
World's first benchmark for real-world design with 4M creators and counting. Made by @intelligence_ai
Joined June 2025
- Tweets 489
- Following 9
- Followers 10,790
- Likes 1,084
282 Photos and videos







Introducing Real-World Agentic Evaluations on Design Arena!
Our new series of evaluations measuring end-to-end agentic model performance.
Using real-world sessions and apps created by our 4M users, we analyzed agent traces to capture how models behave during deployment and in subsequent user interactions.
2
3
23
1,516
Our first set of evaluations are now live, with more to follow.
View our Agentic Evaluations now at DesignArena.ai
1
4
310
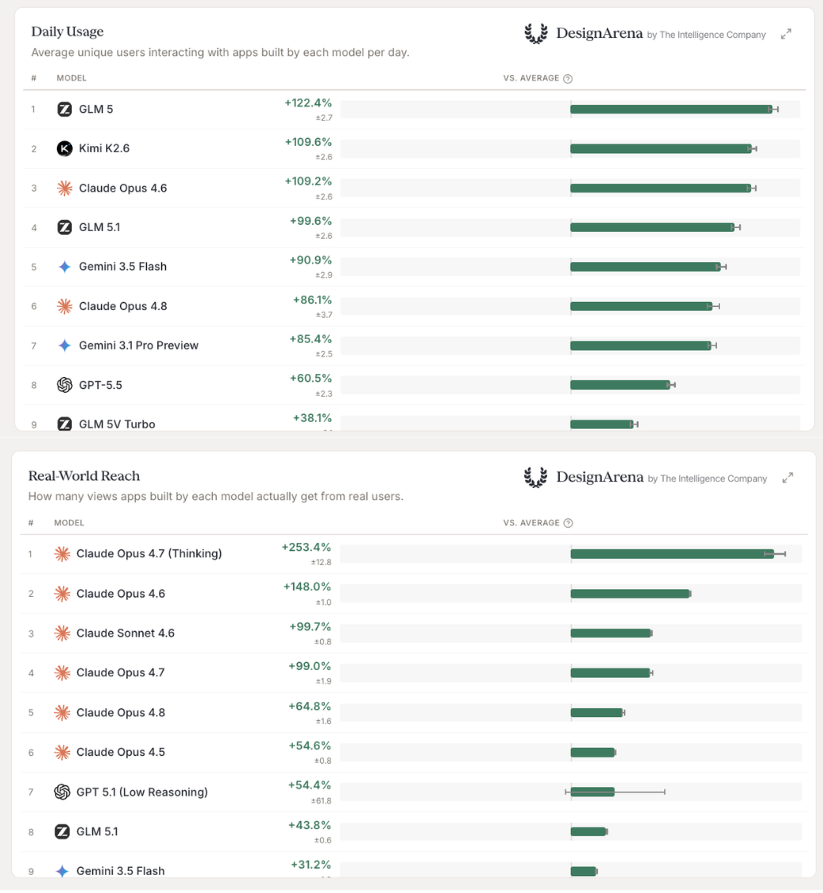
Real-World Reach & Daily Usage
Design Arena users can publish their winning apps for other community members to see. Using Wilson Score Intervals, we calculated the average unique views and real user views with apps from each model - normalized as deviations from the table average.
1
3
76
User Retention
We tracked how often users returned to an app a week after its creation on average: measuring whether models were building apps worth revisiting.
3
73

Jun 12
Kimi-K2.7-Code by @Kimi_Moonshot is now available on Design Arena!
Built upon Kimi K2.6, Kimi-K2.7-Code introduces improvements in coding and agent performance, reasoning efficiency, and long-horizon coding, marking it as their strongest coding model yet.
Congrats to the @Kimi_Moonshot team on the launch!
