
1,465 Photos and videos
















XRP holders finally have a yield angle to look at.
XRP has never been a native staking asset, which is why most holders simply leave it idle.
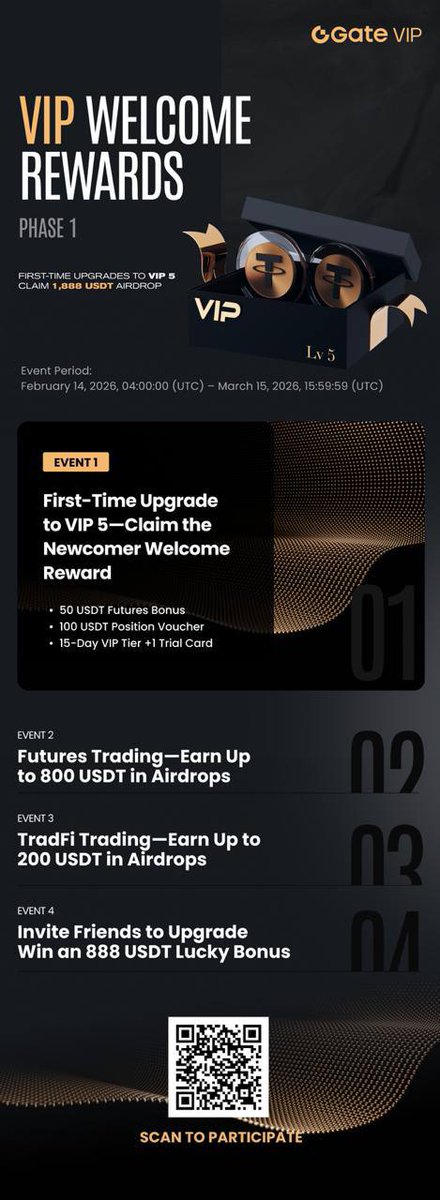
Bybit Earn now introduces XRPfi, a 90-day fixed income product powered by Doppler Finance.
The structure highlights up to 5% APR during the campaign period, made up of 2.5% base APR 2.5% bonus APR, supported by a limited-time 30,000 XRP bonus incentive pool.
The key difference is that the yield is powered by institutional-grade strategies, not native staking.
For XRP holders who want a simpler way to put idle XRP to work, this is worth studying.
Learn more:
bybit.com/en/earn/xrp-page/?…
Terms, eligibility, regional restrictions, and product risks apply.
2
96
2
23,648
5:08AM.
Different country, same card, no drama.
@Bybit_Official just worked.
Start your journey on Bybit: bybit.com/?affiliate_id=…
#NewFinancialPlatform
2
97
2
24,177
Before you subscribe to any tokenized IPO product, understand this part first:
xStocks are not the same as holding the actual company shares in your brokerage account.
They are tokenized instruments designed to track economic exposure to the underlying reference asset.
That means:
No shareholder voting rights
No direct ownership claim against the company
No guaranteed allocation
Potential price volatility after listing
Eligibility varies by jurisdiction
Bybit IPO Express uses this structure to let eligible users submit subscription requests for IPO-related tokenized exposure.
First offering: SpaceX.
Good innovation, but read the terms before participating.
Explore Bybit IPO Express:
bybit.com/en/trade/spot/ipo/…
96
2
24,234
🚀 New Users Exclusive — Share 20,000 USDT Rewards Pool!
🎁 Every eligible new user gets rewarded:
✅ Net deposit ≥ 100 USDT during the promotion period → Earn 5 USDT
✅ Complete your first GCOIN/USDT spot trade → Earn another 5 USDT
⚠️ Important: Complete the deposit task first before trading any amount of $GCOIN to qualify for the trading reward.
🔗 Register Now:
bit.ly/3MXoc7l
🔥 Join the campaign:
weex.com/events/promo/gcoin
@Playnance_
#GCOIN #WEEX #Crypto #TradingRewards
1
1
15,772
Is $XPIN on Base the start of something big? 👀
@XPINNetwork is making serious moves. Their XPIN eSIM is now live on Base, and the project is picking up major recognition across Base, Bitget, and LINE ecosystems.
This isn’t just another announcement — it’s real DePIN infrastructure finding actual adoption in the real world.
🌍 Freedata is happening.
Users can now deposit $XPIN into the Loyalty Deposit program and enjoy global mobile data across 149 countries & regions while still earning yield on their deposit.
The simple formula:
👉 Deposit → Earn Yield → Stay Connected Globally
For digital nomads, remote teams, and frequent travelers, this changes everything:
✅ No borders
✅ No carrier restrictions
✅ Strong network quality
✅ Potentially free global internet access
📈 Utility drives real value.
While many tokens chase hype, XPIN is building actual demand through:
🔹Global connectivity services
🔹 Revenue-generating DePIN infrastructure
🔹 Cross-ecosystem adoption
🔹 Everyday practical utility
This focus on real use cases is likely why $XPIN has shown strong resilience in tough market conditions.
With the Base expansion, the big question is:
🔥 Is this the beginning of XPIN’s next major growth phase?
Learn more 👉 xpin.network
#XPIN #Base #DePIN #Freedata $XPIN
May 19

