
Dream chaser 🔥|I Graphic designer || sui newbie || passionate about web3 || Reply guy.
Joined March 2023
- Tweets 4,739
- Following 555
- Followers 709
- Likes 4,647
209 Photos and videos



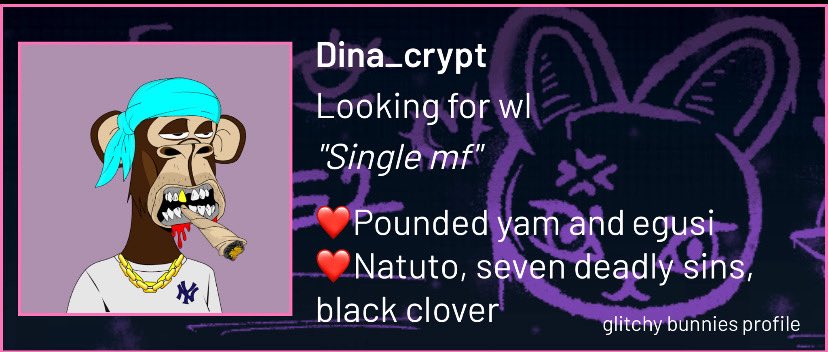



Dina_crypt retweeted

May 16
There is something increasingly rare about art that does not beg to be consumed instantly.
The strongest artistic worlds do not reveal themselves immediately.
They linger first.
They haunt first.
Meaning arrives later.
A thread on @DKashtalyan , the meanings, symbolism,
and the quiet mythology of @thebeaksart 🧵
36
15
48
2,373

May 4
before im nasbela but now im nasient
i will vouch if you comment nasient @nasbelaeth
nasient.xyz?ref=Dina_crypt
1
1
15
Dina_crypt retweeted
Mar 27
GM Web3.
Fresh day, same focus let’s get after it.
Just wrapped up my entries for the Perle Labs campaign, hoping it lands well.
If you’ve been on the fence, there’s still time to jump in. Don’t miss it.

Mar 26

Back again, following up on my last post about AI and data ownership.
This time, let’s dig into something people rarely talk about: the quality of the data that trains AI.
AI doesn’t get smarter just because the model is bigger or faster.
It evolves based on the information it learns from.
Good data = useful, accurate AI.
Bad data = confusing results.
And fake or misleading data? That can be downright harmful.
One growing challenge is that AI is increasingly learning from other AI.
Tweets, blogs, articles all AI-generated content are becoming part of new training datasets.
This creates what experts call synthetic data loops, where the signal slowly degrades over time.
This is where @PerleLabs is different.
Instead of just gathering massive amounts of data, they focus on real human knowledge and verified contributions.
The goal is clear: AI should learn from trustworthy, meaningful data, not recycled noise.
The AI that truly succeeds won’t be the one with the most data it will be the one trained on the right data.
Perle Labs is building AI the right way, and I’m watching closely.
If you’re following along, you’re seeing this early.
#PerleAI #ToPerle
Participating in @PerleLabs community campaign
55
25
58
534
Dina_crypt retweeted

Genesis Globe is coming.
The mint date is officially set for March 11.
Minting will happen via @opensea : opensea.io/collection/genesi…(Wallets are not added yet)
If you still don’t have WL, you still have a chance.
You can apply on our website: genesisglobe.xyz
For the next 48 hours.
This is your chance to be part of Genesis Globe.

13,749
9,249
13,580
704,984
Dina_crypt retweeted

Feb 23
Upcoming mint on eth
Here is a list of upcoming mint I would be showing up for in the coming days
• @ShikiStudios
• @FROGE69mg
• @nucleo_art
• @tatsu_nyc
Sharing spots for some soon.
Like, Rt and Tag a friend.
Good luck 🍀




58
33
104
2,043
Dina_crypt retweeted

Feb 22
Jan 30

Do YOU have what it takes?
MHB is coming to @opensea 🦡
Fill form and get your WL here: megahoneybadgers.com
Drop address and retweet ⬇️
9
5
28
1,686
Feb 20
RT @MikkyWealthMW: Excited to be part of the 3D_PUNKS OG Squad 🦾
I have 20 WL spots to give out to my community! 🎁
How to enter:
– Follow…
11

Giving away 1x GTD and 20x WL spots for @RektBabies
Requirement:
follow @Rektbabies @0xNebula_ @FutureForgers @MrBlahk_
• like
• repost the collab tweet
• tag a rekt baby
• drop 0x
⏳ 24 hours
• repost pinned tweet:
x.com/rektbabies/status/2024…

