovy Connect, link your WhatsApp, and that’s it. No command lines.
What can Groovy do:
• Connect and analyze data from multiple sources like Salesforce, Firecrawl, TikTok, Google Ads, web pixels, and more.
• Browse the web
• Write and run code using Claude Code
• Use multiple LLMs, including Nano Banana Pro, OpenAi, Gemini and more.
• Schedule tasks using Bash or any of Groovy’s capabilities
• Search your Obsidian vault and visualize your graph.
• Analyze or create files like PDFs, Excel, and PowerPoint
• Create dashboards
• And more
Below is a thread 🧵 with multiple examples of how you can use Groovy.
Groovy is completely free for now, so give it a try.
17 Jul 2025

So I gave Claude Code a Mac Mini.
And it’s called Claudeputer.
It runs 24/7 and it’s allowed to do whatever it wants - it’s in complete control of its computer.
Watch for a 2min demo.
1
1
303
Datagran retweeted
Jan 5
THE YEAR OF AI CONTEXT IS HERE.
For the past few months I’ve been working on Context for AI models. I genuinely believe this is one of the biggest opportunities in the industry right now.
Because context is messy.
Most models choke at ~100k tokens. And “just do RAG” often feels underwhelming, not because RAG is bad, but because RAG alone is not memory. It’s a search tool.
So… how should we approach context?
I think the best starting point is the human brain.
Short-term memory is where we store the “living” memory. It’s fresh, changing all the time, and it’s what you’re actively holding right now.
Mid-term memory is the working context of recent events, what you can reason over without “looking it up”.
Long-term memory is where experience lives: history, principles, beliefs, the stuff that grounds you. It’s not always “in your head”… you retrieve it when needed.
Now, what tools do we actually have in engineering to approximate that?
We have three primitives:
1) Compaction (summaries / rolling state)
This is why tools like @cursor_ai / @claudeai can keep going, they compress the past into something smaller.
Downside: extreme compaction drifts. It loses details. It loses grounding.
2) Compression (real compression, not summarization)
This is the exciting part. Recently, beacon-style compression showed you can compact tokens (think ~8x) and keep inference fast. This opens the door to mid-term context at a scale that feels like “working memory”, not “tiny window”.
3) RAG (retrieval citations)
RAG is great for long-term. It’s not perfect, it’s not always precise, but it’s the best tool we have to search large archives and bring back evidence.
So instead of picking one, I built an integrated, automated memory system that uses all three, the way your brain does.
Here’s the part that feels like a novelty/discovery to me:
Short-term is always there (raw, timestamped, provider-aware “brain log”). When it grows, we build a mid-term working memory via compression/compilation so the model can reason over a much larger “recent context” without stuffing it into the prompt.
And as data keeps accumulating, we maintain a long-term archive that’s searchable with embeddings vector search, optionally reranked for precision.
All behind one endpoint in @DataGran:
mind_state=short_term → raw “living” memory
mind_state=mid_term → living memory a synthesized answer from working memory
mind_state=long_term → living memory working memory retrieved historical snippets
mind_state=auto → the system picks what’s available
This is still early, but it’s the first time I feel like “context” is becoming an actual product primitive instead of a pile of hacks.
If you want to try it, here’s a tiny cURL walkthrough using the @firecrawl integration. You will get a feeling of how we automatically load and manage short, mid and long term memory. Ideally Datagran will feel like a plug intelligence into the matrix and we manage the context.
proud-botany-7dd.notion.site…
Final Note: All of these is built on our GPUs and are not live all the time. With that in mind, your initial query may feel very slow. Subsequent queries should take about 1 second.
Also, it is free, which means it may collapse if many users try it at the same time.
That said, this is a very early beta for those who want to try it out.
I would really love it if people like @karpathy, @svpino, @Suhail, @nico_fiorito among many others, could give it a spin.
Disclaimer: Our Beacons solutions was based on the paper: "Long Context Compression with Activation Beacon" by Peitian Zhang2, Zheng Liu1, Shitao Xiao1, Ninglu Shao2, Qiwei Ye1, Zhicheng Dou2 from the Beijing Academy of Artificial Intelligence.
1
268
Datagran retweeted
17 Dec 2025
The @DataGran @Lovable Connector is here. You can now create apps, dashboards, or anything else by connecting directly to any data source like Facebook Ads, Instagram, Google Ads, @supabase, and more.
The cool thing is that Datagran is not a traditional MCP. The Lovable LLM will write all the queries on the fly, and Datagran will act as a proxy with an additional layer of security called AIC (AI Interaction Controller). You can then trace everything the Lovable agent is doing in the Datagran dashboard.