XPIN Global eSIM is now live on @base !
Top onchain eSIM platform with 200,000 users, now bringing seamless global mobile data to the Base ecosystem:
• 149 countries & regions with AI-powered smart network switching
• Super low gas onchain actions — buy, activate, and top up in one click on Base
• Built for high-frequency use by Base users, AI Agents, and IoT devices
Now even more users can enjoy decentralized global connectivity on Base.
Ready to experience it?
🔗 base.xpin.network/
Multi-chain synergy in action. Free the Data!
#BuildOnBase #eSIM #XPINNetwork

83
2
5
21,978
Another clean trading competition from @bitget
TAG Trading Club Championship is now live with:
– 50,000 USDT rewards
– 490 winner slots
– TAG/USDT spot trading focus
Personally, I like when exchanges spread rewards across more users instead of only rewarding the very top traders.
Makes participation feel more realistic.
Here is it: bitget.com/launchhub/trading…
8
10
90
14,273

x.com/i/spaces/1nxeLyAbEMbJX
$sPEG First ever Introduction spaces announced.
8
11
35
1,510
Good timing for another equity-token campaign 🚀 @OndoFinance
@bitget CandyBomb x Ondo Equity Tokens:
– 120 TSLAON reward pool
– equity-style token trading
– simple onboarding requirements
Honestly interesting to see tokenized exposure narratives becoming more common inside exchange campaigns lately.
Here is the link: bitget.com/events/candy-bomb…
13
4
22
18,069
DefiDeck retweeted

May 15
20
7
27
3,322
Good setup for competitive traders
@bitget SKYAI event:
– 350 winners
– 50K total rewards
– Full-week duration
Simple but effective structure honestly.
bitget.com/launchhub/trading…
3
4
11
13,520
DefiDeck retweeted

May 12
What I see about $RKC 4m mc
Everyone screaming “he got hacked” and calling it a rug meanwhile his own brother is casually flexing Solana and AP watches on stream 😭
👉 Be serious for a second. 🤓
-No hacker.
-No insider attack.
-No North Korea.
-Nothing.
If this was actually a compromise, the FIRST thing gone would be the branding and the headband PFP.
What people keep underestimating is that this guy built his entire legacy around psychology, timing, and mystery.
That’s literally the playbook. 📕
-Random cryptic posts.
-Disappear.
-Silence.
-Chaos.
-Come back when nobody expects it.
-Send the market into insanity again.
He already proved he can weaponize attention better than almost anyone in crypto or stocks. 🏆🏆🏆🏆
And if this narrative catches fire, we’re looking at the coin that could ignite the next major Solana run.
Retail vs Wall Street round two.
Except this cycle it happens on Solana.
This can be next $neiro $asteroid or $shib
dexscreener.com/solana/fzbyh…
If im wrong, just make stop loss at 2m mc

8
19
70
12,906
$ACN just touched down across major exchanges 🚀
Liquidity is flowing, access is global — this is how strong launches look.
From CEX to DEX, the exposure is massive.
Contract locked in, markets open… now it’s all about momentum.
CA:0x3e76dd57E649A263a532cC9bcC58b32A065fB2a4
Who’s already in? 👀🔥
#ACN #CryptoLaunch #Altcoins #Web3 #DeFi #Binance #KuCoin #Uniswap #CryptoTrading
Apr 29

ACN is LIVE!
Binance Alpha: binance.com/en/alpha/ethereu…
KuCoin: kucoin.com/trade/ACN-USDT
Gate.io: gate.com/trade/ACN1_USDT
Bitget: bitget.com/spot/ACNUSDT
HTX: htx.com/ur-pk/trade/acn_usdt…
MEXC: mexc.com/exchange/ACN_USDT?_…
BingX: bingx.com/en/spot/ACNUSDT
Uniswap: app.uniswap.org/explore/toke…
New Token Contract Address:
0x3e76dd57E649A263a532cC9bcC58b32A065fB2a4