Feb 18

Introducing Rekt Babies
FREE MINT on ETH
Coming soon to @opensea
Grab WL → rektbabies.xyz
Duration: 36hrs ⏰
Don't get rekt... get a Rekt Baby!
34
20
33
427



First 5000 Solana wallets gets a airdrop $DYOR
Launching Tomorrow
FILL FAST👇
docs.google.com/forms/d/e/1F…
215
173
275
50,774
Dina_crypt retweeted
Feb 18
Free mint on eth
• 550 supply
• Hand drawn arts
• Sharing this soon
Like rt and follow, dropping this soon.
36
20
68
1,975
Feb 18
Feb 18
Introducing Rekt Babies
FREE MINT on ETH
Coming soon to @opensea
Grab WL → rektbabies.xyz
Duration: 36hrs ⏰
Don't get rekt... get a Rekt Baby!
8
Dina_crypt retweeted

Feb 17
LIKE RETWEET
Drop your EVM wallet in comments
ADDING 10 more GTD

142
107
181
5,569
Feb 18
RT @deniyiszn: flash giveaway !
🧧giveaway of 10 nft wl spots for @PUNKBITS_nft
deets;
• chain -apechain
• supply -10,000
to enter;
• f…
51
Dina_crypt retweeted

Feb 14
NFTs are dumb
ask for whitelist and you GMI
Coming 0n main NET ( ETH )
request whitelist → ddb67.xyz/
2,732
1,661
3,064
133,340
Dina_crypt retweeted

Feb 16
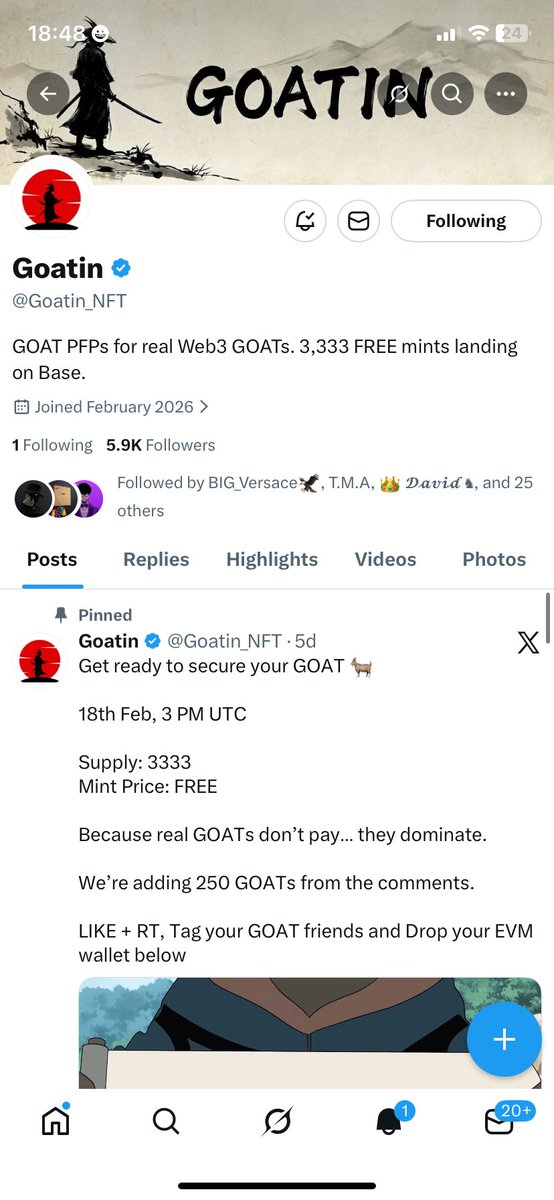
FREEMINT LOADING THIS WEDNESDAY
GOATs only. No brakes.
Checker: goatin.xyz/check
Adding 300 more GTD from the form.
Secure your spot.
Claim here: goatin.xyz/monastery
Form closing soon.
Mint with the GOATs or watch history get written without you.

687
457
847
31,833
Dina_crypt retweeted

Feb 17
Mocha form 3 is live 🍯✨
🧸 step 1: follow/repost
🧸 step 2: join discord ( link in bio)
🧸 step 3: fill mocha form ⚡ tinyurl.com/Mochaform03
welcome home, bestie! ☁️
147
234
520
12,063
Dina_crypt retweeted

Feb 17
Tatsu
A digital collection of 200 1/1 hand-drawn anime-inspired art, each rooted in deep lore
Own a piece of this world
Apply → tatsu.nyc/quest
WL spots are highly limited❕️
8,868
2,954
9,033
699,665