
21 Photos and videos

Deitek retweeted

May 19
Introducing Gemini 3.5: our newest family of models combining frontier intelligence with real-world action.
The first release is 3.5 Flash, our strongest model yet for agents and coding 🧵

124
386
3,744
796,071

Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
2,118
5,973
56,797
21,663,247
Deitek retweeted

Apr 3
Thanks for following us!
We're excited to see what you all build with Gemma 4!
In case you missed it, you can find all our checkpoints, with an Apache 2.0 License, on Hugging Face:
134
331
5,781
404,448

Holy smokes... Anthropic just accidentally dropped entire Claude Code source code 😬
Code in reply
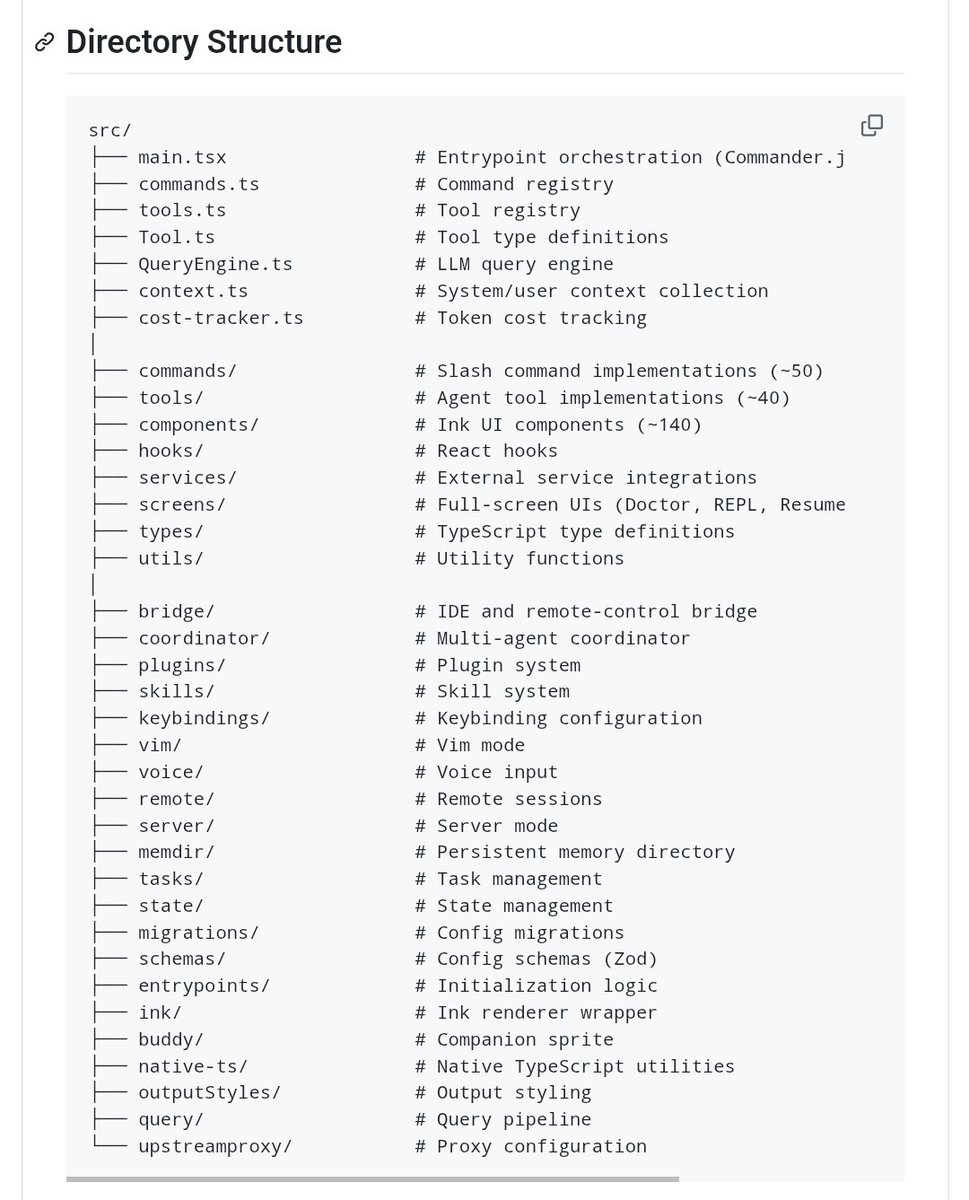
Mar 31

