
Astro ML PhD student @jodrellbank @OfficialUoM. she/her
Joined July 2012
- Tweets 76
- Following 455
- Followers 134
- Likes 2,463
7 Photos and videos






27 Nov 2025
I will be at @NeurIPSConf in San Diego from Dec 2-7, please reach out if you want to chat about AI for science, uncertainties, probabilistic ML, astronomy etc!
I will be presenting two papers at the #ML4PS workshop on Dec 6 -
1
1
3
165
27 Nov 2025
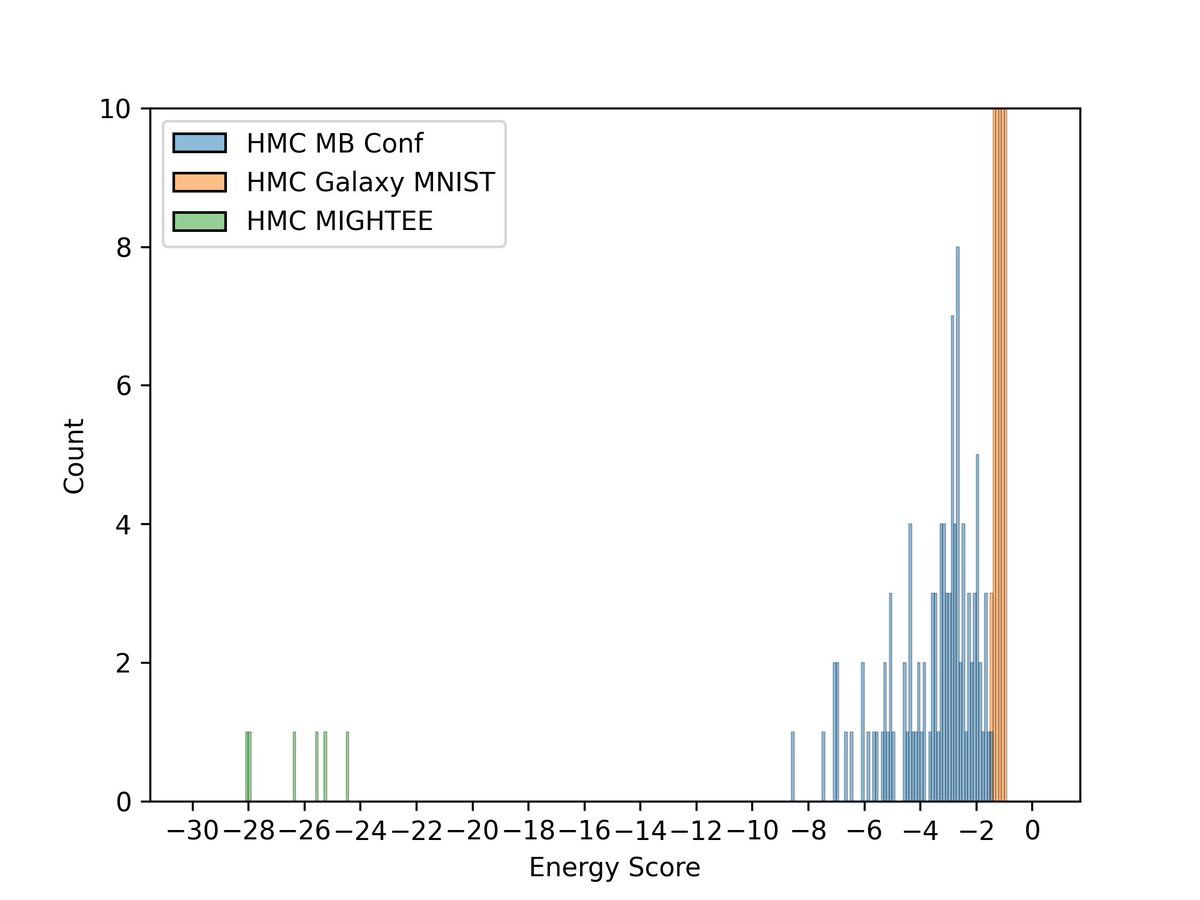
2. We examine diffusion model based intrinsic dimension estimates of the Radio Galaxy Zoo dataset (large unlabelled dataset) as a function of energy scores from an HMC based Bayesian neural network trained on a small labelled dataset (MiraBest)…
1
145
27 Nov 2025
…and find that OoD samples have higher ID estimates
arxiv.org/abs/2511.11490 (work led by @QuerFont , who will also be at NeurIPS! Email him if you want to have a chat.)
1
130
Devina Mohan retweeted

