
Joined January 2024
- Tweets 519
- Following 17
- Followers 4,936
- Likes 483
154 Photos and videos
















Pinned Tweet

Jun 9
Introducing Duet Autopilot, the first verified self-improving AI agent for CX.
It automates agent improvement by turning conversation signals into validated improvements ready for human review, helping agents get better with every conversation. 🧵
3
6
34
13,718
Jun 11
Two design teams shipping AI that people use every day.
We're hosting a design night with @harvey during Config week.
Register below!
1
1
606
Jun 11
We're proud to welcome @CorePowerYoga, the largest yoga studio brand in the US, to the Decagon customer family.
Across 220 studios in 23 states, CorePower makes yoga challenging, accessible, and worth coming back to for millions of students.
1
7
300
Decagon retweeted

Jun 10
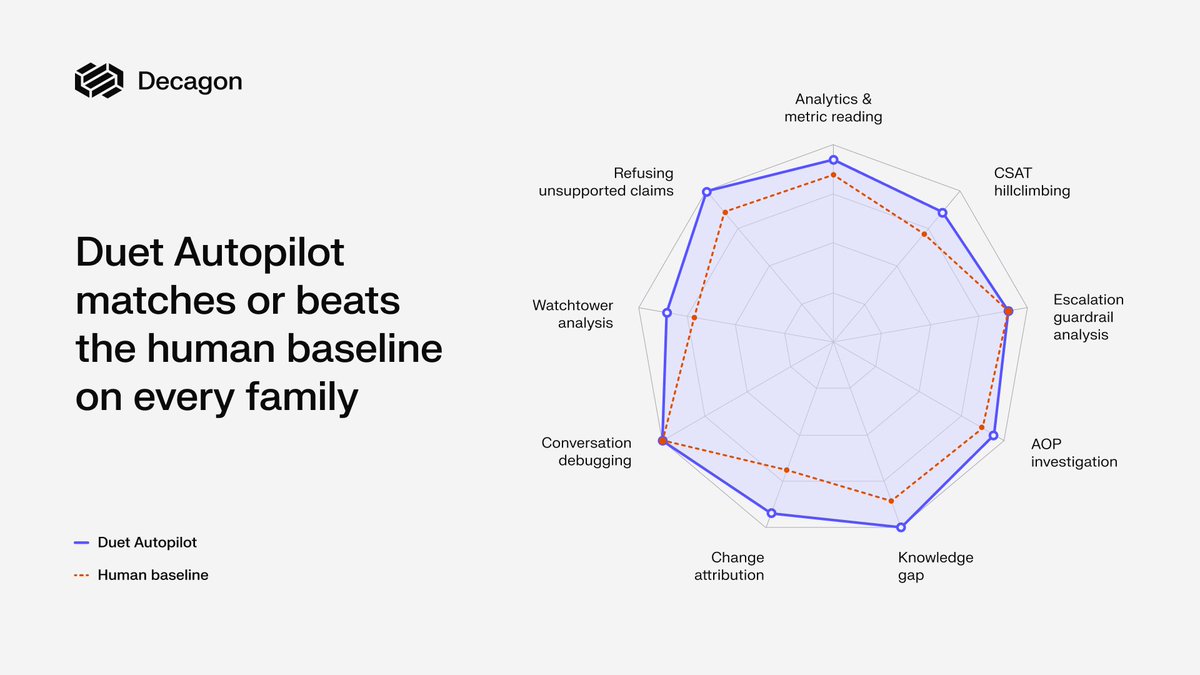
One of the hardest parts of building self-improving agents is proving they are actually improving.
That’s why, alongside Duet Autopilot, we built DuetBench: the first benchmark designed specifically for CX agents that learn and improve over time.
To evaluate Duet Autopilot, we compared its performance against certified human agent builders and graded both on outcome and methodology across 90 diagnostic investigations from simple metric lookups to root-causing CSAT drops.
We also evaluated Autopilot on enterprise agent-building tasks. Starting from messy design documents, it had to build AOPs and tools from scratch, generate simulations, and pass every associated test before a task was considered complete.
Autopilot demonstrated an iterative approach to agent building. Rather than solving problems in a single pass, it ran simulations, identified broken branches, repaired the AOP or underlying tool, and repeated the process until the workflow passed.
Another notable result was that Autopilot improved the quality of its own test set through self critique, increasing simulation accuracy from 58% to 88% across 520 benchmark runs.
As self-improving systems become more common, verified evaluation will matter just as much as model capability.
Excited to share the research behind it. Full writeup below. ↓
2
2
8
408
Jun 10
Yesterday, we introduced Duet Autopilot as the first self-improving agent for CX. It’s a big claim, which is why we decided to build a benchmark to back it up.
DuetBench is the first benchmark designed specifically for CX agents that learn and improve over time.
1
5
14
697
Jun 10
As self-improving systems become more common, verified evaluation will matter just as much as model capability.
1
2
103
Decagon retweeted

Our AI at @DecagonAI is now doing more agent-building than we (humans) are.
Duet wrote 81% of our test simulations, and made 54% of the edits to our customers' agents.
AI products naturally evolve toward AI doing more of the work, and we're pushing that to the frontier
Jun 9

Introducing Duet Autopilot, the first verified self-improving AI agent for CX.
It automates agent improvement by turning conversation signals into validated improvements ready for human review, helping agents get better with every conversation. 🧵
3
1
8
3,906
Decagon retweeted

Jun 9
.@DecagonAI's ability to push the frontier of agent development is truly impressive. Duet Autopilot is the first verified self-improving AI agent for CX – learn more below!
Jun 9

Today, we’re launching Duet Autopilot, the first verified self-improving AI agent for CX!
It automatically analyzes conversations, identifies opportunities for improvement, validates updates, and surfaces them for human review, improving itself with each cycle. 👇
1
6
1,285
Decagon retweeted

Jun 9
Today, we’re launching Duet Autopilot, the first verified self-improving AI agent for CX!
It automatically analyzes conversations, identifies opportunities for improvement, validates updates, and surfaces them for human review, improving itself with each cycle. 👇
4
9
43
10,335
Decagon retweeted

Jun 9
Turn on Autopilot and go touch grass. More gamechanging than Pokemon Go 🤯
Jun 9
Introducing Duet Autopilot, the first verified self-improving AI agent for CX.
It automates agent improvement by turning conversation signals into validated improvements ready for human review, helping agents get better with every conversation. 🧵
2
1
12
2,710
Decagon retweeted

Jun 9
a big part of onboarding @DecagonAI is to become a 'master' at the platform (goated education team)
its been interesting to be a user of the platform i work for (rare if youve spent your life in b2b as an engineer) because ive just become so impressed with our product and engineering team organically through the experience
Duet AP is another feature im extremely impressed with, the right interface for llms data warehousing is proactive suggestions/automations
Jun 9
Introducing Duet Autopilot, the first verified self-improving AI agent for CX.
It automates agent improvement by turning conversation signals into validated improvements ready for human review, helping agents get better with every conversation. 🧵
1
1
11
2,256
Jun 9
Introducing Duet Autopilot, the first verified self-improving AI agent for CX.
It automates agent improvement by turning conversation signals into validated improvements ready for human review, helping agents get better with every conversation. 🧵
3
6
34
13,718