
Joined May 2020
- Tweets 109
- Following 93
- Followers 4,160
- Likes 114
22 Photos and videos



Pinned Tweet

Jun 3
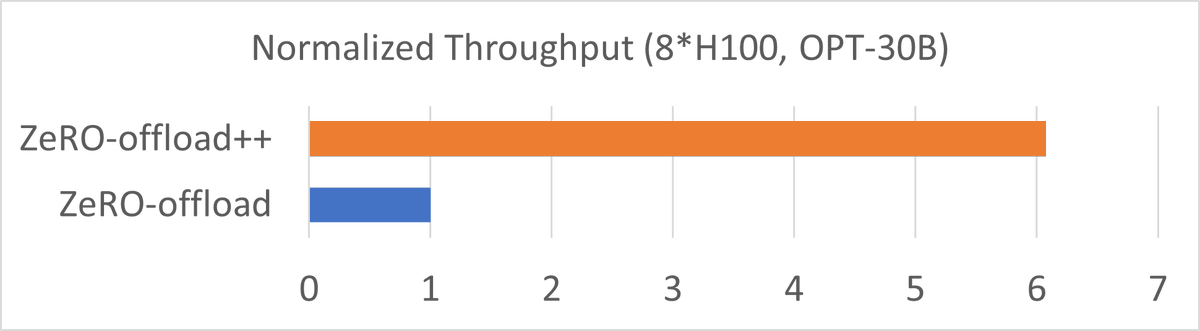
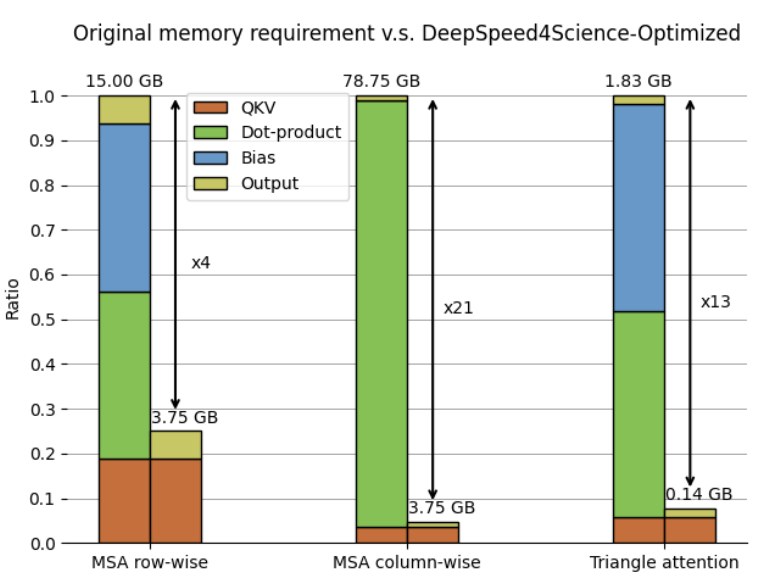
We now have native support for all ZeRO stages 1/2/3 for Muon Optimizers, providing superior performance on LLM pre-training and post-training. Feel free to try it out, kudos to @PKUWZP Guokai Ma, Peng Du and Chi for the contribution!

DeepSpeed now supports the Muon Optimizer.
Optimized specifically for internal 2D weights within neural networks, Muon is gaining traction for its significant memory savings and strong convergence metrics during LLM training.
In our latest blog post, the DeepSpeed team shares a deep dive into their integration setup, implementation of hybrid optimizer strategies, and early benchmark results. @PKUWZP
Read the full technical breakdown here 👉 bit.ly/4dLjGE2

3
13
1,509
May 26
Reminder to join our DeepSpeed Office Hours on Tuesday, May 26 at 12:00 PM America/New_York. We'll cover general questions, Q2 roadmap progress, and requests for Q3. Everyone is welcome!
Zoom:
zoom-lfx.platform.linuxfound…
3
250

Don't miss @DeepSpeedAI virtual office hours on May 26 at 12:00 PM America/New_York to ask questions of @toh_tana member of DeepSpeed TSC & get the latest recent key updates, including AutoSP (sequence parallel), AutoEP (expert parallel), and AutoTP (tensor parallel).