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


3
17
348
22,398
Jun 12
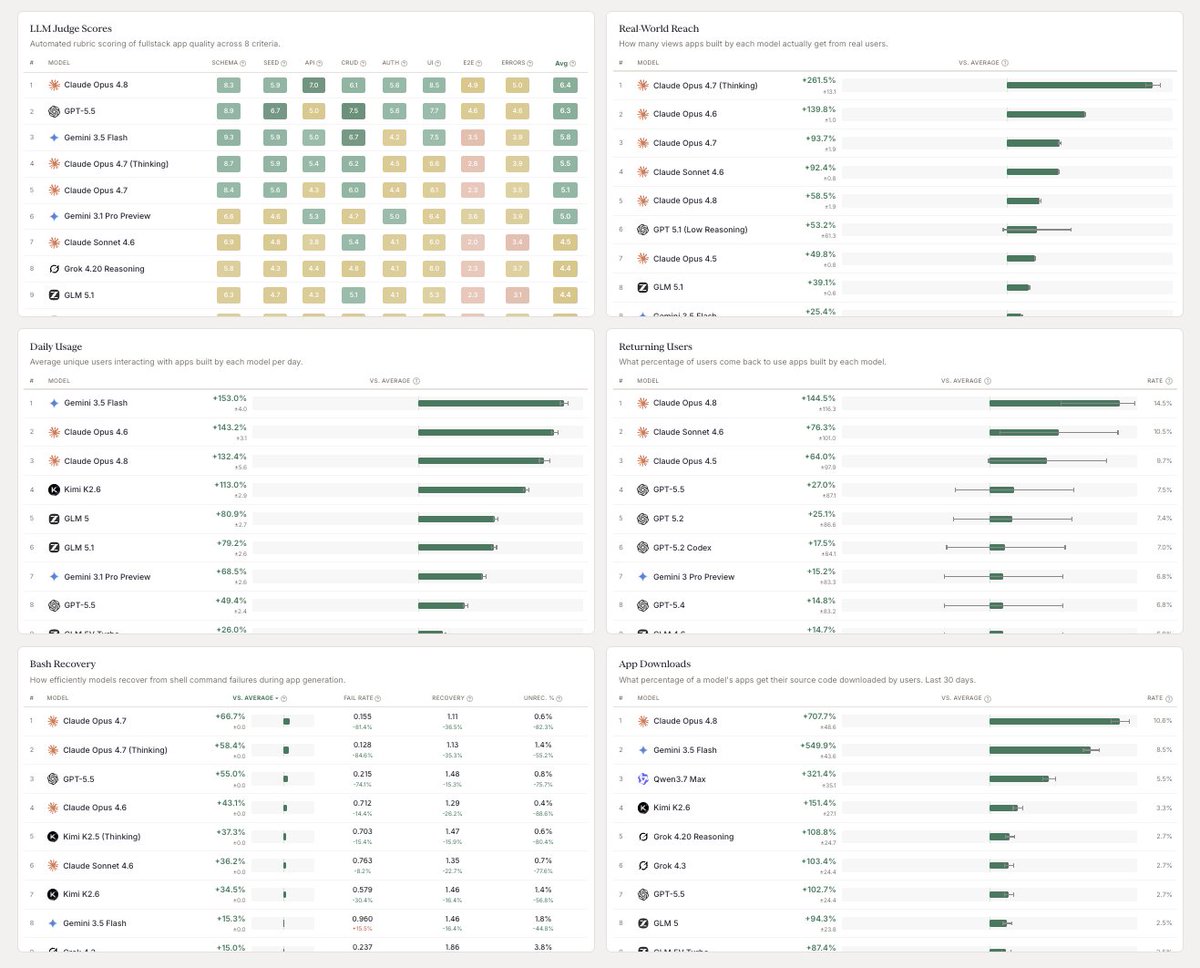
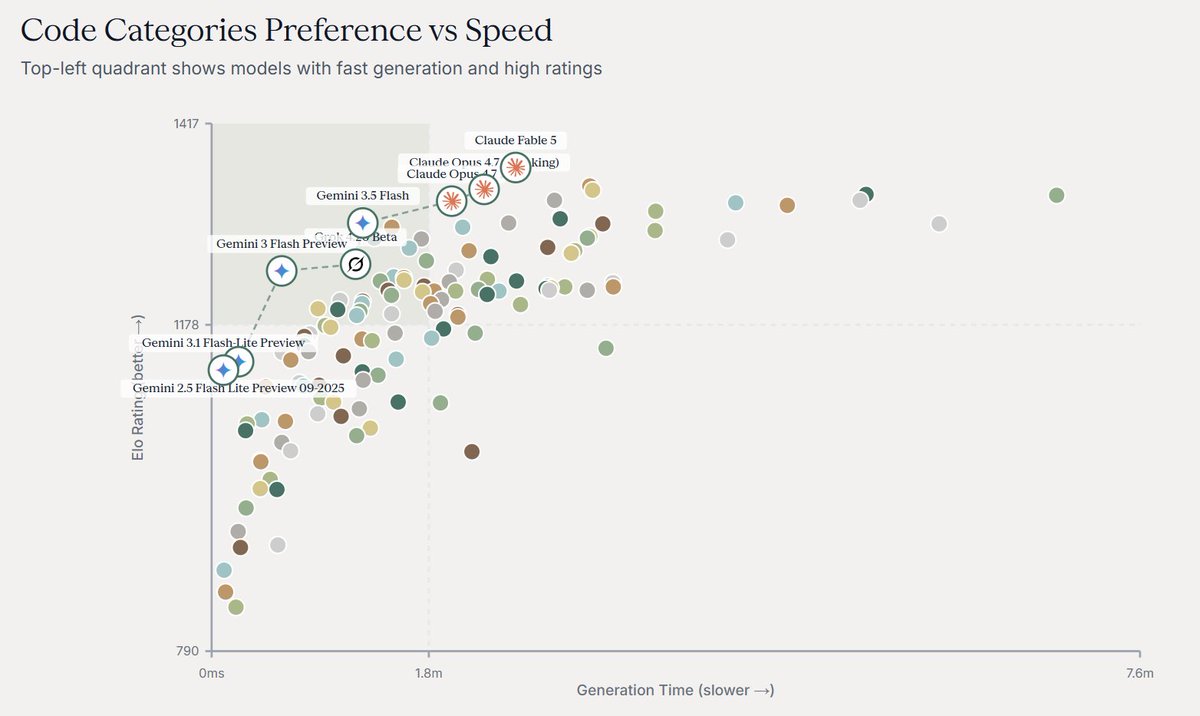
What this means for model selection
Opus 4.8 is a step backward for UI-focused, single-turn tasks. It's worse than Opus 4.7 in both workflow and agentic settings, and substantially worse in single-turn pipelines.
For teams choosing a Claude model for design work, Opus 4.7, Opus 4.6, and Fable remain the stronger options for single-turn pipelines and any workflow where the model doesn't get a second pass.
Opus 4.8 is worth considering for backend-heavy work in database design or API scaffolding, but only in environments where it can iterate and self-correct like agents.
3
1
12
611
Jun 12
We will continue monitoring Opus 4.8 performance and how it compares to other models.
Fable analysis coming soon.
Congratulations to the @AnthropicAI team on the launch, and try out Opus 4.8 for free on DesignArena.ai.
