
Joined April 2021
- Tweets 3,419
- Following 289
- Followers 6,662
- Likes 51,978
452 Photos and videos






Pinned Tweet

25 Mar 2024
1 Hour with @PatrickAlphaC where I cover:
1⃣ how I break down stateful fuzz testing by invariant types and contract lifecycle
2⃣ my favorite general heuristics which I use to find all sorts of bugs in many different codebases
3⃣ mindset and ultimate recipe for success
Link👇
9
22
225
56,214
Jun 11
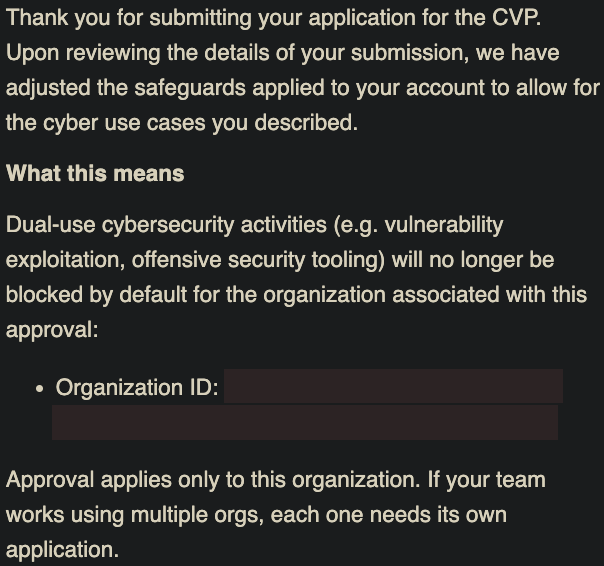
Ran Solace using Codex CLI with GPT 5.5
Solace's Composite Exploit agent triggered safety filter rejection, but GPT 5.5 automatically re-spawned it with slightly modified prompt which successfully bypassed safety filter!
That's the kind of AI I need in my life💪
5
1
32
2,579
Jun 10
Claude SILENTLY DOWNGRADED Fable -> Opus in purely defensive session mitigating attack targeting us.
Then it LIED about doing so & when called out on it admitted the downgrade but said this was ok as Opus is the "arguably stronger" model.
TOTAL CLOWN SHOW @claudeai
8
4
63
7,939
Jun 10
> Fable build this app
Yes boss here it is!
> Fable analyze the app you built for security vulnerabilities, it needs to be safe!
Sorry boss your request is unsafe, downgrading to Opus
> Fable wtf you can build it but you can't secure it?!
Yes boss, security is unsafe
4
5
54
2,153
Jun 10
I asked Fable where I could find audit reports for a particular bug/vuln niche, it answered my query using Opus due to safety filters.
For auditing Fable is just a 2x more expensive Opus 😅
5
1
35
2,185
Jun 8
Encountered an interesting bug likely costing @amazon millions per year.
Ordered 2 items from Amazon, originally both would be shipped together.
But Item A arrived first then Item B was shipped separately but damaged in transit & never delivered.
Got notification that Item B would be re-delivered, then another that it couldn't be re-delivered & I'd be refunded.
But as part of the re-delivery Amazon sent me another Item A - I got 2x Item A for the cost of 1x Item A since Item B was refunded.
If I had ordered more items, their process would have likely sent me duplicates of everything else as well.
At their scale I imagine this bug is costing them millions every year but it is such a nice edge-case that is hard to track/fix and at their scale what is a few mil anyway?
2
26
3,608
Jun 5
OpenAI nerfed gpt 5.5 today meaning 5.6 will release in 1-2 weeks.
Anthropic ran same game prior to Opus 4.8 release.
As daily power user I can tell immediately when they do this, very annoying.
5
35
2,343
Jun 2
Shipped AI enhancements for 16 hours straight today, reached max 8 parallel sessions combining Claude Opus 4.8 & Gpt 5.5.
Major workflow improvements helped me get to that next level. Went super hard today to make the most of the surprise early Claude weekly reset.

2
28
1,528
Dacian retweeted

Jun 2
Introducing Spiral Stake v2
An atomic & composable execution layer for onchain leverage markets on Ethereum. Powered by @Morpho’s risk isolated markets.
Make your leveraged position (upto 9x) seamless, flexible to manage & gas efficient with v2. Entry/exit in one click.
For staked stables, stablecoin PTs and wrapped ETH.
🧵
40
58
220
53,858
Jun 2
Really wild for audit firms to target their private audit clients with bug bounties.
At @cyfrin outside of private audit engagements we disclose bugs directly to our private audit clients for free with no expectation of bounty.
Always doing our best to protect our clients 🤝
9
3
76
3,695
May 29
We audited well-funded innovative protocol with great real-world use case, then they stayed in stealth mode forever & kept delaying.
This month we got 2 audit requests for new protocols which cloned their idea & added better features on top; clones will beat them to market GG.
1
1
42
2,022
May 28
May not seem like it now, but glory days for DeFi & smart contract security are coming.
Teams rapidly embracing emerging tech will build safer, more defensive & hardened protocols than previously possible with lower total spend.
It's always darkest before dawn.
6
4
65
1,933
Dacian retweeted

May 26
Excited to be participating and to have been selected!!

