
Generalist happiest with problems bigger than my grasp. Low-level tinkerer, slow walker/thinker. UMD CS. AI, DBs, PLs. Making things faster, better, simpler.
Joined June 2020
- Tweets 1,464
- Following 2,419
- Followers 141
- Likes 1,778
13 Photos and videos






ReLU: mm256_setzero_ps is called outside the loop, providing an instantaneous, memory-free floor function via _mm256_max_ps.
GELU: SIMD unroll 0.5 * x * (1 tanh(sqrt(2/pi) * (x 0.044715 * x^3))) algebraic curve func.
interleave re im with _mm256_shuffle_ps
1
8
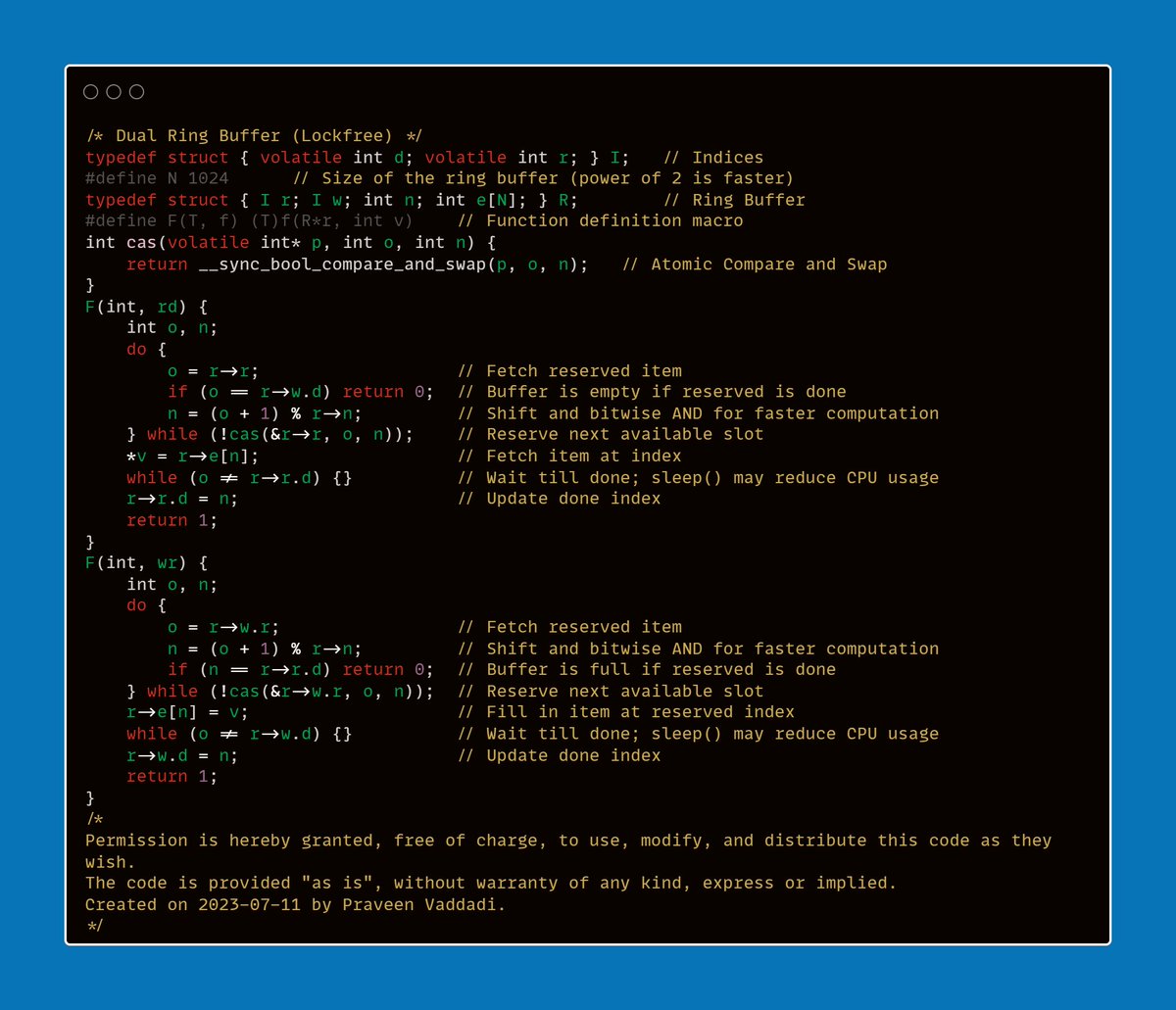
rnn state transitions encoded to bitflags; integer underflow (0 - 1 = UINT_MAX) gets us free warp index; branchless, inlining, etc. std. simult. mean var (welfords algo) for layernorm; reuse bufers for backward passes; _mm256_loadu/storeu_ps > memcpy .