3 Dec 2024
The (true) story of development and inspiration behind the "attention" operator, the one in "Attention is All you Need" that introduced the Transformer. From personal email correspondence with the author @DBahdanau ~2 years ago, published here and now (with permission) following some fake news about how it was developed that circulated here over the last few days.
Attention is a brilliant (data-dependent) weighted average operation. It is a form of global pooling, a reduction, communication. It is a way to aggregate relevant information from multiple nodes (tokens, image patches, or etc.). It is expressive, powerful, has plenty of parallelism, and is efficiently optimizable. Even the Multilayer Perceptron (MLP) can actually be almost re-written as Attention over data-indepedent weights (1st layer weights are the queries, 2nd layer weights are the values, the keys are just input, and softmax becomes elementwise, deleting the normalization). TLDR Attention is awesome and a *major* unlock in neural network architecture design.
It's always been a little surprising to me that the paper "Attention is All You Need" gets ~100X more err ... attention... than the paper that actually introduced Attention ~3 years earlier, by Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio: "Neural Machine Translation by Jointly Learning to Align and Translate". As the name suggests, the core contribution of the Attention is All You Need paper that introduced the Transformer neural net is deleting everything *except* Attention, and basically just stacking it in a ResNet with MLPs (which can also be seen as ~attention per the above). But I do think the Transformer paper stands on its own because it adds many additional amazing ideas bundled up all together at once - positional encodings, scaled attention, multi-headed attention, the isotropic simple design, etc. And the Transformer has imo stuck around basically in its 2017 form to this day ~7 years later, with relatively few and minor modifications, maybe with the exception better positional encoding schemes (RoPE and friends).
Anyway, pasting the full email below, which also hints at why this operation is called "attention" in the first place - it comes from attending to words of a source sentence while emitting the words of the translation in a sequential manner, and was introduced as a term late in the process by Yoshua Bengio in place of RNNSearch (thank god? :D). It's also interesting that the design was inspired by a human cognitive process/strategy, of attending back and forth over some data sequentially. Lastly the story is quite interesting from the perspective of nature of progress, with similar ideas and formulations "in the air", with a particular mentions to the work of Alex Graves (NMT) and Jason Weston (Memory Networks) around that time.
Thank you for the story @DBahdanau !

133
985
6,684
862,504



🤔 Variational learning is often thought to be impractical
🔥 Plot twist: it actually works better than Adam!
Meet IVON, a new optimizer that brings the best out of variational learning – 🧵 (1/9) #NLProc #ICML2024
📰 arxiv.org/abs/2402.17641
youtu.be/TRNYnRRJBRg
1
6
19
4,457
16 Jul 2024
I will be at my poster (#750) from 4.30 today @UncertaintyInAI! #UAI2024
openreview.net/forum?id=JX5R…
29 May 2024