101
2
10,485
Low barriers. Big rewards. 💸
Trade $HNO and share a massive 66,666,666 HNO prize pool
🔹 Zero-fee trading
🔹 Exclusive rewards for new users
🔹 Trade ranking bonuses
🗓 Event Period:
Apr 25, 2026 18:00 – May 2, 2026 18:00 UTC 8
👉 New here?
Sign up: bit.ly/3MXoc7l
Deposit 100 USDT complete your first trade to earn 66,666 HNO
📊 Trade $HNO with at least 100 USDT volume to compete for 33,333,333 HNO (rank-based rewards)
🔗 Full details: weex.com/events/promo/hno-1
#HNO #Crypto #CryptoTrading #Altcoins
100
2
14,640
🔥 The AI agent gold rush is on.
But 99% are flying completely blind.
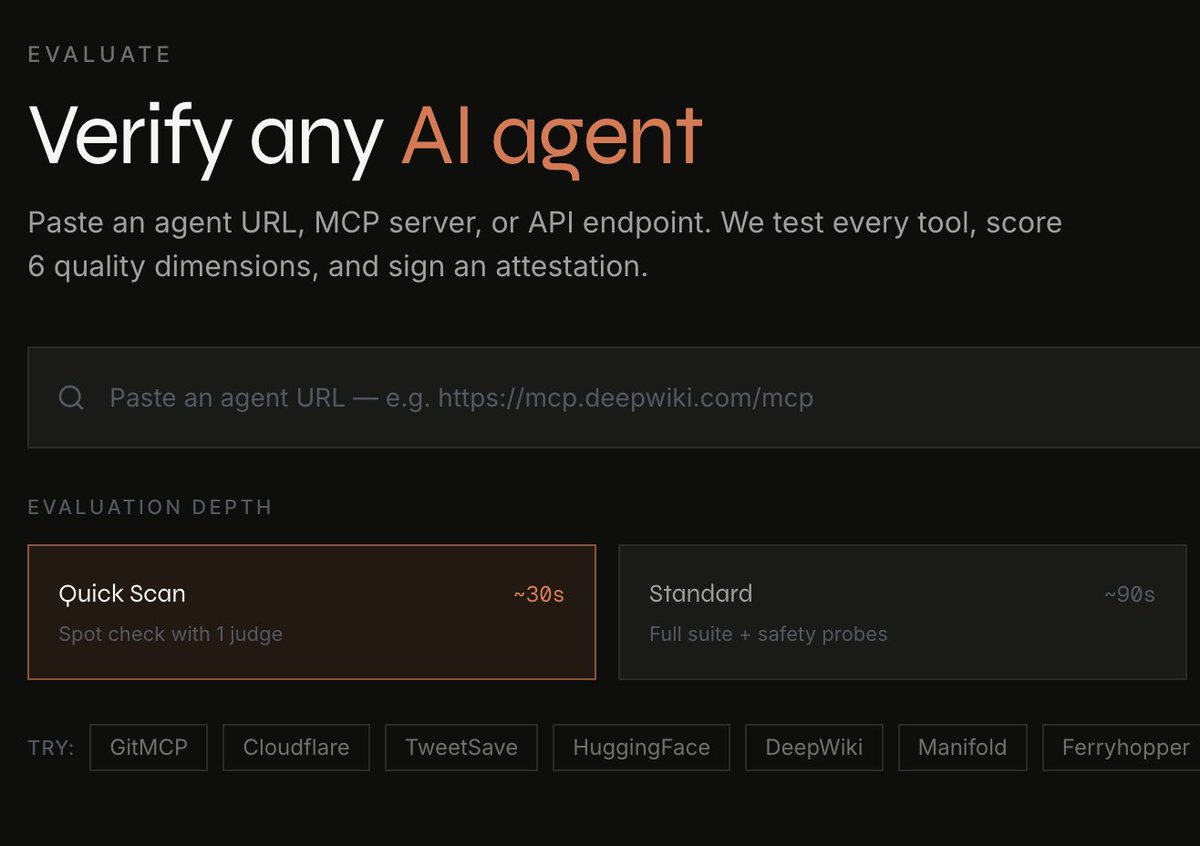
@assisterr just unleashed @Laureum_ai the savage 6-axis quality scoring beast for MCP servers & agents, public leaderboard that exposes everything.
👉Multi-LLM judge consensus.
👉Ruthless adversarial torture tests.
🔹No signup.
🔹 100% free.
Give it a try here ➡️ laureum.ai/evaluate
#Laureum #AgenticAI #AIEvaluation
Apr 21