3
for autograd, flag nodes in the DAG so backward traversal returns early (sever branches in backprop). hardcode identity ops t osave cycles. bitshift 16bit sparse tensor indices t opack in uint64. fast sgemm/dgemm. _mm256_xor_ps breaks dep chains.
1
5
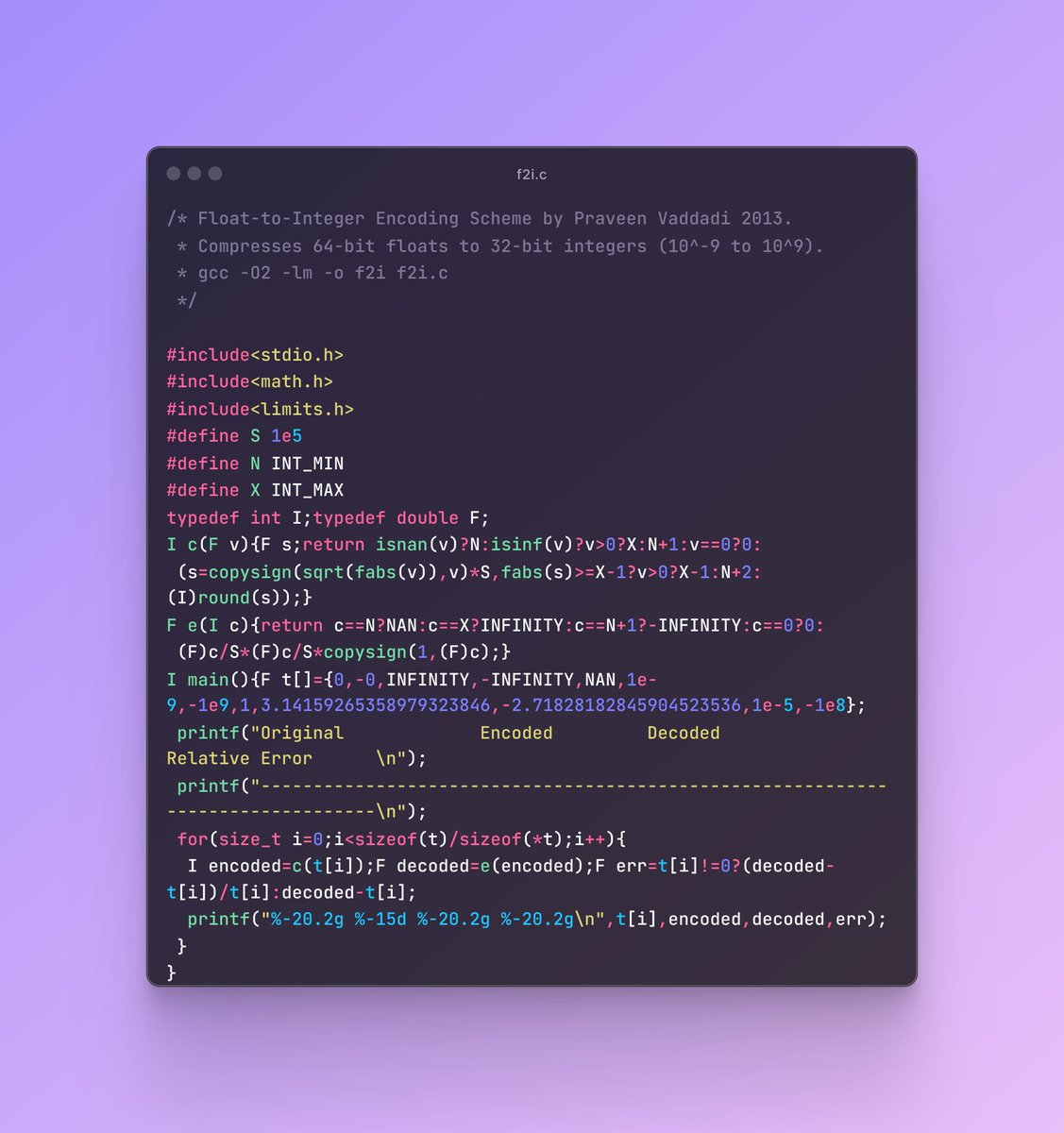
_mm256_cvtps_ph upasts bf16 to fp32 in register. avoid libm (exp, tanh...) - use poly approx. from computer approximations book. Before exp(), do _mm256_max_ps sweep to subract max value from all elements to ensure the maximum input to exp() is exactly 0.0.
1
5
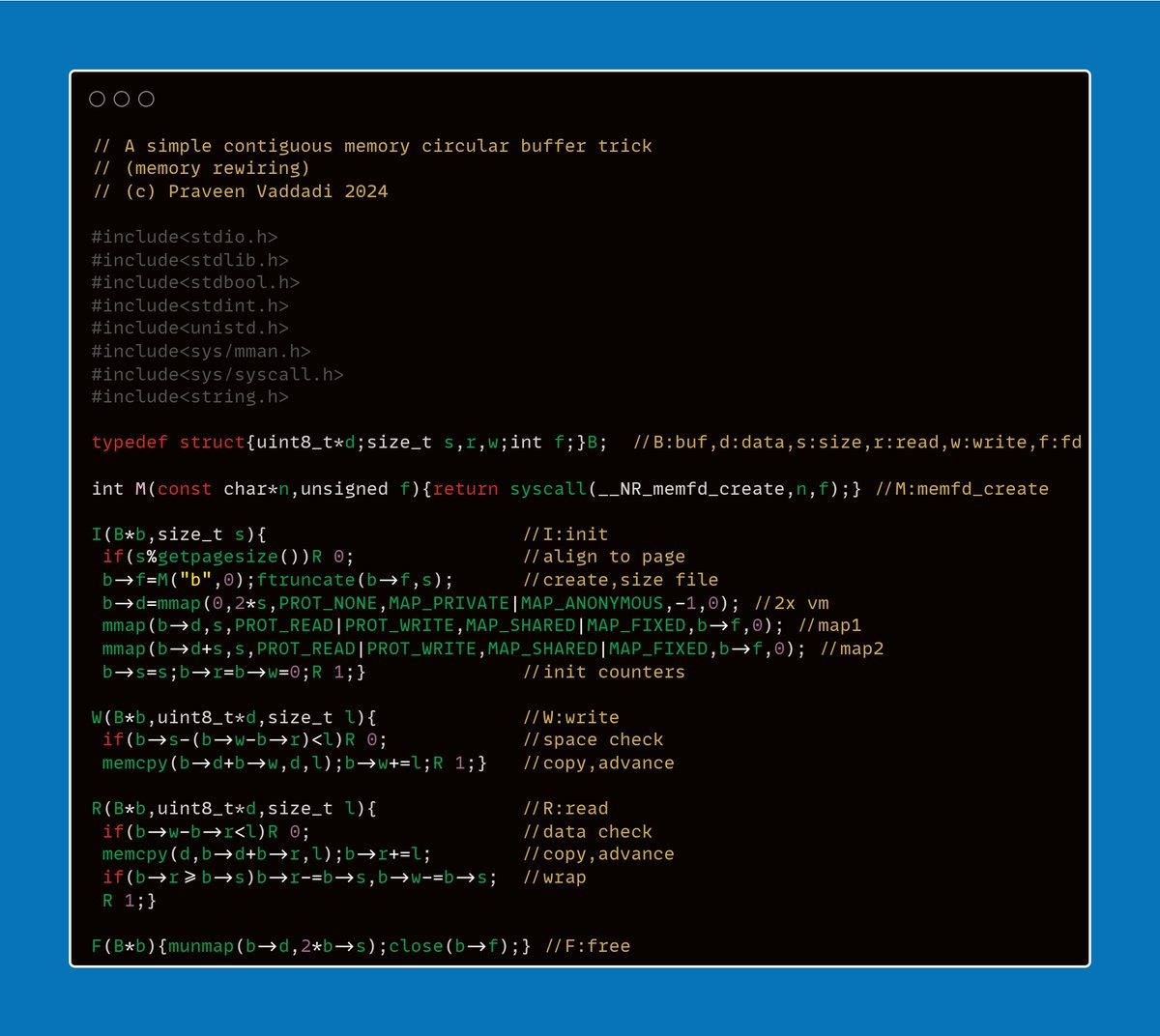
allocate (calculated) abs peak memory required by the mode graph at startup. put a 8/16 byte header before tensor payload carrying