Claude Code just got open sourced again!
69
58
558
144,701
Deitek retweeted

Mar 31
Claude Code's full source code just leaked via a .map file in their npm registry.
Direct link: pub-aea8527898604c1bbb12468b…
One guy already backed it up on GitHub.
Repo: github.com/nirholas/claude-c…


Mar 28

Claude Mythos 5.0 Beta is already rolling out.
Anthropic quietly started giving users access to their next-gen flagship model - the same one from the leaked internal blog post that had everyone talking.
It’s live right now:
-> Main Claude interface shows Mythos 5.0 Beta ("Larger and more intelligent")
-> Claude Code lists Mythos 5 (experimental) as straight-up "Next-gen model"
Early insiders say it’s an absolute monster at coding, reasoning and offensive security, so ridiculously strong that the first leaks reportedly sent cybersecurity stocks tumbling.
This is your sign to smash that Max tier upgrade right now.
Follow for updates.
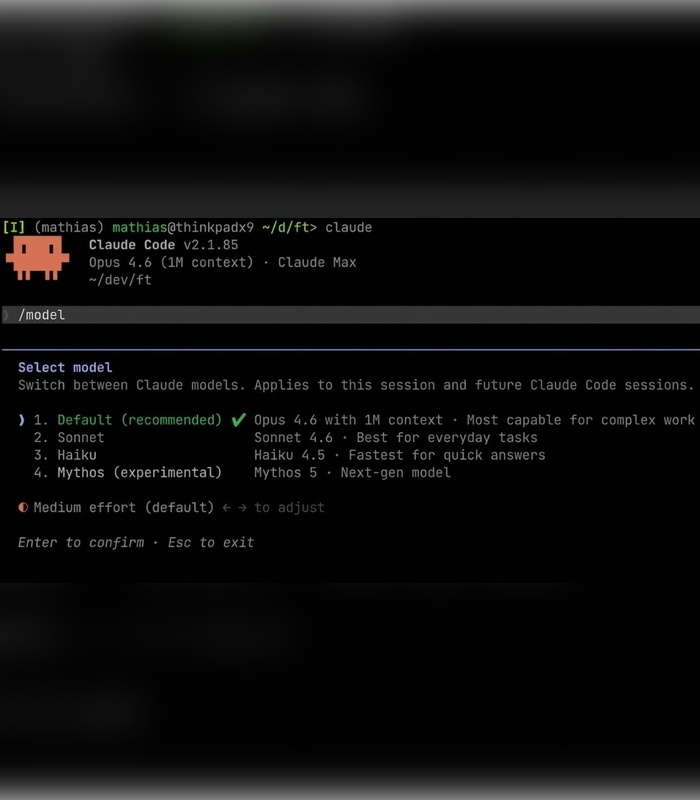

Community note
Anthropic has not released a public beta for Claude Mythos. While a data leak confirmed the model's existence, Anthropic stated it is only in internal testing with planned limited access for cybersecurity experts, not general users.
fortune.com/2026/03/26/ant…
36
29
226
90,470

Deitek retweeted

Mar 26
Mistral releases a new open-source model for speech generation techcrunch.com/2026/03/26/mi…
14
41
167
24,000

Deitek retweeted

Mar 11
🎉 Congrats to @nvidia on the release of Nemotron 3 Super — day-0 support in vLLM v0.17.1! Verified on NVIDIA GPUs.
120B hybrid MoE, only 12B active at inference. Big upgrades over the previous Nemotron Super:
- 5x higher throughput
- 2x higher accuracy on Artificial Analysis Intelligence Index
- Multi-Token Prediction (MTP) for faster long-form generation
- Configurable thinking budget — dial accuracy vs token cost per task
- 1M token context window
Supports BF16, FP8, and NVFP4. Fully open: weights, datasets, recipes.
Blog: vllm.ai/blog/nemotron-3-supe…
🤝 Thanks @NVIDIAAIDev Nemotron team and vLLM community contributors!