1
13
1,027
Devina Mohan retweeted

27 Jun 2024
Some thoughts/ideas, "pêle-mêle" as we say in French, about VI and MCMC after attending #ProbAI.
statmodeling.stat.columbia.e…
3
17
1,802
29 May 2024
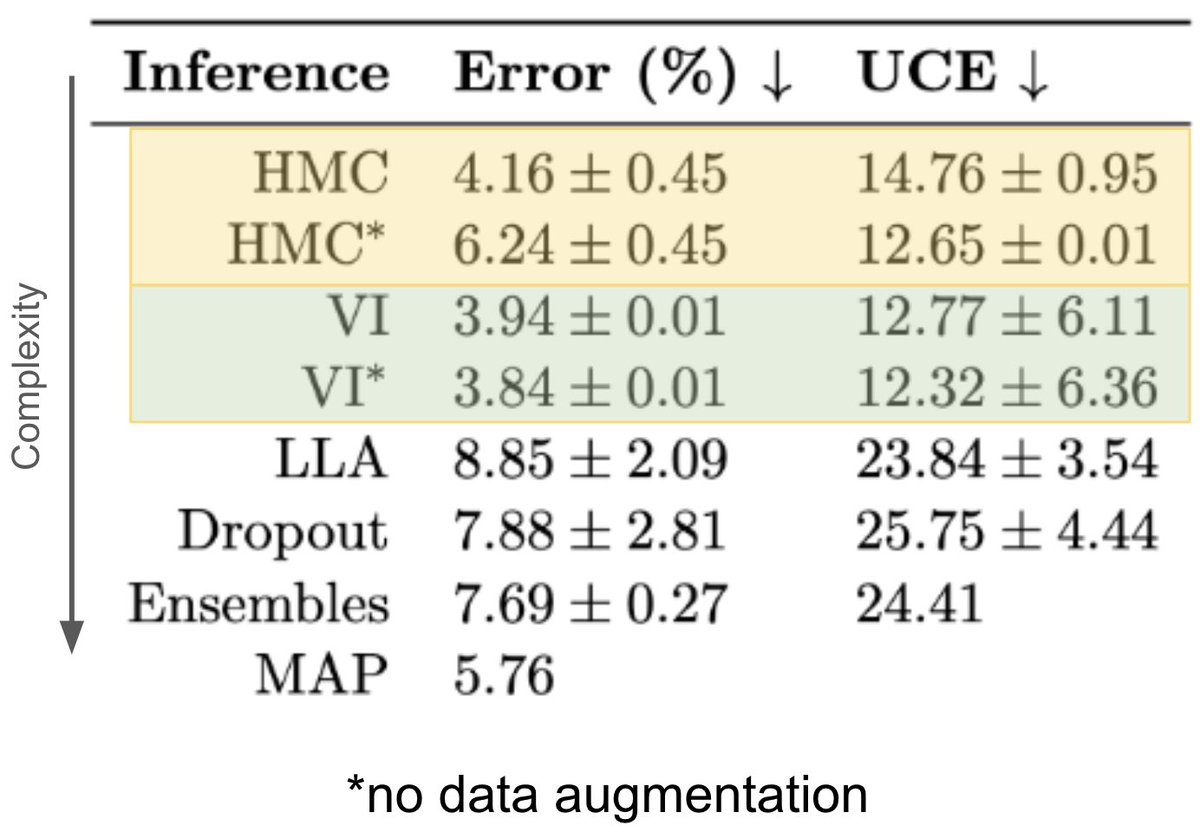
Excited to share our new paper on benchmarking Bayesian deep learning for radio galaxy classification! I’ll be at #UAI2024 and the #AABI2024 Workshop colocated with @icmlconf in July to present this work
29 May 2024

Our #UAI2024 paper, led by @DevinaMohan_ , is on arXiv!
How different Bayesian approximations in deep-learning perform for galaxy classification cf. an HMC baseline.
[model performance, uncertainty calibration, dataset shift detection]
arxiv.org/abs/2405.18351
@UncertaintyInAI

1
6
30
4,418
29 May 2024
Another interesting effect we observed was the trade off between predictive performance and uncertainty calibration on using data augmentation with HMC - but augmentation does not seem to affect our VI models (which have been linked to the cold posterior effect in recent work)
1
548
29 May 2024
Our VI models also experience a cold posterior effect which cannot be explained based on the existing theories in the ML literature. We have previously examined model misspecification in VI with PAC-Bayes bounds, tried different priors, looked at data augmentation..to no avail
308

Three scientist mothers call for a change in how conference childcare costs are reimbursed, drawing on their personal experiences go.nature.com/3X03rLo
11
219
619
155,701
Devina Mohan retweeted

9 May 2024
.@eccvconf reviews are out and the official notification email points to a blog @deviparikh, @stefmlee, and I wrote a few years ago for our students.
Glad to see that our lab style is spreading to the community :-).
deviparikh.medium.com/how-we…
5
12
107
14,184
Devina Mohan retweeted

31 Jan 2024
I’m offering a deep-learning PhD project with my colleagues @sun_mingfei & @JuliaHandl : Combinatorial Optimisation on Graphs for Science Operations in Radio Astronomy ✨📡💻 Get in contact if you are interested! #AI4Astro
6
12
1,600
15 Dec 2023
It’s #ML4PS workshop day at @NeurIPSConf! I’ll be at my poster in the afternoon session (#231). Come by if you’d like to hear about HMC and model misspecification in variational inference for radio galaxy classification: ml4physicalsciences.github.i…
#NeurIPS2023
15 Dec 2023

I'm looking forward to the Machine Learning and the Physical Sciences workshop today (Friday). We are in Hall B2, stop by #ML4PS2023 #NeurIPS2023 @ML4PhyS
ml4physicalsciences.github.i…

6
2,258
Devina Mohan retweeted

14 Dec 2023
This is my attempt to convey how unreasonable and unimaginably large #NeurIPS2023 is. Wild.
3
20
127
36,456