meta info like refcounts, dimensions etc. zero copy mmap (serde.h) OR blast from fopen/fseeko... into arena buffers.
1
8
int8 quant; inflate to 32float at avx2 exec unit. _mm256_cvttps_epi32 crushes frac data into ints. _mm_packus_epi32 to push back down 16/32 bit products ints. lazy fuse chained ops int osingle loop pass.
1
3
mmap based allocator with tensory payloads (2d,3d,4d,..) as flat 1d block (32 byte aligned). buddy alloc is faster. some dead/padding between thread-local vars to avoid false sharing.
1
2
a unified tensor abstraction layer (for CPU and optional GPU) with void* buffers and dynamically mapped func pointers so same C DAG routes both execution paths.
1
3
thread count = core count persistent thread pool; lock CPU's rounding behavior first (DAZ, FTZ, etc. to system state?)
1
1
#notes The anatomy of a tiny neural network compute engine (in C) for CPUbound inference & training.
why: pytorch and tf are too heavy for executing sequence models like gpt/rwkv etc.
how: a lazy DAG that compiles to fused avx2 with int8 quantization, work-stealing concurrency.
1
10

May 18
You can write a surprisingly large class of software under 1.44Mb (a floppy): editors, databases, games, even operating systems. Beyond that, it is usually more abstraction paying for excess.
2
48
May 8
Natural language is little-endian: lower-significance bits come first as shared context, and higher-significance bits come later as the informative payload.