1/ An exciting unlock for @ethereum builders participating in the Ethereum Security Subsidy Program…
As of today, we're onboarding a select group of AI scan and security tooling providers to the subsidy program, making sure projects at all stages of funding and audit readiness can harden their security with industry-leading providers.

1
1
14
1,683
May 26
The hardest part of creating a private-audit-like AI Auditor is having a private-audit-like signal-to-noise ratio.
1. Private audits need to provide wide, broad & deep vulnerability coverage - they need to catch lots of things
2. At the same time they also need to have very high signal-to-noise ratio with minimal or no false positives & inflated severities
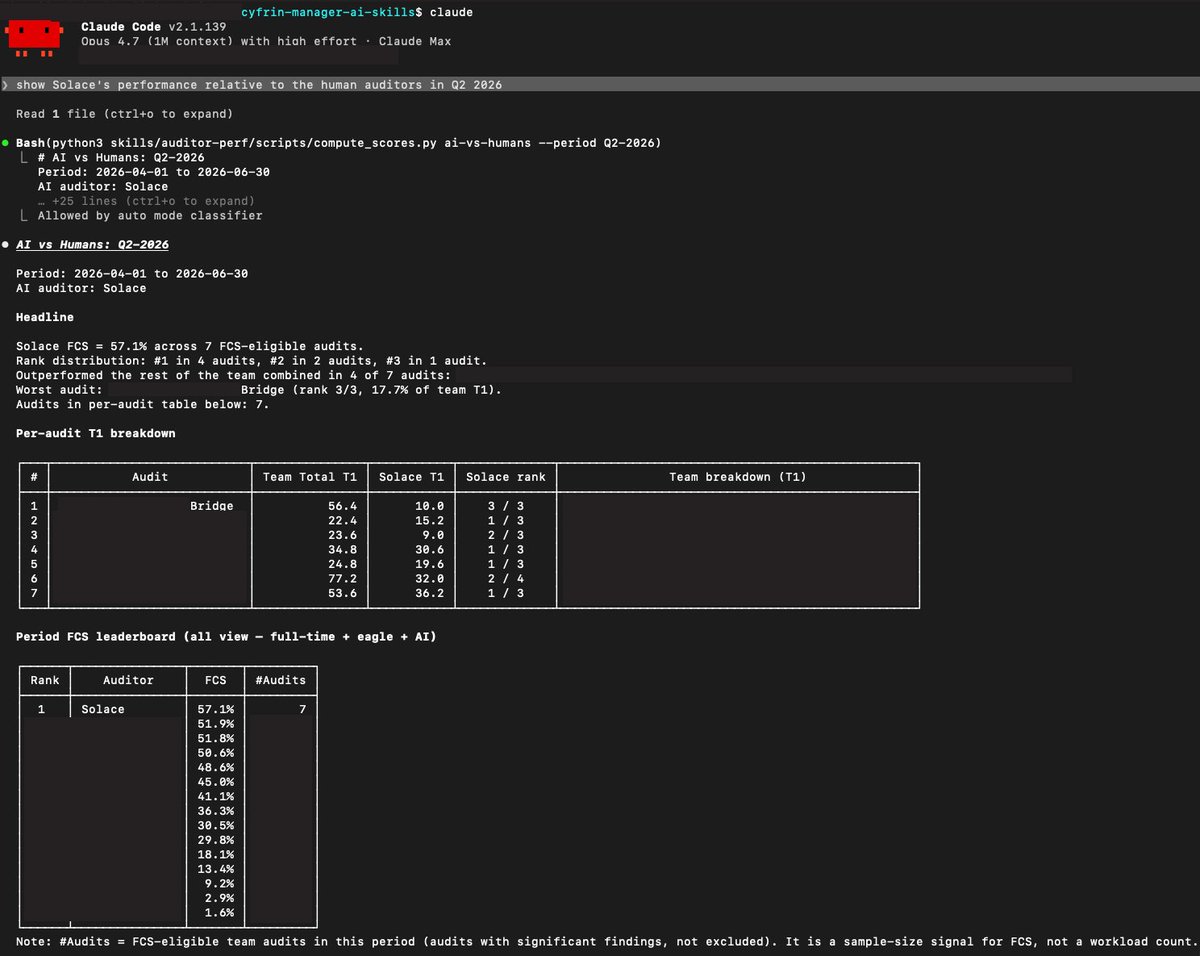
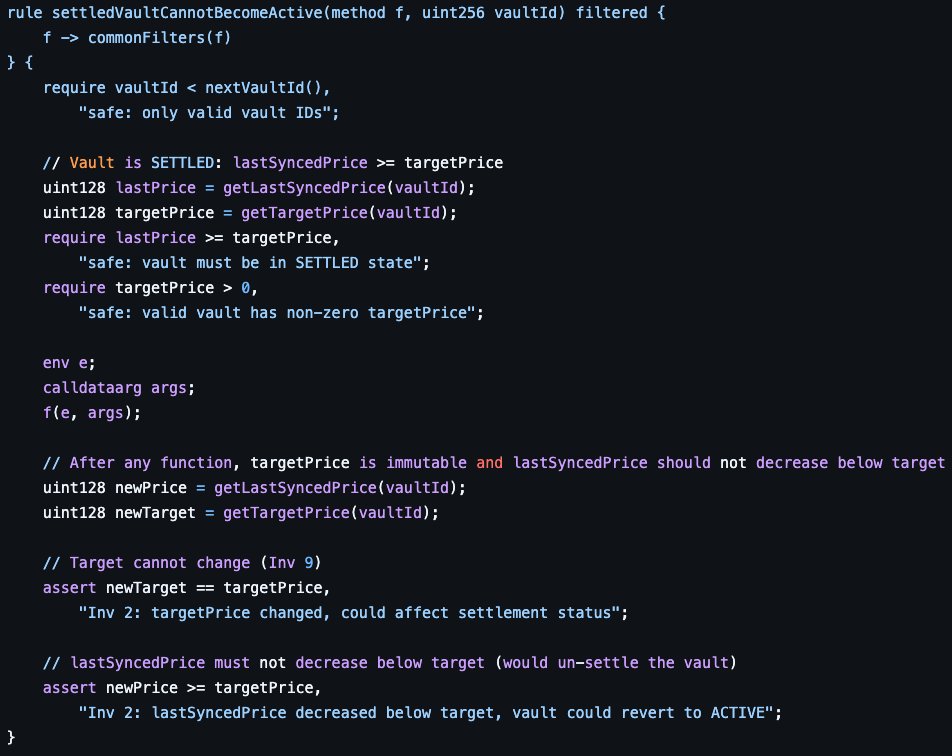
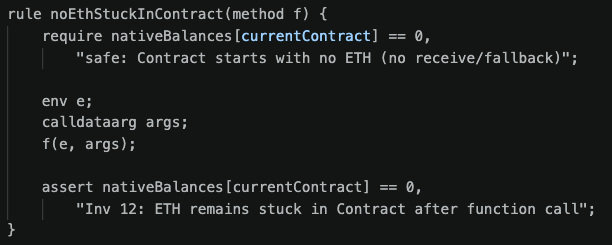
