
Joined June 2012
- Tweets 289
- Following 398
- Followers 2,075
- Likes 693
39 Photos and videos










Pinned Tweet
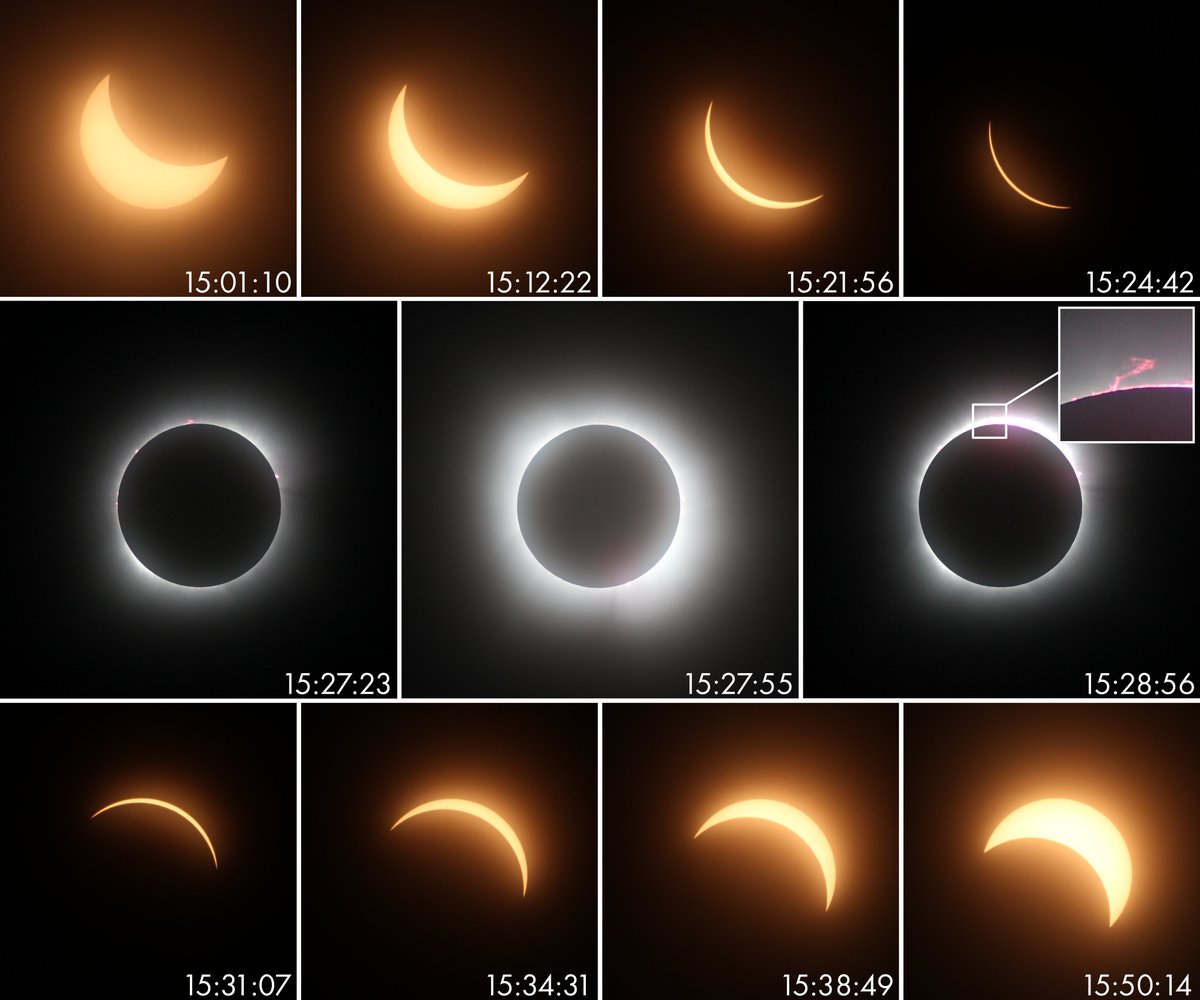
Low-light 3D reconstruction is a very challenging problem — image noise makes it difficult to establish correspondences, predict camera poses, and reconstruct scene geometry. We show that leveraging 3D foundation models enables scene reconstruction in the dark!
Mar 9

📢📢📢Dark3R (#CVPR2026) recovers camera poses and point clouds—and enables novel view synthesis—from images captured in ultra-low light (image SNR < −4 dB).
Project Page: andrewguo.com/pub/dark3r
Code/Dataset: github.com/andrewyguo/dark3r
Paper: arxiv.org/abs/2603.05330
2
15
99
12,033
Congratulations, @KellyKZhu! It was great to work with Kelly during her MSc, and I'm excited for her to start her PhD at CMU. See here for all of Kelly's work, and more exciting things to come soon: kellyzhu.ca/

Seeing research come to life 👀
Kelly Zhu, MSc graduate in computer science, works across AI, robotics and computer vision — and shares what comes next ↓
uoft.me/cs6
1
1
24
4,958
Really cool project led by @HaojunQiu! We show a patch-based image generation method with closed-form diffusion (i.e., analytical denoising—no neural network). It's *super* efficient and even scales to gigapixel generation! #CVPR2026
Jun 5

📢📢📢We introduce Efficient-SID⚡️: training-free single-image diffusion model that generates images by sampling directly from an input image's patch distribution. Our method enables megapixel generation in <1s and scales to gigapixel generation. We also enable stylization, editing, and other applications. The outputs are constrained to follow exactly the patch distribution of the input — something that is very difficult to do with large models!
#CVPR2026 Highlight
🌐 haojunqiu.github.io/efficien…
📄 arxiv.org/abs/2606.04299
[1/6]
2
7
39
5,736
The workshop on Geometry-Free Novel View Synthesis and
Controllable Video Models is happening now in room 607 at #CVPR2026---currently listening to @du_yilun!
geofreenvs.github.io/
13
938
David Lindell retweeted

May 29
Today, I’m proud to announce the launch of Wayve Labs: @wayve_ai's frontier research unit for Embodied AI. 🧵

8
23
155
12,270

May 27
Check out the Geometry-Free Novel View Synthesis and Controllable Video Models Workshop at #CVPR2026! Super lineup of speakers.