38
Praveen Vaddadi retweeted

Mar 24
This 1-pager from Xusheng Li on GDB internals of how watchpoints are implemented is a delight to read! (especially that double-write behaviour false positive - I did not know about that)

5
81
361
22,065
Mar 23
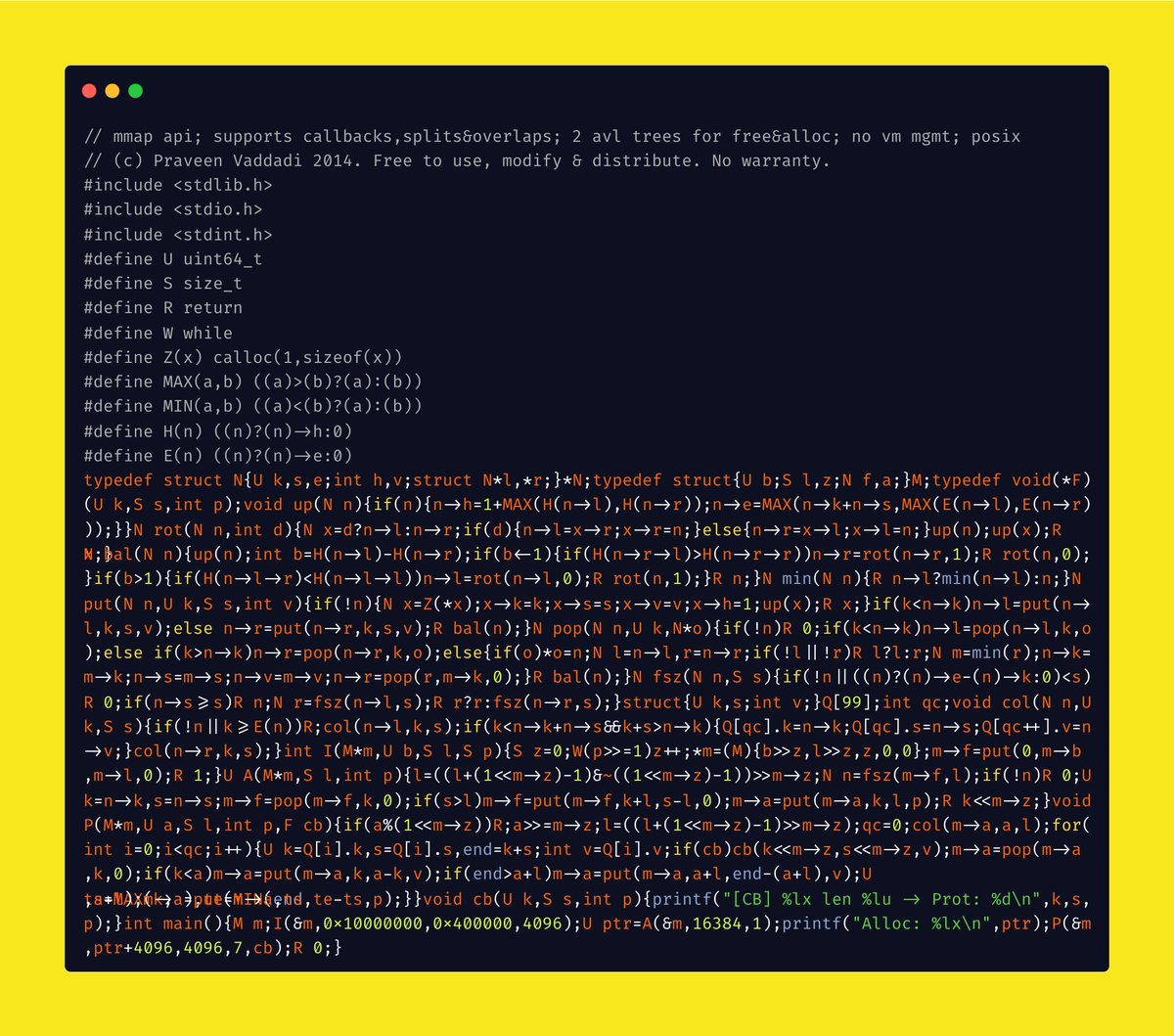
github.com/xtellect/spaces is a C allocator with explicit heap regions. It can work as a drop-in allocator, or give each subsystem its own heap, cap it, inspect it, and destroy it in one step.
64
Mar 3
In AI, a fab/hardware bet may actually be cheaper than backing yet another software startup.
1
33
Mar 3
Fabs have massive fixed costs but near-zero marginal costs and strong long-term pricing power. AI software is hyper-competitive, supply-constrained today but structurally deflationary. Capital may compound better at the chip layer than in crowded model apps.
30