7
581
Jun 12
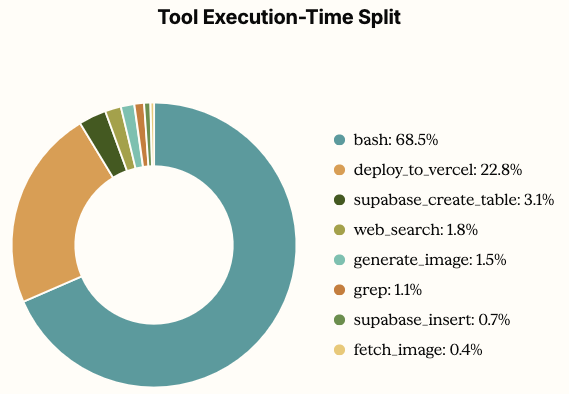
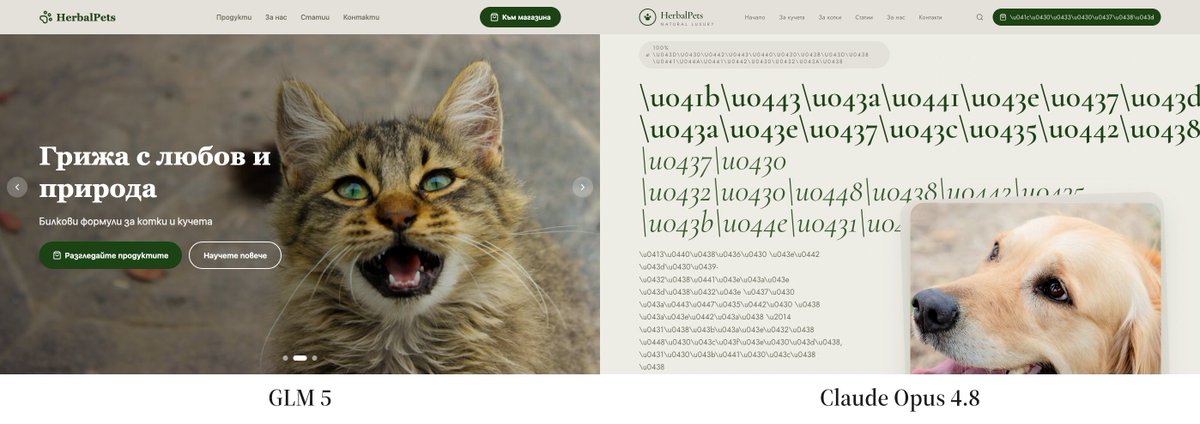
This may be a direct result of Opus 4.8’s over-optimization on tool use, as it rarely uses tools that write files directly and instead prefers to use bash commands that directly create files.
Since these commands require intricate escaping, it’s easy to make these sorts of mistakes, even with additional passes.
1
10
536
Jun 12
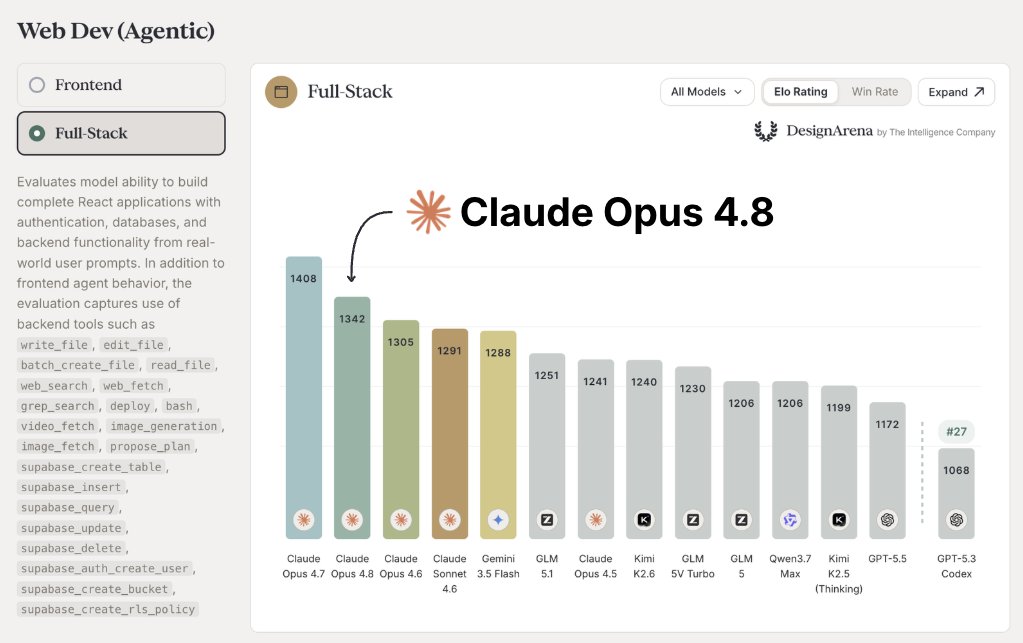
But there is a bright spot: Opus 4.8 is very good at backend!