4
7
20
8,235
Apr 30
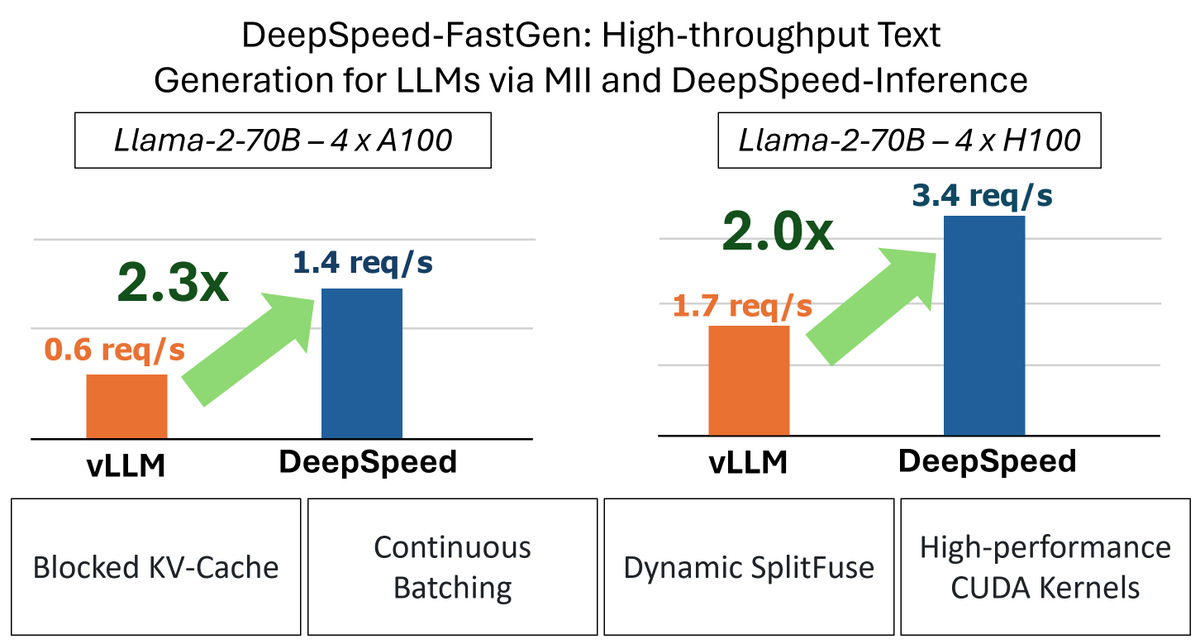
Great News! Thanks to DeepSpeed AutoSP, efficient long context LLM training is now easily accessible.
Want to train LLMs on longer contexts without re-engineering your entire systems stack?
Introducing AutoSP — the first compiler-based solution that automatically optimizes LLM training for long contexts. Under the hood, AutoSP applies a series of compiler passes that trigger sequence parallelism, paired with a curated activation-checkpointing scheme tailored for long-context training. It's integrated directly into DeepSpeed, so enabling long-context training is just a config change away.
No more rewiring your stack to push context lengths. Read the blog to learn more 🖇️ pytorch.org/blog/introducing…
✍ @AhanGupta13, Zhihao W., Neel Dani, @toh_tana, Tunji Ruwase, @_Minjia_Zhang_
#PyTorch #DeepSpeed #AutoSP #OpenSourceAI

1
2
4
1,421
DeepSpeed retweeted

Mar 25
Excited to share that our work SuperOffload received an Honorable Mention for the ASPLOS 2026 Best Paper Award 🎉
Proud of the team for pushing forward system design for large-scale AI. Xinyu gave a great talk presenting the work. In addition, it was also wonderful to spend time with collaborators and the broader community.