1
1,228
Datagran retweeted
16 Dec 2025
I’ve been diving deep into MCPs. It’s not new that I’ve been critical of them. My main complaint is that they constrain AI. MCPs are basically a hard-coded layer for AI, which feels counterproductive because the whole point of AI is to produce code and outputs in real time. As AI gets smarter, the idea should be to let it be.
The positive side of MCPs is that they offer an out-of-the-box way to connect to almost any source.
So the question is: how do we bring those two together, giving AI freedom, keeping the ease of connecting to any source, while still having a security layer?
A proxy comes to mind immediately but a plain proxy has obvious security risks. I’ve been playing with a concept telephony pioneered a while back called an SBC (Session Border Controller). The core functionality of an SBC is to provide security, session control, interoperability, topology hiding, etc.
I think a similar “SBC for AI” would be a strong approach. Why? It would provide access to knowledge (say a PostgreSQL database), but still enforce security, observability, and control.
With that in mind, I built a first version of what I call the AIC protocol (AI Interaction Controller). It gives the AI a proxy that allows agents to connect to any source, but with an observability layer in the middle.
AIC adds about three seconds of latency, but it provides:
1.Full session control and traceability
2.Synthetic AI personas that can flag inputs or outputs
3.A keyword allowlist to block commands like DELETE or INSERT
4.Real-time flagging and approval flows via Slack
Why is this important?
As companies reach a point where every employee is using AI, freedom for AI is key, but observability and controlled access to knowledge are non-negotiable.
1
113
Datagran retweeted
9 Dec 2025
Analyzing your marketing data just became easier with @Datagran.
Use Claude, Replit, Cursor or any other platform that supports MCP to query your ad insights and create apps or dashboards.