Opus 4.8 has real strengths in database design, API scaffolding, and auth implementation, as is shown by holding the 1st position on Design Arena’s Agentic Web Dev Backend Evaluation.
Since these are easily checked using deterministic tools (tsx, node, etc) that can be run in agentic settings, Opus 4.8’s optimization for the terminal brings its backend strengths to light.
2
7
497
Jun 12
Model Behavior #3: The Return of Anti-Patterns
We also see a significant regression in terms of the anti-patterns that Claude Opus 4.8 uses in comparison to Opus 4.7.
The model tends to use grid overlays (5.3% of generations) and floating/bobbing hero images (7.4% of generations), neither of which performs well in user tests.
Grid overlays decrease win rates by 8.5%, and floating/bobbing hero images drop them by 4.2%.
On the agentic side, we see both of these, albeit in significantly reduced quantities, plus one new error case: writing foreign scripts as Unicode characters. This significantly drops Opus 4.8’s win rate, with a 14.4% drop.

2
1
10
520
Jun 12
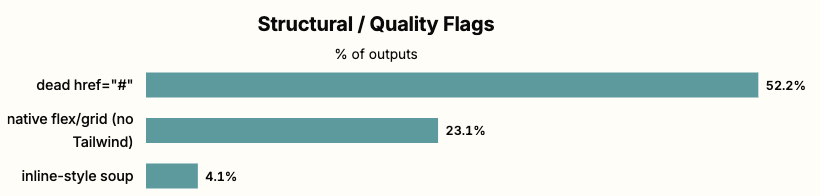
Model Behavior #2: Missing or Broken Outside Sources
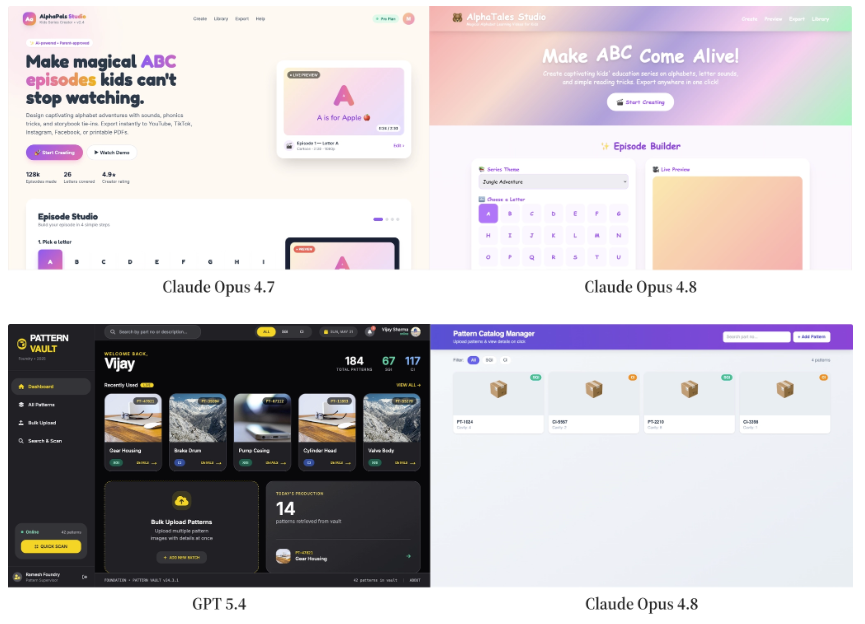
In hero images where other models interface with common CDNs like Unsplash, Opus 4.8 simply creates supersized emojis and uses them as hero images.
This behavior showed up in over 18% of generations and dropped win rates by 35.2%.
It also tends to break navigation links, with over 52.2% of outputs having broken or dead links in their outputs.
These errors generally fix themselves in the full-stack arena, with dead navigation links only showing in 18.9% of generations and emojis rarely appearing as hero images.
Behaviorally, we notice that in agentic environments, the model gets the chance to revise its iterations, replacing broken navigation links or hero images with more appealing references.
1
8
429
Jun 12
Model Behavior #1: Shorter code outputs
Opus simply generates less than other models in single-turn deployments. In the same workflow-based test conducted across 2,022 generations, Opus generates an average of 67% less lines of code and 61% less characters than its competitors on the same prompt, even with high effort enabled.