Attending #CVPR2026, Denver?
We have a stellar speaker lineup for “GeoFreeNVS: Geometry-Free Novel View Synthesis and Controllable Video Models.”
Come early. We anticipate seats will fill up FAST!
1/2

3
47
8,324
May 23
Image diffusion models like Flux natively output at 1k resolution, but what if we want to generate much higher resolution images (6k )? SEGA modifies the RoPE encodings during the diffusion process to generate high-resolution images---no fine-tuning required!
May 22

📢🚀 Happy to share our recent work.
SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers
📄Paper: arxiv.org/abs/2605.22668
🌐Webpage: rajabi2001.github.io/sega/
🤗HF: huggingface.co/papers/2605.2…

5
18
210
29,792
David Lindell retweeted

May 22
🚀 🚀 🚀 Excited to share our new paper:
Remember to be Curious: Episodic Context and Persistent Worlds for 3D Exploration
What does it take for an agent to stay curious in a 3D world?
The answer is memory.
🌐 Project: recuriosity.github.io/
📄 Paper: arxiv.org/abs/2605.22814
💻 Code: github.com/recuriosity/recur…
2
41
220
70,132
May 20
Learning a compact, token-based representation of 4D objects enables multiple applications including image-to-4D, video-to-4D, 3D tracking, and more! Work led by @anagh_malik with collaborators at Apple — also check it out at CVPR 2026!
May 20

📢📢📢 Velox 🚀: Learning Representations of 4D Geometry and Appearance
In our #CVPR2026 paper, we introduce a method for learning a native 4D representation, useful for many downstream tasks, such as video-to-4D, 3D tracking, cloth simulation, and others!
🌐: apple.github.io/ml-velox
📝: arxiv.org/abs/2605.04527
16
1,724
David Lindell retweeted

May 19
High-fidelity generation is hitting a scaling crisis as DiT compute grows with image resolution and video length. But do we need high-resolution denoising at every step?
We introduce Spectral Progressive Diffusion, a plug-and-play framework for efficient image and video generation that directly exploits the spectral autoregression property of diffusion to grow resolution during denoising.
[1/7]
22
65
415
87,591
David Lindell retweeted

📢 Excited to be in Rio at #ICLR2026 for our work Lyra with @xuanchi13. Looking forward to discussing generative world models and grabbing Caipirinhas at Ipanema Beach.
Poster: P4-#3208, Thursday 10:30 AM - 1 PM
Lyra 1.0: research.nvidia.com/labs/tor…
Lyra 2.0: research.nvidia.com/labs/sil…


3
5
65
3,863

I will be presenting "Generative Re-Photography with Video Models" at several places over the next month. Hit me up if you are around!
MIT Media Lab-Apr 1
Harvard-Apr 2
MIT CSAIL-Apr 7
Cornell Tech-Apr 9
Princeton-Apr 10
CMU-Apr 13
Stanford-Apr 24
Berkeley-Apr 28
10
7
73
7,284
Mar 25
Congratulations to Dr. @sherwinbahmani for successfully defending his thesis! It was wonderful to work together (and shout-out to co-supervisor @taiyasaki). Onwards and upwards!
P.S. Check out all Sherwin's amazing work: sherwinbahmani.github.io/


1
3
53
3,669
David Lindell retweeted
Mar 10
Excited to share that Rhoda AI is now out of stealth mode. We've been building a foundation model for physical AI that generalizes to new tasks with a surprisingly small amount of embodiment-specific data. This is enabled by our direct video-action model (DVA).
1/N
Mar 10

After operating in stealth for the last 18 months @rhodaai , we’re excited today to finally show the world what we’ve been working on. We believe we’re on a path to physical AGI with the launch of our brand new foundation model, the Direct Video Action (DVA) model.
6
14
151
26,136
David Lindell retweeted

Mar 10
After operating in stealth for the last 18 months @rhodaai , we’re excited today to finally show the world what we’ve been working on. We believe we’re on a path to physical AGI with the launch of our brand new foundation model, the Direct Video Action (DVA) model.
54
78
608
254,974

To bring generalist intelligent robots to the real world, we have to overcome the data scarcity problem.
At Rhoda, we are solving it by reformulating robot policies as video generation.
Today, we introduce the Direct Video-Action Model (DVA)
18
38
211
68,124
David Lindell retweeted

EGSR'26 Call for Papers is out!
Doing research on rendering? Physics-based, neural, stylized... Submit your work to EGSR!
Papers deadline: April 8th 2026
egsr2026.inria.fr/
7
7
786
David Lindell retweeted

ICCP 2026 is coming to @Princeton, July 13-15! Paper submissions are open, deadline April 10. Accepted papers published in ICCP Proceedings or IEEE PAMI Special Issue.
Take a sneak peek at already confirmed speakers on our website: iccp2026.iccp-conference.org!
#ICCP2026

5
13
1,395