Mar 11

Introducing NVIDIA Nemotron 3 Super 🎉
Open 120B-parameter (12B active) hybrid Mamba-Transformer MoE model
Native 1M-token context
Built for compute-efficient, high-accuracy multi-agent applications
Plus, fully open weights, datasets and recipes for easy customization and deployment. 🧵
11
32
344
44,583
Deitek retweeted

Mar 13
🦞 Developers can run @OpenClaw on NVIDIA DGX Spark, bringing powerful agentic workflows directly onto NVIDIA Grace Blackwell systems.
The step‑by‑step playbook is now available: build.nvidia.com/spark/openc…

59
124
883
125,571
Deitek retweeted

Mar 12
Perplexity Pro users: Enjoy using Computer. Rolling out to all of you on web.
Being on the Max plan will guarantee you monthly promotional credits and higher usage-based spending limits.
Mar 12

Perplexity Computer is now available for Pro subscribers.
Access Computer’s full suite of 20 advanced models, prebuilt and custom skills, and hundreds of connectors.
Max subscribers receive monthly credits and higher spend limits than Pro.
perplexity.ai/computer
51
30
511
52,534
Deitek retweeted

29 Nov 2022
Want to win tickets to @quantum_miami? We will give away 2 VIP tickets each Tomb Tuesday.
To participate:
🔵Follow @tombfinance, @quantum_miami, @Official_LIF3, @FantomFDN and @Felix_Exchange
🔵Like & RT this post
🔵Tag 2 friends below👇
#LIF3 $FTM $TOMB #BTC #DeFi #Crypto

77
85
143

👉I just joined the @vervetvapp IDO Whitelist
🔥GET YOUR GUARANTEED IDO ALLOCATION TODAY! @bscpad @MetaVPad @nft_launch @gamezone_app @velaspad @PulsePad_App
#playtoearn #nft $nft #Crypto #Defi #velas #p2e #eth #bnb #bsc #vlx #stream #content swee.ps/cAEPXH_XUwFTqs
2
👉I just joined the @vervetvapp IDO Whitelist
🔥GET YOUR GUARANTEED IDO ALLOCATION TODAY! @bscpad @MetaVPad @nft_launch @gamezone_app @velaspad @PulsePad_App
#playtoearn #nft $nft #Crypto #Defi #velas #p2e #eth #bnb #bsc #blockchaingaming #interactive swee.ps/cAEPXH_XUwFTqs
I just joined the #SecureDeFi IDO Whitelist on #BSCPAD #ETHPAD #KCCPAD #TRONPAD
GET YOUR GUARANTEED IDO ALLOCATION ON @bscpad @kccpad_official @tronpadofficial @ethpadofficial
TG: t.me/SecureDeFi_Official
$BTC $ETH $BNB #BSC #KCC #TRON # swee.ps/dAVmBQ_DtOEztw
1
I just joined the #SecureDeFi IDO Whitelist on #BSCPAD #ETHPAD #KCCPAD #TRONPAD
GET YOUR GUARANTEED IDO ALLOCATION ON @bscpad @kccpad_official @tronpadofficial @ethpadofficial
TG: t.me/SecureDeFi_Official
$BTC $ETH $BNB #BSC #KCC #TRON #defi swee.ps/dAVmBQ_DtOEztw
👉I just joined the @DOTPad_io IDO Whitelist
🔥GET YOUR GUARANTEED IDO ALLOCATION TODAY! @bscpad @adapadofficial @nft_launch @gamezone_app @velaspad @kccpad_official @tronpadofficial @ethpadofficial @MetaVPad @PulsePad_App
#dot #polkadot #blue swee.ps/uBELBq_dTgRvDp
👉I just joined the @DOTPad_io IDO Whitelist
🔥GET YOUR GUARANTEED IDO ALLOCATION TODAY! @bscpad @adapadofficial @nft_launch @gamezone_app @velaspad @kccpad_official @tronpadofficial @ethpadofficial @MetaVPad @PulsePad_App
#dot #polkadot #bluezilla swee.ps/uBELBq_dTgRvDp
I just joined the #WorldOfDefish @WorldOfDefish
IGO Whitelist on #GameZone #BSCPad
🔥GET YOUR GUARANTEED IDO ALLOCATION TODAY! @bscpad @gamezone_app
TG: t.me/worldofdefish
#NFTgaming #NFT $NFT #Gaming #BSCgem #BSC #metaverse #blockchaingaming swee.ps/cAdACg_qXROZEP
2
I just joined the #WorldOfDefish @WorldOfDefish
IGO Whitelist on #GameZone #BSCPad
🔥GET YOUR GUARANTEED IDO ALLOCATION TODAY! @bscpad @gamezone_app
TG: t.me/worldofdefish
#NFTgaming #NFT $NFT #Gaming #BSCgem #BSC $BNB #play2earn #BNB #m swee.ps/cAdACg_qXROZEP