1
6
33
2,758
DeepSpeed retweeted

Mar 23
💡Excited to be organizing a tutorial at ASPLOS 2026 (lnkd.in/g5auexxg): "Building Efficient Large-Scale Model Systems with DeepSpeed: From Open-Source Foundations to Emerging Research"
🌀 Link: lnkd.in/gixRnAm6
📍 Room: Allegheny
🕘 Time: Monday (Mar 23), 8:30am-12pm
🎤 Speaker: Tunji Ruwase, Masahiro Tanaka, Minjia Zhang, Zhipeng Wang, PhD
We will cover how @DeepSpeedAI enables new forms of parallel, distributed, and heterogeneous execution, and how modern systems tackle key challenges in parallelism, offloading, and memory efficiency.
If you are working on ML systems, LLM training, or emerging hardware, would love to connect at ASPLOS!
1
5
1,010
🗓️ Plan your week: Check out the full "Meet the PyTorch Experts" schedule here: pytorch.org/event/nvidia-gtc…
We'll be posting the daily lineups here in this thread all week. See you at the booth! 🤝 @NVIDIADev
1
2
6
8,297
DeepSpeed retweeted
Mar 14
I am thrilled to release our newly re-architected extremely-scale Linear Programming Solver (DuaLip-GPU), which is developed via PyTorch enabling multi-GPU computations and parallelism (github.com/linkedin/DuaLip). We also released the technical report (arxiv.org/abs/2603.04621) covering all technical details.
Linear Programming Solver is a fundamental building block for solving extreme-scale matching problems, which underline many important technical domains related to social network platforms such as ranking, personalization, item-matching and recommendation systems, as well as in LLMs.
To realize the available parallelism, we develop GPU execution techniques tailored to sparse matching constraints, including constraint-aligned sparse layouts, batched projection kernels, and a distributed design that communicates only dual variables. Further, we improve the underlying ridge-regularized dual ascent method with Jacobi-style row normalization, primal scaling, and a continuation scheme for the regularization parameter.
On extreme-scale matching workloads, the GPU implementation achieves at least a 10x wall-clock speedup over the prior distributed CPU DuaLip solver under matched stopping criteria, while maintaining convergence guarantees. This is the superb technical work combining ML Systems, Mathematical Optimization and Machine Learning. #Optimization #AI
3
16
2,106
DeepSpeed retweeted