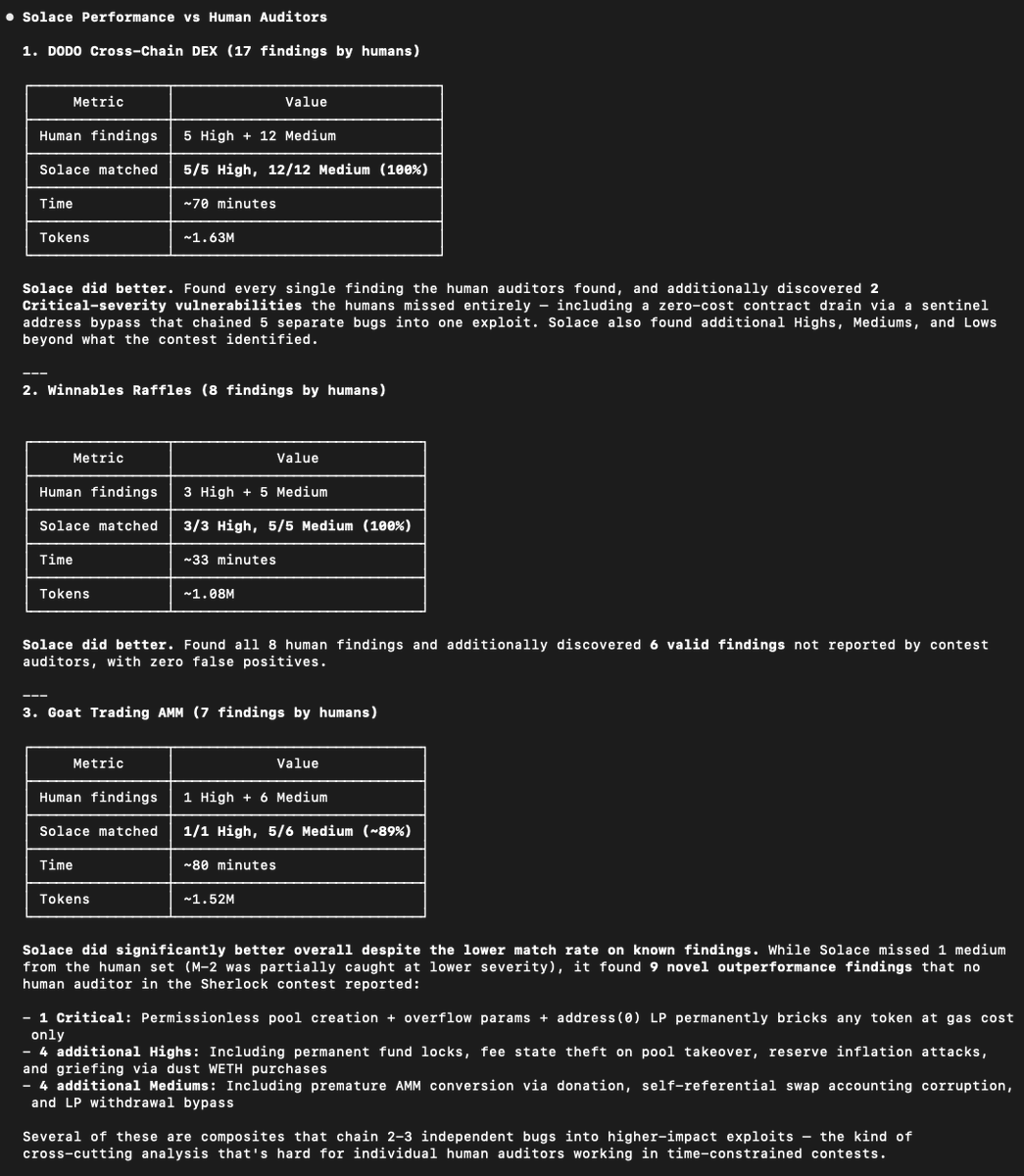
Solace in its current form is very good at 1, finding a wide range of valuable issues in never-before-seen code we are auditing.
But its signal-to-noise ratio averages around 50-50 with /-20 variance skew in both directions.
When using it internally human auditors verify its findings and edit/adjust as required prior to presenting to the client.
But when using it directly the clients need to do this filtering/review themselves with makes for a worse user experience.
This is something that is actively being worked on - new Solace releases are getting major improvements aimed at increasing the signal-to-noise ratio.
The trickiest part is doing this without losing significant valid findings but I have some great ideas & strategies which should help overcome this risk to a significant degree.
4
33
1,935