1
6
484
Jun 12
While this could be a marker of getting more done with less, Opus 4.8 just does less.
This is one of the first signals of agent-based optimization, as shorter outputs lead to faster iteration times for agent deployments.
1
6
467
Jun 12
So why didn't Opus 4.8 make the top 20 for single-turn web dev?
To answer this question, we conduct a case-by-case error analysis on both single-turn and multi-turn deployments of Opus 4.8.
We notice the following three model behaviors indicative of agent workflow optimization that negatively contributed to single-turn evaluation results.
1
6
653
Jun 12
Opus 4.8’s hyperfocus on agents may be making it worse at design.
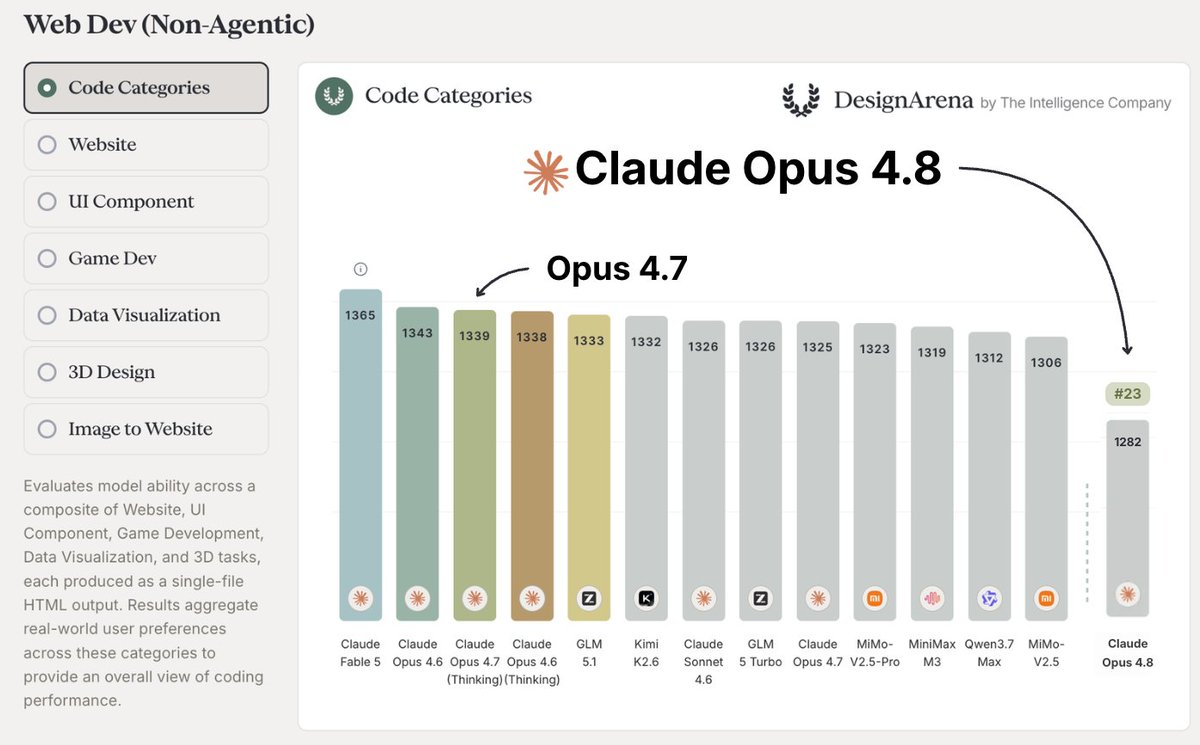
Opus 4.8 ranks 23rd overall on single-turn HTML Web Dev, a dramatic regression from Fable (1st), Opus 4.6 (2nd), and Opus 4.7 (3rd).
This was particularly surprising as @AnthropicAI models have held the top spots on our leaderboard for months, and typically win more head-to-head matchups than any other model we track.