Mar 13
PSA: if you use torch>=2.10 w/ deepspeed ZeRO-3 please update to deepspeed@master - a new release should happen shortly.
If you use torch<2.10 or ZeRO-1/2 nothing needs to be done.
See this fix from Michael Royzen github.com/deepspeedai/DeepS…
Cause: PyTorch made some grad reduction stream-related changes which could lead to borked grad reduction in Deepspeed ZeRO-3.
3
22
4,415
DeepSpeed retweeted
Mar 9
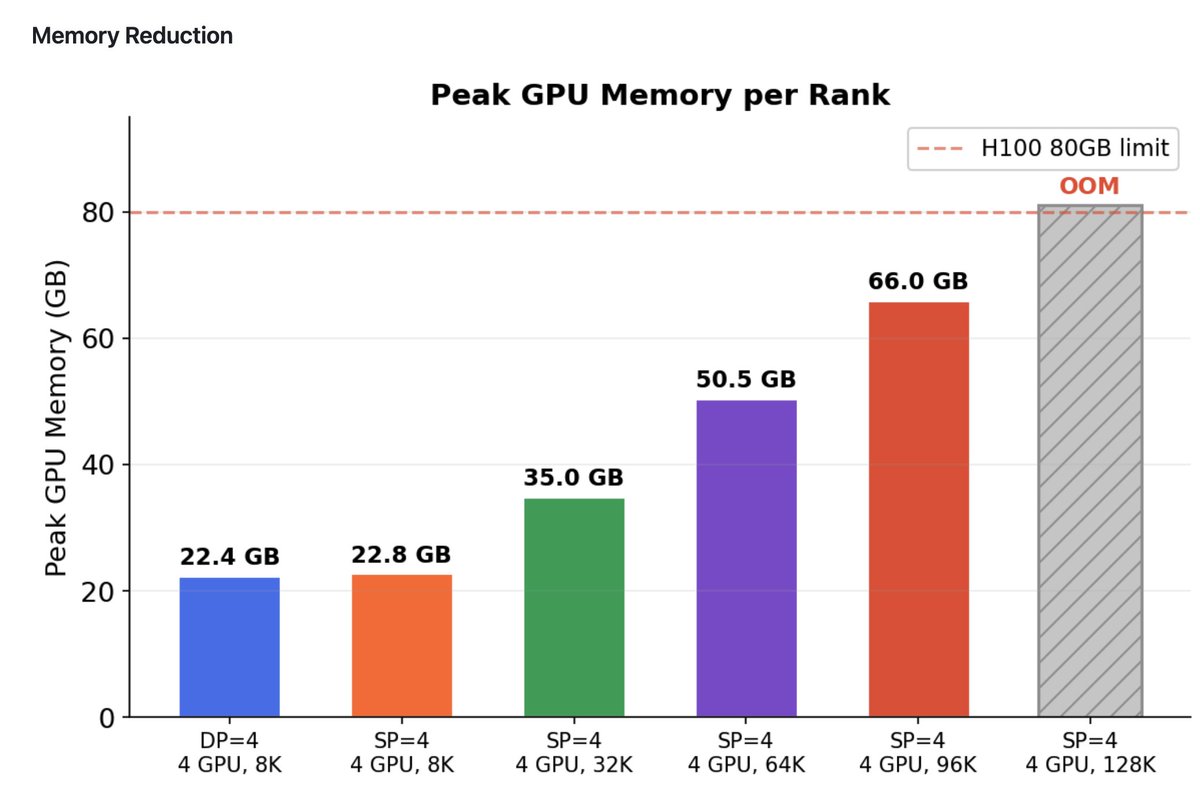
Good news! Ulysses Sequence Parallelism from the Snowflake AI Research and the Deepspeed teams has been integrated into @huggingface Trainer, Accelerate and TRL
For extensive details please see this writeup:
huggingface.co/blog/ulysses-…
Thanks a lot to @krasul for helping make it happen. Also the others in the HF team who helped with integration.
4
20
116
17,818
Feb 25
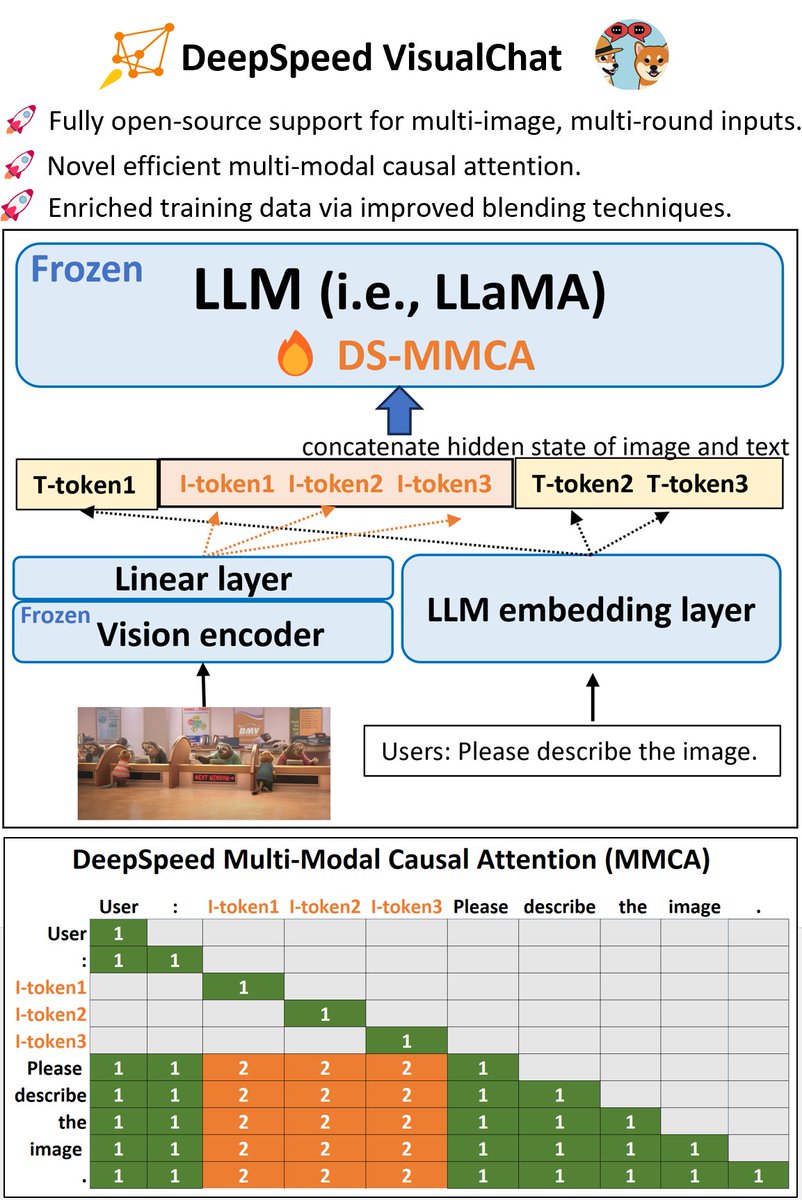
Training Optimization on Multimodal models is an important pillar for pushing the frontier Multimodal Foundation Model development. Kudos to @toh_tana and Tunji Ruwase for their excellent work. It's just the starting point, more to come!
New @DeepSpeedAI updates make large-scale multimodal training simpler and more memory-efficient.
Our latest blog introduces a PyTorch-identical backward API that helps code multimodal training loops easy, plus low-precision model states (BF16/FP16) that can reduce peak memory by up to 40% when combined with torch.autocast.
🖇️ Read the full post for details: hubs.la/Q044yYVs0
#DeepSpeed #PyTorch #MemoryEfficiency #MultimodalTraining #OpenSourceAI