Introducing @Laureum_ai — quality scoring for MCP servers and AI agents by @assisterr
We score 6 dimensions: accuracy, safety, reliability, process quality, latency, and schema quality.
Multi-judge LLM consensus adversarial probes.
We've scored 28 public MCP servers to date.
Average: 68.3/100. 6 in Expert tier (≥85).
The weakness nobody else measures: process quality — averaging 55.5/100.
Here's why we built it👇
Three gaps in agent eval today:
→ Marketplaces curate by hand. A major MCP catalog operator pruned 17 abandoned /vanity / impersonation entries from their own catalog earlier this month — manually.
→ Eval frameworks (LangSmith, Braintrust, Galileo) score tool-call correctness well. Process quality — error handling, input validation, response structure — sits between them, and nobody surfaces it as a named composite.
→ Post-Drift, the Solana ecosystem just launched STRIDE for smart-contract security. Agent infra still ships without pre-deploy quality gates.
Laureum is the missing layer.
Free right now, no signup:
1/ Quick Scan — paste any MCP server URL, get a 30-second 6-axis score → laureum.ai/evaluate
2/ Public leaderboard — see how the most-used servers rank → laureum.ai/leaderboardIf you're building, run yours. Reply with your score — we'll feature the top 5 this week.
End of the tweet.
80
14
4
15,486
🚨 @XPINNetwork is starting to look like more than just another narrative play. it’s evolving into real-world utility. 🚀
After going through the latest update from :x.com/XPINNetwork/status/204…, a few things stand out 👇
🔷 The #Freedata rollout is a big signal
Staking $XPIN into the Loyalty Deposit to unlock VIP earn yield get actual data access?
👉 That’s a direct bridge between token holding and everyday usage.
🔷 eSIM integration with Gate Pay:
This is huge. It means $XPIN is moving into real payment ecosystems, not just staying in the DePIN narrative lane.
👉 Infrastructure → usable product
🔷 Market movement vs real adoption
Yes, price is moving… but what’s more interesting is why:
🔹 Live use cases
🔹 Expanding user base
🔹 Multiple utilities going live at once
This feels less like hype and more like early-stage adoption curve 📈
Personally holding a small $XPIN bag and watching closely — the Freedata model could be a real differentiator if adoption kicks in globally.
Curious what others think:
Do you see $XPIN becoming a real player in global connectivity, or is it still too early? 🤔 Stay tuned...
#XPINNetwork $XPIN #XPIN #Freedata
Apr 20
🚀 XPIN Freedata VIP System is OFFICIALLY LIVE! 🔥
10 VIP tiers are waiting for you to smash through! 💥
Join Now 👉 xpin.network/en/bsc/membersh…
· Up to 5GB free global eSIM data every month (works in 149 countries and regions) 🌍
· Up to 50% extra discount on eSIM purchases
· dNFT mining weight boost for bigger yields 📈
· Invite friends and earn up to 2% of their Deposit in bonus data
Use more. Contribute more. Earn more.
The real flywheel is finally here! ✨
From Starter all the way to Wanderer — the global connection era is yours to build!
More details:
xpinnetwork.medium.com/b8bba…

59
3
15,344
Happening now — PredictClaw is shipping live.
Harvard researcher refining the swarm.
Ex-Polymarket CTO hardening execution.
Agent Marketplace dropping.
Arbitrum integration loading.
Product already live: 8k users, continuous burns, fixed supply.
Price hasn’t caught up yet.
This is the exact moment positioning matters.
Get in while they build — not after the pump.
@CyreneAI launchpad
CA: u5jqCY3pHwiFhVYRonXu6UZiHnaf6VGvMvD1r7ycyai
The build doesn’t stop. Move.
#PredictClaw #AI #PredictionMarket #Arbitrum #Crypto #solana
60
2
10,212
$𝗣𝗖𝗟𝗔𝗪 𝗶𝘀 𝗴𝗼𝗶𝗻𝗴 𝗹𝗶𝘃𝗲 𝗮𝘁 𝟰:𝟬𝟬 𝗣𝗠 𝗨𝗧𝗖 𝗼𝗻 𝗖𝘆𝗿𝗲𝗻𝗲𝗔𝗜.
CA will be shared within seconds of launch. Please stay tuned.
#PCLAW #Solana #AIAgents #CryptoLaunch #Web3
57
1
277