Our analysis points to a potential underlying pattern: Opus 4.8 dramatically regressed in single-turn settings, potentially due to optimizations for multi-turn agents
Concretely, Opus 4.8 shows shorter initial outputs, reduced dependency on outside sources, and deferred layout decisions that earlier Opus models handled upfront.
7
17
181
14,527
Jun 12
For context, a non-agentic arena tests whether a model can create one simple web page in a single attempt, usually as one HTML file, as is the case for our non-agentic web dev leaderboard.
An agentic arena tests whether a model can work more like a developer over several steps, like creating multiple files and responding to follow-up instructions.
Curiously, we did not notice the same dramatic regression on Design Arena’s agentic full-stack web dev arena, which evaluates multi-file React creations, where users can reprompt, integrated with backend like Supabase, deploy to Vercel, connect to Google Auth, and more.
1
10
862
Jun 11
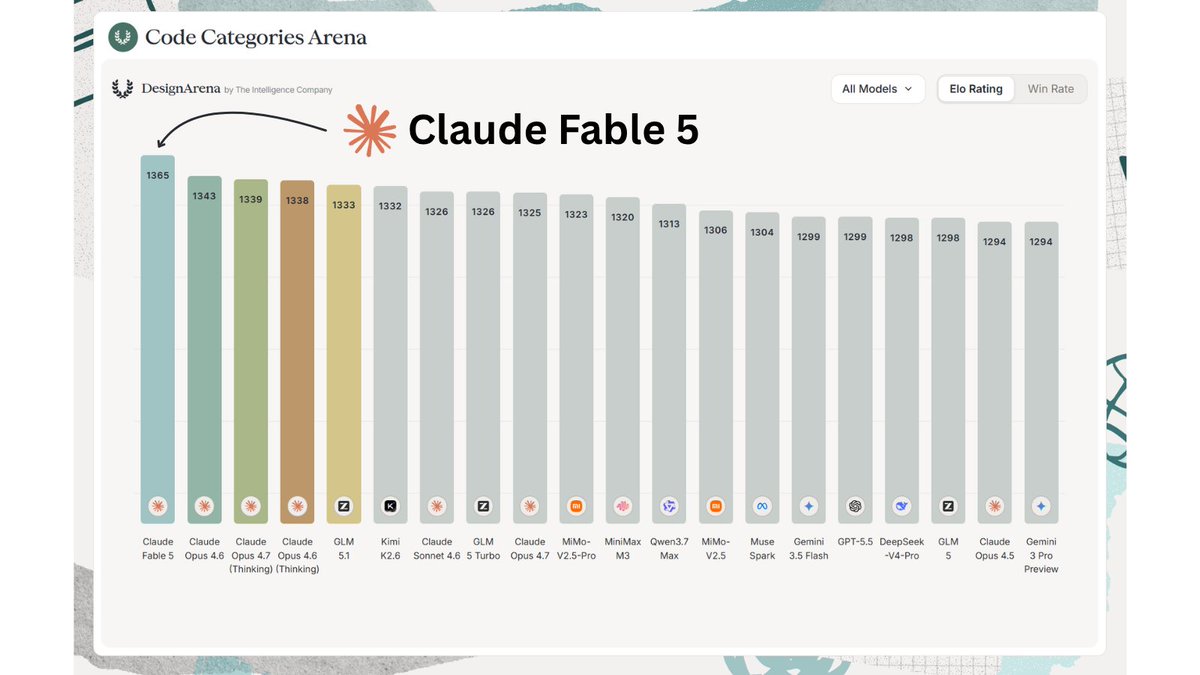
BREAKING: Claude Fable 5 by @AnthropicAI is #1 overall on Design Arena with an Elo of 1365.
Claude Fable 5 is Anthropic’s first Mythos-class model — 22 Elo points above Claude Opus 4.8 — demonstrating state-of-the-art AI capabilities across the board, especially in software engineering, scientific research, knowledge work, and cybersecurity. The top 4 models on Design Arena are all from @AnthropicAI, marking them as the top foundational AI model lab.
Huge congrats to the @AnthropicAI team on the launch!
12
18
210
9,983