4
6
1,216
DeepSpeed retweeted
Feb 13
Deepspeed ZeRO 1 2 used to take forever to load huge models on multi-gpu as tensor flattening was happening on cpu due to the small gpu size back when it was designed.
Now things load super fast thanks to a rework by Kento Sugama to flatten on gpu. Yay!
github.com/deepspeedai/DeepS…
1
5
39
1,959
15 Dec 2025
It's exciting to see DeepSpeed leveraged by Ray in disaggregated hybrid parallelism for multimodal training.
Blog: tinyurl.com/4dwkk37e
Congrats to Masahiro Tanaka (@toh_tana) and @anyscalecompute friends.
5
29
4,110
Zhipeng (Jason) Wang, PhD (@PKUWZP) explains how @DeepSpeedAI supports ML training research and why joining PyTorch Foundation benefits researchers and developers working on AI training workloads.
🔗youtu.be/67719mlOSp0 #PyTorch
#DeepSpeed #OpenSourceAI #AIInfrastructure
1
13
111
11,813
26 Oct 2025
It's nice to share the most recent updates from the DeepSpeed project at #PyTorchCon, we will continue pushing the boundary of LLM distributed training for the OSS community.
🎙️ Mic check: Tunji Ruwase, Lead, DeepSpeed Project & Principal Engineer at Snowflake, is bringing the 🔥 to the keynote stage at #PyTorchCon!
Get ready for big ideas and deeper learning October 22–23 in San Francisco.
👀 Speakers: hubs.la/Q03GPYFn0
🎟️ hubs.la/Q03GPXVH0

1
7
1,294
9 Oct 2025
UIUC, AnyScale, and Snowflake significantly enhanced LLM offloading for the Superchip era!
9 Oct 2025