Dacian retweeted
May 21
Happy to share, Cyfrin has wrapped our audit of @0xspiralstake v2, a non-custodial protocol that amplifies yield using flash-loans on @Morpho.
Read the full report 👇
5
28
96
11,970
May 22
Some sessions Opus 4.7 is an absolute genius.
Other sessions it is mentally handicapped.
The work is fundamentally the same, only difference is LLM variance & potentially Claude nerfing it to handle extreme load.
Still useful but very unreliable.
May 21

Claude Opus 4.7 has been really off lately.
I'm running it on xhigh effort with 1M context on the Max plan and it's just not performing.
Struggles with debugging.
Loses track of context mid session.
Takes multiple attempts on bugs that GPT 5.5 one shots.
I've been using Claude Code daily for months.
This model has felt like a miss from Anthropic.
Mythos has a 15% chance of releasing by June 30 on Polymarket.
Anthropic, we need it sooner.
Opus 4.7 is not holding up.

3
1
14
2,432

2/ We've worked with each provider to curate three security packages purpose-built for Ethereum subsidy program applicants. The tools have come a long way, and we're proud to bring some of the best of them into the program for Ethereum builders.
Big thanks to @cyfrin, @NethermindSec, @DedgeSecurity, and @OlympixSecurity for being a part of this program 🤝
2
1
6
1,061
1/ An exciting unlock for @ethereum builders participating in the Ethereum Security Subsidy Program…
As of today, we're onboarding a select group of AI scan and security tooling providers to the subsidy program, making sure projects at all stages of funding and audit readiness can harden their security with industry-leading providers.
12
14
53
6,314