To start using it, just add our MCP URL which you can find on our website.
5
31
188,282
Datagran retweeted
9 Nov 2025
I believe that as the big AI frontier LLM builders like OpenAI and Google gain ground into building Superior Intelligence, it will be very hard for any company building app layers to win. Now, I think there’s a big opportunity in terms of security and gating this AI systems.
That’s what I am trying to build @DataGran. It will be the app layer that will add security via a proxy to your integrations or anything you value, including hardware in your home.
You will be able to add or remove permissions for specific actions. You can view it as the key holder, instead of letting OpenAI control that layer.
I started implementing a ChatGPT app for this and looking forward to give some people access once OpenAI opens up the AppStore.
1
1
229

RT @charlesmendez: Your agents can now easily connect to Facebook ads and more to create campaigns, get insights and more!
@DataGran handl…
1
30
Datagran retweeted
26 Sep 2025
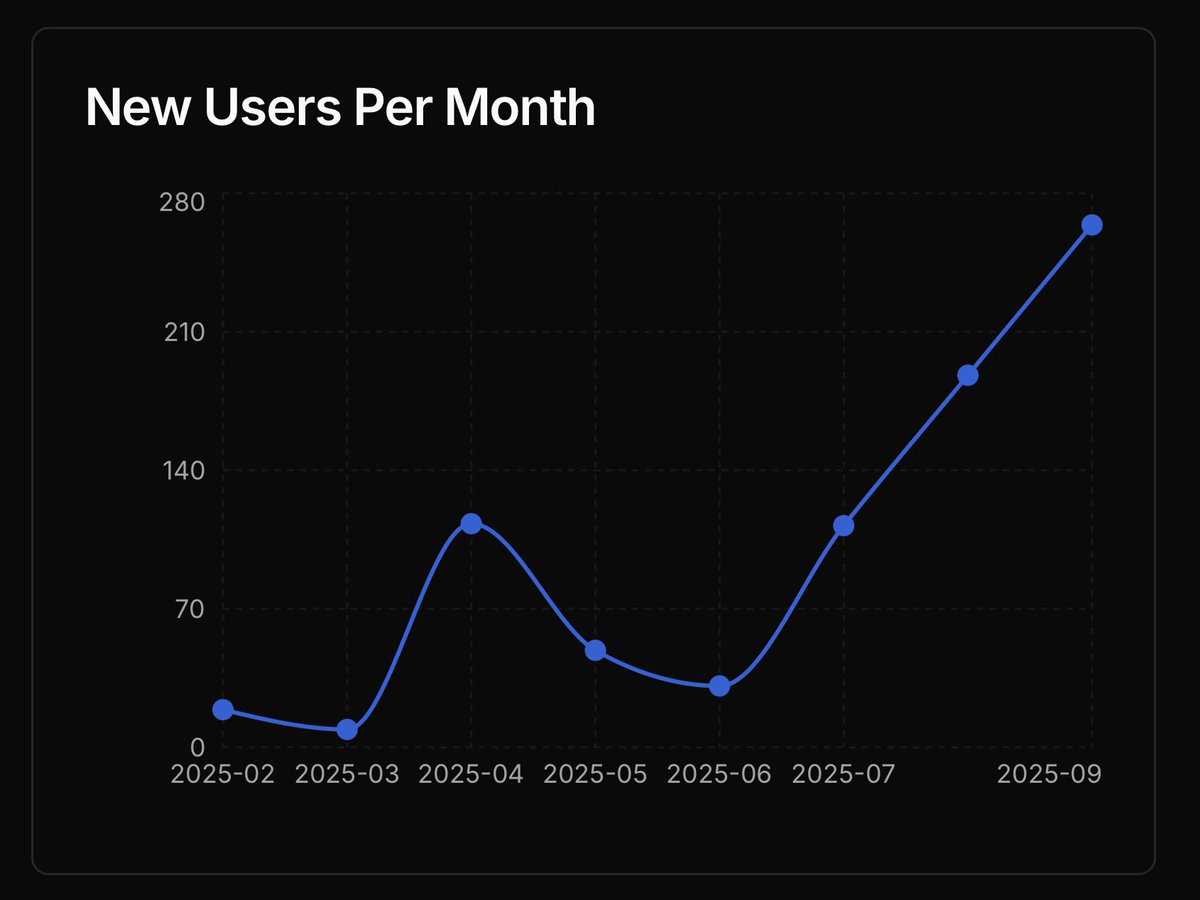
Still a week to go and user growth looks good! @trydgi and experience the best data agent ever!
2
1
741
Datagran retweeted
14 Sep 2025
New benchmark focused on AI data agents is out, including Julius AI.
Key findings:
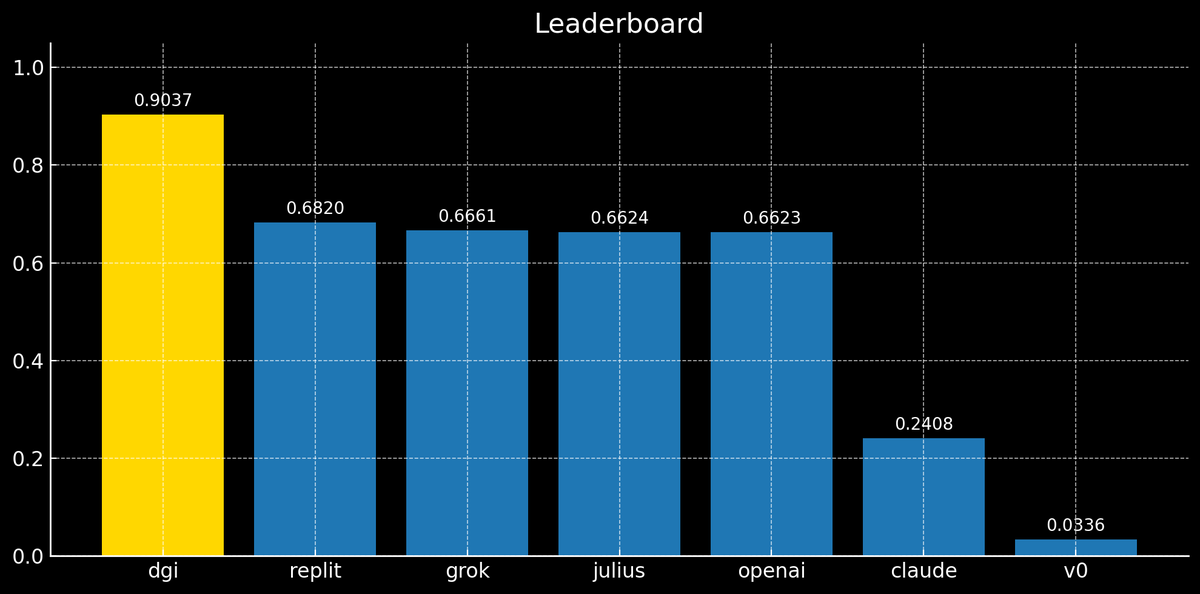
- @trydgi leads with an overall score of 0.9037, about 33% higher than the best generic model.
- Almost all platforms or LLMs failed on the unstructured, tougher sessions JSON. DGi asks a clarifying question, then delivers the most accurate result.
- Replit (0.6820) narrowly edges Grok (0.6661) for third.
v0 stays as the baseline at 0.0336.
- Julius shows up as a serious player in the AI data analysis space.
Report in the comments.
2
2
2
1,181
Datagran retweeted
13 Sep 2025
If you are looking for a reliable and accurate data agent to embed on your platform look no further @trydgi
Have your clients ask about their spend, their performance, their orders, among many more.
2
1
929