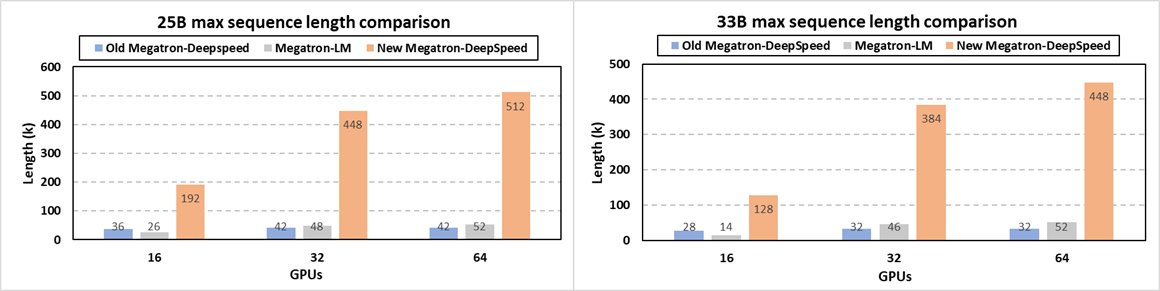
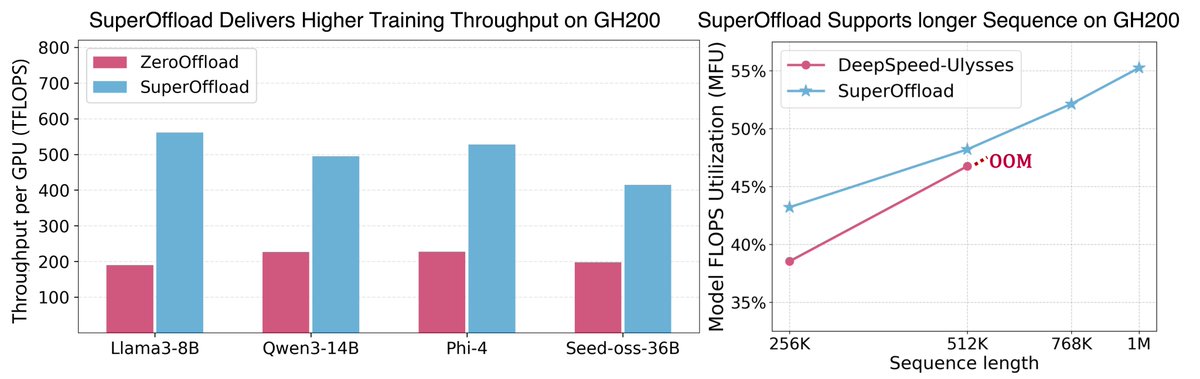
🚀 SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips
Superchips like the NVIDIA GH200 offer tightly coupled GPU-CPU architectures for AI workloads. But most existing offloading techniques were designed for traditional PCIe-based systems. Are we truly tapping into their full potential for LLM training?
🎯 SuperOffload is our answer to this challenge, a new DeepSpeed component rethinking offloading from the ground up, specially designed for LLM training on Superchips.
✨ SuperOffload is exact -- no approximation, no heuristics, and no changes to your training algorithm. Just faster, larger model with longer sequence training using the same code, which are made possible by system-level optimizations exploiting Superchip architecture.
🧪 SuperOffload allows you:
- Finetune models like GPT-OSS-20B, Qwen3-14B, and Phi-4 on a single GH200
- Up to 4X faster speed than previous approaches like ZeRO-Offload
- Effortlessly scales to:
-- Qwen3-30B-A3B and Seed-OSS-36B on 2 x GH200s
-- LLaMA2-70B on 4 x GH200s
-- 1M sequence length on 8x GH200 with 55% MFU
- Easy-to-use: Fully integrated and open-sourced in DeepSpeed. Just a few lines of code to enable!
📚 Read more through official PyTorch blog: pytorch.org/blog/superoffloa…
🧠 For more technical details, please read our technical report: arxiv.org/abs/2509.21271
🛠️ SuperOffload is fully open-sourced through DeepSpeed. Try it now: github.com/deepspeedai/DeepS…
📄 SuperOffload has been accepted to ASPLOS 2026! Kudos to Xinyu Lian (@Alexlian0806), Masahiro Tanaka (@toh_tana), and Olatunji Ruwase.
🎤 Featured at PyTorch Conference 2025
SuperOffload will be featured in the DeepSpeed & vLLM keynote at this year's PyTorch Conference in San Francisco.
🔥Come see how we're rethinking large-scale LLM training for the Superchip era: events.linuxfoundation.org/p…
3
12
2,715
DeepSpeed retweeted

6 Oct 2025
🚨Meetup Alert🚨
Join us for @raydistributed × @DeepSpeedAI Meetup: AI at Scale, including talks from researchers and engineers at @LinkedIn, @anyscalecompute and @Snowflake.
Learn how leading AI teams are scaling efficiently with Ray’s distributed framework and DeepSpeed’s model-training optimizations.
Agenda includes:
• Networking & welcome
• Tech talks: DeepSpeed overview, SuperOffload, Arctic Long Sequence Training, Muon optimizer, DeepCompile, and Ray in Snowflake ML
• Q&A networking
📍In-person at Anyscale HQ, San Francisco
Seats are limited — register now: luma.com/3wctqteh
1
2
11
3,701
9 Sep 2025
Step into the future of AI at #PyTorchCon 2025, Oct 22–23 in San Francisco 🔥 Join the DeepSpeed keynote and technical talks. Register: events.linuxfoundation.org/p…
Oct 21 co-located events: Measuring Intelligence, Open Agent & AI Infra Summits / Startup Showcase & PyTorch Training
2
7
2,886